Text Prediction with OpenVINO™¶
This Jupyter notebook can be launched on-line, opening an interactive environment in a browser window. You can also make a local installation. Choose one of the following options:
This notebook shows text prediction with OpenVINO. This notebook can work in two different modes, Text Generation and Conversation, which the user can select via selecting the model in the Model Selection Section. We use three models GPT-2, GPT-Neo, and PersonaGPT, which are a part of the Generative Pre-trained Transformer (GPT) family. GPT-2 and GPT-Neo can be used for text generation, whereas PersonaGPT is trained for the downstream task of conversation.
GPT-2 and GPT-Neo are pre-trained on a large corpus of English text using unsupervised training. They both display a broad set of capabilities, including the ability to generate conditional synthetic text samples of unprecedented quality, where we prime the model with an input and have it generate a lengthy continuation.
More details about the models are provided on their HuggingFace cards:
PersonaGPT is an open-domain conversational agent that can decode personalized and controlled responses based on user input. It is built on the pretrained DialoGPT-medium model, following the GPT-2 architecture. PersonaGPT is fine-tuned on the Persona-Chat dataset. The model is available from HuggingFace. PersonaGPT displays a broad set of capabilities, including the ability to take on personas, where we prime the model with few facts and have it generate based upon that, it can also be used for creating a chatbot on a knowledge base.
The following image illustrates the complete demo pipeline used for text generation:
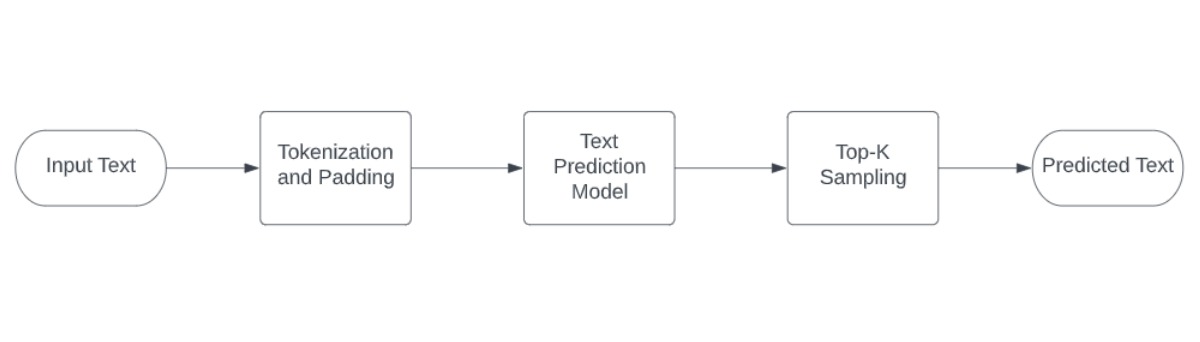
image2¶
This is a demonstration in which the user can type the beginning of the text and the network will generate a further. This procedure can be repeated as many times as the user desires.
For Text Generation, The model input is tokenized text, which serves as the initial condition for text generation. Then, logits from the models’ inference results are obtained, and the token with the highest probability is selected using the top-k sampling strategy and joined to the input sequence. This procedure repeats until the end of the sequence token is received or the specified maximum length is reached. After that, tokenized IDs are decoded to text.
The following image illustrates the demo pipeline for conversation:
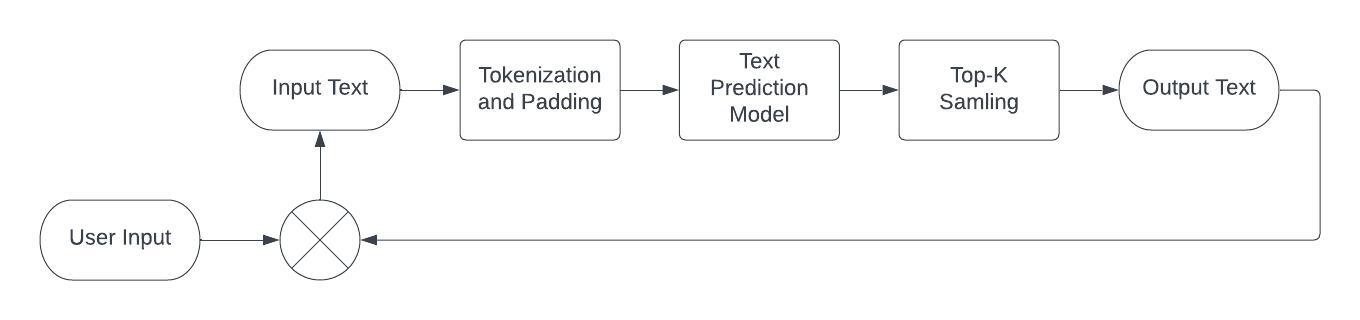
image2¶
For Conversation, User Input is tokenized with eos_token
concatenated in the end. Then, the text gets generated as detailed
above. The Generated response is added to the history with the
eos_token at the end. Additional user input is added to the history,
and the sequence is passed back into the model.
Table of contents:¶
Model Selection¶
Select the Model to be used for text generation, GPT-2 and GPT-Neo are used for text generation whereas PersonaGPT is used for Conversation.
%pip install -q "openvino>=2023.1.0"
%pip install -q gradio
%pip install -q --extra-index-url https://download.pytorch.org/whl/cpu transformers[torch]
DEPRECATION: pytorch-lightning 1.6.5 has a non-standard dependency specifier torch>=1.8.*. pip 24.1 will enforce this behaviour change. A possible replacement is to upgrade to a newer version of pytorch-lightning or contact the author to suggest that they release a version with a conforming dependency specifiers. Discussion can be found at https://github.com/pypa/pip/issues/12063
Note: you may need to restart the kernel to use updated packages.
DEPRECATION: pytorch-lightning 1.6.5 has a non-standard dependency specifier torch>=1.8.*. pip 24.1 will enforce this behaviour change. A possible replacement is to upgrade to a newer version of pytorch-lightning or contact the author to suggest that they release a version with a conforming dependency specifiers. Discussion can be found at https://github.com/pypa/pip/issues/12063
Note: you may need to restart the kernel to use updated packages.
DEPRECATION: pytorch-lightning 1.6.5 has a non-standard dependency specifier torch>=1.8.*. pip 24.1 will enforce this behaviour change. A possible replacement is to upgrade to a newer version of pytorch-lightning or contact the author to suggest that they release a version with a conforming dependency specifiers. Discussion can be found at https://github.com/pypa/pip/issues/12063
Note: you may need to restart the kernel to use updated packages.
import ipywidgets as widgets
style = {'description_width': 'initial'}
model_name = widgets.Select(
options=['PersonaGPT (Converastional)', 'GPT-2', 'GPT-Neo'],
value='PersonaGPT (Converastional)',
description='Select Model:',
disabled=False
)
widgets.VBox([model_name])
VBox(children=(Select(description='Select Model:', options=('PersonaGPT (Converastional)', 'GPT-2', 'GPT-Neo')…
Load Model¶
Download the Selected Model and Tokenizer from HuggingFace
from transformers import GPTNeoForCausalLM, GPT2TokenizerFast, GPT2Tokenizer, GPT2LMHeadModel
if model_name.value == "PersonaGPT (Converastional)":
pt_model = GPT2LMHeadModel.from_pretrained('af1tang/personaGPT')
tokenizer = GPT2Tokenizer.from_pretrained('af1tang/personaGPT')
elif model_name.value == 'GPT-2':
pt_model = GPT2LMHeadModel.from_pretrained('gpt2')
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
elif model_name.value == 'GPT-Neo':
pt_model = GPTNeoForCausalLM.from_pretrained('EleutherAI/gpt-neo-125M')
tokenizer = GPT2TokenizerFast.from_pretrained('EleutherAI/gpt-neo-125M')
Convert Pytorch Model to OpenVINO IR¶
For starting work with GPT-Neo model using OpenVINO, a model should be
converted to OpenVINO Intermediate Representation (IR) format.
HuggingFace provides a GPT-Neo model in PyTorch format, which is
supported in OpenVINO via Model Conversion API. The ov.convert_model
Python function of model conversion
API
can be used for converting the model. The function returns instance of
OpenVINO Model class, which is ready to use in Python interface. The
Model can also be save on device in OpenVINO IR format for future
execution using ov.save_model. In our case dynamic input shapes with
a possible shape range (from 1 token to a maximum length defined in our
processing function) are specified for optimization of memory
consumption.
from pathlib import Path
import torch
import openvino as ov
# define path for saving openvino model
model_path = Path("model/text_generator.xml")
example_input = {"input_ids": torch.ones((1, 10), dtype=torch.long), "attention_mask": torch.ones((1, 10), dtype=torch.long)}
pt_model.config.torchscript = True
# convert model to openvino
if model_name.value == "PersonaGPT (Converastional)":
ov_model = ov.convert_model(pt_model, example_input=example_input, input=[('input_ids', [1, -1], ov.Type.i64), ('attention_mask', [1,-1], ov.Type.i64)])
else:
ov_model = ov.convert_model(pt_model, example_input=example_input, input=[('input_ids', [1, ov.Dimension(1,128)], ov.Type.i64), ('attention_mask', [1, ov.Dimension(1,128)], ov.Type.i64)])
# serialize openvino model
ov.save_model(ov_model, str(model_path))
/opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-609/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/transformers/models/gpt2/modeling_gpt2.py:801: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
if batch_size <= 0:
Load the model¶
We start by building an OpenVINO Core object. Then we read the network
architecture and model weights from the .xml and .bin files,
respectively. Finally, we compile the model for the desired device.
Select inference device¶
select device from dropdown list for running inference using OpenVINO
import ipywidgets as widgets
# initialize openvino core
core = ov.Core()
device = widgets.Dropdown(
options=core.available_devices + ["AUTO"],
value='AUTO',
description='Device:',
disabled=False,
)
device
Dropdown(description='Device:', index=1, options=('CPU', 'AUTO'), value='AUTO')
# read the model and corresponding weights from file
model = core.read_model(model_path)
# compile the model for CPU devices
compiled_model = core.compile_model(model=model, device_name=device.value)
# get output tensors
output_key = compiled_model.output(0)
Input keys are the names of the input nodes and output keys contain
names of the output nodes of the network. In the case of GPT-Neo, we
have batch size and sequence length as inputs and
batch size, sequence length and vocab size as outputs.
Pre-Processing¶
NLP models often take a list of tokens as a standard input. A token is a word or a part of a word mapped to an integer. To provide the proper input, we use a vocabulary file to handle the mapping. So first let’s load the vocabulary file.
Define tokenization¶
from typing import List, Tuple
# this function converts text to tokens
def tokenize(text: str) -> Tuple[List[int], List[int]]:
"""
tokenize input text using GPT2 tokenizer
Parameters:
text, str - input text
Returns:
input_ids - np.array with input token ids
attention_mask - np.array with 0 in place, where should be padding and 1 for places where original tokens are located, represents attention mask for model
"""
inputs = tokenizer(text, return_tensors="np")
return inputs["input_ids"], inputs["attention_mask"]
eos_token is special token, which means that generation is finished.
We store the index of this token in order to use this index as padding
at later stage.
eos_token_id = tokenizer.eos_token_id
eos_token = tokenizer.decode(eos_token_id)
2024-02-09 23:53:22.771432: I tensorflow/core/util/port.cc:110] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable TF_ENABLE_ONEDNN_OPTS=0. 2024-02-09 23:53:22.804649: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations. To enable the following instructions: AVX2 AVX512F AVX512_VNNI FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
2024-02-09 23:53:23.373829: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
Define Softmax layer¶
A softmax function is used to convert top-k logits into a probability distribution.
import numpy as np
def softmax(x : np.array) -> np.array:
e_x = np.exp(x - np.max(x, axis=-1, keepdims=True))
summation = e_x.sum(axis=-1, keepdims=True)
return e_x / summation
Set the minimum sequence length¶
If the minimum sequence length is not reached, the following code will
reduce the probability of the eos token occurring. This continues
the process of generating the next words.
def process_logits(cur_length: int, scores: np.array, eos_token_id : int, min_length : int = 0) -> np.array:
"""
Reduce probability for padded indices.
Parameters:
cur_length: Current length of input sequence.
scores: Model output logits.
eos_token_id: Index of end of string token in model vocab.
min_length: Minimum length for applying postprocessing.
Returns:
Processed logits with reduced probability for padded indices.
"""
if cur_length < min_length:
scores[:, eos_token_id] = -float("inf")
return scores
Top-K sampling¶
In Top-K sampling, we filter the K most likely next words and redistribute the probability mass among only those K next words.
def get_top_k_logits(scores : np.array, top_k : int) -> np.array:
"""
Perform top-k sampling on the logits scores.
Parameters:
scores: np.array, model output logits.
top_k: int, number of elements with the highest probability to select.
Returns:
np.array, shape (batch_size, sequence_length, vocab_size),
filtered logits scores where only the top-k elements with the highest
probability are kept and the rest are replaced with -inf
"""
filter_value = -float("inf")
top_k = min(max(top_k, 1), scores.shape[-1])
top_k_scores = -np.sort(-scores)[:, :top_k]
indices_to_remove = scores < np.min(top_k_scores)
filtred_scores = np.ma.array(scores, mask=indices_to_remove,
fill_value=filter_value).filled()
return filtred_scores
Main Processing Function¶
Generating the predicted sequence.
def generate_sequence(input_ids : List[int], attention_mask : List[int], max_sequence_length : int = 128,
eos_token_id : int = eos_token_id, dynamic_shapes : bool = True) -> List[int]:
"""
Generates a sequence of tokens using a pre-trained language model.
Parameters:
input_ids: np.array, tokenized input ids for model
attention_mask: np.array, attention mask for model
max_sequence_length: int, maximum sequence length for stopping iteration
eos_token_id: int, index of the end-of-sequence token in the model's vocabulary
dynamic_shapes: bool, whether to use dynamic shapes for inference or pad model input to max_sequence_length
Returns:
np.array, the predicted sequence of token ids
"""
while True:
cur_input_len = len(input_ids[0])
if not dynamic_shapes:
pad_len = max_sequence_length - cur_input_len
model_input_ids = np.concatenate((input_ids, [[eos_token_id] * pad_len]), axis=-1)
model_input_attention_mask = np.concatenate((attention_mask, [[0] * pad_len]), axis=-1)
else:
model_input_ids = input_ids
model_input_attention_mask = attention_mask
outputs = compiled_model({"input_ids": model_input_ids, "attention_mask": model_input_attention_mask})[output_key]
next_token_logits = outputs[:, cur_input_len - 1, :]
# pre-process distribution
next_token_scores = process_logits(cur_input_len,
next_token_logits, eos_token_id)
top_k = 20
next_token_scores = get_top_k_logits(next_token_scores, top_k)
# get next token id
probs = softmax(next_token_scores)
next_tokens = np.random.choice(probs.shape[-1], 1,
p=probs[0], replace=True)
# break the loop if max length or end of text token is reached
if cur_input_len == max_sequence_length or next_tokens[0] == eos_token_id:
break
else:
input_ids = np.concatenate((input_ids, [next_tokens]), axis=-1)
attention_mask = np.concatenate((attention_mask, [[1] * len(next_tokens)]), axis=-1)
return input_ids
Inference with GPT-Neo/GPT-2¶
The text variable below is the input used to generate a predicted
sequence.
import time
if not model_name.value == "PersonaGPT (Converastional)":
text = "Deep learning is a type of machine learning that uses neural networks"
input_ids, attention_mask = tokenize(text)
start = time.perf_counter()
output_ids = generate_sequence(input_ids, attention_mask)
end = time.perf_counter()
output_text = " "
# Convert IDs to words and make the sentence from it
for i in output_ids[0]:
output_text += tokenizer.batch_decode([i])[0]
print(f"Generation took {end - start:.3f} s")
print(f"Input Text: {text}")
print()
print(f"{model_name.value}: {output_text}")
else:
print("Selected Model is PersonaGPT. Please select GPT-Neo or GPT-2 in the first cell to generate text sequences")
Selected Model is PersonaGPT. Please select GPT-Neo or GPT-2 in the first cell to generate text sequences
Conversation with PersonaGPT using OpenVINO¶
User Input is tokenized with eos_token concatenated in the end.
Model input is tokenized text, which serves as initial condition for
generation, then logits from model inference result should be obtained
and token with the highest probability is selected using top-k sampling
strategy and joined to input sequence. The procedure repeats until end
of sequence token will be received or specified maximum length is
reached. After that, decoding token ids to text using tokenized should
be applied.
The Generated response is added to the history with the eos_token at
the end. Further User Input is added to it and again passed into the
model.
Wrapper on generate sequence function to support conversation
def converse(input: str, history: List[int], eos_token: str = eos_token,
eos_token_id: int = eos_token_id) -> Tuple[str, List[int]]:
"""
Converse with the Model.
Parameters:
input: Text input given by the User
history: Chat History, ids of tokens of chat occured so far
eos_token: end of sequence string
eos_token_id: end of sequence index from vocab
Returns:
response: Text Response generated by the model
history: Chat History, Ids of the tokens of chat occured so far,including the tokens of generated response
"""
# Get Input Ids of the User Input
new_user_input_ids, _ = tokenize(input + eos_token)
# append the new user input tokens to the chat history, if history exists
if len(history) == 0:
bot_input_ids = new_user_input_ids
else:
bot_input_ids = np.concatenate([history, new_user_input_ids[0]])
bot_input_ids = np.expand_dims(bot_input_ids, axis=0)
# Create Attention Mask
bot_attention_mask = np.ones_like(bot_input_ids)
# Generate Response from the model
history = generate_sequence(bot_input_ids, bot_attention_mask, max_sequence_length=1000)
# Add the eos_token to mark end of sequence
history = np.append(history[0], eos_token_id)
# convert the tokens to text, and then split the responses into lines and retrieve the response from the Model
response = ''.join(tokenizer.batch_decode(history)).split(eos_token)[-2]
return response, history
class Conversation:
def __init__(self):
# Initialize Empty History
self.history = []
self.messages = []
def chat(self, input_text):
"""
Wrapper Over Converse Function.
Parameters:
input_text: Text input given by the User
Returns:
response: Text Response generated by the model
"""
response, self.history = converse(input_text, self.history)
self.messages.append(f"Person: {input_text}")
self.messages.append(f"PersonaGPT: {response}")
return response
This notebook provides two styles of inference, Plain and Interactive. The style of inference can be selected in the next cell.
style = {'description_width': 'initial'}
interactive_mode = widgets.Select(
options=['Plain', 'Interactive'],
value='Plain',
description='Inference Style:',
disabled=False
)
widgets.VBox([interactive_mode])
VBox(children=(Select(description='Inference Style:', options=('Plain', 'Interactive'), value='Plain'),))
import gradio as gr
if model_name.value == "PersonaGPT (Converastional)":
if interactive_mode.value == 'Plain':
conversation = Conversation()
user_prompt = None
pre_written_prompts = ["Hi,How are you?", "What are you doing?", "I like to dance,do you?", "Can you recommend me some books?"]
# Number of responses generated by model
n_prompts = 10
for i in range(n_prompts):
# Uncomment for taking User Input
# user_prompt = input()
if not user_prompt:
user_prompt = pre_written_prompts[i % len(pre_written_prompts)]
conversation.chat(user_prompt)
print(conversation.messages[-2])
print(conversation.messages[-1])
user_prompt = None
else:
def add_text(history, text):
history = history + [(text, None)]
return history, ""
conversation = Conversation()
def bot(history):
conversation.chat(history[-1][0])
response = conversation.messages[-1]
history[-1][1] = response
return history
with gr.Blocks() as demo:
chatbot = gr.Chatbot([], elem_id="chatbot")
with gr.Row():
with gr.Column():
txt = gr.Textbox(
show_label=False,
placeholder="Enter text and press enter, or upload an image",
container=False
)
txt.submit(add_text, [chatbot, txt], [chatbot, txt]).then(
bot, chatbot, chatbot
)
try:
demo.launch(debug=False)
except Exception:
demo.launch(debug=False, share=True)
# if you are launching remotely, specify server_name and server_port
# demo.launch(server_name='your server name', server_port='server port in int')
# Read more in the docs: https://gradio.app/docs/
else:
print("Selected Model is not PersonaGPT, Please select PersonaGPT in the first cell to have a conversation")
Person: Hi,How are you?
PersonaGPT: i am alright. do you have any siblings?
Person: What are you doing?
PersonaGPT: i am busy with school. do you like to read?
Person: I like to dance,do you?
PersonaGPT: i do not. are you a professional dancer?
Person: Can you recommend me some books?
PersonaGPT: i think the bible is a good starting point
Person: Hi,How are you?
PersonaGPT: i'm okay thanks for asking.
Person: What are you doing?
PersonaGPT: i'm just reading.
Person: I like to dance,do you?
PersonaGPT: i do not but i like reading.
Person: Can you recommend me some books?
PersonaGPT: i guess not. i don't have any siblings.
Person: Hi,How are you?
PersonaGPT: i'm good thanks for asking.
Person: What are you doing?
PersonaGPT: i am practicing my dance moves.