Optical Character Recognition with Directed Acyclic Graph¶
This document demonstrates how to create and use an Optical Character Recognition (OCR) pipeline based on east-resnet50 text detection model, text-recognition combined with a custom node implementation.
Using such a pipeline, a single request to OVMS can perform a complex set of operations with a response containing recognized characters for all detected text boxes.
OCR Graph¶
Below is depicted the graph implementing complete OCR pipelines.
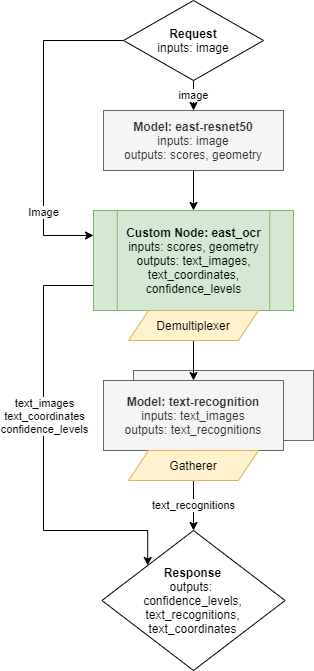
It includes the following nodes:
Model east-resnet50 - inference execution which takes the user image as input. It returns two outputs including information about all detected boxes, their location and scores.
Custom node east_ocr - it includes C++ implementation of east-resnet50 model results processing. It analyses the detected boxes coordinates, filters the results based on the configurable score level threshold and and applies non-max suppression algorithm to remove overlapping boxes. Finally the custom node east-ocr crops all detected boxes from the original image, resize them to the target resolution and combines into a single output of a dynamic batch size. The output batch size is determined by the number of detected boxes according to the configured criteria. All operations on the images employ OpenCV libraries which are preinstalled in the OVMS. Learn more about the east_ocr custom node
demultiplexer - output from the Custom node east_ocr have variable batch size. In order to match it with the sequential text detection model, the data is split into individual images with batch size 1 each. Such smaller requests can be submitted for inference in parallel to the next Model Node. Learn more about the demultiplexing
Model text-recognition - this model recognizes characters included in the input image.
Response - the output of the whole pipeline combines the recognized
image_textswith their metadata. The metadata are thetext_coordinatesand theconfidence_leveloutputs.
Preparing the Models¶
East-resnet50 model¶
The original pretrained model for east-resnet50 topology is stored on https://github.com/argman/EAST in TensorFlow checkpoint format.
Clone GitHub repository:
git clone https://github.com/argman/EAST
cd EAST
Download and unzip the file east_icdar2015_resnet_v1_50_rbox.zip as instructed in the Readme.md file to EAST folder with the GitHub repository.
unzip ./east_icdar2015_resnet_v1_50_rbox.zip
Inside the EAST folder add a file freeze_east_model.py by executing the following echo command from the command line:
echo "from tensorflow.python.framework import graph_util
import tensorflow as tf
import model
def export_model(input_checkpoint, output_graph):
with tf.get_default_graph().as_default():
input_images = tf.placeholder(tf.float32, shape=[None, None, None, 3], name='input_images')
global_step = tf.get_variable('global_step', [], initializer=tf.constant_initializer(0), trainable=False)
f_score, f_geometry = model.model(input_images, is_training=False)
graph = tf.get_default_graph()
input_graph_def = graph.as_graph_def()
init_op = tf.global_variables_initializer()
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(init_op)
saver.restore(sess, input_checkpoint)
output_graph_def = graph_util.convert_variables_to_constants(sess=sess, input_graph_def=input_graph_def, output_node_names=['feature_fusion/concat_3','feature_fusion/Conv_7/Sigmoid'])
with tf.gfile.GFile(output_graph, 'wb') as f:
f.write(output_graph_def.SerializeToString())
export_model('./east_icdar2015_resnet_v1_50_rbox/model.ckpt-49491','./model.pb')" >> freeze_east_model.py
cd ..
Freeze the model in checkpoint format and save it in proto buffer format in model.pb:
docker run -u $(id -u):$(id -g) -v ${PWD}/EAST/:/EAST:rw -w /EAST tensorflow/tensorflow:1.15.5 python3 freeze_east_model.py
Convert the TensorFlow frozen model to Intermediate Representation format using the model_optimizer tool:
docker run -u $(id -u):$(id -g) -v ${PWD}/EAST/:/EAST:rw openvino/ubuntu20_dev:2022.1.0 mo \
--framework=tf --input_shape=[1,1024,1920,3] --input=input_images --output=feature_fusion/Conv_7/Sigmoid,feature_fusion/concat_3 \
--input_model /EAST/model.pb --output_dir /EAST/IR/1/
It will create model files in ${PWD}/EAST/IR/1/ folder.
EAST/IR/1/
├── model.bin
├── model.mapping
└── model.xml
Converted east-resnet50 model will have the following interface:
Input name:
input_images; shape:[1 1024 1920 3]; precision:FP32; layout:N...Output name:
feature_fusion/Conv_7/Sigmoid; shape:[1 256 480 1]; precision:FP32; layout:N...Output name:
feature_fusion/concat_3; shape:[1 256 480 5]; precision:FP32; layout:N...
Text-recognition model¶
Download text-recognition model and store it in ${PWD}/text-recognition/1 folder.
curl -L --create-dir https://storage.openvinotoolkit.org/repositories/open_model_zoo/2022.1/models_bin/2/text-recognition-0014/FP32/text-recognition-0014.bin -o text-recognition/1/model.bin https://storage.openvinotoolkit.org/repositories/open_model_zoo/2022.1/models_bin/2/text-recognition-0014/FP32/text-recognition-0014.xml -o text-recognition/1/model.xml
chmod -R 755 text-recognition/
text-recognition model will have the following interface:
Input name:
imgs; shape:[1 1 32 128]; precision:FP32, layout:N...Output name:
logits; shape:[16 1 37]; precision:FP32
Building the Custom Node “east_ocr” Library¶
Custom nodes are loaded into OVMS as dynamic library implementing OVMS API from custom_node_interface.h. It can use OpenCV libraries included in OVMS or it could use other third party components.
The custom node east_ocr can be built inside a docker container via the following procedure:
go to the directory with custom node examples src/custom_node
run
makecommand:
git clone https://github.com/openvinotoolkit/model_server.git
cd model_server/src/custom_nodes
# replace to 'redhat` if using UBI base image
export BASE_OS=ubuntu
make NODES=east_ocr BASE_OS=${BASE_OS}
cd ../../../
This command will export the compiled library in ./lib folder.
Copy this lib folder to the same location with text-recognition and east_icdar2015_resnet_v1_50_rbox.
mkdir -p OCR/east_fp32 OCR/lib
cp -R model_server/src/custom_nodes/lib/${BASE_OS}/libcustom_node_east_ocr.so OCR/lib/
cp -R text-recognition OCR/text-recognition
cp -R EAST/IR/1 OCR/east_fp32/1
OVMS Configuration File¶
The configuration file for running the OCR demo is stored in config.json Copy this file along with the model files and the custom node library like presented below:
cp model_server/demos/optical_character_recognition/python/config.json OCR
OCR
├── config.json
├── east_fp32
│ └── 1
│ ├── model.bin
│ └── model.xml
├── lib
│ └── libcustom_node_east_ocr.so
└── text-recognition
└── 1
├── model.bin
└── model.xml
NOTE: east_fp32 model created before 2022.1 requires additional parameters in config.json:
layout: {"input_images": "NHWC:NCHW", "feature_fusion/Conv_7/Sigmoid": "NHWC:NCHW", "feature_fusion/concat_3": "NHWC:NCHW"}
Deploying OVMS¶
Deploy OVMS with OCR demo pipeline using the following command:
docker run -p 9000:9000 -d -v ${PWD}/OCR:/OCR openvino/model_server --config_path /OCR/config.json --port 9000
Requesting the Service¶
Enter optical_character_recognition directory
cd model_server/demos/optical_character_recognition/python
Install python dependencies:
pip3 install -r requirements.txt
Now you can create a directory for text images and run the client:
mkdir results
python3 optical_character_recognition.py --grpc_port 9000 --image_input_path demo_images/input.jpg --pipeline_name detect_text_images --text_images_save_path ./results/ --image_layout NHWC
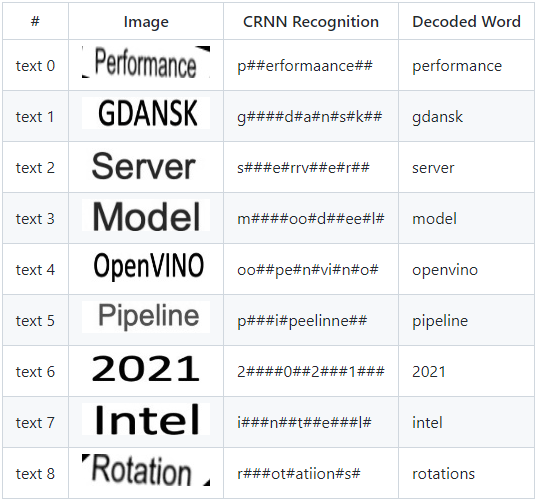
Output: name[confidence_levels]
numpy => shape[(9, 1, 1)] data[float32]
Output: name[texts]
numpy => shape[(9, 16, 1, 37)] data[float32]
performance
gdansk
server
model
openvino
pipeline
2021
intel
rotations
Output: name[text_images]
numpy => shape[(9, 1, 32, 128, 1)] data[float32]
Output: name[text_coordinates]
numpy => shape[(9, 1, 4)] data[int32]
With additional parameter --text_images_save_path the client script saves all detected text images to jpeg files into directory path to confirm
if the image was analyzed correctly.
Below is the exemplary input image.

The custom node generates the following text images retrieved from the original input to CRNN model:
Accuracy¶
Please note that it is possible to swap the models included in DAG with your own to adjust pipeline accuracy for various scenarios and datasets.