Video Subtitle Generation using Whisper and OpenVINO™#
This Jupyter notebook can be launched on-line, opening an interactive environment in a browser window. You can also make a local installation. Choose one of the following options:


Whisper is an automatic speech recognition (ASR) system trained on 680,000 hours of multilingual and multitask supervised data collected from the web. It is a multi-task model that can perform multilingual speech recognition as well as speech translation and language identification.

asr-training-data-desktop.svg#
You can find more information about this model in the research paper, OpenAI blog, model card and GitHub repository.
In this notebook, we will use Whisper model with OpenVINO Generate API for Whisper automatic speech recognition scenarios to generate subtitles in a sample video. Additionally, we will use NNCF improving model performance by INT8 quantization. Notebook contains the following steps: 1. Download the model. 2. Instantiate the PyTorch model pipeline. 3. Convert model to OpenVINO IR, using model conversion API. 4. Run the Whisper pipeline with OpenVINO models. 5. Quantize the OpenVINO model with NNCF. 6. Check quantized model result for the demo video. 7. Compare model size, performance and accuracy of FP32 and quantized INT8 models. 8. Launch Interactive demo for video subtitles generation.
Table of contents:
Installation Instructions#
This is a self-contained example that relies solely on its own code.
We recommend running the notebook in a virtual environment. You only need a Jupyter server to start. For details, please refer to Installation Guide.
Prerequisites#
Install dependencies.
import platform
import importlib.metadata
import importlib.util
%pip install -q "nncf>=2.14.0"
%pip install -q -U "openvino>=2024.5.0" "openvino-tokenizers>=2024.5.0" "openvino-genai>=2024.5.0"
%pip install -q "python-ffmpeg<=1.0.16" "ffmpeg" "moviepy" "transformers>=4.45" "git+https://github.com/huggingface/optimum-intel.git" "torch>=2.1" --extra-index-url https://download.pytorch.org/whl/cpu
%pip install -q -U "yt_dlp>=2024.8.6" soundfile librosa jiwer packaging
%pip install -q "gradio>=4.19" "typing_extensions>=4.9"
if platform.system() == "Darwin":
%pip install -q "numpy<2.0"
from packaging import version
if (
importlib.util.find_spec("tensorflow") is not None
and version.parse(importlib.metadata.version("tensorflow")) < version.parse("2.18.0")
and version.parse(importlib.metadata.version("numpy")) >= version.parse("2.0.0")
):
%pip uninstall -q -y tensorflow
import requests
from pathlib import Path
if not Path("notebook_utils.py").exists():
r = requests.get(
url="https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/utils/notebook_utils.py",
)
open("notebook_utils.py", "w").write(r.text)
if not Path("cmd_helper.py").exists():
r = requests.get(
url="https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/utils/cmd_helper.py",
)
open("cmd_helper.py", "w").write(r.text)
Instantiate model#
Whisper is a Transformer based encoder-decoder model, also referred to as a sequence-to-sequence model. It maps a sequence of audio spectrogram features to a sequence of text tokens. First, the raw audio inputs are converted to a log-Mel spectrogram by action of the feature extractor. Then, the Transformer encoder encodes the spectrogram to form a sequence of encoder hidden states. Finally, the decoder autoregressively predicts text tokens, conditional on both the previous tokens and the encoder hidden states.
You can see the model architecture in the diagram below:

whisper_architecture.svg#
There are several models of different sizes and capabilities trained by
the authors of the model. In this tutorial, we will use the tiny
model, but the same actions are also applicable to other models from
Whisper family.
import ipywidgets as widgets
MODELS = [
"openai/whisper-large-v3-turbo",
"openai/whisper-large-v3",
"openai/whisper-large-v2",
"openai/whisper-large",
"openai/whisper-medium",
"openai/whisper-small",
"openai/whisper-base",
"openai/whisper-tiny",
]
model_id = widgets.Dropdown(
options=list(MODELS),
value="openai/whisper-tiny",
description="Model:",
disabled=False,
)
model_id
Dropdown(description='Model:', index=7, options=('openai/whisper-large-v3-turbo', 'openai/whisper-large-v3', '…
Convert model to OpenVINO Intermediate Representation (IR) format using Optimum-Intel.#
Listed Whisper model are available for downloading via the HuggingFace hub. We will use optimum-cli interface for exporting it into OpenVINO Intermediate Representation (IR) format.
Optimum CLI interface for converting models supports export to OpenVINO (supported starting optimum-intel 1.12 version). General command format:
optimum-cli export openvino --model <model_id_or_path> --task <task> <output_dir>
where --model argument is model id from HuggingFace Hub or local
directory with model (saved using .save_pretrained method),
--task is one of supported
task
that exported model should solve. For LLMs it will be
automatic-speech-recognition-with-past. If model initialization
requires to use remote code, --trust-remote-code flag additionally
should be passed. Full list of supported arguments available via
--help For more details and examples of usage, please check optimum
documentation.
from cmd_helper import optimum_cli
model_dir = model_id.value.split("/")[-1]
if not Path(model_dir).exists():
optimum_cli(model_id.value, model_dir)
Prepare inference pipeline#
The image below illustrates the pipeline of video transcribing using the Whisper model.
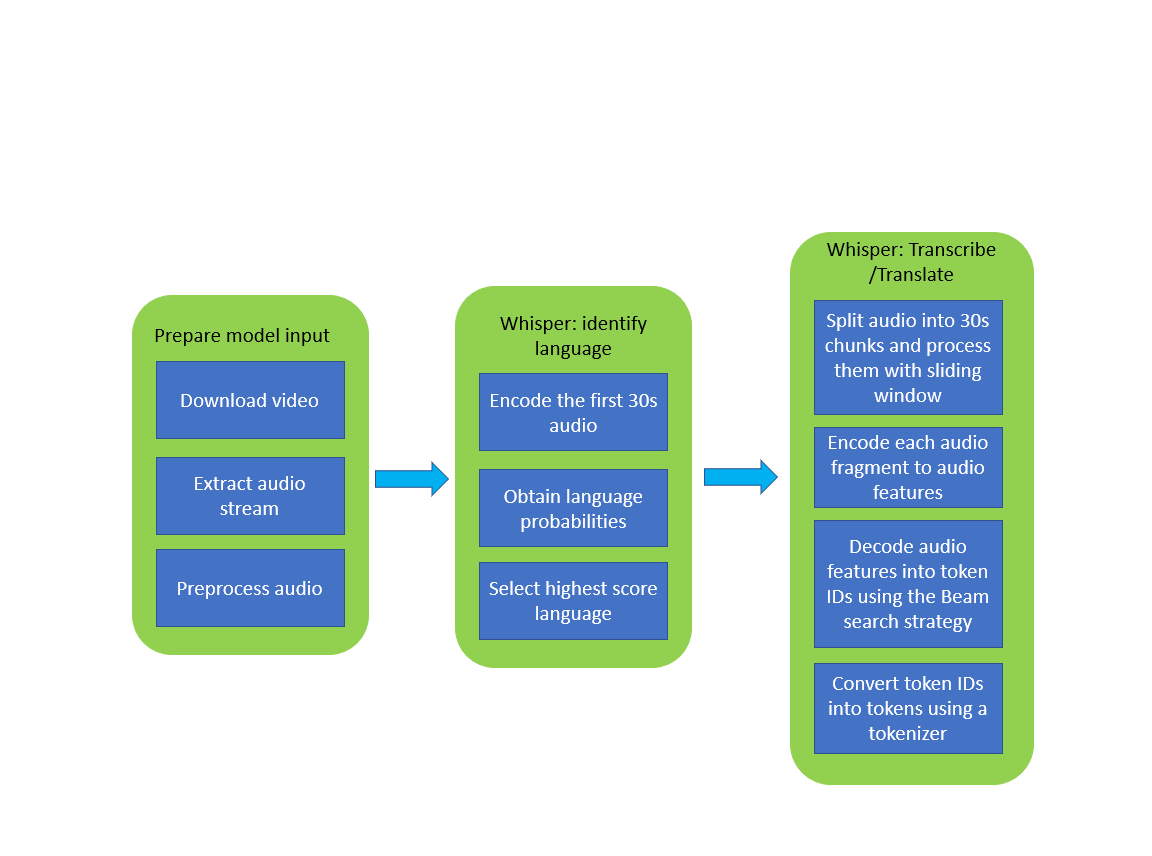
whisper_pipeline.png#
To simplify user experience we will use OpenVINO Generate
API.
Firstly we will create pipeline with WhisperPipeline. You can
construct it straight away from the folder with the converted model. It
will automatically load the model, tokenizer, detokenizer
and default generation configuration.
Select inference device#
select device from dropdown list for running inference using OpenVINO
from notebook_utils import device_widget
device = device_widget(default="CPU", exclude=["NPU"])
device
Dropdown(description='Device:', options=('CPU', 'AUTO'), value='CPU')
import openvino_genai as ov_genai
ov_pipe = ov_genai.WhisperPipeline(str(model_dir), device=device.value)
Run video transcription pipeline#
Now, we are ready to start transcription. Let’s load the video first.
from notebook_utils import download_file
output_file = Path("downloaded_video.mp4")
download_file(
"https://storage.openvinotoolkit.org/repositories/openvino_notebooks/data/data/video/Sheldon%20Cooper%20Jim%20Parsons%20at%20Intels%20Lab.mp4",
filename=output_file.name,
)
'downloaded_video.mp4' already exists.
PosixPath('/home/labuser/work/notebook/openvino_notebooks/notebooks/whisper-subtitles-generation/downloaded_video.mp4')
Select the task for the model:
transcribe - generate audio transcription in the source language (automatically detected).
translate - generate audio transcription with translation to English language.
task = widgets.Select(
options=["transcribe", "translate"],
value="translate",
description="Select task:",
disabled=False,
)
task
Select(description='Select task:', index=1, options=('transcribe', 'translate'), value='translate')
try:
from moviepy import VideoFileClip
except ImportError:
from moviepy.editor import VideoFileClip
from transformers.pipelines.audio_utils import ffmpeg_read
def get_audio(video_file):
"""
Extract audio signal from a given video file, then convert it to float,
then mono-channel format and resample it to the expected sample rate
Parameters:
video_file: path to input video file
Returns:
resampled_audio: mono-channel float audio signal with 16000 Hz sample rate
extracted from video
duration: duration of video fragment in seconds
"""
input_video = VideoFileClip(str(video_file))
duration = input_video.duration
audio_file = video_file.stem + ".wav"
input_video.audio.write_audiofile(audio_file, verbose=False, logger=None)
with open(audio_file, "rb") as f:
inputs = f.read()
audio = ffmpeg_read(inputs, 16000)
return {
"raw": audio,
"sampling_rate": 16000,
}, duration
Let’s run generation method. We will put input data as np array.
Also we will specify task and return_timestamps=True options. If
task is translate, you can place language option, for example
<|fr|> for French or it would be detect automatically. We can set up
generation parameters in different ways. We can get default config with
get_generation_config(), setup parameters and put config directly to
generate(). It’s also possible to specify the needed options just as
inputs in the generate() method and we will use this way. Then we
just run generate method and get the output in text format.
generate method with return_timestamps set to True will
return chunks, which contain attributes: text, start_ts and
end_ts
inputs, duration = get_audio(output_file)
transcription = ov_pipe.generate(inputs["raw"], task=task.value, return_timestamps=True).chunks
import math
def format_timestamp(seconds: float):
"""
format time in srt-file expected format
"""
assert seconds >= 0, "non-negative timestamp expected"
milliseconds = round(seconds * 1000.0)
hours = milliseconds // 3_600_000
milliseconds -= hours * 3_600_000
minutes = milliseconds // 60_000
milliseconds -= minutes * 60_000
seconds = milliseconds // 1_000
milliseconds -= seconds * 1_000
return (f"{hours}:" if hours > 0 else "00:") + f"{minutes:02d}:{seconds:02d},{milliseconds:03d}"
def prepare_srt(transcription, filter_duration=None):
"""
Format transcription into srt file format
"""
segment_lines = []
for idx, segment in enumerate(transcription):
timestamp = (segment.start_ts, segment.end_ts)
# for the case where the model could not predict an ending timestamp, which can happen if audio is cut off in the middle of a word.
if segment.end_ts == -1:
timestamp[1] = filter_duration
if filter_duration is not None and (timestamp[0] >= math.floor(filter_duration) or timestamp[1] > math.ceil(filter_duration) + 1):
break
segment_lines.append(str(idx + 1) + "\n")
time_start = format_timestamp(timestamp[0])
time_end = format_timestamp(timestamp[1])
time_str = f"{time_start} --> {time_end}\n"
segment_lines.append(time_str)
segment_lines.append(segment.text + "\n\n")
return segment_lines
“The results will be saved in the downloaded_video.srt file. SRT is
one of the most popular formats for storing subtitles and is compatible
with many modern video players. This file can be used to embed
transcription into videos during playback or by injecting them directly
into video files using ffmpeg.
srt_lines = prepare_srt(transcription, filter_duration=duration)
# save transcription
with output_file.with_suffix(".srt").open("w") as f:
f.writelines(srt_lines)
Now let us see the results.
widgets.Video.from_file(output_file, loop=False, width=800, height=800)
Video(value=b'x00x00x00x18ftypmp42x00x00x00x00isommp42x00x00Aimoovx00x00x00lmvhd...', height='800…
print("".join(srt_lines))
1
00:00:00,000 --> 00:00:05,000
Oh, what's that?
2
00:00:05,000 --> 00:00:08,000
Oh, wow.
3
00:00:08,000 --> 00:00:10,000
Hello, humans.
4
00:00:13,000 --> 00:00:15,000
Focus on me.
5
00:00:15,000 --> 00:00:17,000
Focus on the guard.
6
00:00:17,000 --> 00:00:20,000
Don't tell anyone what you're seeing in here.
7
00:00:22,000 --> 00:00:24,000
Have you seen what's in there?
8
00:00:24,000 --> 00:00:25,000
They have intel.
9
00:00:25,000 --> 00:00:27,000
This is where it all changes.
Quantization#
NNCF enables post-training quantization by adding the quantization layers into the model graph and then using a subset of the training dataset to initialize the parameters of these additional quantization layers. The framework is designed so that modifications to your original training code are minor.
The optimization process contains the following steps:
Create a calibration dataset for quantization.
Run
nncf.quantizeto obtain quantized encoder and decoder models.Serialize the
INT8model usingopenvino.save_modelfunction.
Note: Quantization is time and memory consuming operation. Running quantization code below may take some time.
Please select below whether you would like to run Whisper quantization.
to_quantize = widgets.Checkbox(
value=True,
description="Quantization",
disabled=False,
)
to_quantize
Checkbox(value=True, description='Quantization')
# Fetch `skip_kernel_extension` module
import requests
r = requests.get(
url="https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/utils/skip_kernel_extension.py",
)
open("skip_kernel_extension.py", "w").write(r.text)
ov_quantized_model = None
quantized_ov_pipe = None
%load_ext skip_kernel_extension
Let’s load converted OpenVINO model format using Optimum-Intel to easily quantize it.
Optimum Intel can be used to load optimized models from the Hugging
Face Hub or
local folder to create pipelines to run an inference with OpenVINO
Runtime using Hugging Face APIs. The Optimum Inference models are API
compatible with Hugging Face Transformers models. This means we just
need to replace the AutoModelForXxx class with the corresponding
OVModelForXxx class.
Below is an example of the whisper-tiny model
-from transformers import AutoModelForSpeechSeq2Seq
+from optimum.intel.openvino import OVModelForSpeechSeq2Seq
from transformers import AutoTokenizer, pipeline
model_id = "openai/whisper-tiny"
-model = AutoModelForSpeechSeq2Seq.from_pretrained(model_id)
+model = OVModelForSpeechSeq2Seq.from_pretrained(model_id, export=True)
Like the original PyTorch model, the OpenVINO model is also compatible
with HuggingFace
pipeline
interface for automatic-speech-recognition.
%%skip not $to_quantize.value
from transformers import AutoProcessor
from optimum.intel.openvino import OVModelForSpeechSeq2Seq
ov_model = OVModelForSpeechSeq2Seq.from_pretrained(model_dir, device=device.value)
processor = AutoProcessor.from_pretrained(model_dir)
Prepare calibration datasets#
First step is to prepare calibration datasets for quantization. Since we
quantize whisper encoder and decoder separately, we need to prepare a
calibration dataset for each of the models. We import an
InferRequestWrapper class that will intercept model inputs and
collect them to a list. Then we run model inference on some small amount
of audio samples. Generally, increasing the calibration dataset size
improves quantization quality.
%%skip not $to_quantize.value
from itertools import islice
from tqdm.notebook import tqdm
from datasets import load_dataset
from transformers import pipeline
from optimum.intel.openvino.quantization import InferRequestWrapper
def collect_calibration_dataset(ov_model: OVModelForSpeechSeq2Seq, calibration_dataset_size: int):
# Overwrite model request properties, saving the original ones for restoring later
encoder_calibration_data = []
decoder_calibration_data = []
ov_model.encoder.request = InferRequestWrapper(ov_model.encoder.request, encoder_calibration_data, apply_caching=True)
ov_model.decoder_with_past.request = InferRequestWrapper(ov_model.decoder_with_past.request,
decoder_calibration_data,
apply_caching=True)
pipe = pipeline(
"automatic-speech-recognition",
model=ov_model,
chunk_length_s=30,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor)
try:
calibration_dataset = dataset = load_dataset("openslr/librispeech_asr", "clean", split="validation", streaming=True, trust_remote_code=True)
for sample in tqdm(islice(calibration_dataset, calibration_dataset_size), desc="Collecting calibration data",
total=calibration_dataset_size):
pipe(sample["audio"], generate_kwargs={"task": task.value}, return_timestamps=True)
finally:
ov_model.encoder.request = ov_model.encoder.request.request
ov_model.decoder_with_past.request = ov_model.decoder_with_past.request.request
return encoder_calibration_data, decoder_calibration_data
Quantize Whisper encoder and decoder models#
Below we run the quantize function which calls nncf.quantize on
Whisper encoder and decoder-with-past models. We don’t quantize
first-step-decoder because its share in whole inference time is
negligible.
%%skip not $to_quantize.value
import gc
import shutil
import nncf
import openvino as ov
CALIBRATION_DATASET_SIZE = 30
quantized_model_path = Path(f"{model_dir}_quantized")
def quantize(ov_model: OVModelForSpeechSeq2Seq, calibration_dataset_size: int):
if not quantized_model_path.exists():
encoder_calibration_data, decoder_calibration_data = collect_calibration_dataset(ov_model, calibration_dataset_size)
print("Quantizing encoder")
quantized_encoder = nncf.quantize(
ov_model.encoder.model,
nncf.Dataset(encoder_calibration_data),
subset_size=len(encoder_calibration_data),
model_type=nncf.ModelType.TRANSFORMER,
# Smooth Quant algorithm reduces activation quantization error; optimal alpha value was obtained through grid search
advanced_parameters=nncf.AdvancedQuantizationParameters(smooth_quant_alpha=0.80),
)
ov.save_model(quantized_encoder, quantized_model_path / "openvino_encoder_model.xml")
del quantized_encoder
del encoder_calibration_data
gc.collect()
print("Quantizing decoder with past")
quantized_decoder_with_past = nncf.quantize(
ov_model.decoder_with_past.model,
nncf.Dataset(decoder_calibration_data),
subset_size=len(decoder_calibration_data),
model_type=nncf.ModelType.TRANSFORMER,
# Smooth Quant algorithm reduces activation quantization error; optimal alpha value was obtained through grid search
advanced_parameters=nncf.AdvancedQuantizationParameters(smooth_quant_alpha=0.96),
)
ov.save_model(quantized_decoder_with_past, quantized_model_path / "openvino_decoder_with_past_model.xml")
del quantized_decoder_with_past
del decoder_calibration_data
gc.collect()
# Copy the config file and the first-step-decoder manually
model_path = Path(model_dir)
shutil.copy(model_path / "config.json", quantized_model_path / "config.json")
shutil.copy(model_path / "generation_config.json", quantized_model_path / "generation_config.json")
shutil.copy(model_path / "openvino_decoder_model.xml", quantized_model_path / "openvino_decoder_model.xml")
shutil.copy(model_path / "openvino_decoder_model.bin", quantized_model_path / "openvino_decoder_model.bin")
shutil.copy(model_path / "openvino_tokenizer.xml", quantized_model_path / "openvino_tokenizer.xml")
shutil.copy(model_path / "openvino_tokenizer.bin", quantized_model_path / "openvino_tokenizer.bin")
shutil.copy(model_path / "openvino_detokenizer.xml", quantized_model_path / "openvino_detokenizer.xml")
shutil.copy(model_path / "openvino_detokenizer.bin", quantized_model_path / "openvino_detokenizer.bin")
shutil.copy(model_path / "tokenizer_config.json", quantized_model_path / "tokenizer_config.json")
shutil.copy(model_path / "tokenizer.json", quantized_model_path / "tokenizer.json")
shutil.copy(model_path / "vocab.json", quantized_model_path / "vocab.json")
shutil.copy(model_path / "preprocessor_config.json", quantized_model_path / "preprocessor_config.json")
shutil.copy(model_path / "special_tokens_map.json", quantized_model_path / "special_tokens_map.json")
shutil.copy(model_path / "normalizer.json", quantized_model_path / "normalizer.json")
shutil.copy(model_path / "merges.txt", quantized_model_path / "merges.txt")
shutil.copy(model_path / "added_tokens.json", quantized_model_path / "added_tokens.json")
quantized_ov_pipe = ov_genai.WhisperPipeline(str(quantized_model_path), device=device.value)
return quantized_ov_pipe
quantized_ov_pipe = quantize(ov_model, CALIBRATION_DATASET_SIZE)
Run quantized model inference#
Let’s compare the transcription results for original and quantized models.
if ov_quantized_model is not None:
inputs, duration = get_audio(output_file)
transcription = quantized_ov_pipe.generate(inputs["raw"], task=task.value, return_timestamps=True).chunks
srt_lines = prepare_srt(transcription, filter_duration=duration)
print("".join(srt_lines))
widgets.Video.from_file(output_file, loop=False, width=800, height=800)
Compare performance and accuracy of the original and quantized models#
Finally, we compare original and quantized Whisper models from accuracy and performance stand-points.
To measure accuracy, we use 1 - WER as a metric, where WER stands
for Word Error Rate.
%%skip not $to_quantize.value
import time
from contextlib import contextmanager
from jiwer import wer, wer_standardize
TEST_DATASET_SIZE = 50
def calculate_transcription_time_and_accuracy(ov_model, test_samples):
whole_infer_times = []
ground_truths = []
predictions = []
for data_item in tqdm(test_samples, desc="Measuring performance and accuracy"):
start_time = time.perf_counter()
transcription = ov_model.generate(data_item["audio"]["array"], return_timestamps=True)
end_time = time.perf_counter()
whole_infer_times.append(end_time - start_time)
ground_truths.append(data_item["text"])
predictions.append(transcription.texts[0])
word_accuracy = (1 - wer(ground_truths, predictions, reference_transform=wer_standardize,
hypothesis_transform=wer_standardize)) * 100
mean_whole_infer_time = sum(whole_infer_times)
return word_accuracy, mean_whole_infer_time
test_dataset = load_dataset("openslr/librispeech_asr", "clean", split="validation", streaming=True, trust_remote_code=True)
test_dataset = test_dataset.shuffle(seed=42).take(TEST_DATASET_SIZE)
test_samples = [sample for sample in test_dataset]
accuracy_original, times_original = calculate_transcription_time_and_accuracy(ov_pipe, test_samples)
accuracy_quantized, times_quantized = calculate_transcription_time_and_accuracy(quantized_ov_pipe, test_samples)
print(f"Whole pipeline performance speedup: {times_original / times_quantized:.3f}")
print(f"Whisper transcription word accuracy. Original model: {accuracy_original:.2f}%. Quantized model: {accuracy_quantized:.2f}%.")
print(f"Accuracy drop: {accuracy_original - accuracy_quantized:.2f}%.")
Measuring performance and accuracy: 0%| | 0/50 [00:00<?, ?it/s]
Measuring performance and accuracy: 0%| | 0/50 [00:00<?, ?it/s]
Whole pipeline performance speedup: 1.452
Whisper transcription word accuracy. Original model: 81.77%. Quantized model: 82.97%.
Accuracy drop: -1.20%.
Interactive demo#
def_config = ov_pipe.get_generation_config()
def transcribe(video_path, task, use_int8):
data_path = Path(video_path)
inputs, duration = get_audio(data_path)
m_pipe = quantized_ov_pipe if use_int8 else ov_pipe
frame_num = len(inputs["raw"]) / 16000
if frame_num > 30:
config = ov_pipe.get_generation_config()
chink_num = math.ceil(frame_num / 30)
config.max_length = chink_num * def_config.max_length
m_pipe.set_generation_config(config)
transcription = m_pipe.generate(inputs["raw"], task=task.lower(), return_timestamps=True).chunks
srt_lines = prepare_srt(transcription, duration)
with data_path.with_suffix(".srt").open("w") as f:
f.writelines(srt_lines)
return [str(data_path), str(data_path.with_suffix(".srt"))]
if not Path("gradio_helper.py").exists():
r = requests.get(url="https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/notebooks/whisper-subtitles-generation/gradio_helper.py")
open("gradio_helper.py", "w").write(r.text)
from gradio_helper import make_demo
demo = make_demo(fn=transcribe, quantized=ov_quantized_model is not None, sample_path=output_file)
try:
demo.launch(debug=False)
except Exception:
demo.launch(share=True, debug=False)
# if you are launching remotely, specify server_name and server_port
# demo.launch(server_name='your server name', server_port='server port in int')
# Read more in the docs: https://gradio.app/docs/