Live Inference and Benchmark CT-scan Data with OpenVINO™¶
This Jupyter notebook can be launched on-line, opening an interactive environment in a browser window. You can also make a local installation. Choose one of the following options:
Kidney Segmentation with PyTorch Lightning and OpenVINO™ - Part 4¶
This tutorial is a part of a series on how to train, optimize, quantize and show live inference on a medical segmentation model. The goal is to accelerate inference on a kidney segmentation model. The UNet model is trained from scratch, and the data is from Kits19.
This tutorial shows how to benchmark performance of the model and show live inference with async API and MULTI plugin in OpenVINO.
This notebook needs a quantized OpenVINO IR model and images from the KiTS-19 dataset, converted to 2D images. (To learn how the model is quantized, see the Convert and Quantize a UNet Model and Show Live Inference tutorial.)
This notebook provides a pre-trained model, trained for 20 epochs with the full KiTS-19 frames dataset, which has an F1 score on the validation set of 0.9. The training code is available in the PyTorch MONAI Training notebook.
For demonstration purposes, this tutorial will download one converted CT scan to use for inference.
Table of contents:¶
%pip install -q "openvino>=2023.1.0" "monai>=0.9.1,<1.0.0" "nncf>=2.5.0"
Note: you may need to restart the kernel to use updated packages.
Imports¶
import os
import sys
import zipfile
from pathlib import Path
import numpy as np
from monai.transforms import LoadImage
import openvino as ov
from custom_segmentation import SegmentationModel
sys.path.append("../utils")
from notebook_utils import download_file
2024-02-09 22:50:38.323593: I tensorflow/core/util/port.cc:110] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable TF_ENABLE_ONEDNN_OPTS=0. 2024-02-09 22:50:38.357752: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations. To enable the following instructions: AVX2 AVX512F AVX512_VNNI FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
2024-02-09 22:50:38.922511: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
Settings¶
To use the pre-trained models, set IR_PATH to
"pretrained_model/unet44.xml" and COMPRESSED_MODEL_PATH to
"pretrained_model/quantized_unet44.xml". To use a model that you
trained or optimized yourself, adjust the model paths.
# The directory that contains the IR model (xml and bin) files.
models_dir = Path('pretrained_model')
ir_model_url = 'https://storage.openvinotoolkit.org/repositories/openvino_notebooks/models/kidney-segmentation-kits19/FP16-INT8/'
ir_model_name_xml = 'quantized_unet_kits19.xml'
ir_model_name_bin = 'quantized_unet_kits19.bin'
download_file(ir_model_url + ir_model_name_xml, filename=ir_model_name_xml, directory=models_dir)
download_file(ir_model_url + ir_model_name_bin, filename=ir_model_name_bin, directory=models_dir)
MODEL_PATH = models_dir / ir_model_name_xml
# Uncomment the next line to use the FP16 model instead of the quantized model.
# MODEL_PATH = "pretrained_model/unet_kits19.xml"
pretrained_model/quantized_unet_kits19.xml: 0%| | 0.00/280k [00:00<?, ?B/s]
pretrained_model/quantized_unet_kits19.bin: 0%| | 0.00/1.90M [00:00<?, ?B/s]
Benchmark Model Performance¶
To measure the inference
performance of the IR model, use Benchmark
Tool
- an inference performance measurement tool in OpenVINO. Benchmark tool
is a command-line application that can be run in the notebook with
! benchmark_app or %sx benchmark_app commands.
NOTE: The
benchmark_apptool is able to measure the performance of the OpenVINO Intermediate Representation (OpenVINO IR) models only. For more accurate performance, runbenchmark_appin a terminal/command prompt after closing other applications. Runbenchmark_app -m model.xml -d CPUto benchmark async inference on CPU for one minute. ChangeCPUtoGPUto benchmark on GPU. Runbenchmark_app --helpto see an overview of all command-line options.
core = ov.Core()
# By default, benchmark on MULTI:CPU,GPU if a GPU is available, otherwise on CPU.
device_list = ["MULTI:CPU,GPU" if "GPU" in core.available_devices else "AUTO"]
import ipywidgets as widgets
device = widgets.Dropdown(
options=core.available_devices + device_list,
value=device_list[0],
description='Device:',
disabled=False,
)
device
Dropdown(description='Device:', index=1, options=('CPU', 'AUTO'), value='AUTO')
# Benchmark model
! benchmark_app -m $MODEL_PATH -d $device.value -t 15 -api sync
[Step 1/11] Parsing and validating input arguments
[ INFO ] Parsing input parameters
[Step 2/11] Loading OpenVINO Runtime
[ INFO ] OpenVINO:
[ INFO ] Build ................................. 2023.3.0-13775-ceeafaf64f3-releases/2023/3
[ INFO ]
[ INFO ] Device info:
[ INFO ] AUTO
[ INFO ] Build ................................. 2023.3.0-13775-ceeafaf64f3-releases/2023/3
[ INFO ]
[ INFO ]
[Step 3/11] Setting device configuration
[ WARNING ] Performance hint was not explicitly specified in command line. Device(AUTO) performance hint will be set to PerformanceMode.LATENCY.
[Step 4/11] Reading model files
[ INFO ] Loading model files
[ INFO ] Read model took 13.02 ms
[ INFO ] Original model I/O parameters:
[ INFO ] Model inputs:
[ INFO ] input.1 (node: input.1) : f32 / [...] / [1,1,512,512]
[ INFO ] Model outputs:
[ INFO ] 153 (node: 153) : f32 / [...] / [1,1,512,512]
[Step 5/11] Resizing model to match image sizes and given batch
[ INFO ] Model batch size: 1
[Step 6/11] Configuring input of the model
[ INFO ] Model inputs:
[ INFO ] input.1 (node: input.1) : f32 / [N,C,H,W] / [1,1,512,512]
[ INFO ] Model outputs:
[ INFO ] 153 (node: 153) : f32 / [...] / [1,1,512,512]
[Step 7/11] Loading the model to the device
[ INFO ] Compile model took 232.64 ms
[Step 8/11] Querying optimal runtime parameters
[ INFO ] Model:
[ INFO ] NETWORK_NAME: pretrained_unet_kits19
[ INFO ] EXECUTION_DEVICES: ['CPU']
[ INFO ] PERFORMANCE_HINT: PerformanceMode.LATENCY
[ INFO ] OPTIMAL_NUMBER_OF_INFER_REQUESTS: 1
[ INFO ] MULTI_DEVICE_PRIORITIES: CPU
[ INFO ] CPU:
[ INFO ] AFFINITY: Affinity.CORE
[ INFO ] CPU_DENORMALS_OPTIMIZATION: False
[ INFO ] CPU_SPARSE_WEIGHTS_DECOMPRESSION_RATE: 1.0
[ INFO ] ENABLE_CPU_PINNING: True
[ INFO ] ENABLE_HYPER_THREADING: False
[ INFO ] EXECUTION_DEVICES: ['CPU']
[ INFO ] EXECUTION_MODE_HINT: ExecutionMode.PERFORMANCE
[ INFO ] INFERENCE_NUM_THREADS: 12
[ INFO ] INFERENCE_PRECISION_HINT: <Type: 'float32'>
[ INFO ] NETWORK_NAME: pretrained_unet_kits19
[ INFO ] NUM_STREAMS: 1
[ INFO ] OPTIMAL_NUMBER_OF_INFER_REQUESTS: 1
[ INFO ] PERFORMANCE_HINT: LATENCY
[ INFO ] PERFORMANCE_HINT_NUM_REQUESTS: 0
[ INFO ] PERF_COUNT: NO
[ INFO ] SCHEDULING_CORE_TYPE: SchedulingCoreType.ANY_CORE
[ INFO ] MODEL_PRIORITY: Priority.MEDIUM
[ INFO ] LOADED_FROM_CACHE: False
[Step 9/11] Creating infer requests and preparing input tensors
[ WARNING ] No input files were given for input 'input.1'!. This input will be filled with random values!
[ INFO ] Fill input 'input.1' with random values
[Step 10/11] Measuring performance (Start inference synchronously, limits: 15000 ms duration)
[ INFO ] Benchmarking in inference only mode (inputs filling are not included in measurement loop).
[ INFO ] First inference took 24.68 ms
[Step 11/11] Dumping statistics report
[ INFO ] Execution Devices:['CPU']
[ INFO ] Count: 1366 iterations
[ INFO ] Duration: 15004.33 ms
[ INFO ] Latency:
[ INFO ] Median: 10.75 ms
[ INFO ] Average: 10.80 ms
[ INFO ] Min: 10.53 ms
[ INFO ] Max: 12.59 ms
[ INFO ] Throughput: 91.04 FPS
Download and Prepare Data¶
Download one validation video for live inference.
This tutorial reuses the KitsDataset class that was also used in the
training and quantization notebook that will be released later.
The data is expected in BASEDIR. The BASEDIR directory should
contain the case_00000 to case_00299 subdirectories. If the data
for the case specified above does not already exist, it will be
downloaded and extracted in the next cell.
# Directory that contains the CT scan data. This directory should contain subdirectories
# case_00XXX where XXX is between 000 and 299.
BASEDIR = Path("kits19_frames_1")
# The CT scan case number. For example: 16 for data from the case_00016 directory.
# Currently only 117 is supported.
CASE = 117
case_path = BASEDIR / f"case_{CASE:05d}"
if not case_path.exists():
filename = download_file(
f"https://storage.openvinotoolkit.org/data/test_data/openvino_notebooks/kits19/case_{CASE:05d}.zip"
)
with zipfile.ZipFile(filename, "r") as zip_ref:
zip_ref.extractall(path=BASEDIR)
os.remove(filename) # remove zipfile
print(f"Downloaded and extracted data for case_{CASE:05d}")
else:
print(f"Data for case_{CASE:05d} exists")
case_00117.zip: 0%| | 0.00/5.48M [00:00<?, ?B/s]
Downloaded and extracted data for case_00117
Show Live Inference¶
To show live inference on the model in the notebook, use the asynchronous processing feature of OpenVINO Runtime.
If you use a GPU device, with device="GPU" or
device="MULTI:CPU,GPU" to do inference on an integrated graphics
card, model loading will be slow the first time you run this code. The
model will be cached, so after the first time model loading will be
faster. For more information on OpenVINO Runtime, including Model
Caching, refer to the OpenVINO API
tutorial.
We will use
AsyncInferQueue
to perform asynchronous inference. It can be instantiated with compiled
model and a number of jobs - parallel execution threads. If you don’t
pass a number of jobs or pass 0, then OpenVINO will pick the optimal
number based on your device and heuristics. After acquiring the
inference queue, there are two jobs to do:
Preprocess the data and push it to the inference queue. The preprocessing steps will remain the same.
Tell the inference queue what to do with the model output after the inference is finished. It is represented by the
callbackpython function that takes an inference result and data that we passed to the inference queue along with the prepared input data
Everything else will be handled by the AsyncInferQueue instance.
Load the segmentation model to OpenVINO Runtime with
SegmentationModel, based on the Model API from Open Model
Zoo. This model
implementation includes pre and post processing for the model. For
SegmentationModel this includes the code to create an overlay of the
segmentation mask on the original image/frame. Uncomment the next cell
to see the implementation.
core = ov.Core()
segmentation_model = SegmentationModel(
ie=core, model_path=Path(MODEL_PATH), sigmoid=True, rotate_and_flip=True
)
image_paths = sorted(case_path.glob("imaging_frames/*jpg"))
print(f"{case_path.name}, {len(image_paths)} images")
case_00117, 69 images
Use the reader = LoadImage() function to read the images in the same
way as in the
training
tutorial.
framebuf = []
next_frame_id = 0
reader = LoadImage(image_only=True, dtype=np.uint8)
while next_frame_id < len(image_paths) - 1:
image_path = image_paths[next_frame_id]
image = reader(str(image_path))
framebuf.append(image)
next_frame_id += 1
device
Dropdown(description='Device:', index=1, options=('CPU', 'AUTO'), value='AUTO')
When callback is set, any job that ends the inference, calls the
Python function. The callback function must have two arguments: one
is the request that calls the callback, which provides the
InferRequest API; the other is called userdata, which provides
the possibility of passing runtime values.
The callback function will show the results of inference.
import cv2
import copy
from IPython import display
from typing import Dict, Any
# Define a callback function that runs every time the asynchronous pipeline completes inference on a frame
def completion_callback(infer_request: ov.InferRequest, user_data: Dict[str, Any],) -> None:
preprocess_meta = user_data['preprocess_meta']
raw_outputs = {out.any_name: copy.deepcopy(res.data) for out, res in zip(infer_request.model_outputs, infer_request.output_tensors)}
frame = segmentation_model.postprocess(raw_outputs, preprocess_meta)
_, encoded_img = cv2.imencode(".jpg", frame, params=[cv2.IMWRITE_JPEG_QUALITY, 90])
# Create IPython image
i = display.Image(data=encoded_img)
# Display the image in this notebook
display.clear_output(wait=True)
display.display(i)
import time
load_start_time = time.perf_counter()
compiled_model = core.compile_model(segmentation_model.net, device.value)
# Create asynchronous inference queue with optimal number of infer requests
infer_queue = ov.AsyncInferQueue(compiled_model)
infer_queue.set_callback(completion_callback)
load_end_time = time.perf_counter()
results = [None] * len(framebuf)
frame_number = 0
# Perform inference on every frame in the framebuffer
start_time = time.time()
for i, input_frame in enumerate(framebuf):
inputs, preprocessing_meta = segmentation_model.preprocess({segmentation_model.net.input(0): input_frame})
infer_queue.start_async(inputs, {'preprocess_meta': preprocessing_meta})
# Wait until all inference requests in the AsyncInferQueue are completed
infer_queue.wait_all()
stop_time = time.time()
# Calculate total inference time and FPS
total_time = stop_time - start_time
fps = len(framebuf) / total_time
time_per_frame = 1 / fps
print(f"Loaded model to {device} in {load_end_time-load_start_time:.2f} seconds.")
print(f'Total time to infer all frames: {total_time:.3f}s')
print(f'Time per frame: {time_per_frame:.6f}s ({fps:.3f} FPS)')
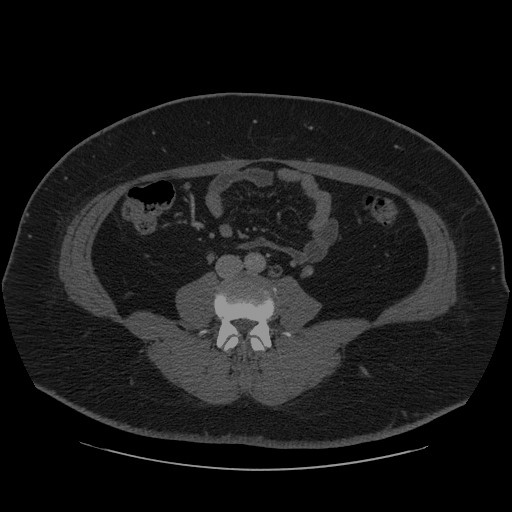
Loaded model to Dropdown(description='Device:', index=1, options=('CPU', 'AUTO'), value='AUTO') in 0.23 seconds.
Total time to infer all frames: 2.588s
Time per frame: 0.038061s (26.274 FPS)