OpenVINO 2024.6#
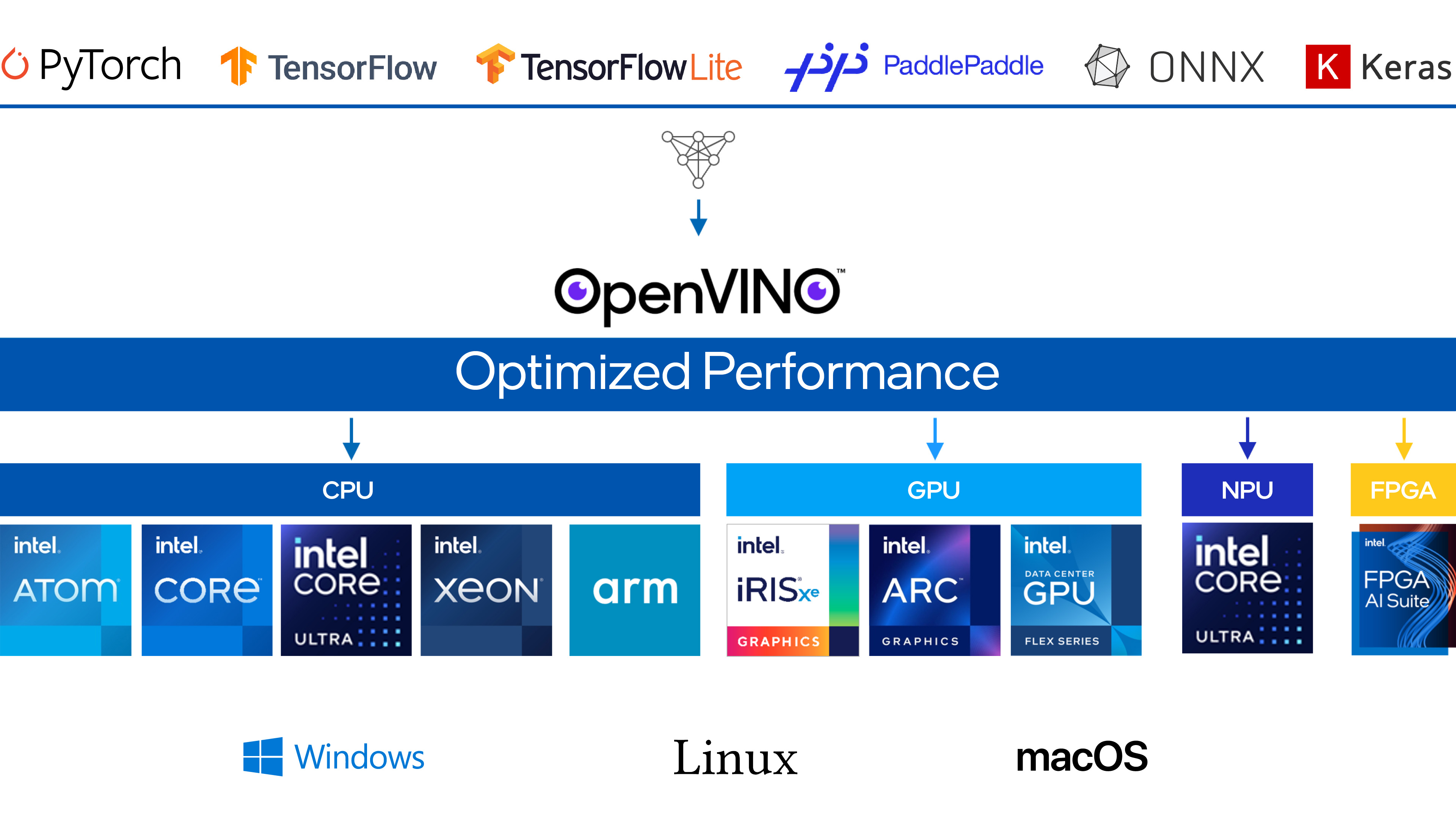
OpenVINO is an open-source toolkit for optimizing and deploying deep learning models from cloud to edge. It accelerates deep learning inference across various use cases, such as generative AI, video, audio, and language with models from popular frameworks like PyTorch, TensorFlow, ONNX, and more. Convert and optimize models, and deploy across a mix of Intel® hardware and environments, on-premises and on-device, in the browser or in the cloud.
Places to Begin#

This guide introduces installation and learning materials for Intel® Distribution of OpenVINO™ toolkit.

See latest benchmark numbers for OpenVINO and OpenVINO Model Server.

Load models directly (for TensorFlow, ONNX, PaddlePaddle) or convert to OpenVINO format.



Reach for performance with post-training and training-time compression with NNCF.
Key Features#

You can either link directly with OpenVINO Runtime to run inference locally or use OpenVINO Model Server to serve model inference from a separate server or within Kubernetes environment.

Write an application once, deploy it anywhere, achieving maximum performance from hardware. Automatic device discovery allows for superior deployment flexibility. OpenVINO Runtime supports Linux, Windows and MacOS and provides Python, C++ and C API. Use your preferred language and OS.

Designed with minimal external dependencies reduces the application footprint, simplifying installation and dependency management. Popular package managers enable application dependencies to be easily installed and upgraded. Custom compilation for your specific model(s) further reduces final binary size.

In applications where fast start-up is required, OpenVINO significantly reduces first-inference latency by using the CPU for initial inference and then switching to another device once the model has been compiled and loaded to memory. Compiled models are cached, improving start-up time even more.