Audio compression with EnCodec and OpenVINO¶
This Jupyter notebook can be launched after a local installation only.
Compression is an important part of the Internet today because it enables people to easily share high-quality photos, listen to audio messages, stream their favorite shows, and so much more. Even when using today’s state-of-the-art techniques, enjoying these rich multimedia experiences requires a high speed Internet connection and plenty of storage space. AI helps to overcome these limitations: “Imagine listening to a friend’s audio message in an area with low connectivity and not having it stall or glitch.”
This tutorial considers ways to use OpenVINO and EnCodec algorithm for hyper compression of audio. EnCodec is a real-time, high-fidelity audio codec that uses AI to compress audio files without losing quality. It was introduced in High Fidelity Neural Audio Compression paper by Meta AI. The researchers claimed they achieved an approximate 10x compression rate without loss of quality and made it work for CD-quality audio. More details about this approach can be found in Meta AI blog and original repo.
image.png¶
Table of contents:¶
Prerequisites¶
Install required dependencies:
%pip install -q --extra-index-url https://download.pytorch.org/whl/cpu "openvino>=2023.3.0" "torch>=2.1" "torchaudio>=2.1" encodec gradio "librosa>=0.8.1"
DEPRECATION: pytorch-lightning 1.6.5 has a non-standard dependency specifier torch>=1.8.*. pip 24.1 will enforce this behaviour change. A possible replacement is to upgrade to a newer version of pytorch-lightning or contact the author to suggest that they release a version with a conforming dependency specifiers. Discussion can be found at https://github.com/pypa/pip/issues/12063
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
pyannote-audio 2.0.1 requires torchaudio<1.0,>=0.10, but you have torchaudio 2.2.0+cpu which is incompatible.
torchvision 0.14.1+cpu requires torch==1.13.1, but you have torch 2.2.0+cpu which is incompatible.
Note: you may need to restart the kernel to use updated packages.
Instantiate audio compression pipeline¶
Codecs, which act as encoders and decoders for streams of data, help empower most of the audio compression people currently use online. Some examples of commonly used codecs include MP3, Opus, and EVS. Classic codecs like these decompose the signal between different frequencies and encode as efficiently as possible. Most classic codecs leverage human hearing knowledge (psychoacoustics) but have a finite or given set of handcrafted ways to efficiently encode and decode the file. EnCodec, a neural network that is trained from end to end to reconstruct the input signal, was introduced as an attempt to overcome this limitation. It consists of three parts:
The encoder, which takes the uncompressed data in and transforms it into a higher dimensional and lower frame rate representation.
The quantizer, which compresses this representation to the target size. This compressed representation is what is stored on disk or will be sent through the network.
The decoder is the final step. It turns the compressed signal back into a waveform that is as similar as possible to the original. The key to lossless compression is to identify changes that will not be perceivable by humans, as perfect reconstruction is impossible at low bit rates.
)
The authors provide two multi-bandwidth models: *
encodec_model_24khz - a causal model operating at 24 kHz on
monophonic audio trained on a variety of audio data. *
encodec_model_48khz - a non-causal model operating at 48 kHz on
stereophonic audio trained on music-only data.
In this tutorial, we will use encodec_model_24khz as an example, but
the same actions are also applicable to encodec_model_48khz model as
well. To start working with this model, we need to instantiate model
class using EncodecModel.encodec_model_24khz() and select required
compression bandwidth among available: 1.5, 3, 6, 12 or 24 kbps for 24
kHz model and 3, 6, 12 and 24 kbps for 48 kHz model. We will use 6 kbps
bandwidth.
from encodec import compress, decompress
from encodec.utils import convert_audio, save_audio
from encodec.compress import MODELS
import torchaudio
import torch
import typing as tp
model_id = "encodec_24khz"
# Instantiate a pretrained EnCodec model
model = MODELS[model_id]()
model.set_target_bandwidth(6.0)
/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-609/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/torch/nn/utils/weight_norm.py:28: UserWarning: torch.nn.utils.weight_norm is deprecated in favor of torch.nn.utils.parametrizations.weight_norm.
warnings.warn("torch.nn.utils.weight_norm is deprecated in favor of torch.nn.utils.parametrizations.weight_norm.")
Explore EnCodec pipeline¶
Let us explore model capabilities on example audio:
import sys
import librosa
import matplotlib.pyplot as plt
import librosa.display
import IPython.display as ipd
sys.path.append("../utils")
from notebook_utils import download_file
test_data_url = "https://github.com/facebookresearch/encodec/raw/main/test_24k.wav"
sample_file = 'test_24k.wav'
download_file(test_data_url, sample_file)
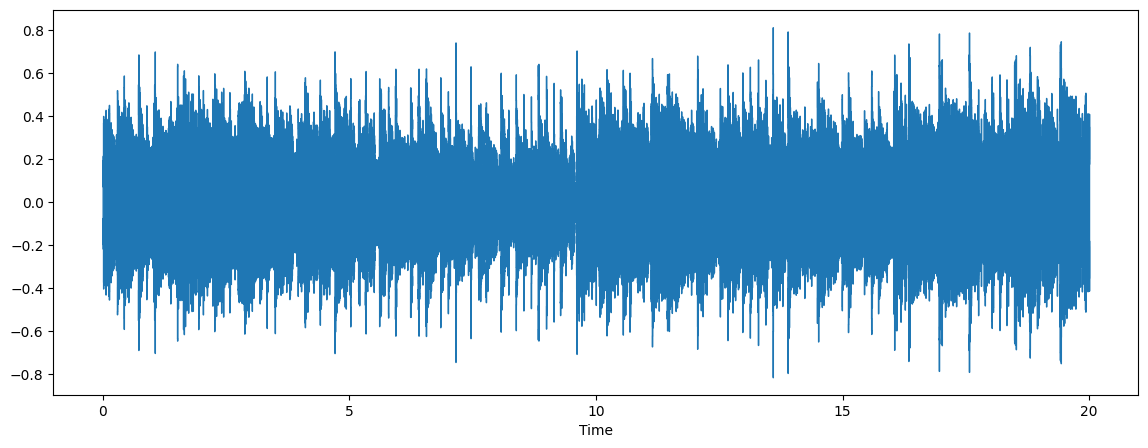
audio, sr = librosa.load(sample_file)
plt.figure(figsize=(14, 5))
librosa.display.waveshow(audio, sr=sr)
ipd.Audio(sample_file)
test_24k.wav: 0%| | 0.00/938k [00:00<?, ?B/s]
Preprocessing¶
To achieve the best result, audio should have the number of channels and
sample rate expected by the model. If audio does not fulfill these
requirements, it can be converted to the desired sample rate and the
number of channels using the convert_audio function.
model_sr, model_channels = model.sample_rate, model.channels
print(f"Model expected sample rate {model_sr}")
print(f"Model expected audio format {'mono' if model_channels == 1 else 'stereo'}")
Model expected sample rate 24000
Model expected audio format mono
# Load and pre-process the audio waveform
wav, sr = torchaudio.load(sample_file)
wav = convert_audio(wav, sr, model_sr, model_channels)
Encoding¶
Audio waveform should be split by chunks and then encoded by Encoder
model, then compressed by quantizer for reducing memory. The result of
compression is a binary file with ecdc extension, a special format
for storing EnCodec compressed audio on disc.
from pathlib import Path
out_file = Path("compressed.ecdc")
b = compress(model, wav)
out_file.write_bytes(b)
15067
Let us compare obtained compression result:
import os
orig_file_stats = os.stat(sample_file)
compressed_file_stats = os.stat("compressed.ecdc")
print(f"size before compression in Bytes: {orig_file_stats.st_size}")
print(f"size after compression in Bytes: {compressed_file_stats.st_size}")
print(f"Compression file size ratio: {orig_file_stats.st_size / compressed_file_stats.st_size:.2f}")
size before compression in Bytes: 960078
size after compression in Bytes: 15067
Compression file size ratio: 63.72
Great! Now, we see the power of hyper compression. Binary size of a file becomes 60 times smaller and more suitable for sending via network.
Decompression¶
After successful sending of the compressed audio, it should be decompressed on the recipient’s side. The decoder model is responsible for restoring the compressed signal back into a waveform that is as similar as possible to the original.
out, out_sr = decompress(out_file.read_bytes())
/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-609/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/torch/nn/utils/weight_norm.py:28: UserWarning: torch.nn.utils.weight_norm is deprecated in favor of torch.nn.utils.parametrizations.weight_norm.
warnings.warn("torch.nn.utils.weight_norm is deprecated in favor of torch.nn.utils.parametrizations.weight_norm.")
output_file = "decopressed.wav"
save_audio(out, output_file, out_sr)
The decompressed audio will be saved to the decompressed.wav file
when decompression is finished. We can compare result with the original
audio.
audio, sr = librosa.load(output_file)
plt.figure(figsize=(14, 5))
librosa.display.waveshow(audio, sr=sr)
ipd.Audio(output_file)
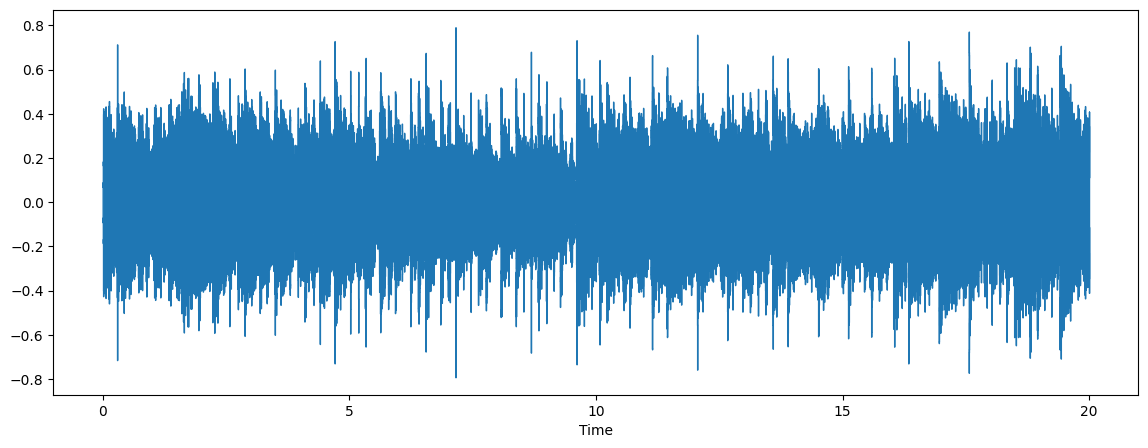
Nice! Audio sounds close to original.
Convert model to OpenVINO Intermediate Representation format¶
For best results with OpenVINO, it is recommended to convert the model
to OpenVINO IR format. OpenVINO supports PyTorch via conversion to
OpenVINO IR format. We need to provide initialized model’s instance and
example of inputs for shape inference. We will use ov.convert_model
functionality to convert the PyTorch models. The ov.convert_model
Python function returns an OpenVINO model ready to load on the device
and start making predictions. We can save it on disk for the next usage
with ov.save_model.
class FrameEncoder(torch.nn.Module):
def __init__(self, model):
super().__init__()
self.model = model
def forward(self, x: torch.Tensor):
codes, scale = self.model._encode_frame(x)
if not self.model.normalize:
return codes
return codes, scale
class FrameDecoder(torch.nn.Module):
def __init__(self, model):
super().__init__()
self.model = model
def forward(self, codes, scale=None):
return model._decode_frame((codes, scale))
encoder = FrameEncoder(model)
decoder = FrameDecoder(model)
import openvino as ov
core = ov.Core()
OV_ENCODER_PATH = Path("encodec_encoder.xml")
if not OV_ENCODER_PATH.exists():
encoder_ov = ov.convert_model(encoder, example_input=torch.zeros(1, 1, 480000), input=[[1, 1, 480000]])
ov.save_model(encoder_ov, OV_ENCODER_PATH)
else:
encoder_ov = core.read_model(OV_ENCODER_PATH)
/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-609/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/encodec/modules/conv.py:60: TracerWarning: Converting a tensor to a Python float might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
ideal_length = (math.ceil(n_frames) - 1) * stride + (kernel_size - padding_total)
/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-609/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/encodec/modules/conv.py:85: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
assert padding_left >= 0 and padding_right >= 0, (padding_left, padding_right)
/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-609/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/encodec/modules/conv.py:87: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
max_pad = max(padding_left, padding_right)
/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-609/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/encodec/modules/conv.py:89: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
if length <= max_pad:
OV_DECODER_PATH = Path("encodec_decoder.xml")
if not OV_DECODER_PATH.exists():
decoder_ov = ov.convert_model(decoder, example_input=torch.zeros([1, 8, 1500], dtype=torch.long), input=[[1, 8, 1500]])
ov.save_model(decoder_ov, OV_DECODER_PATH)
else:
decoder_ov = core.read_model(OV_DECODER_PATH)
/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-609/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/encodec/quantization/core_vq.py:358: TracerWarning: torch.tensor results are registered as constants in the trace. You can safely ignore this warning if you use this function to create tensors out of constant variables that would be the same every time you call this function. In any other case, this might cause the trace to be incorrect.
quantized_out = torch.tensor(0.0, device=q_indices.device)
/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-609/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/encodec/quantization/core_vq.py:359: TracerWarning: Iterating over a tensor might cause the trace to be incorrect. Passing a tensor of different shape won't change the number of iterations executed (and might lead to errors or silently give incorrect results).
for i, indices in enumerate(q_indices):
/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-609/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/encodec/modules/conv.py:103: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
assert (padding_left + padding_right) <= x.shape[-1]
Integrate OpenVINO to EnCodec pipeline¶
The following steps are required for integration of OpenVINO to EnCodec pipeline:
Load the model to a device.
Define audio frame processing functions.
Replace the original frame processing functions with OpenVINO based algorithms.
Select inference device¶
select device from dropdown list for running inference using OpenVINO
import ipywidgets as widgets
device = widgets.Dropdown(
options=core.available_devices + ["AUTO"],
value='AUTO',
description='Device:',
disabled=False,
)
device
Dropdown(description='Device:', index=1, options=('CPU', 'AUTO'), value='AUTO')
compiled_encoder = core.compile_model(encoder_ov, device.value)
encoder_out = compiled_encoder.output(0)
compiled_decoder = core.compile_model(decoder_ov, device.value)
decoder_out = compiled_decoder.output(0)
def encode_frame(x: torch.Tensor):
has_scale = len(compiled_encoder.outputs) == 2
result = compiled_encoder(x)
codes = torch.from_numpy(result[encoder_out])
if has_scale:
scale = torch.from_numpy(result[compiled_encoder.output(1)])
else:
scale = None
return codes, scale
EncodedFrame = tp.Tuple[torch.Tensor, tp.Optional[torch.Tensor]]
def decode_frame(encoded_frame: EncodedFrame):
codes, scale = encoded_frame
inputs = [codes]
if scale is not None:
inputs.append(scale)
return torch.from_numpy(compiled_decoder(inputs)[decoder_out])
model._encode_frame = encode_frame
model._decode_frame = decode_frame
MODELS[model_id] = lambda : model
Run EnCodec with OpenVINO¶
The process of running encodec with OpenVINO under hood will be the same like with the original PyTorch models.
b = compress(model, wav, use_lm=False)
out_file = Path("compressed_ov.ecdc")
out_file.write_bytes(b)
15067
out, out_sr = decompress(out_file.read_bytes())
ov_output_file = "decopressed_ov.wav"
save_audio(out, ov_output_file, out_sr)
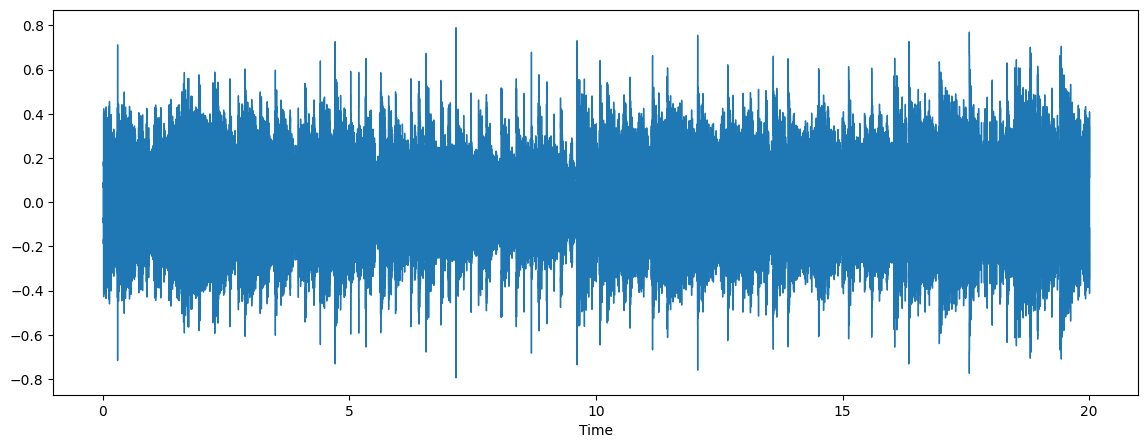
audio, sr = librosa.load(ov_output_file)
plt.figure(figsize=(14, 5))
librosa.display.waveshow(audio, sr=sr)
ipd.Audio(ov_output_file)
import gradio as gr
from typing import Tuple
import numpy as np
def preprocess(input, sample_rate, model_sr, model_channels):
input = torch.tensor(input, dtype=torch.float32)
input = input / 2**15 # adjust to int16 scale
input = input.unsqueeze(0)
input = convert_audio(input, sample_rate, model_sr, model_channels)
return input
def postprocess(output):
output = output.squeeze()
output = output * 2**15 # adjust to [-1, 1] scale
output = output.numpy(force=True)
output = output.astype(np.int16)
return output
def _compress(input: Tuple[int, np.ndarray]):
sample_rate, waveform = input
waveform = preprocess(waveform, sample_rate, model_sr, model_channels)
b = compress(model, waveform, use_lm=False)
out, out_sr = decompress(b)
out = postprocess(out)
return out_sr, out
demo = gr.Interface(
_compress,
'audio',
'audio',
examples=['test_24k.wav']
)
try:
demo.launch(debug=False)
except Exception:
demo.launch(share=True, debug=False)
# if you are launching remotely, specify server_name and server_port
# demo.launch(server_name='your server name', server_port='server port in int')
# Read more in the docs: https://gradio.app/docs/
Running on local URL: http://127.0.0.1:7860 To create a public link, set share=True in launch().