Speech to Text with OpenVINO™¶
This Jupyter notebook can be launched on-line, opening an interactive environment in a browser window. You can also make a local installation. Choose one of the following options:
This tutorial demonstrates speech-to-text recognition with OpenVINO.
This tutorial uses the QuartzNet 15x5 model. QuartzNet performs automatic speech recognition. Its design is based on the Jasper architecture, which is a convolutional model trained with Connectionist Temporal Classification (CTC) loss. The model is available from Open Model Zoo.
Table of contents:¶
Imports¶
%pip install -q "librosa>=0.8.1" "matplotlib<3.8" "openvino-dev>=2023.1.0" "numpy<1.24"
from pathlib import Path
import sys
import torch
import torch.nn as nn
import IPython.display as ipd
import matplotlib.pyplot as plt
import librosa
import librosa.display
import numpy as np
import scipy
import openvino as ov
# Fetch `notebook_utils` module
import urllib.request
urllib.request.urlretrieve(
url='https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/main/notebooks/utils/notebook_utils.py',
filename='notebook_utils.py'
)
from notebook_utils import download_file
Settings¶
In this part, all variables used in the notebook are set.
model_folder = "model"
download_folder = "output"
data_folder = "data"
precision = "FP16"
model_name = "quartznet-15x5-en"
Download and Convert Public Model¶
If it is your first run, models
will be downloaded and converted here. It my take a few minutes. Use
omz_downloader and omz_converter, which are command-line tools
from the openvino-dev package.
Download Model¶
The omz_downloader tool automatically creates a directory structure
and downloads the selected model. This step is skipped if the model is
already downloaded. The selected model comes from the public directory,
which means it must be converted into OpenVINO Intermediate
Representation (OpenVINO IR).
# Check if a model is already downloaded (to the download directory).
path_to_model_weights = Path(f'{download_folder}/public/{model_name}/models')
downloaded_model_file = list(path_to_model_weights.glob('*.pth'))
if not path_to_model_weights.is_dir() or len(downloaded_model_file) == 0:
download_command = f"omz_downloader --name {model_name} --output_dir {download_folder} --precision {precision}"
! $download_command
sys.path.insert(0, str(path_to_model_weights))
def convert_model(model_path:Path, converted_model_path:Path):
"""
helper function for converting QuartzNet model to IR
The function accepts path to directory with dowloaded packages, weights and configs using OMZ downloader,
initialize model and convert to OpenVINO model and serialize it to IR.
Params:
model_path: path to model modules, weights and configs downloaded via omz_downloader
converted_model_path: path for saving converted model
Returns:
None
"""
# add model path to PYTHONPATH for access to downloaded modules
sys.path.append(str(model_path))
# import necessary classes
from ruamel.yaml import YAML
from nemo.collections.asr import JasperEncoder, JasperDecoderForCTC
from nemo.core import NeuralModuleFactory, DeviceType
YAML = YAML(typ='safe')
# utility fornction fr replacing 1d convolutions to 2d for better efficiency
def convert_to_2d(model):
for name, l in model.named_children():
layer_type = l.__class__.__name__
if layer_type == 'Conv1d':
new_layer = nn.Conv2d(l.in_channels, l.out_channels,
(1, l.kernel_size[0]), (1, l.stride[0]),
(0, l.padding[0]), (1, l.dilation[0]),
l.groups, False if l.bias is None else True, l.padding_mode)
params = l.state_dict()
params['weight'] = params['weight'].unsqueeze(2)
new_layer.load_state_dict(params)
setattr(model, name, new_layer)
elif layer_type == 'BatchNorm1d':
new_layer = nn.BatchNorm2d(l.num_features, l.eps)
new_layer.load_state_dict(l.state_dict())
new_layer.eval()
setattr(model, name, new_layer)
else:
convert_to_2d(l)
# model class
class QuartzNet(torch.nn.Module):
def __init__(self, model_config, encoder_weights, decoder_weights):
super().__init__()
with open(model_config, 'r') as config:
model_args = YAML.load(config)
_ = NeuralModuleFactory(placement=DeviceType.CPU)
encoder_params = model_args['init_params']['encoder_params']['init_params']
self.encoder = JasperEncoder(**encoder_params)
self.encoder.load_state_dict(torch.load(encoder_weights, map_location='cpu'))
decoder_params = model_args['init_params']['decoder_params']['init_params']
self.decoder = JasperDecoderForCTC(**decoder_params)
self.decoder.load_state_dict(torch.load(decoder_weights, map_location='cpu'))
self.encoder._prepare_for_deployment()
self.decoder._prepare_for_deployment()
convert_to_2d(self.encoder)
convert_to_2d(self.decoder)
def forward(self, input_signal):
input_signal = input_signal.unsqueeze(axis=2)
i_encoded = self.encoder(input_signal)
i_log_probs = self.decoder(i_encoded)
shape = i_log_probs.shape
return i_log_probs.reshape(shape[0], shape[1], shape[3])
# path to configs and weights for creating model instane
model_config = model_path / ".nemo_tmp/module.yaml"
encoder_weights = model_path / ".nemo_tmp/JasperEncoder.pt"
decoder_weights = model_path / ".nemo_tmp/JasperDecoderForCTC.pt"
# create model instance
model = QuartzNet(model_config, encoder_weights, decoder_weights)
# turn model to inference mode
model.eval()
# convert model to OpenVINO Model using model conversion API
ov_model = ov.convert_model(model, example_input=torch.zeros([1, 64, 128]))
# save model in IR format for next usage
ov.save_model(ov_model, converted_model_path)
# Check if a model is already converted (in the model directory).
path_to_converted_weights = Path(f'{model_folder}/public/{model_name}/{precision}/{model_name}.bin')
path_to_converted_model = Path(f'{model_folder}/public/{model_name}/{precision}/{model_name}.xml')
if not path_to_converted_weights.is_file():
downloaded_model_path = Path("output/public/quartznet-15x5-en/models")
convert_model(downloaded_model_path, path_to_converted_model)
[NeMo W 2023-09-11 15:01:17 jasper:148] Turned off 170 masked convolutions
INFO:nncf:NNCF initialized successfully. Supported frameworks detected: torch, tensorflow, onnx, openvino
[NeMo W 2023-09-11 15:01:18 deprecated:66] Function local_parameters is deprecated. It is going to be removed in the 0.11 version.
Audio Processing¶
Now that the model is converted, load an audio file.
Define constants¶
First, locate an audio file and define the alphabet used by the model.
This tutorial uses the Latin alphabet beginning with a space symbol and
ending with a blank symbol. In this case it will be ~, but that
could be any other character.
audio_file_name = "edge_to_cloud.ogg"
alphabet = " abcdefghijklmnopqrstuvwxyz'~"
Available Audio Formats¶
There are multiple supported audio formats that can be used with the model:
AIFF, AU, AVR, CAF, FLAC, HTK, SVX,
MAT4, MAT5, MPC2K, OGG, PAF, PVF, RAW,
RF64, SD2, SDS, IRCAM, VOC, W64, WAV,
NIST, WAVEX, WVE, XI
Load Audio File¶
Load the file after checking a file extension. Pass sr (stands for a
sampling rate) as an additional parameter. The model supports files
with a sampling rate of 16 kHz.
# Download the audio from the openvino_notebooks storage
file_name = download_file(
"https://storage.openvinotoolkit.org/repositories/openvino_notebooks/data/data/audio/" + audio_file_name,
directory=data_folder
)
audio, sampling_rate = librosa.load(path=str(file_name), sr=16000)
Now, you can play your audio file.
ipd.Audio(audio, rate=sampling_rate)
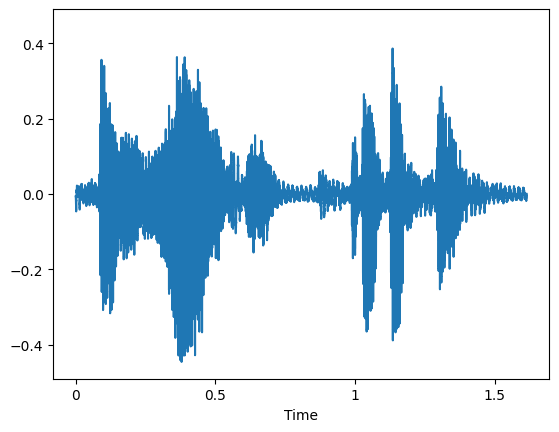
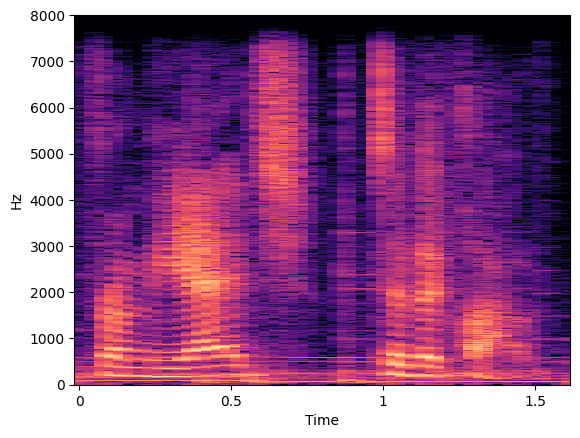
Visualize Audio File¶
You can visualize how your audio file presents on a wave plot and spectrogram.
plt.figure()
librosa.display.waveshow(y=audio, sr=sampling_rate, max_points=50000, x_axis='time', offset=0.0);
plt.show()
specto_audio = librosa.stft(audio)
specto_audio = librosa.amplitude_to_db(np.abs(specto_audio), ref=np.max)
print(specto_audio.shape)
librosa.display.specshow(specto_audio, sr=sampling_rate, x_axis='time', y_axis='hz');
(1025, 51)
Change Type of Data¶
The file loaded in the previous step may contain data in float type
with a range of values between -1 and 1. To generate a viable input,
multiply each value by the max value of int16 and convert it to
int16 type.
if max(np.abs(audio)) <= 1:
audio = (audio * (2**15 - 1))
audio = audio.astype(np.int16)
Convert Audio to Mel Spectrum¶
Next, convert the pre-pre-processed audio to Mel Spectrum. For more information on why it needs to be done, refer to this article.
def audio_to_mel(audio, sampling_rate):
assert sampling_rate == 16000, "Only 16 KHz audio supported"
preemph = 0.97
preemphased = np.concatenate([audio[:1], audio[1:] - preemph * audio[:-1].astype(np.float32)])
# Calculate the window length.
win_length = round(sampling_rate * 0.02)
# Based on the previously calculated window length, run short-time Fourier transform.
spec = np.abs(librosa.core.spectrum.stft(preemphased, n_fft=512, hop_length=round(sampling_rate * 0.01),
win_length=win_length, center=True, window=scipy.signal.windows.hann(win_length), pad_mode='reflect'))
# Create mel filter-bank, produce transformation matrix to project current values onto Mel-frequency bins.
mel_basis = librosa.filters.mel(sr=sampling_rate, n_fft=512, n_mels=64, fmin=0.0, fmax=8000.0, htk=False)
return mel_basis, spec
def mel_to_input(mel_basis, spec, padding=16):
# Convert to a logarithmic scale.
log_melspectrum = np.log(np.dot(mel_basis, np.power(spec, 2)) + 2 ** -24)
# Normalize the output.
normalized = (log_melspectrum - log_melspectrum.mean(1)[:, None]) / (log_melspectrum.std(1)[:, None] + 1e-5)
# Calculate padding.
remainder = normalized.shape[1] % padding
if remainder != 0:
return np.pad(normalized, ((0, 0), (0, padding - remainder)))[None]
return normalized[None]
Run Conversion from Audio to Mel Format¶
In this step, convert a current audio file into Mel scale.
mel_basis, spec = audio_to_mel(audio=audio.flatten(), sampling_rate=sampling_rate)
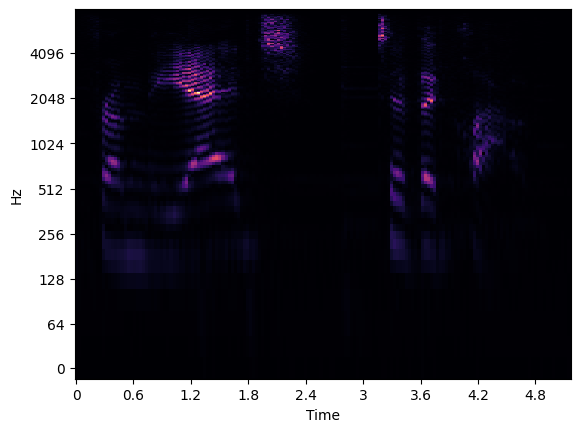
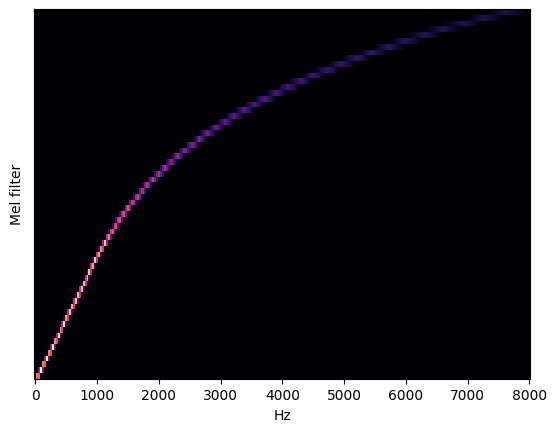
Visualize Mel Spectrogram¶
For more information about Mel spectrogram, refer to this article. The first image visualizes Mel frequency spectrogram, the second one presents filter bank for converting Hz to Mels.
librosa.display.specshow(data=spec, sr=sampling_rate, x_axis='time', y_axis='log');
plt.show();
librosa.display.specshow(data=mel_basis, sr=sampling_rate, x_axis='linear');
plt.ylabel('Mel filter');
Adjust Mel scale to Input¶
Before reading the network, make sure that the input is ready.
audio = mel_to_input(mel_basis=mel_basis, spec=spec)
Load the Model¶
Now, you can read and load the network.
core = ov.Core()
You may run the model on multiple devices. By default, it will load the model on CPU (you can choose manually CPU, GPU etc.) or let the engine choose the best available device (AUTO).
To list all available devices that can be used, run
print(core.available_devices) command.
print(core.available_devices)
['CPU', 'GPU']
Select device from dropdown list
import ipywidgets as widgets
device = widgets.Dropdown(
options=core.available_devices + ["AUTO"],
value='AUTO',
description='Device:',
disabled=False,
)
device
Dropdown(description='Device:', index=2, options=('CPU', 'GPU', 'AUTO'), value='AUTO')
model = core.read_model(
model=f"{model_folder}/public/{model_name}/{precision}/{model_name}.xml"
)
model_input_layer = model.input(0)
shape = model_input_layer.partial_shape
shape[2] = -1
model.reshape({model_input_layer: shape})
compiled_model = core.compile_model(model=model, device_name=device.value)
Do Inference¶
Everything is set up. Now, the only thing that remains is passing input to the previously loaded network and running inference.
character_probabilities = compiled_model([ov.Tensor(audio)])[0]
Read Output¶
After inference, you need to reach out the output. The default output
format for QuartzNet 15x5 are per-frame probabilities (after
LogSoftmax) for every symbol in the alphabet, name - output, shape -
1x64x29, output data format is BxNxC, where:
B - batch size
N - number of audio frames
C - alphabet size, including the Connectionist Temporal Classification (CTC) blank symbol
You need to make it in a more human-readable format. To do this you, use a symbol with the highest probability. When you hold a list of indexes that are predicted to have the highest probability, due to limitations given by Connectionist Temporal Classification Decoding you will remove concurrent symbols and then remove all the blanks.
The last step is getting symbols from corresponding indexes in charlist.
# Remove unnececery dimension
character_probabilities = np.squeeze(character_probabilities)
# Run argmax to pick most possible symbols
character_probabilities = np.argmax(character_probabilities, axis=1)
Implementation of Decoding¶
To decode previously explained output, you need the Connectionist Temporal Classification (CTC) decode function. This solution will remove consecutive letters from the output.
def ctc_greedy_decode(predictions):
previous_letter_id = blank_id = len(alphabet) - 1
transcription = list()
for letter_index in predictions:
if previous_letter_id != letter_index != blank_id:
transcription.append(alphabet[letter_index])
previous_letter_id = letter_index
return ''.join(transcription)
Run Decoding and Print Output¶
transcription = ctc_greedy_decode(character_probabilities)
print(transcription)
from the edge to the cloud