Infinite Zoom Stable Diffusion v2 and OpenVINO™¶
This Jupyter notebook can be launched after a local installation only.
Stable Diffusion v2 is the next generation of Stable Diffusion model a Text-to-Image latent diffusion model created by the researchers and engineers from Stability AI and LAION.
General diffusion models are machine learning systems that are trained to denoise random gaussian noise step by step, to get to a sample of interest, such as an image. Diffusion models have shown to achieve state-of-the-art results for generating image data. But one downside of diffusion models is that the reverse denoising process is slow. In addition, these models consume a lot of memory because they operate in pixel space, which becomes unreasonably expensive when generating high-resolution images. Therefore, it is challenging to train these models and also use them for inference. OpenVINO brings capabilities to run model inference on Intel hardware and opens the door to the fantastic world of diffusion models for everyone!
In previous notebooks, we already discussed how to run Text-to-Image generation and Image-to-Image generation using Stable Diffusion v1 and controlling its generation process using ControlNet. Now is turn of Stable Diffusion v2.
Stable Diffusion v2: What’s new?¶
The new stable diffusion model offers a bunch of new features inspired by the other models that have emerged since the introduction of the first iteration. Some of the features that can be found in the new model are:
The model comes with a new robust encoder, OpenCLIP, created by LAION and aided by Stability AI; this version v2 significantly enhances the produced photos over the V1 versions.
The model can now generate images in a 768x768 resolution, offering more information to be shown in the generated images.
The model finetuned with v-objective. The v-parameterization is particularly useful for numerical stability throughout the diffusion process to enable progressive distillation for models. For models that operate at higher resolution, it is also discovered that the v-parameterization avoids color shifting artifacts that are known to affect high resolution diffusion models, and in the video setting it avoids temporal color shifting that sometimes appears with epsilon-prediction used in Stable Diffusion v1.
The model also comes with a new diffusion model capable of running upscaling on the images generated. Upscaled images can be adjusted up to 4 times the original image. Provided as separated model, for more details please check stable-diffusion-x4-upscaler
The model comes with a new refined depth architecture capable of preserving context from prior generation layers in an image-to-image setting. This structure preservation helps generate images that preserving forms and shadow of objects, but with different content.
The model comes with an updated inpainting module built upon the previous model. This text-guided inpainting makes switching out parts in the image easier than before.
This notebook demonstrates how to convert and run Stable Diffusion v2 model using OpenVINO.
Notebook contains the following steps:
Create pipeline with PyTorch models using Diffusers library.
Convert models to OpenVINO IR format, using model conversion API.
Run Stable Diffusion v2 inpainting pipeline for generation infinity zoom video
Table of contents:¶
Stable Diffusion v2 Infinite Zoom Showcase¶
In this tutorial we consider how to use Stable Diffusion v2 model for generation sequence of images for infinite zoom video effect. To do this, we will need stabilityai/stable-diffusion-2-inpainting model.
In image editing, inpainting is a process of restoring missing parts of pictures. Most commonly applied to reconstructing old deteriorated images, removing cracks, scratches, dust spots, or red-eyes from photographs.
But with the power of AI and the Stable Diffusion model, inpainting can be used to achieve more than that. For example, instead of just restoring missing parts of an image, it can be used to render something entirely new in any part of an existing picture. Only your imagination limits it.
The workflow diagram explains how Stable Diffusion inpainting pipeline for inpainting works:
sd2-inpainting¶
The pipeline has a lot of common with Text-to-Image generation pipeline discussed in previous section. Additionally to text prompt, pipeline accepts input source image and mask which provides an area of image which should be modified. Masked image encoded by VAE encoder into latent diffusion space and concatenated with randomly generated (on initial step only) or produced by U-Net latent generated image representation and used as input for next step denoising.
Using this inpainting feature, decreasing image by certain margin and masking this border for every new frame we can create interesting Zoom Out video based on our prompt.
Prerequisites¶
install required packages
%pip install -q "diffusers>=0.14.0" "transformers>=4.25.1" gradio "openvino>=2023.1.0" --extra-index-url https://download.pytorch.org/whl/cpu
To work with Stable Diffusion v2, we will use Hugging Face
Diffusers library. To
experiment with Stable Diffusion models for Inpainting use case,
Diffusers exposes the
StableDiffusionInpaintPipeline
similar to the other Diffusers
pipelines.
The code below demonstrates how to create
StableDiffusionInpaintPipeline using
stable-diffusion-2-inpainting:
from diffusers import StableDiffusionInpaintPipeline, DPMSolverMultistepScheduler
model_id_inpaint = "stabilityai/stable-diffusion-2-inpainting"
pipe_inpaint = StableDiffusionInpaintPipeline.from_pretrained(model_id_inpaint)
scheduler_inpaint = DPMSolverMultistepScheduler.from_config(pipe_inpaint.scheduler.config)
2023-09-25 12:14:32.810031: I tensorflow/core/util/port.cc:110] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable TF_ENABLE_ONEDNN_OPTS=0. 2023-09-25 12:14:32.851215: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations. To enable the following instructions: AVX2 AVX512F AVX512_VNNI FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags. 2023-09-25 12:14:33.562760: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
Loading pipeline components...: 0%| | 0/6 [00:00<?, ?it/s]
import gc
text_encoder_inpaint = pipe_inpaint.text_encoder
text_encoder_inpaint.eval()
unet_inpaint = pipe_inpaint.unet
unet_inpaint.eval()
vae_inpaint = pipe_inpaint.vae
vae_inpaint.eval()
del pipe_inpaint
gc.collect();
Conversion part of model stayed remain as in Text-to-Image generation notebook. Except U-Net now has 9 channels, which now calculated like 4 for U-Net generated latents channels + 4 for latent representation of masked image + 1 channel resized mask.
from pathlib import Path
import torch
import numpy as np
import openvino as ov
sd2_inpainting_model_dir = Path("sd2_inpainting")
sd2_inpainting_model_dir.mkdir(exist_ok=True)
def cleanup_torchscript_cache():
"""
Helper for removing cached model representation
"""
torch._C._jit_clear_class_registry()
torch.jit._recursive.concrete_type_store = torch.jit._recursive.ConcreteTypeStore()
torch.jit._state._clear_class_state()
def convert_encoder(text_encoder: torch.nn.Module, ir_path:Path):
"""
Convert Text Encoder model to IR.
Function accepts pipeline, prepares example inputs for conversion
Parameters:
text_encoder (torch.nn.Module): text encoder PyTorch model
ir_path (Path): File for storing model
Returns:
None
"""
if not ir_path.exists():
input_ids = torch.ones((1, 77), dtype=torch.long)
# switch model to inference mode
text_encoder.eval()
# disable gradients calculation for reducing memory consumption
with torch.no_grad():
# export model
ov_model = ov.convert_model(
text_encoder, # model instance
example_input=input_ids, # example inputs for model tracing
input=([1,77],) # input shape for conversion
)
ov.save_model(ov_model, ir_path)
del ov_model
cleanup_torchscript_cache()
print('Text Encoder successfully converted to IR')
def convert_unet(unet:torch.nn.Module, ir_path:Path, num_channels:int = 4, width:int = 64, height:int = 64):
"""
Convert Unet model to IR format.
Function accepts pipeline, prepares example inputs for conversion
Parameters:
unet (torch.nn.Module): UNet PyTorch model
ir_path (Path): File for storing model
num_channels (int, optional, 4): number of input channels
width (int, optional, 64): input width
height (int, optional, 64): input height
Returns:
None
"""
dtype_mapping = {
torch.float32: ov.Type.f32,
torch.float64: ov.Type.f64
}
if not ir_path.exists():
# prepare inputs
encoder_hidden_state = torch.ones((2, 77, 1024))
latents_shape = (2, num_channels, width, height)
latents = torch.randn(latents_shape)
t = torch.from_numpy(np.array(1, dtype=np.float32))
unet.eval()
dummy_inputs = (latents, t, encoder_hidden_state)
input_info = []
for input_tensor in dummy_inputs:
shape = ov.PartialShape(tuple(input_tensor.shape))
element_type = dtype_mapping[input_tensor.dtype]
input_info.append((shape, element_type))
with torch.no_grad():
ov_model = ov.convert_model(
unet,
example_input=dummy_inputs,
input=input_info
)
ov.save_model(ov_model, ir_path)
del ov_model
cleanup_torchscript_cache()
print('U-Net successfully converted to IR')
def convert_vae_encoder(vae: torch.nn.Module, ir_path: Path, width:int = 512, height:int = 512):
"""
Convert VAE model to IR format.
VAE model, creates wrapper class for export only necessary for inference part,
prepares example inputs for onversion
Parameters:
vae (torch.nn.Module): VAE PyTorch model
ir_path (Path): File for storing model
width (int, optional, 512): input width
height (int, optional, 512): input height
Returns:
None
"""
class VAEEncoderWrapper(torch.nn.Module):
def __init__(self, vae):
super().__init__()
self.vae = vae
def forward(self, image):
return self.vae.encode(x=image)["latent_dist"].sample()
if not ir_path.exists():
vae_encoder = VAEEncoderWrapper(vae)
vae_encoder.eval()
image = torch.zeros((1, 3, width, height))
with torch.no_grad():
ov_model = ov.convert_model(vae_encoder, example_input=image, input=([1,3, width, height],))
ov.save_model(ov_model, ir_path)
del ov_model
cleanup_torchscript_cache()
print('VAE encoder successfully converted to IR')
def convert_vae_decoder(vae: torch.nn.Module, ir_path: Path, width:int = 64, height:int = 64):
"""
Convert VAE decoder model to IR format.
Function accepts VAE model, creates wrapper class for export only necessary for inference part,
prepares example inputs for conversion
Parameters:
vae (torch.nn.Module): VAE model
ir_path (Path): File for storing model
width (int, optional, 64): input width
height (int, optional, 64): input height
Returns:
None
"""
class VAEDecoderWrapper(torch.nn.Module):
def __init__(self, vae):
super().__init__()
self.vae = vae
def forward(self, latents):
return self.vae.decode(latents)
if not ir_path.exists():
vae_decoder = VAEDecoderWrapper(vae)
latents = torch.zeros((1, 4, width, height))
vae_decoder.eval()
with torch.no_grad():
ov_model = ov.convert_model(vae_decoder, example_input=latents, input=([1,4, width, height],))
ov.save_model(ov_model, ir_path)
del ov_model
cleanup_torchscript_cache()
print('VAE decoder successfully converted to IR')
TEXT_ENCODER_OV_PATH_INPAINT = sd2_inpainting_model_dir / "text_encoder.xml"
if not TEXT_ENCODER_OV_PATH_INPAINT.exists():
convert_encoder(text_encoder_inpaint, TEXT_ENCODER_OV_PATH_INPAINT)
else:
print(f"Text encoder will be loaded from {TEXT_ENCODER_OV_PATH_INPAINT}")
del text_encoder_inpaint
gc.collect();
Text encoder will be loaded from sd2_inpainting/text_encoder.xml
UNET_OV_PATH_INPAINT = sd2_inpainting_model_dir / 'unet.xml'
if not UNET_OV_PATH_INPAINT.exists():
convert_unet(unet_inpaint, UNET_OV_PATH_INPAINT, num_channels=9, width=64, height=64)
del unet_inpaint
gc.collect()
else:
del unet_inpaint
print(f"U-Net will be loaded from {UNET_OV_PATH_INPAINT}")
gc.collect();
U-Net will be loaded from sd2_inpainting/unet.xml
VAE_ENCODER_OV_PATH_INPAINT = sd2_inpainting_model_dir / 'vae_encoder.xml'
if not VAE_ENCODER_OV_PATH_INPAINT.exists():
convert_vae_encoder(vae_inpaint, VAE_ENCODER_OV_PATH_INPAINT, 512, 512)
else:
print(f"VAE encoder will be loaded from {VAE_ENCODER_OV_PATH_INPAINT}")
VAE_DECODER_OV_PATH_INPAINT = sd2_inpainting_model_dir / 'vae_decoder.xml'
if not VAE_DECODER_OV_PATH_INPAINT.exists():
convert_vae_decoder(vae_inpaint, VAE_DECODER_OV_PATH_INPAINT, 64, 64)
else:
print(f"VAE decoder will be loaded from {VAE_DECODER_OV_PATH_INPAINT}")
del vae_inpaint
gc.collect();
VAE encoder will be loaded from sd2_inpainting/vae_encoder.xml
VAE decoder will be loaded from sd2_inpainting/vae_decoder.xml
As it was discussed previously, Inpainting inference pipeline is based
on Text-to-Image inference pipeline with addition mask processing step.
We will reuse OVStableDiffusionPipeline basic utilities in
OVStableDiffusionInpaintingPipeline class.
import inspect
from typing import List, Optional, Union, Dict
import PIL
import cv2
from transformers import CLIPTokenizer
from diffusers import DiffusionPipeline
from diffusers.schedulers import DDIMScheduler, LMSDiscreteScheduler, PNDMScheduler
def prepare_mask_and_masked_image(image:PIL.Image.Image, mask:PIL.Image.Image):
"""
Prepares a pair (image, mask) to be consumed by the Stable Diffusion pipeline. This means that those inputs will be
converted to ``np.array`` with shapes ``batch x channels x height x width`` where ``channels`` is ``3`` for the
``image`` and ``1`` for the ``mask``.
The ``image`` will be converted to ``np.float32`` and normalized to be in ``[-1, 1]``. The ``mask`` will be
binarized (``mask > 0.5``) and cast to ``np.float32`` too.
Args:
image (Union[np.array, PIL.Image]): The image to inpaint.
It can be a ``PIL.Image``, or a ``height x width x 3`` ``np.array``
mask (_type_): The mask to apply to the image, i.e. regions to inpaint.
It can be a ``PIL.Image``, or a ``height x width`` ``np.array``.
Returns:
tuple[np.array]: The pair (mask, masked_image) as ``torch.Tensor`` with 4
dimensions: ``batch x channels x height x width``.
"""
if isinstance(image, (PIL.Image.Image, np.ndarray)):
image = [image]
if isinstance(image, list) and isinstance(image[0], PIL.Image.Image):
image = [np.array(i.convert("RGB"))[None, :] for i in image]
image = np.concatenate(image, axis=0)
elif isinstance(image, list) and isinstance(image[0], np.ndarray):
image = np.concatenate([i[None, :] for i in image], axis=0)
image = image.transpose(0, 3, 1, 2)
image = image.astype(np.float32) / 127.5 - 1.0
# preprocess mask
if isinstance(mask, (PIL.Image.Image, np.ndarray)):
mask = [mask]
if isinstance(mask, list) and isinstance(mask[0], PIL.Image.Image):
mask = np.concatenate([np.array(m.convert("L"))[None, None, :] for m in mask], axis=0)
mask = mask.astype(np.float32) / 255.0
elif isinstance(mask, list) and isinstance(mask[0], np.ndarray):
mask = np.concatenate([m[None, None, :] for m in mask], axis=0)
mask[mask < 0.5] = 0
mask[mask >= 0.5] = 1
masked_image = image * (mask < 0.5)
return mask, masked_image
/tmp/ipykernel_1292073/2055396221.py:8: FutureWarning: Importing DiffusionPipeline or ImagePipelineOutput from diffusers is deprecated. Please import from diffusers.pipelines.pipeline_utils instead. from diffusers import DiffusionPipeline
class OVStableDiffusionInpaintingPipeline(DiffusionPipeline):
def __init__(
self,
vae_decoder: ov.Model,
text_encoder: ov.Model,
tokenizer: CLIPTokenizer,
unet: ov.Model,
scheduler: Union[DDIMScheduler, PNDMScheduler, LMSDiscreteScheduler],
vae_encoder: ov.Model = None,
):
"""
Pipeline for text-to-image generation using Stable Diffusion.
Parameters:
vae_decoder (Model):
Variational Auto-Encoder (VAE) Model to decode images to and from latent representations.
text_encoder (Model):
Frozen text-encoder. Stable Diffusion uses the text portion of
[CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
the clip-vit-large-patch14(https://huggingface.co/openai/clip-vit-large-patch14) variant.
tokenizer (CLIPTokenizer):
Tokenizer of class CLIPTokenizer(https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
unet (Model): Conditional U-Net architecture to denoise the encoded image latents.
vae_encoder (Model):
Variational Auto-Encoder (VAE) Model to encode images to latent representation.
scheduler (SchedulerMixin):
A scheduler to be used in combination with unet to denoise the encoded image latents. Can be one of
DDIMScheduler, LMSDiscreteScheduler, or PNDMScheduler.
"""
super().__init__()
self.scheduler = scheduler
self.vae_decoder = vae_decoder
self.vae_encoder = vae_encoder
self.text_encoder = text_encoder
self.unet = unet
self._text_encoder_output = text_encoder.output(0)
self._unet_output = unet.output(0)
self._vae_d_output = vae_decoder.output(0)
self._vae_e_output = vae_encoder.output(0) if vae_encoder is not None else None
self.height = self.unet.input(0).shape[2] * 8
self.width = self.unet.input(0).shape[3] * 8
self.tokenizer = tokenizer
self.register_to_config(_progress_bar_config={})
def prepare_mask_latents(
self,
mask,
masked_image,
height=512,
width=512,
do_classifier_free_guidance=True,
):
"""
Prepare mask as Unet nput and encode input masked image to latent space using vae encoder
Parameters:
mask (np.array): input mask array
masked_image (np.array): masked input image tensor
heigh (int, *optional*, 512): generated image height
width (int, *optional*, 512): generated image width
do_classifier_free_guidance (bool, *optional*, True): whether to use classifier free guidance or not
Returns:
mask (np.array): resized mask tensor
masked_image_latents (np.array): masked image encoded into latent space using VAE
"""
mask = torch.nn.functional.interpolate(torch.from_numpy(mask), size=(height // 8, width // 8))
mask = mask.numpy()
# encode the mask image into latents space so we can concatenate it to the latents
latents = self.vae_encoder(masked_image)[self._vae_e_output]
masked_image_latents = latents * 0.18215
mask = np.concatenate([mask] * 2) if do_classifier_free_guidance else mask
masked_image_latents = (
np.concatenate([masked_image_latents] * 2)
if do_classifier_free_guidance
else masked_image_latents
)
return mask, masked_image_latents
def __call__(
self,
prompt: Union[str, List[str]],
image: PIL.Image.Image,
mask_image: PIL.Image.Image,
negative_prompt: Union[str, List[str]] = None,
num_inference_steps: Optional[int] = 50,
guidance_scale: Optional[float] = 7.5,
eta: Optional[float] = 0,
output_type: Optional[str] = "pil",
seed: Optional[int] = None,
):
"""
Function invoked when calling the pipeline for generation.
Parameters:
prompt (str or List[str]):
The prompt or prompts to guide the image generation.
image (PIL.Image.Image):
Source image for inpainting.
mask_image (PIL.Image.Image):
Mask area for inpainting
negative_prompt (str or List[str]):
The negative prompt or prompts to guide the image generation.
num_inference_steps (int, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (float, *optional*, defaults to 7.5):
Guidance scale as defined in Classifier-Free Diffusion Guidance(https://arxiv.org/abs/2207.12598).
guidance_scale is defined as `w` of equation 2.
Higher guidance scale encourages to generate images that are closely linked to the text prompt,
usually at the expense of lower image quality.
eta (float, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[DDIMScheduler], will be ignored for others.
output_type (`str`, *optional*, defaults to "pil"):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): PIL.Image.Image or np.array.
seed (int, *optional*, None):
Seed for random generator state initialization.
Returns:
Dictionary with keys:
sample - the last generated image PIL.Image.Image or np.array
"""
if seed is not None:
np.random.seed(seed)
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# get prompt text embeddings
text_embeddings = self._encode_prompt(
prompt,
do_classifier_free_guidance=do_classifier_free_guidance,
negative_prompt=negative_prompt,
)
# prepare mask
mask, masked_image = prepare_mask_and_masked_image(image, mask_image)
# set timesteps
accepts_offset = "offset" in set(
inspect.signature(self.scheduler.set_timesteps).parameters.keys()
)
extra_set_kwargs = {}
if accepts_offset:
extra_set_kwargs["offset"] = 1
self.scheduler.set_timesteps(num_inference_steps, **extra_set_kwargs)
timesteps, num_inference_steps = self.get_timesteps(num_inference_steps, 1)
latent_timestep = timesteps[:1]
# get the initial random noise unless the user supplied it
latents, meta = self.prepare_latents(latent_timestep)
mask, masked_image_latents = self.prepare_mask_latents(
mask,
masked_image,
do_classifier_free_guidance=do_classifier_free_guidance,
)
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(
inspect.signature(self.scheduler.step).parameters.keys()
)
extra_step_kwargs = {}
if accepts_eta:
extra_step_kwargs["eta"] = eta
for t in self.progress_bar(timesteps):
# expand the latents if we are doing classifier free guidance
latent_model_input = (
np.concatenate([latents] * 2)
if do_classifier_free_guidance
else latents
)
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
latent_model_input = np.concatenate(
[latent_model_input, mask, masked_image_latents], axis=1
)
# predict the noise residual
noise_pred = self.unet(
[latent_model_input, np.array(t, dtype=np.float32), text_embeddings]
)[self._unet_output]
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred[0], noise_pred[1]
noise_pred = noise_pred_uncond + guidance_scale * (
noise_pred_text - noise_pred_uncond
)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(
torch.from_numpy(noise_pred),
t,
torch.from_numpy(latents),
**extra_step_kwargs,
)["prev_sample"].numpy()
# scale and decode the image latents with vae
image = self.vae_decoder(latents * (1 / 0.18215))[self._vae_d_output]
image = self.postprocess_image(image, meta, output_type)
return {"sample": image}
def _encode_prompt(self, prompt:Union[str, List[str]], num_images_per_prompt:int = 1, do_classifier_free_guidance:bool = True, negative_prompt:Union[str, List[str]] = None):
"""
Encodes the prompt into text encoder hidden states.
Parameters:
prompt (str or list(str)): prompt to be encoded
num_images_per_prompt (int): number of images that should be generated per prompt
do_classifier_free_guidance (bool): whether to use classifier free guidance or not
negative_prompt (str or list(str)): negative prompt to be encoded
Returns:
text_embeddings (np.ndarray): text encoder hidden states
"""
batch_size = len(prompt) if isinstance(prompt, list) else 1
# tokenize input prompts
text_inputs = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="np",
)
text_input_ids = text_inputs.input_ids
text_embeddings = self.text_encoder(
text_input_ids)[self._text_encoder_output]
# duplicate text embeddings for each generation per prompt
if num_images_per_prompt != 1:
bs_embed, seq_len, _ = text_embeddings.shape
text_embeddings = np.tile(
text_embeddings, (1, num_images_per_prompt, 1))
text_embeddings = np.reshape(
text_embeddings, (bs_embed * num_images_per_prompt, seq_len, -1))
# get unconditional embeddings for classifier free guidance
if do_classifier_free_guidance:
uncond_tokens: List[str]
max_length = text_input_ids.shape[-1]
if negative_prompt is None:
uncond_tokens = [""] * batch_size
elif isinstance(negative_prompt, str):
uncond_tokens = [negative_prompt]
else:
uncond_tokens = negative_prompt
uncond_input = self.tokenizer(
uncond_tokens,
padding="max_length",
max_length=max_length,
truncation=True,
return_tensors="np",
)
uncond_embeddings = self.text_encoder(uncond_input.input_ids)[self._text_encoder_output]
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
seq_len = uncond_embeddings.shape[1]
uncond_embeddings = np.tile(uncond_embeddings, (1, num_images_per_prompt, 1))
uncond_embeddings = np.reshape(uncond_embeddings, (batch_size * num_images_per_prompt, seq_len, -1))
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
text_embeddings = np.concatenate([uncond_embeddings, text_embeddings])
return text_embeddings
def prepare_latents(self, latent_timestep:torch.Tensor = None):
"""
Function for getting initial latents for starting generation
Parameters:
latent_timestep (torch.Tensor, *optional*, None):
Predicted by scheduler initial step for image generation, required for latent image mixing with nosie
Returns:
latents (np.ndarray):
Image encoded in latent space
"""
latents_shape = (1, 4, self.height // 8, self.width // 8)
noise = np.random.randn(*latents_shape).astype(np.float32)
# if we use LMSDiscreteScheduler, let's make sure latents are mulitplied by sigmas
if isinstance(self.scheduler, LMSDiscreteScheduler):
noise = noise * self.scheduler.sigmas[0].numpy()
return noise, {}
def postprocess_image(self, image:np.ndarray, meta:Dict, output_type:str = "pil"):
"""
Postprocessing for decoded image. Takes generated image decoded by VAE decoder, unpad it to initila image size (if required),
normalize and convert to [0, 255] pixels range. Optionally, convertes it from np.ndarray to PIL.Image format
Parameters:
image (np.ndarray):
Generated image
meta (Dict):
Metadata obtained on latents preparing step, can be empty
output_type (str, *optional*, pil):
Output format for result, can be pil or numpy
Returns:
image (List of np.ndarray or PIL.Image.Image):
Postprocessed images
"""
if "padding" in meta:
pad = meta["padding"]
(_, end_h), (_, end_w) = pad[1:3]
h, w = image.shape[2:]
unpad_h = h - end_h
unpad_w = w - end_w
image = image[:, :, :unpad_h, :unpad_w]
image = np.clip(image / 2 + 0.5, 0, 1)
image = np.transpose(image, (0, 2, 3, 1))
# 9. Convert to PIL
if output_type == "pil":
image = self.numpy_to_pil(image)
if "src_height" in meta:
orig_height, orig_width = meta["src_height"], meta["src_width"]
image = [img.resize((orig_width, orig_height),
PIL.Image.Resampling.LANCZOS) for img in image]
else:
if "src_height" in meta:
orig_height, orig_width = meta["src_height"], meta["src_width"]
image = [cv2.resize(img, (orig_width, orig_width))
for img in image]
return image
def get_timesteps(self, num_inference_steps:int, strength:float):
"""
Helper function for getting scheduler timesteps for generation
In case of image-to-image generation, it updates number of steps according to strength
Parameters:
num_inference_steps (int):
number of inference steps for generation
strength (float):
value between 0.0 and 1.0, that controls the amount of noise that is added to the input image.
Values that approach 1.0 allow for lots of variations but will also produce images that are not semantically consistent with the input.
"""
# get the original timestep using init_timestep
init_timestep = min(int(num_inference_steps * strength), num_inference_steps)
t_start = max(num_inference_steps - init_timestep, 0)
timesteps = self.scheduler.timesteps[t_start:]
return timesteps, num_inference_steps - t_start
For achieving zoom effect, we will use inpainting to expand images
beyond their original borders. We run our
OVStableDiffusionInpaintingPipeline in the loop, where each next
frame will add edges to previous. The frame generation process
illustrated on diagram below:
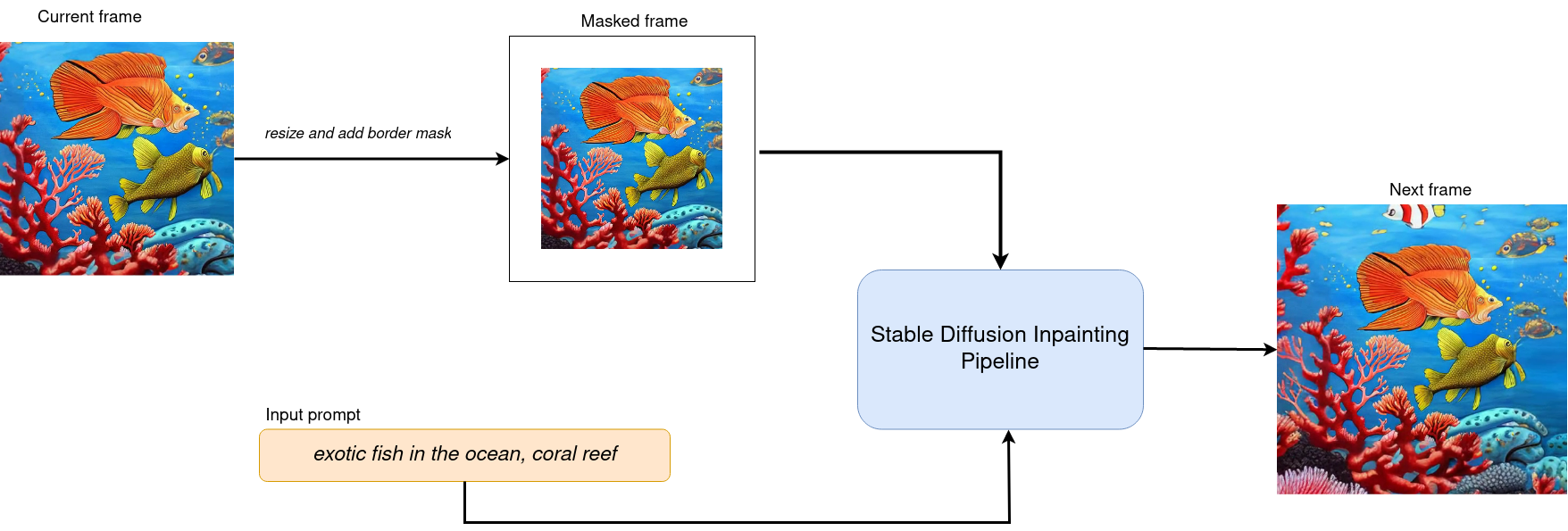
frame generation)¶
After processing current frame, we decrease size of current image by mask size pixels from each side and use it as input for next step. Changing size of mask we can influence the size of painting area and image scaling.
There are 2 zooming directions:
Zoom Out - move away from object
Zoom In - move closer to object
Zoom In will be processed in the same way as Zoom Out, but after generation is finished, we record frames in reversed order.
from tqdm import trange
def generate_video(
pipe:OVStableDiffusionInpaintingPipeline,
prompt:Union[str, List[str]],
negative_prompt:Union[str, List[str]],
guidance_scale:float = 7.5,
num_inference_steps:int = 20,
num_frames:int = 20,
mask_width:int = 128,
seed:int = 9999,
zoom_in:bool = False,
):
"""
Zoom video generation function
Parameters:
pipe (OVStableDiffusionInpaintingPipeline): inpainting pipeline.
prompt (str or List[str]): The prompt or prompts to guide the image generation.
negative_prompt (str or List[str]): The negative prompt or prompts to guide the image generation.
guidance_scale (float, *optional*, defaults to 7.5):
Guidance scale as defined in Classifier-Free Diffusion Guidance(https://arxiv.org/abs/2207.12598).
guidance_scale is defined as `w` of equation 2.
Higher guidance scale encourages to generate images that are closely linked to the text prompt,
usually at the expense of lower image quality.
num_inference_steps (int, *optional*, defaults to 50): The number of denoising steps for each frame. More denoising steps usually lead to a higher quality image at the expense of slower inference.
num_frames (int, *optional*, 20): number frames for video.
mask_width (int, *optional*, 128): size of border mask for inpainting on each step.
seed (int, *optional*, None): Seed for random generator state initialization.
zoom_in (bool, *optional*, False): zoom mode Zoom In or Zoom Out.
Returns:
output_path (str): Path where generated video loacated.
"""
height = 512
width = height
current_image = PIL.Image.new(mode="RGBA", size=(height, width))
mask_image = np.array(current_image)[:, :, 3]
mask_image = PIL.Image.fromarray(255 - mask_image).convert("RGB")
current_image = current_image.convert("RGB")
pipe.set_progress_bar_config(desc='Generating initial image...')
init_images = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
image=current_image,
guidance_scale=guidance_scale,
mask_image=mask_image,
seed=seed,
num_inference_steps=num_inference_steps,
)["sample"]
pipe.set_progress_bar_config()
image_grid(init_images, rows=1, cols=1)
num_outpainting_steps = num_frames
num_interpol_frames = 30
current_image = init_images[0]
all_frames = []
all_frames.append(current_image)
for i in trange(num_outpainting_steps, desc=f'Generating {num_outpainting_steps} additional images...'):
prev_image_fix = current_image
prev_image = shrink_and_paste_on_blank(current_image, mask_width)
current_image = prev_image
# create mask (black image with white mask_width width edges)
mask_image = np.array(current_image)[:, :, 3]
mask_image = PIL.Image.fromarray(255 - mask_image).convert("RGB")
# inpainting step
current_image = current_image.convert("RGB")
images = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
image=current_image,
guidance_scale=guidance_scale,
mask_image=mask_image,
seed=seed,
num_inference_steps=num_inference_steps,
)["sample"]
current_image = images[0]
current_image.paste(prev_image, mask=prev_image)
# interpolation steps bewteen 2 inpainted images (=sequential zoom and crop)
for j in range(num_interpol_frames - 1):
interpol_image = current_image
interpol_width = round((1 - (1 - 2 * mask_width / height) ** (1 - (j + 1) / num_interpol_frames)) * height / 2)
interpol_image = interpol_image.crop(
(
interpol_width,
interpol_width,
width - interpol_width,
height - interpol_width,
)
)
interpol_image = interpol_image.resize((height, width))
# paste the higher resolution previous image in the middle to avoid drop in quality caused by zooming
interpol_width2 = round((1 - (height - 2 * mask_width) / (height - 2 * interpol_width)) / 2 * height)
prev_image_fix_crop = shrink_and_paste_on_blank(prev_image_fix, interpol_width2)
interpol_image.paste(prev_image_fix_crop, mask=prev_image_fix_crop)
all_frames.append(interpol_image)
all_frames.append(current_image)
video_file_name = f"infinite_zoom_{'in' if zoom_in else 'out'}"
fps = 30
save_path = video_file_name + ".mp4"
write_video(save_path, all_frames, fps, reversed_order=zoom_in)
return save_path
def shrink_and_paste_on_blank(current_image:PIL.Image.Image, mask_width:int):
"""
Decreases size of current_image by mask_width pixels from each side,
then adds a mask_width width transparent frame,
so that the image the function returns is the same size as the input.
Parameters:
current_image (PIL.Image): input image to transform
mask_width (int): width in pixels to shrink from each side
Returns:
prev_image (PIL.Image): resized image with extended borders
"""
height = current_image.height
width = current_image.width
# shrink down by mask_width
prev_image = current_image.resize((height - 2 * mask_width, width - 2 * mask_width))
prev_image = prev_image.convert("RGBA")
prev_image = np.array(prev_image)
# create blank non-transparent image
blank_image = np.array(current_image.convert("RGBA")) * 0
blank_image[:, :, 3] = 1
# paste shrinked onto blank
blank_image[
mask_width : height - mask_width, mask_width : width - mask_width, :
] = prev_image
prev_image = PIL.Image.fromarray(blank_image)
return prev_image
def image_grid(imgs:List[PIL.Image.Image], rows:int, cols:int):
"""
Insert images to grid
Parameters:
imgs (List[PIL.Image.Image]): list of images for making grid
rows (int): number of rows in grid
cols (int): number of columns in grid
Returns:
grid (PIL.Image): image with input images collage
"""
assert len(imgs) == rows * cols
w, h = imgs[0].size
grid = PIL.Image.new("RGB", size=(cols * w, rows * h))
for i, img in enumerate(imgs):
grid.paste(img, box=(i % cols * w, i // cols * h))
return grid
def write_video(file_path:str, frames:List[PIL.Image.Image], fps:float, reversed_order:bool = True, gif:bool = True):
"""
Writes frames to an mp4 video file and optionaly to gif
Parameters:
file_path (str): Path to output video, must end with .mp4
frames (List of PIL.Image): list of frames
fps (float): Desired frame rate
reversed_order (bool): if order of images to be reversed (default = True)
gif (bool): save frames to gif format (default = True)
Returns:
None
"""
if reversed_order:
frames.reverse()
w, h = frames[0].size
fourcc = cv2.VideoWriter_fourcc("m", "p", "4", "v")
# fourcc = cv2.VideoWriter_fourcc(*'avc1')
writer = cv2.VideoWriter(file_path, fourcc, fps, (w, h))
for frame in frames:
np_frame = np.array(frame.convert("RGB"))
cv_frame = cv2.cvtColor(np_frame, cv2.COLOR_RGB2BGR)
writer.write(cv_frame)
writer.release()
if gif:
frames[0].save(
file_path.replace(".mp4", ".gif"),
save_all=True,
append_images=frames[1:],
duratiobn=len(frames) / fps,
loop=0,
)
Configuration steps: 1. Load models on device 2. Configure tokenizer and
scheduler 3. Create instance of OVStableDiffusionInpaintingPipeline
class
core = ov.Core()
tokenizer = CLIPTokenizer.from_pretrained('openai/clip-vit-large-patch14')
select device from dropdown list for running inference using OpenVINO
import ipywidgets as widgets
device = widgets.Dropdown(
options=core.available_devices + ["AUTO"],
value='AUTO',
description='Device:',
disabled=False,
)
device
Dropdown(description='Device:', index=2, options=('CPU', 'GNA', 'AUTO'), value='AUTO')
ov_config = {"INFERENCE_PRECISION_HINT": "f32"} if device.value != "CPU" else {}
text_enc_inpaint = core.compile_model(TEXT_ENCODER_OV_PATH_INPAINT, device.value)
unet_model_inpaint = core.compile_model(UNET_OV_PATH_INPAINT, device.value)
vae_decoder_inpaint = core.compile_model(VAE_DECODER_OV_PATH_INPAINT, device.value, ov_config)
vae_encoder_inpaint = core.compile_model(VAE_ENCODER_OV_PATH_INPAINT, device.value, ov_config)
ov_pipe_inpaint = OVStableDiffusionInpaintingPipeline(
tokenizer=tokenizer,
text_encoder=text_enc_inpaint,
unet=unet_model_inpaint,
vae_encoder=vae_encoder_inpaint,
vae_decoder=vae_decoder_inpaint,
scheduler=scheduler_inpaint,
)
import gradio as gr
from socket import gethostbyname, gethostname
def generate(
prompt,
negative_prompt,
seed,
steps,
frames,
edge_size,
zoom_in,
progress=gr.Progress(track_tqdm=True),
):
video_path = generate_video(
ov_pipe_inpaint,
prompt,
negative_prompt,
num_inference_steps=steps,
num_frames=frames,
mask_width=edge_size,
seed=seed,
zoom_in=zoom_in,
)
return video_path.replace(".mp4", ".gif")
gr.close_all()
demo = gr.Interface(
generate,
[
gr.Textbox(
"valley in the Alps at sunset, epic vista, beautiful landscape, 4k, 8k",
label="Prompt",
),
gr.Textbox("lurry, bad art, blurred, text, watermark", label="Negative prompt"),
gr.Slider(value=9999, label="Seed", maximum=10000000),
gr.Slider(value=20, label="Steps", minimum=1, maximum=50),
gr.Slider(value=3, label="Frames", minimum=1, maximum=50),
gr.Slider(value=128, label="Edge size", minimum=32, maximum=256),
gr.Checkbox(label="Zoom in"),
],
"image",
)
ipaddr = gethostbyname(gethostname())
demo.queue().launch(share=True)
Running on local URL: http://127.0.0.1:7860 Running on public URL: https://372deef95f8b1d0168.gradio.live This share link expires in 72 hours. For free permanent hosting and GPU upgrades, run gradio deploy from Terminal to deploy to Spaces (https://huggingface.co/spaces)