Performance Benchmarks¶
This page presents benchmark results for Intel® Distribution of OpenVINO™ toolkit and OpenVINO Model Server, for a representative selection of public neural networks and Intel® devices. The results may help you decide which hardware to use in your applications or plan AI workload for the hardware you have already implemented in your solutions. Click the buttons below to see the chosen benchmark data.
Please visit the tabs below for more information on key performance indicators and workload parameters.
Measures the number of inferences delivered within a latency threshold (for example, number of Frames Per Second - FPS). When deploying a system with deep learning inference, select the throughput that delivers the best trade-off between latency and power for the price and performance that meets your requirements.
While throughput is important, what is more critical in edge AI deployments is the performance efficiency or performance-per-cost. Application performance in throughput per dollar of system cost is the best measure of value. The value KPI is calculated as “Throughput measured as inferences per second / price of inference engine”. This means for a 2 socket system 2x the price of a CPU is used. Prices are as per date of benchmarking and sources can be found as links in the Hardware Platforms (PDF) description below.
System power is a key consideration from the edge to the data center. When selecting deep learning solutions, power efficiency (throughput/watt) is a critical factor to consider. Intel designs provide excellent power efficiency for running deep learning workloads. The efficiency KPI is calculated as “Throughput measured as inferences per second / TDP of inference engine”. This means for a 2 socket system 2x the power dissipation (TDP) of a CPU is used. TDP-values are as per date of benchmarking and sources can be found as links in the Hardware Platforms (PDF) description below.
This measures the synchronous execution of inference requests and is reported in milliseconds. Each inference request (for example: preprocess, infer, postprocess) is allowed to complete before the next is started. This performance metric is relevant in usage scenarios where a single image input needs to be acted upon as soon as possible. An example would be the healthcare sector where medical personnel only request analysis of a single ultra sound scanning image or in real-time or near real-time applications for example an industrial robot’s response to actions in its environment or obstacle avoidance for autonomous vehicles.
The workload parameters affect the performance results of the different models we use for benchmarking. Image processing models have different image size definitions and the Natural Language Processing models have different max token list lengths. All these can be found in detail in the FAQ section. All models are executed using a batch size of 1. Below are the parameters for the GenAI models we display.
Input tokens: 1024,
Output tokens: 128,
number of beams: 1
For text to image:
iteration steps: 20,
image size (HxW): 256 x 256,
input token length: 1024 (the tokens for GenAI models are in English).
Platforms, Configurations, Methodology¶
For a listing of all platforms and configurations used for testing, refer to the following:
The OpenVINO benchmark setup includes a single system with OpenVINO™, as well as the benchmark application installed. It measures the time spent on actual inference (excluding any pre or post processing) and then reports on the inferences per second (or Frames Per Second).
OpenVINO™ Model Server (OVMS) employs the Intel® Distribution of OpenVINO™ toolkit runtime libraries and exposes a set of models via a convenient inference API over gRPC or HTTP/REST. Its benchmark results are measured with the configuration of multiple-clients-single-server, using two hardware platforms connected by ethernet. Network bandwidth depends on both, platforms and models under investigation. It is set not to be a bottleneck for workload intensity. The connection is dedicated only to measuring performance.
See more details about OVMS benchmark setup
The benchmark setup for OVMS consists of four main parts:
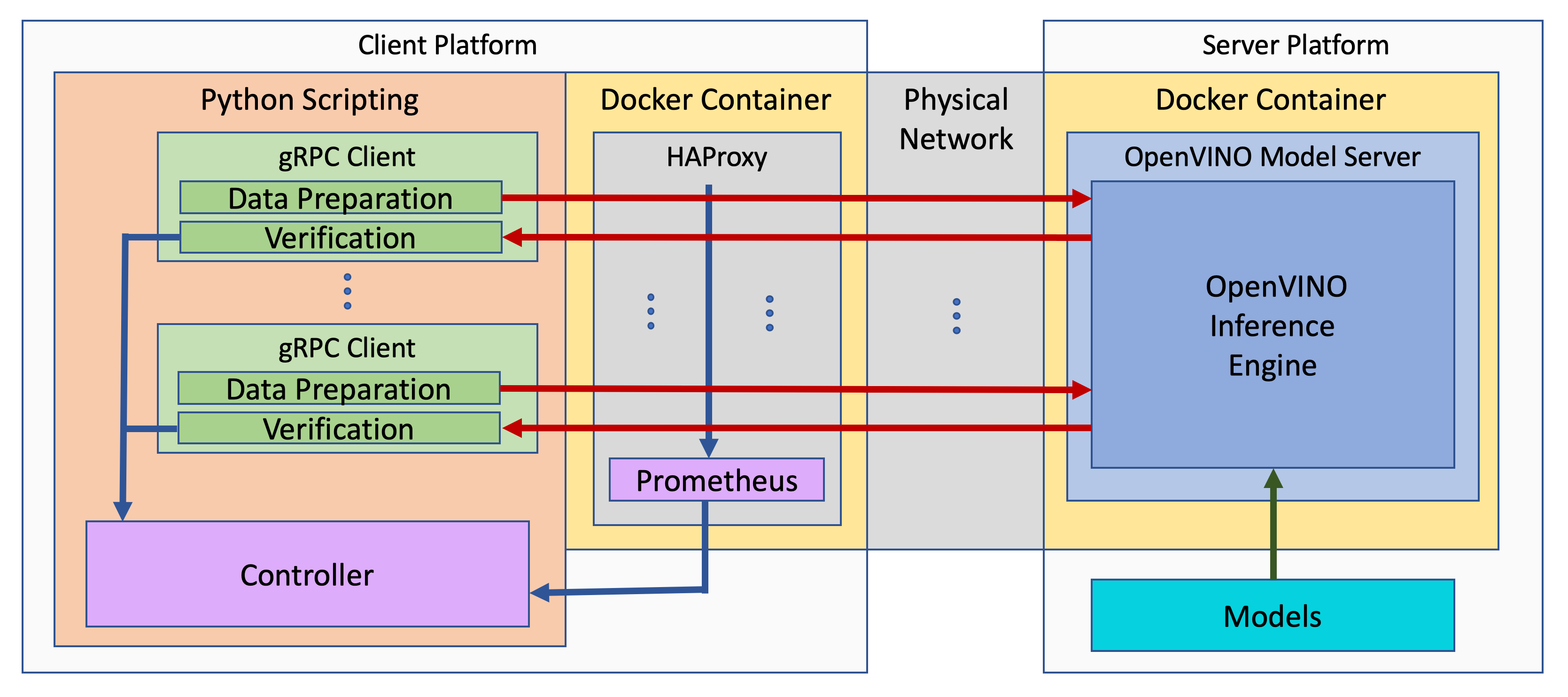
OpenVINO™ Model Server is launched as a docker container on the server platform and it listens (and answers on) requests from clients. OpenVINO™ Model Server is run on the same machine as the OpenVINO™ toolkit benchmark application in corresponding benchmarking. Models served by OpenVINO™ Model Server are located in a local file system mounted into the docker container. The OpenVINO™ Model Server instance communicates with other components via ports over a dedicated docker network.
Clients are run in separated physical machine referred to as client platform. Clients are implemented in Python3 programming language based on TensorFlow* API and they work as parallel processes. Each client waits for a response from OpenVINO™ Model Server before it will send a new next request. The role played by the clients is also verification of responses.
Load balancer works on the client platform in a docker container. HAProxy is used for this purpose. Its main role is counting of requests forwarded from clients to OpenVINO™ Model Server, estimating its latency, and sharing this information by Prometheus service. The reason of locating the load balancer on the client site is to simulate real life scenario that includes impact of physical network on reported metrics.
Execution Controller is launched on the client platform. It is responsible for synchronization of the whole measurement process, downloading metrics from the load balancer, and presenting the final report of the execution.
Test performance yourself¶
You can also test performance for your system yourself, following the guide on getting performance numbers.
Performance of a particular application can also be evaluated virtually using Intel® DevCloud for the Edge. It is a remote development environment with access to Intel® hardware and the latest versions of the Intel® Distribution of the OpenVINO™ Toolkit. To learn more about it, visit the website or create an account.
Disclaimers¶
Intel® Distribution of OpenVINO™ toolkit performance results are based on release 2023.3, as of February 13, 2024.
OpenVINO Model Server performance results are based on release 2023.3, as of February 13, 2024.
The results may not reflect all publicly available updates. Intel technologies’ features and benefits depend on system configuration and may require enabled hardware, software, or service activation. Learn more at intel.com, or from the OEM or retailer.
See configuration disclosure for details. No product can be absolutely secure. Performance varies by use, configuration and other factors. Learn more at www.intel.com/PerformanceIndex. Your costs and results may vary. Intel optimizations, for Intel compilers or other products, may not optimize to the same degree for non-Intel products.