PixArt-α: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis with OpenVINO#
This Jupyter notebook can be launched after a local installation only.

This paper introduces PIXART-α, a Transformer-based T2I diffusion model whose image generation quality is competitive with state-of-the-art image generators, reaching near-commercial application standards. Additionally, it supports high-resolution image synthesis up to 1024px resolution with low training cost. To achieve this goal, three core designs are proposed: 1. Training strategy decomposition: We devise three distinct training steps that separately optimize pixel dependency, text-image alignment, and image aesthetic quality; 2. Efficient T2I Transformer: We incorporate cross-attention modules into Diffusion Transformer (DiT) to inject text conditions and streamline the computation-intensive class-condition branch; 3. High-informative data: We emphasize the significance of concept density in text-image pairs and leverage a large Vision-Language model to auto-label dense pseudo-captions to assist text-image alignment learning.

Table of contents:
This is a self-contained example that relies solely on its own code.
We recommend running the notebook in a virtual environment. You only need a Jupyter server to start. For details, please refer to Installation Guide.
Prerequisites#
%pip install -q "diffusers>=0.14.0" sentencepiece "datasets>=2.14.6" "transformers>=4.25.1" "gradio>=4.19" "torch>=2.1" Pillow opencv-python --extra-index-url https://download.pytorch.org/whl/cpu
%pip install -Uq "openvino>=2024.3.0"
Note: you may need to restart the kernel to use updated packages.
Note: you may need to restart the kernel to use updated packages.
import requests
from pathlib import Path
if not Path("pixart_helper.py").exists():
r = requests.get(url="https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/notebooks/pixart/pixart_helper.py")
open("pixart_helper.py", "w").write(r.text)
if not Path("pixart_quantization_helper.py").exists():
r = requests.get(url="https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/notebooks/pixart/pixart_quantization_helper.py")
open("pixart_quantization_helper.py", "w").write(r.text)
Load and run the original pipeline#
We use
PixArt-LCM-XL-2-1024-MS
that uses LCMs. LCMs is a
diffusion distillation method which predict PF-ODE's solution
directly in latent space, achieving super fast inference with few steps.
import torch
from diffusers import PixArtAlphaPipeline
pipe = PixArtAlphaPipeline.from_pretrained("PixArt-alpha/PixArt-LCM-XL-2-1024-MS", use_safetensors=True)
prompt = "A small cactus with a happy face in the Sahara desert."
generator = torch.Generator().manual_seed(42)
image = pipe(prompt, guidance_scale=0.0, num_inference_steps=4, generator=generator).images[0]
2024-12-10 02:57:23.724286: I tensorflow/core/util/port.cc:110] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable TF_ENABLE_ONEDNN_OPTS=0. 2024-12-10 02:57:23.749610: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations. To enable the following instructions: AVX2 AVX512F AVX512_VNNI FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
Loading pipeline components...: 0%| | 0/5 [00:00<?, ?it/s]
You are using the default legacy behaviour of the <class 'transformers.models.t5.tokenization_t5.T5Tokenizer'>. This is expected, and simply means that the legacy (previous) behavior will be used so nothing changes for you. If you want to use the new behaviour, set legacy=False. This should only be set if you understand what it means, and thoroughly read the reason why this was added as explained in huggingface/transformers#24565 Some weights of the model checkpoint were not used when initializing PixArtTransformer2DModel: ['caption_projection.y_embedding']
Loading checkpoint shards: 0%| | 0/4 [00:00<?, ?it/s]
0%| | 0/4 [00:00<?, ?it/s]
image

Convert the model to OpenVINO IR#
Let’s define the conversion function for PyTorch modules. We use
ov.convert_model function to obtain OpenVINO Intermediate
Representation object and ov.save_model function to save it as XML
file.
import torch
import openvino as ov
def convert(model: torch.nn.Module, xml_path: str, example_input):
xml_path = Path(xml_path)
if not xml_path.exists():
xml_path.parent.mkdir(parents=True, exist_ok=True)
model.eval()
with torch.no_grad():
converted_model = ov.convert_model(model, example_input=example_input)
ov.save_model(converted_model, xml_path)
# cleanup memory
torch._C._jit_clear_class_registry()
torch.jit._recursive.concrete_type_store = torch.jit._recursive.ConcreteTypeStore()
torch.jit._state._clear_class_state()
PixArt-α consists of pure transformer blocks for latent diffusion: It can directly generate 1024px images from text prompts within a single sampling process.
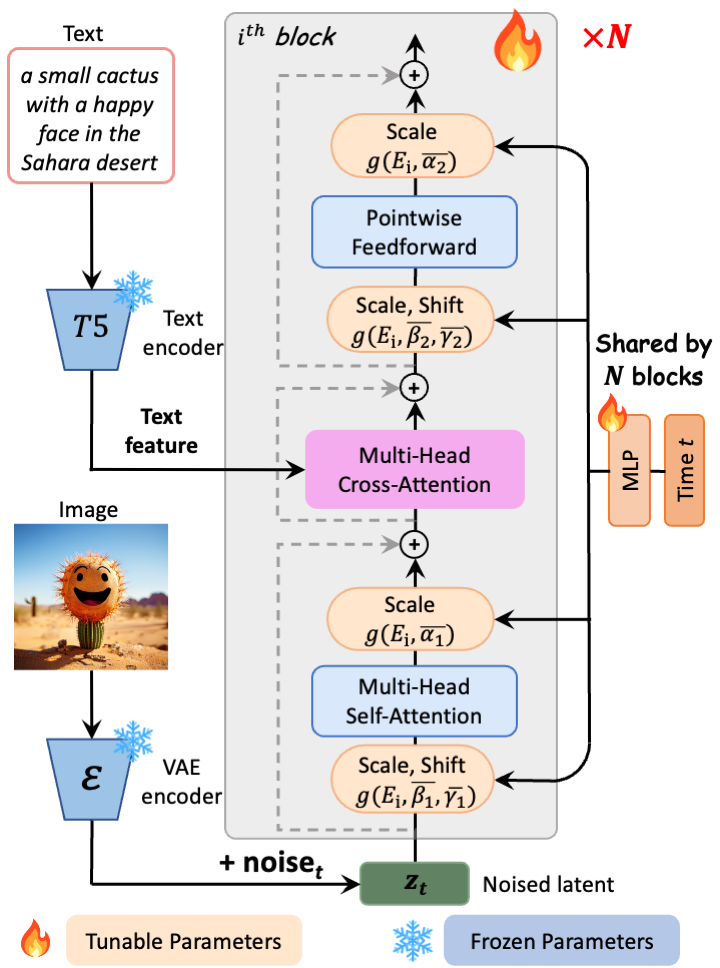 .
.
During inference it uses text encoder T5EncoderModel, transformer
Transformer2DModel and VAE decoder AutoencoderKL. Let’s convert
the models from the pipeline one by one.
from pixart_helper import TEXT_ENCODER_PATH, TRANSFORMER_OV_PATH, VAE_DECODER_PATH
Convert text encoder#
example_input = {
"input_ids": torch.zeros(1, 120, dtype=torch.int64),
"attention_mask": torch.zeros(1, 120, dtype=torch.int64),
}
convert(pipe.text_encoder, TEXT_ENCODER_PATH, example_input)
WARNING:tensorflow:Please fix your imports. Module tensorflow.python.training.tracking.base has been moved to tensorflow.python.trackable.base. The old module will be deleted in version 2.11.
[ WARNING ] Please fix your imports. Module %s has been moved to %s. The old module will be deleted in version %s. /opt/home/k8sworker/ci-ai/cibuilds/jobs/ov-notebook/jobs/OVNotebookOps/builds/835/archive/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/transformers/modeling_utils.py:5006: FutureWarning: _is_quantized_training_enabled is going to be deprecated in transformers 4.39.0. Please use model.hf_quantizer.is_trainable instead warnings.warn( loss_type=None was set in the config but it is unrecognised.Using the default loss: ForCausalLMLoss.
Convert transformer#
class TransformerWrapper(torch.nn.Module):
def __init__(self, transformer):
super().__init__()
self.transformer = transformer
def forward(self, hidden_states=None, timestep=None, encoder_hidden_states=None, encoder_attention_mask=None, resolution=None, aspect_ratio=None):
return self.transformer.forward(
hidden_states,
timestep=timestep,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
added_cond_kwargs={"resolution": resolution, "aspect_ratio": aspect_ratio},
)
example_input = {
"hidden_states": torch.rand([2, 4, 128, 128], dtype=torch.float32),
"timestep": torch.tensor([999, 999]),
"encoder_hidden_states": torch.rand([2, 120, 4096], dtype=torch.float32),
"encoder_attention_mask": torch.rand([2, 120], dtype=torch.float32),
"resolution": torch.tensor([[1024.0, 1024.0], [1024.0, 1024.0]]),
"aspect_ratio": torch.tensor([[1.0], [1.0]]),
}
w_transformer = TransformerWrapper(pipe.transformer)
convert(w_transformer, TRANSFORMER_OV_PATH, example_input)
/opt/home/k8sworker/ci-ai/cibuilds/jobs/ov-notebook/jobs/OVNotebookOps/builds/835/archive/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/diffusers/models/embeddings.py:219: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
if self.height != height or self.width != width:
/opt/home/k8sworker/ci-ai/cibuilds/jobs/ov-notebook/jobs/OVNotebookOps/builds/835/archive/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/diffusers/models/attention_processor.py:682: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
if current_length != target_length:
/opt/home/k8sworker/ci-ai/cibuilds/jobs/ov-notebook/jobs/OVNotebookOps/builds/835/archive/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/diffusers/models/attention_processor.py:697: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
if attention_mask.shape[0] < batch_size * head_size:
Convert VAE decoder#
class VAEDecoderWrapper(torch.nn.Module):
def __init__(self, vae):
super().__init__()
self.vae = vae
def forward(self, latents):
return self.vae.decode(latents, return_dict=False)
convert(VAEDecoderWrapper(pipe.vae), VAE_DECODER_PATH, (torch.zeros((1, 4, 128, 128))))
/opt/home/k8sworker/ci-ai/cibuilds/jobs/ov-notebook/jobs/OVNotebookOps/builds/835/archive/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/diffusers/models/upsampling.py:146: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
assert hidden_states.shape[1] == self.channels
/opt/home/k8sworker/ci-ai/cibuilds/jobs/ov-notebook/jobs/OVNotebookOps/builds/835/archive/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/diffusers/models/upsampling.py:162: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
if hidden_states.shape[0] >= 64:
Compiling models#
Select device from dropdown list for running inference using OpenVINO.
import requests
r = requests.get(
url="https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/utils/notebook_utils.py",
)
open("notebook_utils.py", "w").write(r.text)
from notebook_utils import device_widget
device = device_widget()
device
Dropdown(description='Device:', index=1, options=('CPU', 'AUTO'), value='AUTO')
core = ov.Core()
compiled_model = core.compile_model(TRANSFORMER_OV_PATH, device.value)
compiled_vae = core.compile_model(VAE_DECODER_PATH, device.value)
compiled_text_encoder = core.compile_model(TEXT_ENCODER_PATH, device.value)
Building the pipeline#
Let’s create callable wrapper classes for compiled models to allow
interaction with original pipelines. Note that all of wrapper classes
return torch.Tensors instead of np.arrays.
from collections import namedtuple
EncoderOutput = namedtuple("EncoderOutput", "last_hidden_state")
class TextEncoderWrapper(torch.nn.Module):
def __init__(self, text_encoder, dtype):
super().__init__()
self.text_encoder = text_encoder
self.dtype = dtype
def forward(self, input_ids=None, attention_mask=None):
inputs = {
"input_ids": input_ids,
"attention_mask": attention_mask,
}
last_hidden_state = self.text_encoder(inputs)[0]
return EncoderOutput(torch.from_numpy(last_hidden_state))
class TransformerWrapper(torch.nn.Module):
def __init__(self, transformer, config):
super().__init__()
self.transformer = transformer
self.config = config
def forward(
self,
hidden_states=None,
timestep=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
resolution=None,
aspect_ratio=None,
added_cond_kwargs=None,
**kwargs
):
inputs = {
"hidden_states": hidden_states,
"timestep": timestep,
"encoder_hidden_states": encoder_hidden_states,
"encoder_attention_mask": encoder_attention_mask,
}
resolution = added_cond_kwargs["resolution"]
aspect_ratio = added_cond_kwargs["aspect_ratio"]
if resolution is not None:
inputs["resolution"] = resolution
inputs["aspect_ratio"] = aspect_ratio
outputs = self.transformer(inputs)[0]
return [torch.from_numpy(outputs)]
class VAEWrapper(torch.nn.Module):
def __init__(self, vae, config):
super().__init__()
self.vae = vae
self.config = config
def decode(self, latents=None, **kwargs):
inputs = {
"latents": latents,
}
outs = self.vae(inputs)
outs = namedtuple("VAE", "sample")(torch.from_numpy(outs[0]))
return outs
And insert wrappers instances in the pipeline:
pipe.__dict__["_internal_dict"]["_execution_device"] = pipe._execution_device # this is to avoid some problem that can occur in the pipeline
pipe.register_modules(
text_encoder=TextEncoderWrapper(compiled_text_encoder, pipe.text_encoder.dtype),
transformer=TransformerWrapper(compiled_model, pipe.transformer.config),
vae=VAEWrapper(compiled_vae, pipe.vae.config),
)
generator = torch.Generator().manual_seed(42)
image = pipe(prompt=prompt, guidance_scale=0.0, num_inference_steps=4, generator=generator).images[0]
/opt/home/k8sworker/ci-ai/cibuilds/jobs/ov-notebook/jobs/OVNotebookOps/builds/835/archive/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/diffusers/configuration_utils.py:140: FutureWarning: Accessing config attribute _execution_device directly via 'PixArtAlphaPipeline' object attribute is deprecated. Please access '_execution_device' over 'PixArtAlphaPipeline's config object instead, e.g. 'scheduler.config._execution_device'.
deprecate("direct config name access", "1.0.0", deprecation_message, standard_warn=False)
0%| | 0/4 [00:00<?, ?it/s]
image

Quantization#
NNCF enables
post-training quantization by adding quantization layers into model
graph and then using a subset of the training dataset to initialize the
parameters of these additional quantization layers. Quantized operations
are executed in INT8 instead of FP32/FP16 making model
inference faster.
According to PixArt-LCM-XL-2-1024-MS structure,
Transformer2DModel is used in the cycle repeating inference on each
diffusion step, while other parts of pipeline take part only once.
Quantizing the rest of the pipeline does not significantly improve
inference performance but can lead to a substantial degradation of
accuracy. That’s why we use only weight compression in 4-bits for the
text encoder and vae decoder to reduce the memory footprint. Now
we will show you how to optimize pipeline using
NNCF to reduce memory and
computation cost.
Please select below whether you would like to run quantization to improve model inference speed.
NOTE: Quantization is time and memory consuming operation. Running quantization code below may take some time.
from notebook_utils import quantization_widget
to_quantize = quantization_widget()
to_quantize
Checkbox(value=True, description='Quantization')
Let’s load skip magic extension to skip quantization if
to_quantize is not selected
# Fetch `skip_kernel_extension` module
r = requests.get(
url="https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/utils/skip_kernel_extension.py",
)
open("skip_kernel_extension.py", "w").write(r.text)
optimized_pipe = None
%load_ext skip_kernel_extension
Prepare calibration dataset#
We use a portion of google-research-datasets/conceptual_captions dataset from Hugging Face as calibration data. We use prompts below to guide image generation and to determine what not to include in the resulting image.
To collect intermediate model inputs for calibration we should customize
CompiledModel.
%%skip not $to_quantize.value
from pixart_quantization_helper import INT8_TRANSFORMER_OV_PATH, INT4_TEXT_ENCODER_PATH, INT4_VAE_DECODER_PATH, collect_calibration_data
if not INT8_TRANSFORMER_OV_PATH.exists():
subset_size = 100
calibration_data = collect_calibration_data(pipe, subset_size=subset_size)
0%| | 0/100 [00:00<?, ?it/s]
/opt/home/k8sworker/ci-ai/cibuilds/jobs/ov-notebook/jobs/OVNotebookOps/builds/835/archive/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/diffusers/configuration_utils.py:140: FutureWarning: Accessing config attribute _execution_device directly via 'PixArtAlphaPipeline' object attribute is deprecated. Please access '_execution_device' over 'PixArtAlphaPipeline's config object instead, e.g. 'scheduler.config._execution_device'.
deprecate("direct config name access", "1.0.0", deprecation_message, standard_warn=False)
Run Hybrid Quantization#
For the Transformer2DModel model we apply quantization in hybrid
mode which means that we quantize: (1) weights of MatMul and Embedding
layers and (2) activations of other layers. The steps are the following:
Create a calibration dataset for quantization.
Collect operations with weights.
Run nncf.compress_model() to compress only the model weights.
Run nncf.quantize() on the compressed model with weighted operations ignored by providing ignored_scope parameter.
Save the INT8 model using openvino.save_model() function.
%%skip not $to_quantize.value
import nncf
from nncf.quantization.advanced_parameters import AdvancedSmoothQuantParameters
from nncf.quantization.advanced_parameters import AdvancedQuantizationParameters
from pixart_quantization_helper import get_quantization_ignored_scope
if not INT8_TRANSFORMER_OV_PATH.exists():
model = core.read_model(TRANSFORMER_OV_PATH)
ignored_scope = get_quantization_ignored_scope(model)
# The convolution operations will be fully quantized
compressed_model = nncf.compress_weights(model, ignored_scope=nncf.IgnoredScope(types=['Convolution']))
quantized_model = nncf.quantize(
model=compressed_model,
calibration_dataset=nncf.Dataset(calibration_data),
subset_size=subset_size,
ignored_scope=nncf.IgnoredScope(names=ignored_scope),
model_type=nncf.ModelType.TRANSFORMER,
# Disable SQ because MatMul weights are already compressed
advanced_parameters=AdvancedQuantizationParameters(smooth_quant_alphas=AdvancedSmoothQuantParameters(matmul=-1))
)
ov.save_model(quantized_model, INT8_TRANSFORMER_OV_PATH)
INFO:nncf:NNCF initialized successfully. Supported frameworks detected: torch, tensorflow, onnx, openvino
INFO:nncf:1 ignored nodes were found by types in the NNCFGraph
INFO:nncf:Statistics of the bitwidth distribution:
┍━━━━━━━━━━━━━━━━┯━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┯━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┑
│ Num bits (N) │ % all parameters (layers) │ % ratio-defining parameters (layers) │
┝━━━━━━━━━━━━━━━━┿━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┿━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┥
│ 8 │ 100% (290 / 290) │ 100% (290 / 290) │
┕━━━━━━━━━━━━━━━━┷━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┷━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┙
Output()
INFO:nncf:290 ignored nodes were found by names in the NNCFGraph
INFO:nncf:Not adding activation input quantizer for operation: 9 __module.transformer.caption_projection.linear_1/aten::linear/MatMul
18 __module.transformer.caption_projection.linear_1/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 44 __module.transformer.caption_projection.linear_2/aten::linear/MatMul
171 __module.transformer.caption_projection.linear_2/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 110 __module.transformer.transformer_blocks.0.attn2.to_k/aten::linear/MatMul
263 __module.transformer.transformer_blocks.0.attn2.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 111 __module.transformer.transformer_blocks.0.attn2.to_v/aten::linear/MatMul
264 __module.transformer.transformer_blocks.0.attn2.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 112 __module.transformer.transformer_blocks.1.attn2.to_k/aten::linear/MatMul
265 __module.transformer.transformer_blocks.1.attn2.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 113 __module.transformer.transformer_blocks.1.attn2.to_v/aten::linear/MatMul
266 __module.transformer.transformer_blocks.1.attn2.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 114 __module.transformer.transformer_blocks.10.attn2.to_k/aten::linear/MatMul
267 __module.transformer.transformer_blocks.10.attn2.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 115 __module.transformer.transformer_blocks.10.attn2.to_v/aten::linear/MatMul
268 __module.transformer.transformer_blocks.10.attn2.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 116 __module.transformer.transformer_blocks.11.attn2.to_k/aten::linear/MatMul
269 __module.transformer.transformer_blocks.11.attn2.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 117 __module.transformer.transformer_blocks.11.attn2.to_v/aten::linear/MatMul
270 __module.transformer.transformer_blocks.11.attn2.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 118 __module.transformer.transformer_blocks.12.attn2.to_k/aten::linear/MatMul
271 __module.transformer.transformer_blocks.12.attn2.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 119 __module.transformer.transformer_blocks.12.attn2.to_v/aten::linear/MatMul
272 __module.transformer.transformer_blocks.12.attn2.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 120 __module.transformer.transformer_blocks.13.attn2.to_k/aten::linear/MatMul
273 __module.transformer.transformer_blocks.13.attn2.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 121 __module.transformer.transformer_blocks.13.attn2.to_v/aten::linear/MatMul
274 __module.transformer.transformer_blocks.13.attn2.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 122 __module.transformer.transformer_blocks.14.attn2.to_k/aten::linear/MatMul
275 __module.transformer.transformer_blocks.14.attn2.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 123 __module.transformer.transformer_blocks.14.attn2.to_v/aten::linear/MatMul
276 __module.transformer.transformer_blocks.14.attn2.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 124 __module.transformer.transformer_blocks.15.attn2.to_k/aten::linear/MatMul
277 __module.transformer.transformer_blocks.15.attn2.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 125 __module.transformer.transformer_blocks.15.attn2.to_v/aten::linear/MatMul
278 __module.transformer.transformer_blocks.15.attn2.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 126 __module.transformer.transformer_blocks.16.attn2.to_k/aten::linear/MatMul
279 __module.transformer.transformer_blocks.16.attn2.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 127 __module.transformer.transformer_blocks.16.attn2.to_v/aten::linear/MatMul
280 __module.transformer.transformer_blocks.16.attn2.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 128 __module.transformer.transformer_blocks.17.attn2.to_k/aten::linear/MatMul
281 __module.transformer.transformer_blocks.17.attn2.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 129 __module.transformer.transformer_blocks.17.attn2.to_v/aten::linear/MatMul
282 __module.transformer.transformer_blocks.17.attn2.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 130 __module.transformer.transformer_blocks.18.attn2.to_k/aten::linear/MatMul
283 __module.transformer.transformer_blocks.18.attn2.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 131 __module.transformer.transformer_blocks.18.attn2.to_v/aten::linear/MatMul
284 __module.transformer.transformer_blocks.18.attn2.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 132 __module.transformer.transformer_blocks.19.attn2.to_k/aten::linear/MatMul
285 __module.transformer.transformer_blocks.19.attn2.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 133 __module.transformer.transformer_blocks.19.attn2.to_v/aten::linear/MatMul
286 __module.transformer.transformer_blocks.19.attn2.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 134 __module.transformer.transformer_blocks.2.attn2.to_k/aten::linear/MatMul
287 __module.transformer.transformer_blocks.2.attn2.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 135 __module.transformer.transformer_blocks.2.attn2.to_v/aten::linear/MatMul
288 __module.transformer.transformer_blocks.2.attn2.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 136 __module.transformer.transformer_blocks.20.attn2.to_k/aten::linear/MatMul
289 __module.transformer.transformer_blocks.20.attn2.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 137 __module.transformer.transformer_blocks.20.attn2.to_v/aten::linear/MatMul
290 __module.transformer.transformer_blocks.20.attn2.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 138 __module.transformer.transformer_blocks.21.attn2.to_k/aten::linear/MatMul
291 __module.transformer.transformer_blocks.21.attn2.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 139 __module.transformer.transformer_blocks.21.attn2.to_v/aten::linear/MatMul
292 __module.transformer.transformer_blocks.21.attn2.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 140 __module.transformer.transformer_blocks.22.attn2.to_k/aten::linear/MatMul
293 __module.transformer.transformer_blocks.22.attn2.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 141 __module.transformer.transformer_blocks.22.attn2.to_v/aten::linear/MatMul
294 __module.transformer.transformer_blocks.22.attn2.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 142 __module.transformer.transformer_blocks.23.attn2.to_k/aten::linear/MatMul
295 __module.transformer.transformer_blocks.23.attn2.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 143 __module.transformer.transformer_blocks.23.attn2.to_v/aten::linear/MatMul
296 __module.transformer.transformer_blocks.23.attn2.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 144 __module.transformer.transformer_blocks.24.attn2.to_k/aten::linear/MatMul
297 __module.transformer.transformer_blocks.24.attn2.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 145 __module.transformer.transformer_blocks.24.attn2.to_v/aten::linear/MatMul
298 __module.transformer.transformer_blocks.24.attn2.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 146 __module.transformer.transformer_blocks.25.attn2.to_k/aten::linear/MatMul
299 __module.transformer.transformer_blocks.25.attn2.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 147 __module.transformer.transformer_blocks.25.attn2.to_v/aten::linear/MatMul
300 __module.transformer.transformer_blocks.25.attn2.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 148 __module.transformer.transformer_blocks.26.attn2.to_k/aten::linear/MatMul
301 __module.transformer.transformer_blocks.26.attn2.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 149 __module.transformer.transformer_blocks.26.attn2.to_v/aten::linear/MatMul
302 __module.transformer.transformer_blocks.26.attn2.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 150 __module.transformer.transformer_blocks.27.attn2.to_k/aten::linear/MatMul
303 __module.transformer.transformer_blocks.27.attn2.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 151 __module.transformer.transformer_blocks.27.attn2.to_v/aten::linear/MatMul
304 __module.transformer.transformer_blocks.27.attn2.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 152 __module.transformer.transformer_blocks.3.attn2.to_k/aten::linear/MatMul
305 __module.transformer.transformer_blocks.3.attn2.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 153 __module.transformer.transformer_blocks.3.attn2.to_v/aten::linear/MatMul
306 __module.transformer.transformer_blocks.3.attn2.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 154 __module.transformer.transformer_blocks.4.attn2.to_k/aten::linear/MatMul
307 __module.transformer.transformer_blocks.4.attn2.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 155 __module.transformer.transformer_blocks.4.attn2.to_v/aten::linear/MatMul
308 __module.transformer.transformer_blocks.4.attn2.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 156 __module.transformer.transformer_blocks.5.attn2.to_k/aten::linear/MatMul
309 __module.transformer.transformer_blocks.5.attn2.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 157 __module.transformer.transformer_blocks.5.attn2.to_v/aten::linear/MatMul
310 __module.transformer.transformer_blocks.5.attn2.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 158 __module.transformer.transformer_blocks.6.attn2.to_k/aten::linear/MatMul
311 __module.transformer.transformer_blocks.6.attn2.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 159 __module.transformer.transformer_blocks.6.attn2.to_v/aten::linear/MatMul
312 __module.transformer.transformer_blocks.6.attn2.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 160 __module.transformer.transformer_blocks.7.attn2.to_k/aten::linear/MatMul
313 __module.transformer.transformer_blocks.7.attn2.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 161 __module.transformer.transformer_blocks.7.attn2.to_v/aten::linear/MatMul
314 __module.transformer.transformer_blocks.7.attn2.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 162 __module.transformer.transformer_blocks.8.attn2.to_k/aten::linear/MatMul
315 __module.transformer.transformer_blocks.8.attn2.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 163 __module.transformer.transformer_blocks.8.attn2.to_v/aten::linear/MatMul
316 __module.transformer.transformer_blocks.8.attn2.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 164 __module.transformer.transformer_blocks.9.attn2.to_k/aten::linear/MatMul
317 __module.transformer.transformer_blocks.9.attn2.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 165 __module.transformer.transformer_blocks.9.attn2.to_v/aten::linear/MatMul
318 __module.transformer.transformer_blocks.9.attn2.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 932 __module.transformer.adaln_single.emb.timestep_embedder.linear_1/aten::linear/MatMul
1219 __module.transformer.adaln_single.emb.timestep_embedder.linear_1/aten::linear/Add
1450 __module.transformer.adaln_single.emb.aspect_ratio_embedder.act/aten::silu/Swish
INFO:nncf:Not adding activation input quantizer for operation: 1624 __module.transformer.adaln_single.emb.timestep_embedder.linear_2/aten::linear/MatMul
1769 __module.transformer.adaln_single.emb.timestep_embedder.linear_2/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 934 __module.transformer.adaln_single.emb.resolution_embedder.linear_1/aten::linear/MatMul
1221 __module.transformer.adaln_single.emb.resolution_embedder.linear_1/aten::linear/Add
1452 __module.transformer.adaln_single.emb.aspect_ratio_embedder.act/aten::silu/Swish_1
INFO:nncf:Not adding activation input quantizer for operation: 1625 __module.transformer.adaln_single.emb.resolution_embedder.linear_2/aten::linear/MatMul
1770 __module.transformer.adaln_single.emb.resolution_embedder.linear_2/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 935 __module.transformer.adaln_single.emb.aspect_ratio_embedder.linear_1/aten::linear/MatMul
1222 __module.transformer.adaln_single.emb.aspect_ratio_embedder.linear_1/aten::linear/Add
1453 __module.transformer.adaln_single.emb.aspect_ratio_embedder.act/aten::silu/Swish_2
INFO:nncf:Not adding activation input quantizer for operation: 1626 __module.transformer.adaln_single.emb.aspect_ratio_embedder.linear_2/aten::linear/MatMul
1771 __module.transformer.adaln_single.emb.aspect_ratio_embedder.linear_2/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 623 __module.transformer.adaln_single.linear/aten::linear/MatMul
938 __module.transformer.adaln_single.linear/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 971 __module.transformer.transformer_blocks.0.attn1.to_k/aten::linear/MatMul
1229 __module.transformer.transformer_blocks.0.attn1.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 972 __module.transformer.transformer_blocks.0.attn1.to_q/aten::linear/MatMul
1230 __module.transformer.transformer_blocks.0.attn1.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 973 __module.transformer.transformer_blocks.0.attn1.to_v/aten::linear/MatMul
1231 __module.transformer.transformer_blocks.0.attn1.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1859 __module.transformer.transformer_blocks.0.attn1.to_out.0/aten::linear/MatMul
1887 __module.transformer.transformer_blocks.0.attn1.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 330 __module.transformer.transformer_blocks.0.attn2.to_q/aten::linear/MatMul
620 __module.transformer.transformer_blocks.0.attn2.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 625 __module.transformer.transformer_blocks.0.attn2.to_out.0/aten::linear/MatMul
941 __module.transformer.transformer_blocks.0.attn2.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 656 __module.transformer.transformer_blocks.0.ff.net.0.proj/aten::linear/MatMul
974 __module.transformer.transformer_blocks.0.ff.net.0.proj/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1461 __module.transformer.transformer_blocks.0.ff.net.2/aten::linear/MatMul
1633 __module.transformer.transformer_blocks.0.ff.net.2/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 977 __module.transformer.transformer_blocks.1.attn1.to_k/aten::linear/MatMul
1235 __module.transformer.transformer_blocks.1.attn1.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 978 __module.transformer.transformer_blocks.1.attn1.to_q/aten::linear/MatMul
1236 __module.transformer.transformer_blocks.1.attn1.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 979 __module.transformer.transformer_blocks.1.attn1.to_v/aten::linear/MatMul
1237 __module.transformer.transformer_blocks.1.attn1.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1860 __module.transformer.transformer_blocks.1.attn1.to_out.0/aten::linear/MatMul
1888 __module.transformer.transformer_blocks.1.attn1.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 980 __module.transformer.transformer_blocks.1.attn2.to_q/aten::linear/MatMul
1238 __module.transformer.transformer_blocks.1.attn2.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 626 __module.transformer.transformer_blocks.1.attn2.to_out.0/aten::linear/MatMul
942 __module.transformer.transformer_blocks.1.attn2.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 663 __module.transformer.transformer_blocks.1.ff.net.0.proj/aten::linear/MatMul
982 __module.transformer.transformer_blocks.1.ff.net.0.proj/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1467 __module.transformer.transformer_blocks.1.ff.net.2/aten::linear/MatMul
1638 __module.transformer.transformer_blocks.1.ff.net.2/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1076 __module.transformer.transformer_blocks.2.attn1.to_k/aten::linear/MatMul
1323 __module.transformer.transformer_blocks.2.attn1.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1077 __module.transformer.transformer_blocks.2.attn1.to_q/aten::linear/MatMul
1324 __module.transformer.transformer_blocks.2.attn1.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1078 __module.transformer.transformer_blocks.2.attn1.to_v/aten::linear/MatMul
1325 __module.transformer.transformer_blocks.2.attn1.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1871 __module.transformer.transformer_blocks.2.attn1.to_out.0/aten::linear/MatMul
1899 __module.transformer.transformer_blocks.2.attn1.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1079 __module.transformer.transformer_blocks.2.attn2.to_q/aten::linear/MatMul
1326 __module.transformer.transformer_blocks.2.attn2.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 637 __module.transformer.transformer_blocks.2.attn2.to_out.0/aten::linear/MatMul
953 __module.transformer.transformer_blocks.2.attn2.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 751 __module.transformer.transformer_blocks.2.ff.net.0.proj/aten::linear/MatMul
1081 __module.transformer.transformer_blocks.2.ff.net.0.proj/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1533 __module.transformer.transformer_blocks.2.ff.net.2/aten::linear/MatMul
1693 __module.transformer.transformer_blocks.2.ff.net.2/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1157 __module.transformer.transformer_blocks.3.attn1.to_k/aten::linear/MatMul
1396 __module.transformer.transformer_blocks.3.attn1.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1158 __module.transformer.transformer_blocks.3.attn1.to_q/aten::linear/MatMul
1397 __module.transformer.transformer_blocks.3.attn1.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1159 __module.transformer.transformer_blocks.3.attn1.to_v/aten::linear/MatMul
1398 __module.transformer.transformer_blocks.3.attn1.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1880 __module.transformer.transformer_blocks.3.attn1.to_out.0/aten::linear/MatMul
1908 __module.transformer.transformer_blocks.3.attn1.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1160 __module.transformer.transformer_blocks.3.attn2.to_q/aten::linear/MatMul
1399 __module.transformer.transformer_blocks.3.attn2.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 646 __module.transformer.transformer_blocks.3.attn2.to_out.0/aten::linear/MatMul
962 __module.transformer.transformer_blocks.3.attn2.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 823 __module.transformer.transformer_blocks.3.ff.net.0.proj/aten::linear/MatMul
1162 __module.transformer.transformer_blocks.3.ff.net.0.proj/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1587 __module.transformer.transformer_blocks.3.ff.net.2/aten::linear/MatMul
1738 __module.transformer.transformer_blocks.3.ff.net.2/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1166 __module.transformer.transformer_blocks.4.attn1.to_k/aten::linear/MatMul
1404 __module.transformer.transformer_blocks.4.attn1.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1167 __module.transformer.transformer_blocks.4.attn1.to_q/aten::linear/MatMul
1405 __module.transformer.transformer_blocks.4.attn1.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1168 __module.transformer.transformer_blocks.4.attn1.to_v/aten::linear/MatMul
1406 __module.transformer.transformer_blocks.4.attn1.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1881 __module.transformer.transformer_blocks.4.attn1.to_out.0/aten::linear/MatMul
1909 __module.transformer.transformer_blocks.4.attn1.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1169 __module.transformer.transformer_blocks.4.attn2.to_q/aten::linear/MatMul
1407 __module.transformer.transformer_blocks.4.attn2.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 647 __module.transformer.transformer_blocks.4.attn2.to_out.0/aten::linear/MatMul
963 __module.transformer.transformer_blocks.4.attn2.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 831 __module.transformer.transformer_blocks.4.ff.net.0.proj/aten::linear/MatMul
1171 __module.transformer.transformer_blocks.4.ff.net.0.proj/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1593 __module.transformer.transformer_blocks.4.ff.net.2/aten::linear/MatMul
1743 __module.transformer.transformer_blocks.4.ff.net.2/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1175 __module.transformer.transformer_blocks.5.attn1.to_k/aten::linear/MatMul
1412 __module.transformer.transformer_blocks.5.attn1.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1176 __module.transformer.transformer_blocks.5.attn1.to_q/aten::linear/MatMul
1413 __module.transformer.transformer_blocks.5.attn1.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1177 __module.transformer.transformer_blocks.5.attn1.to_v/aten::linear/MatMul
1414 __module.transformer.transformer_blocks.5.attn1.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1882 __module.transformer.transformer_blocks.5.attn1.to_out.0/aten::linear/MatMul
1910 __module.transformer.transformer_blocks.5.attn1.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1178 __module.transformer.transformer_blocks.5.attn2.to_q/aten::linear/MatMul
1415 __module.transformer.transformer_blocks.5.attn2.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 648 __module.transformer.transformer_blocks.5.attn2.to_out.0/aten::linear/MatMul
964 __module.transformer.transformer_blocks.5.attn2.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 839 __module.transformer.transformer_blocks.5.ff.net.0.proj/aten::linear/MatMul
1180 __module.transformer.transformer_blocks.5.ff.net.0.proj/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1599 __module.transformer.transformer_blocks.5.ff.net.2/aten::linear/MatMul
1748 __module.transformer.transformer_blocks.5.ff.net.2/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1184 __module.transformer.transformer_blocks.6.attn1.to_k/aten::linear/MatMul
1420 __module.transformer.transformer_blocks.6.attn1.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1185 __module.transformer.transformer_blocks.6.attn1.to_q/aten::linear/MatMul
1421 __module.transformer.transformer_blocks.6.attn1.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1186 __module.transformer.transformer_blocks.6.attn1.to_v/aten::linear/MatMul
1422 __module.transformer.transformer_blocks.6.attn1.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1883 __module.transformer.transformer_blocks.6.attn1.to_out.0/aten::linear/MatMul
1911 __module.transformer.transformer_blocks.6.attn1.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1187 __module.transformer.transformer_blocks.6.attn2.to_q/aten::linear/MatMul
1423 __module.transformer.transformer_blocks.6.attn2.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 649 __module.transformer.transformer_blocks.6.attn2.to_out.0/aten::linear/MatMul
965 __module.transformer.transformer_blocks.6.attn2.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 847 __module.transformer.transformer_blocks.6.ff.net.0.proj/aten::linear/MatMul
1189 __module.transformer.transformer_blocks.6.ff.net.0.proj/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1605 __module.transformer.transformer_blocks.6.ff.net.2/aten::linear/MatMul
1753 __module.transformer.transformer_blocks.6.ff.net.2/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1193 __module.transformer.transformer_blocks.7.attn1.to_k/aten::linear/MatMul
1428 __module.transformer.transformer_blocks.7.attn1.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1194 __module.transformer.transformer_blocks.7.attn1.to_q/aten::linear/MatMul
1429 __module.transformer.transformer_blocks.7.attn1.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1195 __module.transformer.transformer_blocks.7.attn1.to_v/aten::linear/MatMul
1430 __module.transformer.transformer_blocks.7.attn1.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1884 __module.transformer.transformer_blocks.7.attn1.to_out.0/aten::linear/MatMul
1912 __module.transformer.transformer_blocks.7.attn1.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1196 __module.transformer.transformer_blocks.7.attn2.to_q/aten::linear/MatMul
1431 __module.transformer.transformer_blocks.7.attn2.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 650 __module.transformer.transformer_blocks.7.attn2.to_out.0/aten::linear/MatMul
966 __module.transformer.transformer_blocks.7.attn2.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 855 __module.transformer.transformer_blocks.7.ff.net.0.proj/aten::linear/MatMul
1198 __module.transformer.transformer_blocks.7.ff.net.0.proj/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1611 __module.transformer.transformer_blocks.7.ff.net.2/aten::linear/MatMul
1758 __module.transformer.transformer_blocks.7.ff.net.2/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1202 __module.transformer.transformer_blocks.8.attn1.to_k/aten::linear/MatMul
1436 __module.transformer.transformer_blocks.8.attn1.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1203 __module.transformer.transformer_blocks.8.attn1.to_q/aten::linear/MatMul
1437 __module.transformer.transformer_blocks.8.attn1.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1204 __module.transformer.transformer_blocks.8.attn1.to_v/aten::linear/MatMul
1438 __module.transformer.transformer_blocks.8.attn1.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1885 __module.transformer.transformer_blocks.8.attn1.to_out.0/aten::linear/MatMul
1913 __module.transformer.transformer_blocks.8.attn1.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1205 __module.transformer.transformer_blocks.8.attn2.to_q/aten::linear/MatMul
1439 __module.transformer.transformer_blocks.8.attn2.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 651 __module.transformer.transformer_blocks.8.attn2.to_out.0/aten::linear/MatMul
967 __module.transformer.transformer_blocks.8.attn2.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 863 __module.transformer.transformer_blocks.8.ff.net.0.proj/aten::linear/MatMul
1207 __module.transformer.transformer_blocks.8.ff.net.0.proj/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1617 __module.transformer.transformer_blocks.8.ff.net.2/aten::linear/MatMul
1763 __module.transformer.transformer_blocks.8.ff.net.2/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1211 __module.transformer.transformer_blocks.9.attn1.to_k/aten::linear/MatMul
1444 __module.transformer.transformer_blocks.9.attn1.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1212 __module.transformer.transformer_blocks.9.attn1.to_q/aten::linear/MatMul
1445 __module.transformer.transformer_blocks.9.attn1.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1213 __module.transformer.transformer_blocks.9.attn1.to_v/aten::linear/MatMul
1446 __module.transformer.transformer_blocks.9.attn1.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1886 __module.transformer.transformer_blocks.9.attn1.to_out.0/aten::linear/MatMul
1914 __module.transformer.transformer_blocks.9.attn1.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1214 __module.transformer.transformer_blocks.9.attn2.to_q/aten::linear/MatMul
1447 __module.transformer.transformer_blocks.9.attn2.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 652 __module.transformer.transformer_blocks.9.attn2.to_out.0/aten::linear/MatMul
968 __module.transformer.transformer_blocks.9.attn2.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 871 __module.transformer.transformer_blocks.9.ff.net.0.proj/aten::linear/MatMul
1216 __module.transformer.transformer_blocks.9.ff.net.0.proj/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1623 __module.transformer.transformer_blocks.9.ff.net.2/aten::linear/MatMul
1768 __module.transformer.transformer_blocks.9.ff.net.2/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 986 __module.transformer.transformer_blocks.10.attn1.to_k/aten::linear/MatMul
1243 __module.transformer.transformer_blocks.10.attn1.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 987 __module.transformer.transformer_blocks.10.attn1.to_q/aten::linear/MatMul
1244 __module.transformer.transformer_blocks.10.attn1.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 988 __module.transformer.transformer_blocks.10.attn1.to_v/aten::linear/MatMul
1245 __module.transformer.transformer_blocks.10.attn1.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1861 __module.transformer.transformer_blocks.10.attn1.to_out.0/aten::linear/MatMul
1889 __module.transformer.transformer_blocks.10.attn1.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 989 __module.transformer.transformer_blocks.10.attn2.to_q/aten::linear/MatMul
1246 __module.transformer.transformer_blocks.10.attn2.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 627 __module.transformer.transformer_blocks.10.attn2.to_out.0/aten::linear/MatMul
943 __module.transformer.transformer_blocks.10.attn2.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 671 __module.transformer.transformer_blocks.10.ff.net.0.proj/aten::linear/MatMul
991 __module.transformer.transformer_blocks.10.ff.net.0.proj/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1473 __module.transformer.transformer_blocks.10.ff.net.2/aten::linear/MatMul
1643 __module.transformer.transformer_blocks.10.ff.net.2/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 995 __module.transformer.transformer_blocks.11.attn1.to_k/aten::linear/MatMul
1251 __module.transformer.transformer_blocks.11.attn1.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 996 __module.transformer.transformer_blocks.11.attn1.to_q/aten::linear/MatMul
1252 __module.transformer.transformer_blocks.11.attn1.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 997 __module.transformer.transformer_blocks.11.attn1.to_v/aten::linear/MatMul
1253 __module.transformer.transformer_blocks.11.attn1.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1862 __module.transformer.transformer_blocks.11.attn1.to_out.0/aten::linear/MatMul
1890 __module.transformer.transformer_blocks.11.attn1.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 998 __module.transformer.transformer_blocks.11.attn2.to_q/aten::linear/MatMul
1254 __module.transformer.transformer_blocks.11.attn2.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 628 __module.transformer.transformer_blocks.11.attn2.to_out.0/aten::linear/MatMul
944 __module.transformer.transformer_blocks.11.attn2.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 679 __module.transformer.transformer_blocks.11.ff.net.0.proj/aten::linear/MatMul
1000 __module.transformer.transformer_blocks.11.ff.net.0.proj/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1479 __module.transformer.transformer_blocks.11.ff.net.2/aten::linear/MatMul
1648 __module.transformer.transformer_blocks.11.ff.net.2/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1004 __module.transformer.transformer_blocks.12.attn1.to_k/aten::linear/MatMul
1259 __module.transformer.transformer_blocks.12.attn1.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1005 __module.transformer.transformer_blocks.12.attn1.to_q/aten::linear/MatMul
1260 __module.transformer.transformer_blocks.12.attn1.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1006 __module.transformer.transformer_blocks.12.attn1.to_v/aten::linear/MatMul
1261 __module.transformer.transformer_blocks.12.attn1.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1863 __module.transformer.transformer_blocks.12.attn1.to_out.0/aten::linear/MatMul
1891 __module.transformer.transformer_blocks.12.attn1.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1007 __module.transformer.transformer_blocks.12.attn2.to_q/aten::linear/MatMul
1262 __module.transformer.transformer_blocks.12.attn2.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 629 __module.transformer.transformer_blocks.12.attn2.to_out.0/aten::linear/MatMul
945 __module.transformer.transformer_blocks.12.attn2.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 687 __module.transformer.transformer_blocks.12.ff.net.0.proj/aten::linear/MatMul
1009 __module.transformer.transformer_blocks.12.ff.net.0.proj/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1485 __module.transformer.transformer_blocks.12.ff.net.2/aten::linear/MatMul
1653 __module.transformer.transformer_blocks.12.ff.net.2/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1013 __module.transformer.transformer_blocks.13.attn1.to_k/aten::linear/MatMul
1267 __module.transformer.transformer_blocks.13.attn1.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1014 __module.transformer.transformer_blocks.13.attn1.to_q/aten::linear/MatMul
1268 __module.transformer.transformer_blocks.13.attn1.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1015 __module.transformer.transformer_blocks.13.attn1.to_v/aten::linear/MatMul
1269 __module.transformer.transformer_blocks.13.attn1.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1864 __module.transformer.transformer_blocks.13.attn1.to_out.0/aten::linear/MatMul
1892 __module.transformer.transformer_blocks.13.attn1.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1016 __module.transformer.transformer_blocks.13.attn2.to_q/aten::linear/MatMul
1270 __module.transformer.transformer_blocks.13.attn2.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 630 __module.transformer.transformer_blocks.13.attn2.to_out.0/aten::linear/MatMul
946 __module.transformer.transformer_blocks.13.attn2.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 695 __module.transformer.transformer_blocks.13.ff.net.0.proj/aten::linear/MatMul
1018 __module.transformer.transformer_blocks.13.ff.net.0.proj/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1491 __module.transformer.transformer_blocks.13.ff.net.2/aten::linear/MatMul
1658 __module.transformer.transformer_blocks.13.ff.net.2/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1022 __module.transformer.transformer_blocks.14.attn1.to_k/aten::linear/MatMul
1275 __module.transformer.transformer_blocks.14.attn1.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1023 __module.transformer.transformer_blocks.14.attn1.to_q/aten::linear/MatMul
1276 __module.transformer.transformer_blocks.14.attn1.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1024 __module.transformer.transformer_blocks.14.attn1.to_v/aten::linear/MatMul
1277 __module.transformer.transformer_blocks.14.attn1.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1865 __module.transformer.transformer_blocks.14.attn1.to_out.0/aten::linear/MatMul
1893 __module.transformer.transformer_blocks.14.attn1.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1025 __module.transformer.transformer_blocks.14.attn2.to_q/aten::linear/MatMul
1278 __module.transformer.transformer_blocks.14.attn2.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 631 __module.transformer.transformer_blocks.14.attn2.to_out.0/aten::linear/MatMul
947 __module.transformer.transformer_blocks.14.attn2.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 703 __module.transformer.transformer_blocks.14.ff.net.0.proj/aten::linear/MatMul
1027 __module.transformer.transformer_blocks.14.ff.net.0.proj/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1497 __module.transformer.transformer_blocks.14.ff.net.2/aten::linear/MatMul
1663 __module.transformer.transformer_blocks.14.ff.net.2/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1031 __module.transformer.transformer_blocks.15.attn1.to_k/aten::linear/MatMul
1283 __module.transformer.transformer_blocks.15.attn1.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1032 __module.transformer.transformer_blocks.15.attn1.to_q/aten::linear/MatMul
1284 __module.transformer.transformer_blocks.15.attn1.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1033 __module.transformer.transformer_blocks.15.attn1.to_v/aten::linear/MatMul
1285 __module.transformer.transformer_blocks.15.attn1.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1866 __module.transformer.transformer_blocks.15.attn1.to_out.0/aten::linear/MatMul
1894 __module.transformer.transformer_blocks.15.attn1.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1034 __module.transformer.transformer_blocks.15.attn2.to_q/aten::linear/MatMul
1286 __module.transformer.transformer_blocks.15.attn2.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 632 __module.transformer.transformer_blocks.15.attn2.to_out.0/aten::linear/MatMul
948 __module.transformer.transformer_blocks.15.attn2.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 711 __module.transformer.transformer_blocks.15.ff.net.0.proj/aten::linear/MatMul
1036 __module.transformer.transformer_blocks.15.ff.net.0.proj/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1503 __module.transformer.transformer_blocks.15.ff.net.2/aten::linear/MatMul
1668 __module.transformer.transformer_blocks.15.ff.net.2/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1040 __module.transformer.transformer_blocks.16.attn1.to_k/aten::linear/MatMul
1291 __module.transformer.transformer_blocks.16.attn1.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1041 __module.transformer.transformer_blocks.16.attn1.to_q/aten::linear/MatMul
1292 __module.transformer.transformer_blocks.16.attn1.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1042 __module.transformer.transformer_blocks.16.attn1.to_v/aten::linear/MatMul
1293 __module.transformer.transformer_blocks.16.attn1.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1867 __module.transformer.transformer_blocks.16.attn1.to_out.0/aten::linear/MatMul
1895 __module.transformer.transformer_blocks.16.attn1.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1043 __module.transformer.transformer_blocks.16.attn2.to_q/aten::linear/MatMul
1294 __module.transformer.transformer_blocks.16.attn2.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 633 __module.transformer.transformer_blocks.16.attn2.to_out.0/aten::linear/MatMul
949 __module.transformer.transformer_blocks.16.attn2.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 719 __module.transformer.transformer_blocks.16.ff.net.0.proj/aten::linear/MatMul
1045 __module.transformer.transformer_blocks.16.ff.net.0.proj/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1509 __module.transformer.transformer_blocks.16.ff.net.2/aten::linear/MatMul
1673 __module.transformer.transformer_blocks.16.ff.net.2/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1049 __module.transformer.transformer_blocks.17.attn1.to_k/aten::linear/MatMul
1299 __module.transformer.transformer_blocks.17.attn1.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1050 __module.transformer.transformer_blocks.17.attn1.to_q/aten::linear/MatMul
1300 __module.transformer.transformer_blocks.17.attn1.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1051 __module.transformer.transformer_blocks.17.attn1.to_v/aten::linear/MatMul
1301 __module.transformer.transformer_blocks.17.attn1.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1868 __module.transformer.transformer_blocks.17.attn1.to_out.0/aten::linear/MatMul
1896 __module.transformer.transformer_blocks.17.attn1.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1052 __module.transformer.transformer_blocks.17.attn2.to_q/aten::linear/MatMul
1302 __module.transformer.transformer_blocks.17.attn2.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 634 __module.transformer.transformer_blocks.17.attn2.to_out.0/aten::linear/MatMul
950 __module.transformer.transformer_blocks.17.attn2.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 727 __module.transformer.transformer_blocks.17.ff.net.0.proj/aten::linear/MatMul
1054 __module.transformer.transformer_blocks.17.ff.net.0.proj/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1515 __module.transformer.transformer_blocks.17.ff.net.2/aten::linear/MatMul
1678 __module.transformer.transformer_blocks.17.ff.net.2/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1058 __module.transformer.transformer_blocks.18.attn1.to_k/aten::linear/MatMul
1307 __module.transformer.transformer_blocks.18.attn1.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1059 __module.transformer.transformer_blocks.18.attn1.to_q/aten::linear/MatMul
1308 __module.transformer.transformer_blocks.18.attn1.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1060 __module.transformer.transformer_blocks.18.attn1.to_v/aten::linear/MatMul
1309 __module.transformer.transformer_blocks.18.attn1.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1869 __module.transformer.transformer_blocks.18.attn1.to_out.0/aten::linear/MatMul
1897 __module.transformer.transformer_blocks.18.attn1.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1061 __module.transformer.transformer_blocks.18.attn2.to_q/aten::linear/MatMul
1310 __module.transformer.transformer_blocks.18.attn2.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 635 __module.transformer.transformer_blocks.18.attn2.to_out.0/aten::linear/MatMul
951 __module.transformer.transformer_blocks.18.attn2.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 735 __module.transformer.transformer_blocks.18.ff.net.0.proj/aten::linear/MatMul
1063 __module.transformer.transformer_blocks.18.ff.net.0.proj/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1521 __module.transformer.transformer_blocks.18.ff.net.2/aten::linear/MatMul
1683 __module.transformer.transformer_blocks.18.ff.net.2/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1067 __module.transformer.transformer_blocks.19.attn1.to_k/aten::linear/MatMul
1315 __module.transformer.transformer_blocks.19.attn1.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1068 __module.transformer.transformer_blocks.19.attn1.to_q/aten::linear/MatMul
1316 __module.transformer.transformer_blocks.19.attn1.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1069 __module.transformer.transformer_blocks.19.attn1.to_v/aten::linear/MatMul
1317 __module.transformer.transformer_blocks.19.attn1.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1870 __module.transformer.transformer_blocks.19.attn1.to_out.0/aten::linear/MatMul
1898 __module.transformer.transformer_blocks.19.attn1.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1070 __module.transformer.transformer_blocks.19.attn2.to_q/aten::linear/MatMul
1318 __module.transformer.transformer_blocks.19.attn2.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 636 __module.transformer.transformer_blocks.19.attn2.to_out.0/aten::linear/MatMul
952 __module.transformer.transformer_blocks.19.attn2.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 743 __module.transformer.transformer_blocks.19.ff.net.0.proj/aten::linear/MatMul
1072 __module.transformer.transformer_blocks.19.ff.net.0.proj/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1527 __module.transformer.transformer_blocks.19.ff.net.2/aten::linear/MatMul
1688 __module.transformer.transformer_blocks.19.ff.net.2/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1085 __module.transformer.transformer_blocks.20.attn1.to_k/aten::linear/MatMul
1331 __module.transformer.transformer_blocks.20.attn1.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1086 __module.transformer.transformer_blocks.20.attn1.to_q/aten::linear/MatMul
1332 __module.transformer.transformer_blocks.20.attn1.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1087 __module.transformer.transformer_blocks.20.attn1.to_v/aten::linear/MatMul
1333 __module.transformer.transformer_blocks.20.attn1.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1872 __module.transformer.transformer_blocks.20.attn1.to_out.0/aten::linear/MatMul
1900 __module.transformer.transformer_blocks.20.attn1.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1088 __module.transformer.transformer_blocks.20.attn2.to_q/aten::linear/MatMul
1334 __module.transformer.transformer_blocks.20.attn2.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 638 __module.transformer.transformer_blocks.20.attn2.to_out.0/aten::linear/MatMul
954 __module.transformer.transformer_blocks.20.attn2.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 759 __module.transformer.transformer_blocks.20.ff.net.0.proj/aten::linear/MatMul
1090 __module.transformer.transformer_blocks.20.ff.net.0.proj/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1539 __module.transformer.transformer_blocks.20.ff.net.2/aten::linear/MatMul
1698 __module.transformer.transformer_blocks.20.ff.net.2/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1094 __module.transformer.transformer_blocks.21.attn1.to_k/aten::linear/MatMul
1339 __module.transformer.transformer_blocks.21.attn1.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1095 __module.transformer.transformer_blocks.21.attn1.to_q/aten::linear/MatMul
1340 __module.transformer.transformer_blocks.21.attn1.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1096 __module.transformer.transformer_blocks.21.attn1.to_v/aten::linear/MatMul
1341 __module.transformer.transformer_blocks.21.attn1.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1873 __module.transformer.transformer_blocks.21.attn1.to_out.0/aten::linear/MatMul
1901 __module.transformer.transformer_blocks.21.attn1.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1097 __module.transformer.transformer_blocks.21.attn2.to_q/aten::linear/MatMul
1342 __module.transformer.transformer_blocks.21.attn2.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 639 __module.transformer.transformer_blocks.21.attn2.to_out.0/aten::linear/MatMul
955 __module.transformer.transformer_blocks.21.attn2.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 767 __module.transformer.transformer_blocks.21.ff.net.0.proj/aten::linear/MatMul
1099 __module.transformer.transformer_blocks.21.ff.net.0.proj/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1545 __module.transformer.transformer_blocks.21.ff.net.2/aten::linear/MatMul
1703 __module.transformer.transformer_blocks.21.ff.net.2/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1103 __module.transformer.transformer_blocks.22.attn1.to_k/aten::linear/MatMul
1347 __module.transformer.transformer_blocks.22.attn1.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1104 __module.transformer.transformer_blocks.22.attn1.to_q/aten::linear/MatMul
1348 __module.transformer.transformer_blocks.22.attn1.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1105 __module.transformer.transformer_blocks.22.attn1.to_v/aten::linear/MatMul
1349 __module.transformer.transformer_blocks.22.attn1.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1874 __module.transformer.transformer_blocks.22.attn1.to_out.0/aten::linear/MatMul
1902 __module.transformer.transformer_blocks.22.attn1.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1106 __module.transformer.transformer_blocks.22.attn2.to_q/aten::linear/MatMul
1350 __module.transformer.transformer_blocks.22.attn2.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 640 __module.transformer.transformer_blocks.22.attn2.to_out.0/aten::linear/MatMul
956 __module.transformer.transformer_blocks.22.attn2.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 775 __module.transformer.transformer_blocks.22.ff.net.0.proj/aten::linear/MatMul
1108 __module.transformer.transformer_blocks.22.ff.net.0.proj/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1551 __module.transformer.transformer_blocks.22.ff.net.2/aten::linear/MatMul
1708 __module.transformer.transformer_blocks.22.ff.net.2/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1112 __module.transformer.transformer_blocks.23.attn1.to_k/aten::linear/MatMul
1355 __module.transformer.transformer_blocks.23.attn1.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1113 __module.transformer.transformer_blocks.23.attn1.to_q/aten::linear/MatMul
1356 __module.transformer.transformer_blocks.23.attn1.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1114 __module.transformer.transformer_blocks.23.attn1.to_v/aten::linear/MatMul
1357 __module.transformer.transformer_blocks.23.attn1.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1875 __module.transformer.transformer_blocks.23.attn1.to_out.0/aten::linear/MatMul
1903 __module.transformer.transformer_blocks.23.attn1.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1115 __module.transformer.transformer_blocks.23.attn2.to_q/aten::linear/MatMul
1358 __module.transformer.transformer_blocks.23.attn2.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 641 __module.transformer.transformer_blocks.23.attn2.to_out.0/aten::linear/MatMul
957 __module.transformer.transformer_blocks.23.attn2.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 783 __module.transformer.transformer_blocks.23.ff.net.0.proj/aten::linear/MatMul
1117 __module.transformer.transformer_blocks.23.ff.net.0.proj/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1557 __module.transformer.transformer_blocks.23.ff.net.2/aten::linear/MatMul
1713 __module.transformer.transformer_blocks.23.ff.net.2/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1121 __module.transformer.transformer_blocks.24.attn1.to_k/aten::linear/MatMul
1363 __module.transformer.transformer_blocks.24.attn1.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1122 __module.transformer.transformer_blocks.24.attn1.to_q/aten::linear/MatMul
1364 __module.transformer.transformer_blocks.24.attn1.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1123 __module.transformer.transformer_blocks.24.attn1.to_v/aten::linear/MatMul
1365 __module.transformer.transformer_blocks.24.attn1.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1876 __module.transformer.transformer_blocks.24.attn1.to_out.0/aten::linear/MatMul
1904 __module.transformer.transformer_blocks.24.attn1.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1124 __module.transformer.transformer_blocks.24.attn2.to_q/aten::linear/MatMul
1366 __module.transformer.transformer_blocks.24.attn2.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 642 __module.transformer.transformer_blocks.24.attn2.to_out.0/aten::linear/MatMul
958 __module.transformer.transformer_blocks.24.attn2.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 791 __module.transformer.transformer_blocks.24.ff.net.0.proj/aten::linear/MatMul
1126 __module.transformer.transformer_blocks.24.ff.net.0.proj/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1563 __module.transformer.transformer_blocks.24.ff.net.2/aten::linear/MatMul
1718 __module.transformer.transformer_blocks.24.ff.net.2/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1130 __module.transformer.transformer_blocks.25.attn1.to_k/aten::linear/MatMul
1371 __module.transformer.transformer_blocks.25.attn1.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1131 __module.transformer.transformer_blocks.25.attn1.to_q/aten::linear/MatMul
1372 __module.transformer.transformer_blocks.25.attn1.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1132 __module.transformer.transformer_blocks.25.attn1.to_v/aten::linear/MatMul
1373 __module.transformer.transformer_blocks.25.attn1.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1877 __module.transformer.transformer_blocks.25.attn1.to_out.0/aten::linear/MatMul
1905 __module.transformer.transformer_blocks.25.attn1.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1133 __module.transformer.transformer_blocks.25.attn2.to_q/aten::linear/MatMul
1374 __module.transformer.transformer_blocks.25.attn2.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 643 __module.transformer.transformer_blocks.25.attn2.to_out.0/aten::linear/MatMul
959 __module.transformer.transformer_blocks.25.attn2.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 799 __module.transformer.transformer_blocks.25.ff.net.0.proj/aten::linear/MatMul
1135 __module.transformer.transformer_blocks.25.ff.net.0.proj/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1569 __module.transformer.transformer_blocks.25.ff.net.2/aten::linear/MatMul
1723 __module.transformer.transformer_blocks.25.ff.net.2/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1139 __module.transformer.transformer_blocks.26.attn1.to_k/aten::linear/MatMul
1379 __module.transformer.transformer_blocks.26.attn1.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1140 __module.transformer.transformer_blocks.26.attn1.to_q/aten::linear/MatMul
1380 __module.transformer.transformer_blocks.26.attn1.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1141 __module.transformer.transformer_blocks.26.attn1.to_v/aten::linear/MatMul
1381 __module.transformer.transformer_blocks.26.attn1.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1878 __module.transformer.transformer_blocks.26.attn1.to_out.0/aten::linear/MatMul
1906 __module.transformer.transformer_blocks.26.attn1.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1142 __module.transformer.transformer_blocks.26.attn2.to_q/aten::linear/MatMul
1382 __module.transformer.transformer_blocks.26.attn2.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 644 __module.transformer.transformer_blocks.26.attn2.to_out.0/aten::linear/MatMul
960 __module.transformer.transformer_blocks.26.attn2.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 807 __module.transformer.transformer_blocks.26.ff.net.0.proj/aten::linear/MatMul
1144 __module.transformer.transformer_blocks.26.ff.net.0.proj/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1575 __module.transformer.transformer_blocks.26.ff.net.2/aten::linear/MatMul
1728 __module.transformer.transformer_blocks.26.ff.net.2/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1148 __module.transformer.transformer_blocks.27.attn1.to_k/aten::linear/MatMul
1387 __module.transformer.transformer_blocks.27.attn1.to_k/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1149 __module.transformer.transformer_blocks.27.attn1.to_q/aten::linear/MatMul
1388 __module.transformer.transformer_blocks.27.attn1.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1150 __module.transformer.transformer_blocks.27.attn1.to_v/aten::linear/MatMul
1389 __module.transformer.transformer_blocks.27.attn1.to_v/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1879 __module.transformer.transformer_blocks.27.attn1.to_out.0/aten::linear/MatMul
1907 __module.transformer.transformer_blocks.27.attn1.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1151 __module.transformer.transformer_blocks.27.attn2.to_q/aten::linear/MatMul
1390 __module.transformer.transformer_blocks.27.attn2.to_q/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 645 __module.transformer.transformer_blocks.27.attn2.to_out.0/aten::linear/MatMul
961 __module.transformer.transformer_blocks.27.attn2.to_out.0/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 815 __module.transformer.transformer_blocks.27.ff.net.0.proj/aten::linear/MatMul
1153 __module.transformer.transformer_blocks.27.ff.net.0.proj/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1581 __module.transformer.transformer_blocks.27.ff.net.2/aten::linear/MatMul
1733 __module.transformer.transformer_blocks.27.ff.net.2/aten::linear/Add
INFO:nncf:Not adding activation input quantizer for operation: 1456 __module.transformer.proj_out/aten::linear/MatMul
1629 __module.transformer.proj_out/aten::linear/Add
Output()
Run Weights Compression#
Quantizing of the T5EncoderModel and AutoencoderKL does not
significantly improve inference performance but can lead to a
substantial degradation of accuracy. The weight compression will be
applied to footprint reduction.
%%skip not $to_quantize.value
if not INT4_TEXT_ENCODER_PATH.exists():
text_encoder = core.read_model(TEXT_ENCODER_PATH)
compressed_text_encoder = nncf.compress_weights(text_encoder, mode=nncf.CompressWeightsMode.INT4_SYM)
ov.save_model(compressed_text_encoder, INT4_TEXT_ENCODER_PATH)
if not INT4_VAE_DECODER_PATH.exists():
vae_decoder = core.read_model(VAE_DECODER_PATH)
compressed_vae_decoder = nncf.compress_weights(vae_decoder, mode=nncf.CompressWeightsMode.INT4_SYM)
ov.save_model(compressed_vae_decoder, INT4_VAE_DECODER_PATH)
INFO:nncf:Statistics of the bitwidth distribution:
┍━━━━━━━━━━━━━━━━┯━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┯━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┑
│ Num bits (N) │ % all parameters (layers) │ % ratio-defining parameters (layers) │
┝━━━━━━━━━━━━━━━━┿━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┿━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┥
│ 8 │ 3% (3 / 194) │ 0% (0 / 191) │
├────────────────┼─────────────────────────────┼────────────────────────────────────────┤
│ 4 │ 97% (191 / 194) │ 100% (191 / 191) │
┕━━━━━━━━━━━━━━━━┷━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┷━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┙
Output()
INFO:nncf:Statistics of the bitwidth distribution:
┍━━━━━━━━━━━━━━━━┯━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┯━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┑
│ Num bits (N) │ % all parameters (layers) │ % ratio-defining parameters (layers) │
┝━━━━━━━━━━━━━━━━┿━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┿━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┥
│ 8 │ 98% (37 / 40) │ 0% (0 / 3) │
├────────────────┼─────────────────────────────┼────────────────────────────────────────┤
│ 4 │ 2% (3 / 40) │ 100% (3 / 3) │
┕━━━━━━━━━━━━━━━━┷━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┷━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┙
Output()
Let’s compare the images generated by the original and optimized pipelines.
%%skip not $to_quantize.value
# Disable dynamic quantization due to the performance overhead for Diffusion models
optimized_transformer = core.compile_model(INT8_TRANSFORMER_OV_PATH, device.value, config={"DYNAMIC_QUANTIZATION_GROUP_SIZE":"0"})
optimized_text_encoder = core.compile_model(INT4_TEXT_ENCODER_PATH, device.value)
optimized_vae_decoder = core.compile_model(INT4_VAE_DECODER_PATH, device.value)
optimized_pipe = PixArtAlphaPipeline.from_pretrained("PixArt-alpha/PixArt-LCM-XL-2-1024-MS", use_safetensors=True)
optimized_pipe.__dict__["_internal_dict"]["_execution_device"] = optimized_pipe._execution_device # this is to avoid some problem that can occur in the pipeline
optimized_pipe.register_modules(
text_encoder=TextEncoderWrapper(optimized_text_encoder, optimized_pipe.text_encoder.dtype),
transformer=TransformerWrapper(optimized_transformer, optimized_pipe.transformer.config),
vae=VAEWrapper(optimized_vae_decoder, optimized_pipe.vae.config),
)
Loading pipeline components...: 0%| | 0/5 [00:00<?, ?it/s]
Some weights of the model checkpoint were not used when initializing PixArtTransformer2DModel:
['caption_projection.y_embedding']
Loading checkpoint shards: 0%| | 0/4 [00:00<?, ?it/s]
%%skip not $to_quantize.value
from pixart_quantization_helper import visualize_results
prompt = "A small cactus with a happy face in the Sahara desert."
generator = torch.Generator().manual_seed(42)
opt_image = optimized_pipe(prompt=prompt, guidance_scale=0.0, num_inference_steps=4, generator=generator).images[0]
visualize_results(image, opt_image)
/opt/home/k8sworker/ci-ai/cibuilds/jobs/ov-notebook/jobs/OVNotebookOps/builds/835/archive/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/diffusers/configuration_utils.py:140: FutureWarning: Accessing config attribute _execution_device directly via 'PixArtAlphaPipeline' object attribute is deprecated. Please access '_execution_device' over 'PixArtAlphaPipeline's config object instead, e.g. 'scheduler.config._execution_device'.
deprecate("direct config name access", "1.0.0", deprecation_message, standard_warn=False)
0%| | 0/4 [00:00<?, ?it/s]

Compare model file sizes#
%%skip not $to_quantize.value
from pixart_quantization_helper import compare_models_size
compare_models_size()
transformer_ir compression rate: 1.979
text_encoder compression rate: 4.514
vae_decoder compression rate: 2.012
Compare inference time of the FP16 and optimized pipelines#
To measure the inference performance of the FP16 and optimized
pipelines, we use mean inference time on 3 samples.
NOTE: For the most accurate performance estimation, it is recommended to run
benchmark_appin a terminal/command prompt after closing other applications.
%%skip not $to_quantize.value
from pixart_quantization_helper import compare_perf
compare_perf(pipe, optimized_pipe, validation_size=3)
FP16 pipeline: 46.334 seconds
Optimized pipeline: 40.080 seconds
Performance speed-up: 1.156
Interactive inference#
Please select below whether you would like to use the quantized models to launch the interactive demo.
from pixart_helper import get_pipeline_selection_option
use_quantized_models = get_pipeline_selection_option(optimized_pipe)
use_quantized_models
Checkbox(value=True, description='Use quantized models')
pipeline = optimized_pipe if use_quantized_models.value else pipe
def generate(prompt, seed, negative_prompt, num_inference_steps):
generator = torch.Generator().manual_seed(seed)
image = pipeline(prompt=prompt, negative_prompt=negative_prompt, num_inference_steps=num_inference_steps, generator=generator, guidance_scale=0.0).images[0]
return image
if not Path("gradio_helper.py").exists():
r = requests.get(url="https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/notebooks/pixart/gradio_helper.py")
open("gradio_helper.py", "w").write(r.text)
from gradio_helper import make_demo
demo = make_demo(fn=generate)
try:
demo.queue().launch(debug=False)
except Exception:
demo.queue().launch(debug=False, share=True)
# if you are launching remotely, specify server_name and server_port
# demo.launch(server_name='your server name', server_port='server port in int')
# Read more in the docs: https://gradio.app/docs/
Running on local URL: http://127.0.0.1:7860 To create a public link, set share=True in launch().
# please uncomment and run this cell for stopping gradio interface
# demo.close()