Datumaro¶
Datumaro provides a suite of basic data import/export (IE) for more than 35 public vision data formats and manipulation functionalities such as validation, correction, filtration, and some transformations. To achieve the web-scale training, this further aims to merge multiple heterogeneous datasets through comparator and merger. Datumaro is integrated into Geti™, OpenVINO™ Training Extensions, and CVAT for the ease of data preparation. Datumaro is open-sourced and available on GitHub. Refer to the official documentation to learn more. Plus, enjoy Jupyter notebooks for the real Datumaro practices.
Detailed Workflow¶
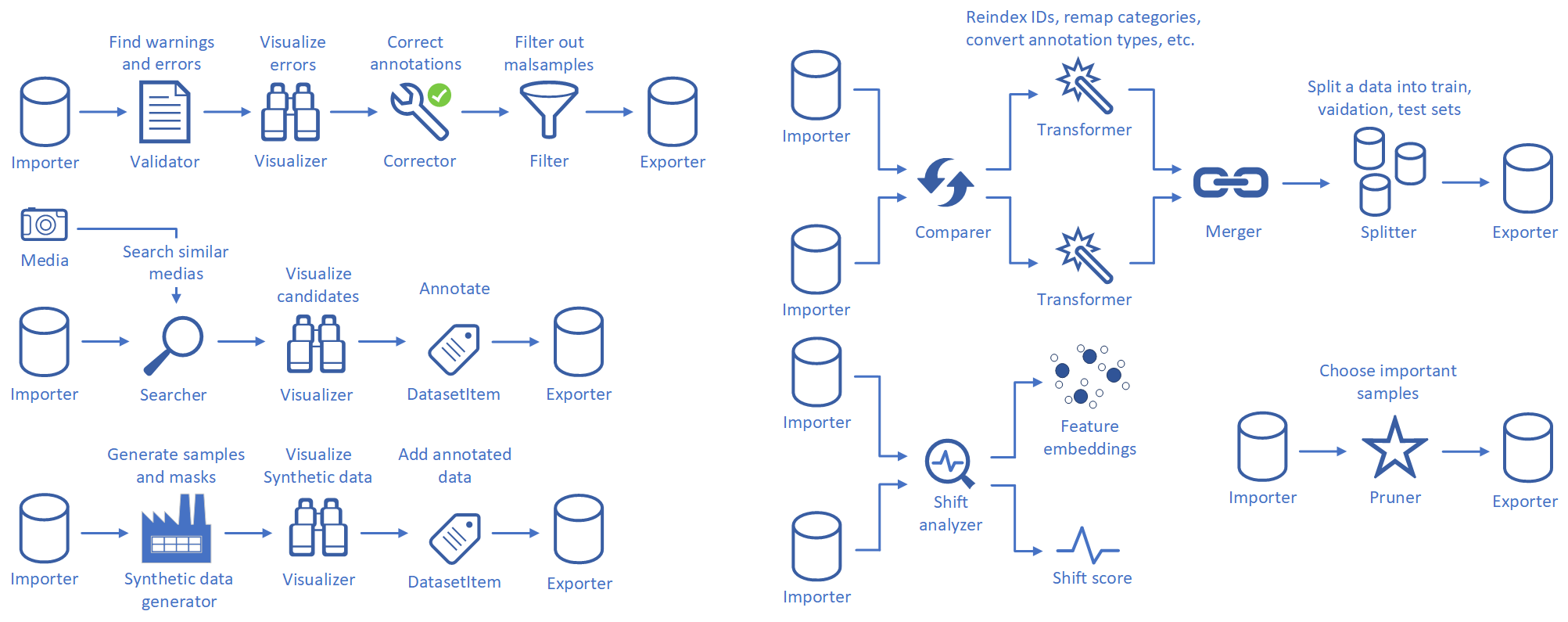
To start working with Datumaro, download public datasets or prepare your own annotated dataset.
Note
Datumaro provides a CLI datum download for downloading TensorFlow Datasets.
Import data into Datumaro and manipulate the dataset for the data quality using Validator, Corrector, and Filter.
Compare two datasets and transform the label schemas (category information) before merging them.
Merge two datasets to a large-scale dataset.
Note
There are some choices of merger, i.e., ExactMerger, IntersectMerger, and UnionMerger.
Split the unified dataset into subsets, e.g., train, valid, and test through Splitter.
Note
We can split data with a given ratio of subsets according to both the number of samples or annotations. Please see SplitTask for the task-specific split.
6. Export the cleaned and unified dataset for follow-up workflows such as model training. Go to OpenVINO™ Training Extensions.
If the results are unsatisfactory, add datasets and perform the same steps, starting with dataset annotation.