Speaker diarization¶
This Jupyter notebook can be launched after a local installation only.
Speaker diarization is the process of partitioning an audio stream containing human speech into homogeneous segments according to the identity of each speaker. It can enhance the readability of an automatic speech transcription by structuring the audio stream into speaker turns and, when used together with speaker recognition systems, by providing the speaker’s true identity. It is used to answer the question “who spoke when?”
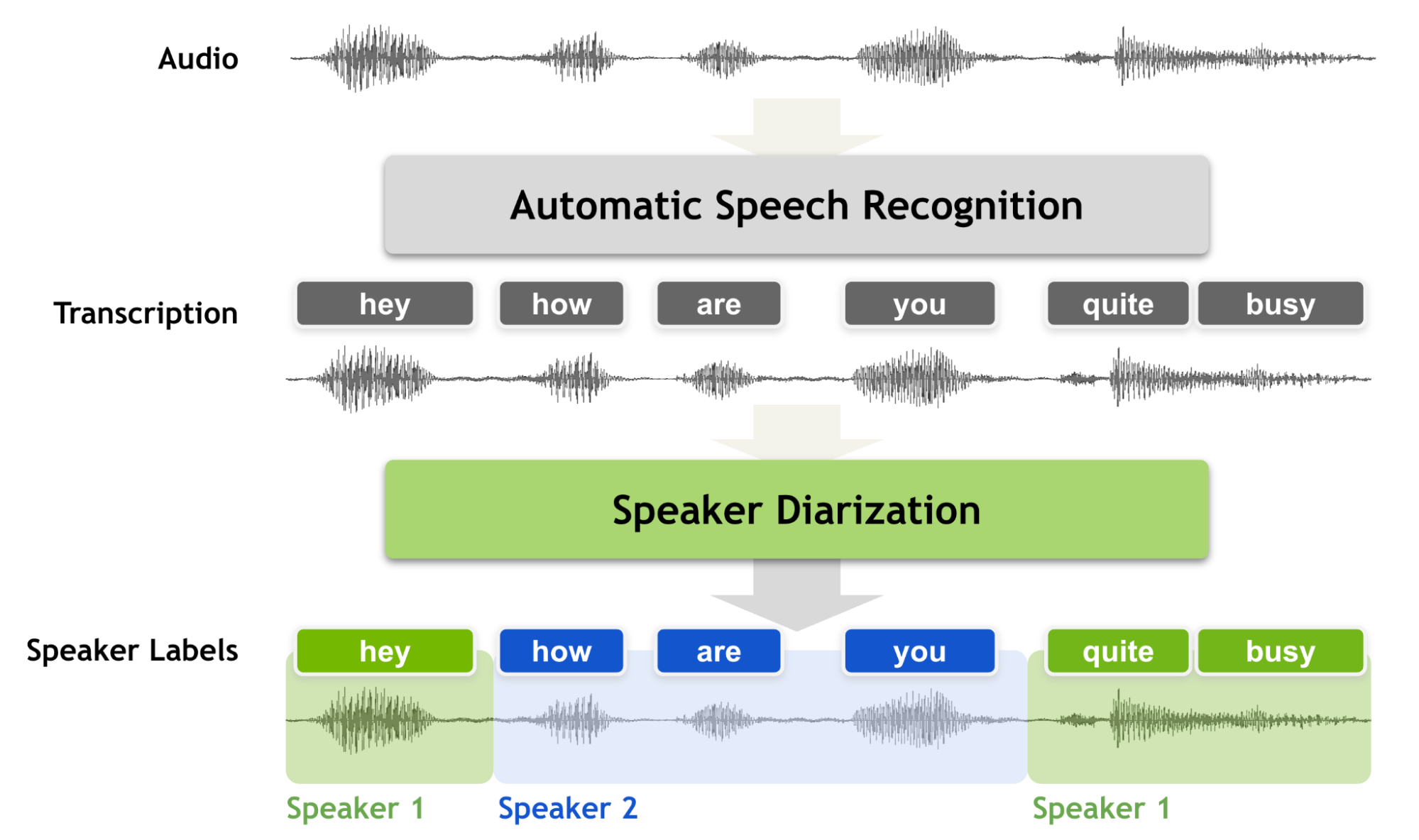
image.png¶
With the increasing number of broadcasts, meeting recordings and voice mail collected every year, speaker diarization has received much attention by the speech community. Speaker diarization is an essential feature for a speech recognition system to enrich the transcription with speaker labels.
Speaker diarization is used to increase transcript readability and better understand what a conversation is about. Speaker diarization can help extract important points or action items from the conversation and identify who said what. It also helps to identify how many speakers were on the audio.
This tutorial considers ways to build speaker diarization pipeline using
pyannote.audio and OpenVINO. pyannote.audio is an open-source
toolkit written in Python for speaker diarization. Based on PyTorch deep
learning framework, it provides a set of trainable end-to-end neural
building blocks that can be combined and jointly optimized to build
speaker diarization pipelines. You can find more information about
pyannote pre-trained models in model
card,
repo and
paper.
Table of contents:¶
Prerequisites¶
%pip install -q "librosa>=0.8.1" "matplotlib<3.8" "ruamel.yaml>=0.17.8,<0.17.29" --extra-index-url https://download.pytorch.org/whl/cpu torch torchvision torchaudio git+https://github.com/eaidova/pyannote-audio.git@hub0.10 openvino>=2023.1.0
DEPRECATION: pytorch-lightning 1.6.5 has a non-standard dependency specifier torch>=1.8.*. pip 24.1 will enforce this behaviour change. A possible replacement is to upgrade to a newer version of pytorch-lightning or contact the author to suggest that they release a version with a conforming dependency specifiers. Discussion can be found at https://github.com/pypa/pip/issues/12063
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
googleapis-common-protos 1.62.0 requires protobuf!=3.20.0,!=3.20.1,!=4.21.1,!=4.21.2,!=4.21.3,!=4.21.4,!=4.21.5,<5.0.0.dev0,>=3.19.5, but you have protobuf 3.20.1 which is incompatible.
onnx 1.15.0 requires protobuf>=3.20.2, but you have protobuf 3.20.1 which is incompatible.
paddlepaddle 2.6.0 requires protobuf>=3.20.2; platform_system != "Windows", but you have protobuf 3.20.1 which is incompatible.
ppgan 2.1.0 requires imageio==2.9.0, but you have imageio 2.33.1 which is incompatible.
ppgan 2.1.0 requires librosa==0.8.1, but you have librosa 0.9.2 which is incompatible.
ppgan 2.1.0 requires opencv-python<=4.6.0.66, but you have opencv-python 4.9.0.80 which is incompatible.
tensorflow 2.12.0 requires protobuf!=4.21.0,!=4.21.1,!=4.21.2,!=4.21.3,!=4.21.4,!=4.21.5,<5.0.0dev,>=3.20.3, but you have protobuf 3.20.1 which is incompatible.
tensorflow-metadata 1.14.0 requires protobuf<4.21,>=3.20.3, but you have protobuf 3.20.1 which is incompatible.
Note: you may need to restart the kernel to use updated packages.
Prepare pipeline¶
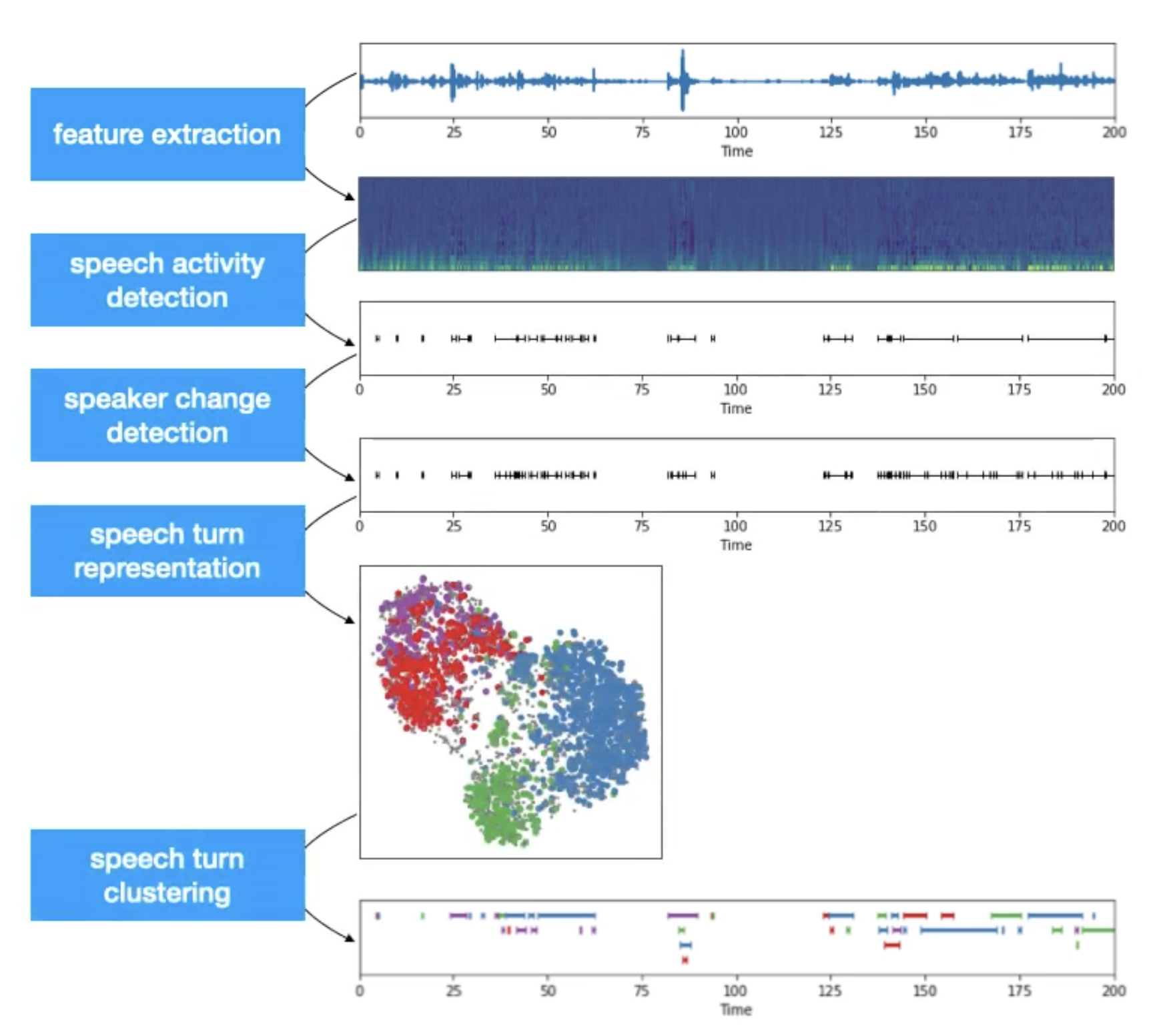
Traditional Speaker Diarization systems can be generalized into a five-step process:
Feature extraction: transform the raw waveform into audio features like mel spectrogram.
Voice activity detection: identify the chunks in the audio where some voice activity was observed. As we are not interested in silence and noise, we ignore those irrelevant chunks.
Speaker change detection: identify the speaker change points in the conversation present in the audio.
Speech turn representation: encode each subchunk by creating feature representations.
Speech turn clustering: cluster the subchunks based on their vector representation. Different clustering algorithms may be applied based on the availability of cluster count (k) and the embedding process of the previous step.
The final output will be the clusters of different subchunks from the audio stream. Each cluster can be given an anonymous identifier (speaker_a, ..) and then it can be mapped with the audio stream to create the speaker-aware audio timeline.
On the diagram, you can see a typical speaker diarization pipeline:
diarization_pipeline¶
From a simplified point of view, speaker diarization is a combination of speaker segmentation and speaker clustering. The first aims at finding speaker change points in an audio stream. The second aims at grouping together speech segments based on speaker characteristics.
For instantiating speaker diarization pipeline with pyannote.audio
library, we should import Pipeline class and use from_pretrained
method by providing a path to the directory with pipeline configuration
or identification from HuggingFace
hub.
NOTE: This tutorial uses a non-official version of model
philschmid/pyannote-speaker-diarization-endpoint, provided only for demo purposes. The original model (pyannote/speaker-diarization) requires you to accept the model license before downloading or using its weights, visit the pyannote/speaker-diarization to read accept the license before you proceed. To use this model, you must be a registered user in Hugging Face Hub. You will need to use an access token for the code below to run. For more information on access tokens, please refer to this section of the documentation. You can log in on HuggingFace Hub in the notebook environment using the following code:
## login to huggingfacehub to get access to pre-trained model
from huggingface_hub import notebook_login, whoami
try:
whoami()
print('Authorization token already provided')
except OSError:
notebook_login()
from pyannote.audio import Pipeline
pipeline = Pipeline.from_pretrained("philschmid/pyannote-speaker-diarization-endpoint")
Load test audio file¶
import sys
sys.path.append("../utils")
from notebook_utils import download_file
test_data_url = "https://github.com/pyannote/pyannote-audio/raw/develop/tutorials/assets/sample.wav"
sample_file = 'sample.wav'
download_file(test_data_url, 'sample.wav')
AUDIO_FILE = {'uri': sample_file.replace('.wav', ''), 'audio': sample_file}
sample.wav: 0%| | 0.00/938k [00:00<?, ?B/s]
import librosa
import matplotlib.pyplot as plt
import librosa.display
import IPython.display as ipd
audio, sr = librosa.load(sample_file)
plt.figure(figsize=(14, 5))
librosa.display.waveshow(audio, sr=sr)
ipd.Audio(sample_file)
Run inference pipeline¶
For running inference, we should provide a path to input audio to the pipeline
%%capture
import time
start = time.perf_counter()
diarization = pipeline(AUDIO_FILE)
end = time.perf_counter()
print(f"Diarization pipeline took {end - start:.2f} s")
Diarization pipeline took 15.72 s
The result of running the pipeline can be represented as a diagram indicating when each person speaks.
diarization

We can also print each time frame and corresponding speaker:
for turn, _, speaker in diarization.itertracks(yield_label=True):
print(f"start={turn.start:.1f}s stop={turn.end:.1f}s speaker_{speaker}")
start=6.7s stop=7.1s speaker_SPEAKER_00
start=7.6s stop=8.6s speaker_SPEAKER_00
start=8.6s stop=10.0s speaker_SPEAKER_02
start=9.8s stop=11.0s speaker_SPEAKER_00
start=10.6s stop=14.7s speaker_SPEAKER_02
start=14.3s stop=17.9s speaker_SPEAKER_01
start=17.9s stop=21.5s speaker_SPEAKER_02
start=18.3s stop=18.4s speaker_SPEAKER_01
start=21.7s stop=28.6s speaker_SPEAKER_01
start=27.8s stop=29.5s speaker_SPEAKER_02
Convert model to OpenVINO Intermediate Representation format¶
For best results with OpenVINO, it is recommended to convert the model
to OpenVINO IR format. OpenVINO supports PyTorch via ONNX conversion. We
will use torch.onnx.export for exporting the ONNX model from
PyTorch. We need to provide initialized model’s instance and example of
inputs for shape inference. We will use ov.convert_model
functionality to convert the ONNX models. The mo.convert_model
Python function returns an OpenVINO model ready to load on the device
and start making predictions. We can save it on disk for the next usage
with ov.save_model.
from pathlib import Path
import torch
import openvino as ov
core = ov.Core()
ov_speaker_segmentation_path = Path("pyannote-segmentation.xml")
if not ov_speaker_segmentation_path.exists():
onnx_path = ov_speaker_segmentation_path.with_suffix(".onnx")
torch.onnx.export(pipeline._segmentation.model, torch.zeros((1, 1, 80000)), onnx_path, input_names=["chunks"], output_names=["outputs"], dynamic_axes={"chunks": {0: "batch_size", 2: "wave_len"}})
ov_speaker_segmentation = ov.convert_model(onnx_path)
ov.save_model(ov_speaker_segmentation, str(ov_speaker_segmentation_path))
print(f"Model successfully converted to IR and saved to {ov_speaker_segmentation_path}")
else:
ov_speaker_segmentation = core.read_model(ov_speaker_segmentation_path)
print(f"Model successfully loaded from {ov_speaker_segmentation_path}")
Model successfully converted to IR and saved to pyannote-segmentation.xml
Select inference device¶
select device from dropdown list for running inference using OpenVINO
import ipywidgets as widgets
device = widgets.Dropdown(
options=core.available_devices + ["AUTO"],
value='AUTO',
description='Device:',
disabled=False,
)
device
Dropdown(description='Device:', index=1, options=('CPU', 'AUTO'), value='AUTO')
Replace segmentation model with OpenVINO¶
core = ov.Core()
ov_seg_model = core.compile_model(ov_speaker_segmentation, device.value)
infer_request = ov_seg_model.create_infer_request()
ov_seg_out = ov_seg_model.output(0)
import numpy as np
def infer_segm(chunks: torch.Tensor) -> np.ndarray:
"""
Inference speaker segmentation mode using OpenVINO
Parameters:
chunks (torch.Tensor) input audio chunks
Return:
segments (np.ndarray)
"""
res = ov_seg_model(chunks)
return res[ov_seg_out]
pipeline._segmentation.infer = infer_segm
Run speaker diarization with OpenVINO¶
start = time.perf_counter()
diarization = pipeline(AUDIO_FILE)
end = time.perf_counter()
print(f"Diarization pipeline took {end - start:.2f} s")
Diarization pipeline took 15.12 s
diarization

for turn, _, speaker in diarization.itertracks(yield_label=True):
print(f"start={turn.start:.1f}s stop={turn.end:.1f}s speaker_{speaker}")
start=6.7s stop=7.1s speaker_SPEAKER_00
start=7.6s stop=8.6s speaker_SPEAKER_00
start=8.6s stop=10.0s speaker_SPEAKER_02
start=9.8s stop=11.0s speaker_SPEAKER_00
start=10.6s stop=14.7s speaker_SPEAKER_02
start=14.3s stop=17.9s speaker_SPEAKER_01
start=17.9s stop=21.5s speaker_SPEAKER_02
start=18.3s stop=18.4s speaker_SPEAKER_01
start=21.7s stop=28.6s speaker_SPEAKER_01
start=27.8s stop=29.5s speaker_SPEAKER_02
Nice! As we can see, the result preserves the same level of accuracy!