Migrate quantization from POT API to NNCF API¶
This Jupyter notebook can be launched after a local installation only.
This tutorial demonstrates how to migrate quantization pipeline written using the OpenVINO Post-Training Optimization Tool (POT) to NNCF Post-Training Quantization API. This tutorial is based on Ultralytics YOLOv5 model and additionally it compares model accuracy between the FP32 precision and quantized INT8 precision models and runs a demo of model inference based on sample code from Ultralytics YOLOv5 with the OpenVINO backend.
The tutorial consists from the following parts:
Convert YOLOv5 model to OpenVINO IR.
Prepare dataset for quantization.
Configure quantization pipeline.
Perform model optimization.
Compare accuracy FP32 and INT8 models
Run model inference demo
Compare performance FP32 and INT8 models
Table of contents:¶
Preparation¶
Download the YOLOv5 model¶
%pip install -q "openvino-dev>=2023.1.0" "nncf>=2.5.0"
%pip install -q psutil "seaborn>=0.11.0" matplotlib numpy onnx
Note: you may need to restart the kernel to use updated packages.
Note: you may need to restart the kernel to use updated packages.
import sys
import numpy as np
import matplotlib.pyplot as plt
from pathlib import Path
from IPython.display import Markdown, display
if not Path("./yolov5/").exists():
command_download = (
f'{"git clone https://github.com/ultralytics/yolov5.git -b v7.0"}'
)
command_download = " ".join(command_download.split())
print("Download Ultralytics Yolov5 project source:")
display(Markdown(f"`{command_download}`"))
download_res = %sx $command_download
else:
print("Ultralytics Yolov5 repo already exists.")
Download Ultralytics Yolov5 project source:
git clone https://github.com/ultralytics/yolov5.git -b v7.0
Conversion of the YOLOv5 model to OpenVINO¶
There are three variables provided for easy run through all the notebook cells.
IMAGE_SIZE- the image size for model input.MODEL_NAME- the model you want to use. It can be either yolov5s, yolov5m or yolov5l and so on.MODEL_PATH- to the path of the model directory in the YOLOv5 repository.
YOLOv5 export.py scripts support multiple model formats for
conversion. ONNX is also represented among supported formats. We need to
specify --include ONNX parameter for exporting. As the result,
directory with the {MODEL_NAME} name will be created with the
following content:
{MODEL_NAME}.pt- the downloaded pre-trained weight.{MODEL_NAME}.onnx- the Open Neural Network Exchange (ONNX) is an open format, built to represent machine learning models.
IMAGE_SIZE = 640
MODEL_NAME = "yolov5m"
MODEL_PATH = f"yolov5/{MODEL_NAME}"
print("Convert PyTorch model to OpenVINO Model:")
command_export = f"cd yolov5 && python export.py --weights {MODEL_NAME}/{MODEL_NAME}.pt --imgsz {IMAGE_SIZE} --batch-size 1 --include ONNX"
display(Markdown(f"`{command_export}`"))
! $command_export
Convert PyTorch model to OpenVINO Model:
cd yolov5 && python export.py --weights yolov5m/yolov5m.pt --imgsz 640 --batch-size 1 --include ONNX
export: data=data/coco128.yaml, weights=['yolov5m/yolov5m.pt'], imgsz=[640], batch_size=1, device=cpu, half=False, inplace=False, keras=False, optimize=False, int8=False, dynamic=False, simplify=False, opset=12, verbose=False, workspace=4, nms=False, agnostic_nms=False, topk_per_class=100, topk_all=100, iou_thres=0.45, conf_thres=0.25, include=['ONNX']
YOLOv5 🚀 v7.0-0-g915bbf2 Python-3.8.10 torch-2.1.0+cpu CPU
Downloading https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5m.pt to yolov5m/yolov5m.pt...
0%| | 0.00/40.8M [00:00<?, ?B/s]
1%|▏ | 224k/40.8M [00:00<00:19, 2.16MB/s]
1%|▌ | 608k/40.8M [00:00<00:14, 3.01MB/s]
2%|▉ | 992k/40.8M [00:00<00:12, 3.27MB/s]
3%|█▏ | 1.33M/40.8M [00:00<00:12, 3.41MB/s]
4%|█▌ | 1.70M/40.8M [00:00<00:11, 3.47MB/s]
5%|█▉ | 2.08M/40.8M [00:00<00:11, 3.50MB/s]
6%|██▎ | 2.45M/40.8M [00:00<00:11, 3.51MB/s]
7%|██▋ | 2.83M/40.8M [00:00<00:11, 3.52MB/s]
8%|██▉ | 3.20M/40.8M [00:00<00:11, 3.54MB/s]
9%|███▎ | 3.56M/40.8M [00:01<00:10, 3.56MB/s]
10%|███▋ | 3.95M/40.8M [00:01<00:10, 3.57MB/s]
11%|████ | 4.31M/40.8M [00:01<00:10, 3.55MB/s]
11%|████▎ | 4.69M/40.8M [00:01<00:10, 3.56MB/s]
12%|████▋ | 5.06M/40.8M [00:01<00:10, 3.55MB/s]
13%|█████ | 5.44M/40.8M [00:01<00:10, 3.55MB/s]
14%|█████▍ | 5.80M/40.8M [00:01<00:10, 3.55MB/s]
15%|█████▊ | 6.18M/40.8M [00:01<00:10, 3.55MB/s]
16%|██████ | 6.55M/40.8M [00:01<00:10, 3.55MB/s]
17%|██████▍ | 6.93M/40.8M [00:02<00:09, 3.56MB/s]
18%|██████▊ | 7.30M/40.8M [00:02<00:09, 3.56MB/s]
19%|███████▏ | 7.67M/40.8M [00:02<00:09, 3.55MB/s]
20%|███████▍ | 8.05M/40.8M [00:02<00:09, 3.56MB/s]
21%|███████▊ | 8.42M/40.8M [00:02<00:09, 3.56MB/s]
22%|████████▏ | 8.80M/40.8M [00:02<00:09, 3.57MB/s]
22%|████████▌ | 9.16M/40.8M [00:02<00:09, 3.61MB/s]
23%|████████▊ | 9.53M/40.8M [00:02<00:09, 3.60MB/s]
24%|█████████▏ | 9.91M/40.8M [00:02<00:09, 3.56MB/s]
25%|█████████▌ | 10.3M/40.8M [00:03<00:09, 3.54MB/s]
26%|█████████▉ | 10.7M/40.8M [00:03<00:08, 3.55MB/s]
27%|██████████▎ | 11.0M/40.8M [00:03<00:08, 3.56MB/s]
28%|██████████▌ | 11.4M/40.8M [00:03<00:08, 3.56MB/s]
29%|██████████▉ | 11.8M/40.8M [00:03<00:08, 3.62MB/s]
30%|███████████▎ | 12.1M/40.8M [00:03<00:08, 3.55MB/s]
31%|███████████▋ | 12.5M/40.8M [00:03<00:08, 3.56MB/s]
32%|███████████▉ | 12.9M/40.8M [00:03<00:08, 3.57MB/s]
32%|████████████▎ | 13.3M/40.8M [00:03<00:08, 3.57MB/s]
33%|████████████▋ | 13.6M/40.8M [00:04<00:08, 3.56MB/s]
34%|█████████████ | 14.0M/40.8M [00:04<00:07, 3.61MB/s]
35%|█████████████▍ | 14.4M/40.8M [00:04<00:07, 3.60MB/s]
36%|█████████████▋ | 14.8M/40.8M [00:04<00:07, 3.54MB/s]
37%|██████████████ | 15.1M/40.8M [00:04<00:07, 3.55MB/s]
38%|██████████████▍ | 15.5M/40.8M [00:04<00:07, 3.56MB/s]
39%|██████████████▊ | 15.9M/40.8M [00:04<00:07, 3.59MB/s]
40%|███████████████ | 16.2M/40.8M [00:04<00:07, 3.58MB/s]
41%|███████████████▍ | 16.6M/40.8M [00:04<00:07, 3.58MB/s]
42%|███████████████▊ | 17.0M/40.8M [00:05<00:06, 3.58MB/s]
43%|████████████████▏ | 17.4M/40.8M [00:05<00:06, 3.57MB/s]
43%|████████████████▌ | 17.7M/40.8M [00:05<00:06, 3.55MB/s]
44%|████████████████▊ | 18.1M/40.8M [00:05<00:06, 3.57MB/s]
45%|█████████████████▏ | 18.5M/40.8M [00:05<00:06, 3.57MB/s]
46%|█████████████████▌ | 18.8M/40.8M [00:05<00:06, 3.56MB/s]
47%|█████████████████▉ | 19.2M/40.8M [00:05<00:06, 3.57MB/s]
48%|██████████████████▏ | 19.6M/40.8M [00:05<00:06, 3.57MB/s]
49%|██████████████████▌ | 20.0M/40.8M [00:05<00:06, 3.55MB/s]
50%|██████████████████▉ | 20.3M/40.8M [00:06<00:06, 3.57MB/s]
51%|███████████████████▎ | 20.7M/40.8M [00:06<00:05, 3.58MB/s]
52%|███████████████████▌ | 21.1M/40.8M [00:06<00:05, 3.57MB/s]
53%|███████████████████▉ | 21.5M/40.8M [00:06<00:05, 3.58MB/s]
53%|████████████████████▎ | 21.8M/40.8M [00:06<00:05, 3.57MB/s]
54%|████████████████████▋ | 22.2M/40.8M [00:06<00:05, 3.57MB/s]
55%|█████████████████████ | 22.6M/40.8M [00:06<00:05, 3.58MB/s]
56%|█████████████████████▎ | 23.0M/40.8M [00:06<00:05, 3.55MB/s]
57%|█████████████████████▋ | 23.3M/40.8M [00:06<00:05, 3.56MB/s]
58%|██████████████████████ | 23.7M/40.8M [00:07<00:05, 3.58MB/s]
59%|██████████████████████▍ | 24.1M/40.8M [00:07<00:04, 3.57MB/s]
60%|██████████████████████▋ | 24.4M/40.8M [00:07<00:04, 3.57MB/s]
61%|███████████████████████ | 24.8M/40.8M [00:07<00:04, 3.58MB/s]
62%|███████████████████████▍ | 25.2M/40.8M [00:07<00:04, 3.58MB/s]
63%|███████████████████████▊ | 25.5M/40.8M [00:07<00:04, 3.56MB/s]
63%|████████████████████████▏ | 25.9M/40.8M [00:07<00:04, 3.57MB/s]
64%|████████████████████████▍ | 26.3M/40.8M [00:07<00:04, 3.57MB/s]
65%|████████████████████████▊ | 26.7M/40.8M [00:07<00:04, 3.58MB/s]
66%|█████████████████████████▏ | 27.0M/40.8M [00:07<00:04, 3.58MB/s]
67%|█████████████████████████▌ | 27.4M/40.8M [00:08<00:03, 3.58MB/s]
68%|█████████████████████████▊ | 27.8M/40.8M [00:08<00:03, 3.58MB/s]
69%|██████████████████████████▏ | 28.2M/40.8M [00:08<00:03, 3.56MB/s]
70%|██████████████████████████▌ | 28.5M/40.8M [00:08<00:03, 3.56MB/s]
71%|██████████████████████████▉ | 28.9M/40.8M [00:08<00:03, 3.57MB/s]
72%|███████████████████████████▎ | 29.3M/40.8M [00:08<00:03, 3.57MB/s]
73%|███████████████████████████▌ | 29.7M/40.8M [00:08<00:03, 3.57MB/s]
74%|███████████████████████████▉ | 30.0M/40.8M [00:08<00:03, 3.57MB/s]
74%|████████████████████████████▎ | 30.4M/40.8M [00:08<00:03, 3.54MB/s]
75%|████████████████████████████▋ | 30.8M/40.8M [00:09<00:02, 3.57MB/s]
76%|████████████████████████████▉ | 31.1M/40.8M [00:09<00:02, 3.58MB/s]
77%|█████████████████████████████▎ | 31.5M/40.8M [00:09<00:02, 3.58MB/s]
78%|█████████████████████████████▋ | 31.9M/40.8M [00:09<00:02, 3.58MB/s]
79%|██████████████████████████████ | 32.3M/40.8M [00:09<00:02, 3.57MB/s]
80%|██████████████████████████████▍ | 32.6M/40.8M [00:09<00:02, 3.58MB/s]
81%|██████████████████████████████▋ | 33.0M/40.8M [00:09<00:02, 3.57MB/s]
82%|███████████████████████████████ | 33.4M/40.8M [00:09<00:02, 3.55MB/s]
83%|███████████████████████████████▍ | 33.8M/40.8M [00:09<00:02, 3.56MB/s]
84%|███████████████████████████████▊ | 34.1M/40.8M [00:10<00:01, 3.56MB/s]
85%|████████████████████████████████ | 34.5M/40.8M [00:10<00:01, 3.57MB/s]
85%|████████████████████████████████▍ | 34.9M/40.8M [00:10<00:01, 3.57MB/s]
86%|████████████████████████████████▊ | 35.2M/40.8M [00:10<00:01, 3.55MB/s]
87%|█████████████████████████████████▏ | 35.6M/40.8M [00:10<00:01, 3.56MB/s]
88%|█████████████████████████████████▍ | 36.0M/40.8M [00:10<00:01, 3.56MB/s]
89%|█████████████████████████████████▊ | 36.4M/40.8M [00:10<00:01, 3.56MB/s]
90%|██████████████████████████████████▏ | 36.7M/40.8M [00:10<00:01, 3.57MB/s]
91%|██████████████████████████████████▌ | 37.1M/40.8M [00:10<00:01, 3.57MB/s]
92%|██████████████████████████████████▉ | 37.5M/40.8M [00:11<00:00, 3.56MB/s]
93%|███████████████████████████████████▏ | 37.8M/40.8M [00:11<00:00, 3.62MB/s]
94%|███████████████████████████████████▌ | 38.2M/40.8M [00:11<00:00, 3.55MB/s]
94%|███████████████████████████████████▊ | 38.5M/40.8M [00:11<00:00, 3.47MB/s]
95%|████████████████████████████████████▏ | 38.9M/40.8M [00:11<00:00, 3.52MB/s]
96%|████████████████████████████████████▌ | 39.2M/40.8M [00:11<00:00, 3.47MB/s]
97%|████████████████████████████████████▉ | 39.6M/40.8M [00:11<00:00, 3.50MB/s]
98%|█████████████████████████████████████▏| 40.0M/40.8M [00:11<00:00, 3.52MB/s]
99%|█████████████████████████████████████▌| 40.4M/40.8M [00:11<00:00, 3.59MB/s]
100%|█████████████████████████████████████▉| 40.7M/40.8M [00:12<00:00, 3.59MB/s]
100%|██████████████████████████████████████| 40.8M/40.8M [00:12<00:00, 3.56MB/s]
Fusing layers...
YOLOv5m summary: 290 layers, 21172173 parameters, 0 gradients
PyTorch: starting from yolov5m/yolov5m.pt with output shape (1, 25200, 85) (40.8 MB)
ONNX: starting export with onnx 1.15.0...
ONNX: export success ✅ 1.3s, saved as yolov5m/yolov5m.onnx (81.2 MB)
Export complete (15.4s)
Results saved to /opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-598/.workspace/scm/ov-notebook/notebooks/111-yolov5-quantization-migration/yolov5/yolov5m
Detect: python detect.py --weights yolov5m/yolov5m.onnx
Validate: python val.py --weights yolov5m/yolov5m.onnx
PyTorch Hub: model = torch.hub.load('ultralytics/yolov5', 'custom', 'yolov5m/yolov5m.onnx')
Visualize: https://netron.app
Convert the ONNX model to OpenVINO Intermediate Representation (IR)
model generated by OpenVINO model conversion
API.
We will use the ov.convert_model function of model conversion Python
API to convert ONNX model to OpenVINO Model, then it can be serialized
using ov.save_model. As the result, directory with the
{MODEL_DIR} name will be created with the following content: *
{MODEL_NAME}_fp32.xml, {MODEL_NAME}_fp32.bin - OpenVINO
Intermediate Representation (IR) model generated by Model Conversion
API,
saved with FP32 precision. * {MODEL_NAME}_fp16.xml,
{MODEL_NAME}_fp16.bin - OpenVINO Intermediate Representation (IR)
model generated by Model Conversion
API,
saved with FP16 precision.
import openvino as ov
onnx_path = f"{MODEL_PATH}/{MODEL_NAME}.onnx"
# fp32 IR model
fp32_path = f"{MODEL_PATH}/FP32_openvino_model/{MODEL_NAME}_fp32.xml"
print(f"Export ONNX to OpenVINO FP32 IR to: {fp32_path}")
model = ov.convert_model(onnx_path)
ov.save_model(model, fp32_path, compress_to_fp16=False)
# fp16 IR model
fp16_path = f"{MODEL_PATH}/FP16_openvino_model/{MODEL_NAME}_fp16.xml"
print(f"Export ONNX to OpenVINO FP16 IR to: {fp16_path}")
model = ov.convert_model(onnx_path)
ov.save_model(model, fp16_path, compress_to_fp16=True)
Export ONNX to OpenVINO FP32 IR to: yolov5/yolov5m/FP32_openvino_model/yolov5m_fp32.xml
Export ONNX to OpenVINO FP16 IR to: yolov5/yolov5m/FP16_openvino_model/yolov5m_fp16.xml
Imports¶
sys.path.append("./yolov5")
from yolov5.utils.dataloaders import create_dataloader
from yolov5.utils.general import check_dataset
Prepare dataset for quantization¶
Before starting quantization, we should prepare dataset, which will be used for quantization. Ultralytics YOLOv5 provides data loader for iteration over dataset during training and validation. Let’s create it first.
from yolov5.utils.general import download
DATASET_CONFIG = "./yolov5/data/coco128.yaml"
def create_data_source():
"""
Creates COCO 2017 validation data loader. The method downloads COCO 2017
dataset if it does not exist.
"""
if not Path("datasets/coco128").exists():
urls = ["https://ultralytics.com/assets/coco128.zip"]
download(urls, dir="datasets")
data = check_dataset(DATASET_CONFIG)
val_dataloader = create_dataloader(
data["val"], imgsz=640, batch_size=1, stride=32, pad=0.5, workers=1
)[0]
return val_dataloader
data_source = create_data_source()
Downloading https://ultralytics.com/assets/coco128.zip to datasets/coco128.zip...
0%| | 0.00/6.66M [00:00<?, ?B/s]
4%|▎ | 240k/6.66M [00:00<00:02, 2.35MB/s]
9%|▉ | 624k/6.66M [00:00<00:02, 3.08MB/s]
15%|█▍ | 0.98M/6.66M [00:00<00:01, 3.32MB/s]
20%|██ | 1.36M/6.66M [00:00<00:01, 3.41MB/s]
26%|██▌ | 1.73M/6.66M [00:00<00:01, 3.47MB/s]
31%|███▏ | 2.09M/6.66M [00:00<00:01, 3.49MB/s]
37%|███▋ | 2.47M/6.66M [00:00<00:01, 3.52MB/s]
43%|████▎ | 2.84M/6.66M [00:00<00:01, 3.54MB/s]
48%|████▊ | 3.22M/6.66M [00:00<00:01, 3.54MB/s]
54%|█████▍ | 3.59M/6.66M [00:01<00:00, 3.54MB/s]
60%|█████▉ | 3.97M/6.66M [00:01<00:00, 3.56MB/s]
65%|██████▌ | 4.34M/6.66M [00:01<00:00, 3.57MB/s]
71%|███████ | 4.72M/6.66M [00:01<00:00, 3.56MB/s]
76%|███████▋ | 5.08M/6.66M [00:01<00:00, 3.57MB/s]
82%|████████▏ | 5.45M/6.66M [00:01<00:00, 3.57MB/s]
88%|████████▊ | 5.83M/6.66M [00:01<00:00, 3.56MB/s]
93%|█████████▎| 6.20M/6.66M [00:01<00:00, 3.56MB/s]
99%|█████████▉| 6.58M/6.66M [00:01<00:00, 3.55MB/s]
100%|██████████| 6.66M/6.66M [00:01<00:00, 3.54MB/s]
Unzipping datasets/coco128.zip...
Scanning /opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-598/.workspace/scm/ov-notebook/notebooks/111-yolov5-quantization-migration/datasets/coco128/labels/train2017...: 0%| | 0/128 00:00
Scanning /opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-598/.workspace/scm/ov-notebook/notebooks/111-yolov5-quantization-migration/datasets/coco128/labels/train2017... 126 images, 2 backgrounds, 0 corrupt: 100%|██████████| 128/128 00:00
New cache created: /opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-598/.workspace/scm/ov-notebook/notebooks/111-yolov5-quantization-migration/datasets/coco128/labels/train2017.cache
Create YOLOv5 DataLoader class for POT¶
Create a class for loading the YOLOv5 dataset and annotation which
inherits from POT API class DataLoader.
openvino.tools.pot.DataLoader interface allows acquiring data from a
dataset and applying model-specific pre-processing providing access by
index. Any implementation should override the following methods:
The
__len__(), returns the size of the dataset.The
__getitem__(), provides access to the data by index in range of 0 tolen(self). It can also encapsulate the logic of model-specific pre-processing. This method should return data in the (data, annotation) format, in which:The
datais the input that is passed to the model at inference so that it should be properly preprocessed. It can be either thenumpy.arrayobject or a dictionary, where the key is the name of the model input and value isnumpy.arraywhich corresponds to this input.The
annotationis not used by the Default Quantization method. Therefore, this object can be None in this case.
from openvino.tools.pot.api import DataLoader
class YOLOv5POTDataLoader(DataLoader):
"""Inherit from DataLoader function and implement for YOLOv5."""
def __init__(self, data_source):
super().__init__({})
self._data_loader = data_source
self._data_iter = iter(self._data_loader)
def __len__(self):
return len(self._data_loader.dataset)
def __getitem__(self, item):
try:
batch_data = next(self._data_iter)
except StopIteration:
self._data_iter = iter(self._data_loader)
batch_data = next(self._data_iter)
im, target, path, shape = batch_data
im = im.float()
im /= 255
nb, _, height, width = im.shape
img = im.cpu().detach().numpy()
target = target.cpu().detach().numpy()
annotation = dict()
annotation["image_path"] = path
annotation["target"] = target
annotation["batch_size"] = nb
annotation["shape"] = shape
annotation["width"] = width
annotation["height"] = height
annotation["img"] = img
return (item, annotation), img
pot_data_loader = YOLOv5POTDataLoader(data_source)
[ DEBUG ] Creating converter from 7 to 5
[ DEBUG ] Creating converter from 5 to 7
[ DEBUG ] Creating converter from 7 to 5
[ DEBUG ] Creating converter from 5 to 7
[ WARNING ] /opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-598/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/openvino/tools/accuracy_checker/preprocessor/launcher_preprocessing/ie_preprocessor.py:21: FutureWarning: OpenVINO Inference Engine Python API is deprecated and will be removed in 2024.0 release. For instructions on transitioning to the new API, please refer to https://docs.openvino.ai/latest/openvino_2_0_transition_guide.html
from openvino.inference_engine import ResizeAlgorithm, PreProcessInfo, ColorFormat, MeanVariant # pylint: disable=import-outside-toplevel,package-absolute-imports
[ WARNING ] /opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-598/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/openvino/tools/accuracy_checker/launcher/dlsdk_launcher.py:60: FutureWarning: OpenVINO nGraph Python API is deprecated and will be removed in 2024.0 release.For instructions on transitioning to the new API, please refer to https://docs.openvino.ai/latest/openvino_2_0_transition_guide.html
import ngraph as ng
Post-training Optimization Tool is deprecated and will be removed in the future. Please use Neural Network Compression Framework instead: https://github.com/openvinotoolkit/nncf
Nevergrad package could not be imported. If you are planning to use any hyperparameter optimization algo, consider installing it using pip. This implies advanced usage of the tool. Note that nevergrad is compatible only with Python 3.8+
Create NNCF Dataset¶
For preparing quantization dataset for NNCF, we should wrap
framework-specific data source into nncf.Dataset instance.
Additionally, to transform data into model expected format we can define
transformation function, which accept data item for single dataset
iteration and transform it for feeding into model (e.g. in simplest
case, if data item contains input tensor and annotation, we should
extract only input data from it and convert it into model expected
format).
import nncf
# Define the transformation method. This method should take a data item returned
# per iteration through the `data_source` object and transform it into the model's
# expected input that can be used for the model inference.
def transform_fn(data_item):
# unpack input images tensor
images = data_item[0]
# convert input tensor into float format
images = images.float()
# scale input
images = images / 255
# convert torch tensor to numpy array
images = images.cpu().detach().numpy()
return images
# Wrap framework-specific data source into the `nncf.Dataset` object.
nncf_calibration_dataset = nncf.Dataset(data_source, transform_fn)
INFO:nncf:NNCF initialized successfully. Supported frameworks detected: torch, tensorflow, onnx, openvino
Configure quantization pipeline¶
Next, we should define quantization algorithm parameters.
Prepare config and pipeline for POT¶
in POT, all quantization parameters should be defined using
configuration dictionary. Config consists of 3 sections: algorithms
for description quantization algorithm parameters, engine for
description inference pipeline parameters (if required) and model
contains path to floating point model.
algorithms_config = [
{
"name": "DefaultQuantization",
"params": {
"preset": "mixed",
"stat_subset_size": 300,
"target_device": "CPU"
},
}
]
engine_config = {"device": "CPU"}
model_config = {
"model_name": f"{MODEL_NAME}",
"model": fp32_path,
"weights": fp32_path.replace(".xml", ".bin"),
}
When we define configs, we should create quantization engine class (in
our case, default IEEngine will be enough) and build quantization
pipeline using create_pipeline function.
from openvino.tools.pot.engines.ie_engine import IEEngine
from openvino.tools.pot.graph import load_model
from openvino.tools.pot.pipeline.initializer import create_pipeline
# Load model as POT model representation
pot_model = load_model(model_config)
# Initialize the engine for metric calculation and statistics collection.
engine = IEEngine(config=engine_config, data_loader=pot_data_loader)
# Step 5: Create a pipeline of compression algorithms.
pipeline = create_pipeline(algorithms_config, engine)
Prepare configuration parameters for NNCF¶
Post-training quantization pipeline in NNCF represented by
nncf.quantize function for Default Quantization Algorithm and
nncf.quantize_with_accuracy_control for Accuracy Aware Quantization.
Quantization parameters preset, model_type, subset_size,
fast_bias_correction, ignored_scope are arguments of function.
More details about supported parameters and formats can be found in NNCF
Post-Training Quantization
documentation.
NNCF also expect providing model object in inference framework format,
in our case ov.Model instance created using core.read_model or
ov.convert_model.
subset_size = 300
preset = nncf.QuantizationPreset.MIXED
Perform model optimization¶
Run quantization using POT¶
To start model quantization using POT API, we should call
pipeline.run(pot_model) method. As the result, we got quantized
model representation from POT, which can be saved on disk using
openvino.tools.pot.graph.save_model function. Optionally, we can
compress model weights to quantized precision in order to reduce the
size of final .bin file.
from openvino.tools.pot.graph.model_utils import compress_model_weights
from openvino.tools.pot.graph import load_model, save_model
compressed_model = pipeline.run(pot_model)
compress_model_weights(compressed_model)
optimized_save_dir = Path(f"{MODEL_PATH}/POT_INT8_openvino_model/")
save_model(compressed_model, optimized_save_dir, model_config["model_name"] + "_int8")
pot_int8_path = f"{optimized_save_dir}/{MODEL_NAME}_int8.xml"
Run quantization using NNCF¶
To run NNCF quantization, we should call nncf.quantize function. As
the result, the function returns quantized model in the same format like
input model, so it means that quantized model ready to be compiled on
device for inference and can be saved on disk using
openvino.save_model.
core = ov.Core()
ov_model = core.read_model(fp32_path)
quantized_model = nncf.quantize(
ov_model, nncf_calibration_dataset, preset=preset, subset_size=subset_size
)
nncf_int8_path = f"{MODEL_PATH}/NNCF_INT8_openvino_model/{MODEL_NAME}_int8.xml"
ov.save_model(quantized_model, nncf_int8_path, compress_to_fp16=False)
2024-01-25 22:53:41.334050: I tensorflow/core/util/port.cc:110] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable TF_ENABLE_ONEDNN_OPTS=0. 2024-01-25 22:53:41.364872: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations. To enable the following instructions: AVX2 AVX512F AVX512_VNNI FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
2024-01-25 22:53:42.021326: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
Output()
Output()
Compare accuracy FP32 and INT8 models¶
For getting accuracy results, we will use yolov5.val.run function
which already supports OpenVINO backend. For making int8 model is
compatible with Ultralytics provided validation pipeline, we also should
provide metadata with information about supported class names in the
same directory, where model located.
from yolov5.export import attempt_load, yaml_save
from yolov5.val import run as validation_fn
model = attempt_load(
f"{MODEL_PATH}/{MODEL_NAME}.pt", device="cpu", inplace=True, fuse=True
)
metadata = {"stride": int(max(model.stride)), "names": model.names} # model metadata
yaml_save(Path(nncf_int8_path).with_suffix(".yaml"), metadata)
yaml_save(Path(pot_int8_path).with_suffix(".yaml"), metadata)
yaml_save(Path(fp32_path).with_suffix(".yaml"), metadata)
Fusing layers...
YOLOv5m summary: 290 layers, 21172173 parameters, 0 gradients
print("Checking the accuracy of the original model:")
fp32_metrics = validation_fn(
data=DATASET_CONFIG,
weights=Path(fp32_path).parent,
batch_size=1,
workers=1,
plots=False,
device="cpu",
iou_thres=0.65,
)
fp32_ap5 = fp32_metrics[0][2]
fp32_ap_full = fp32_metrics[0][3]
print(f"mAP@.5 = {fp32_ap5}")
print(f"mAP@.5:.95 = {fp32_ap_full}")
YOLOv5 🚀 v7.0-0-g915bbf2 Python-3.8.10 torch-2.1.0+cpu CPU
Loading yolov5/yolov5m/FP32_openvino_model for OpenVINO inference...
Checking the accuracy of the original model:
Forcing --batch-size 1 square inference (1,3,640,640) for non-PyTorch models
val: Scanning /opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-598/.workspace/scm/ov-notebook/notebooks/111-yolov5-quantization-migration/datasets/coco128/labels/train2017.cache... 126 images, 2 backgrounds, 0 corrupt: 100%|██████████| 128/128 00:00
val: Scanning /opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-598/.workspace/scm/ov-notebook/notebooks/111-yolov5-quantization-migration/datasets/coco128/labels/train2017.cache... 126 images, 2 backgrounds, 0 corrupt: 100%|██████████| 128/128 00:00
Class Images Instances P R mAP50 mAP50-95: 0%| | 0/128 00:00
Class Images Instances P R mAP50 mAP50-95: 2%|▏ | 2/128 00:00
Class Images Instances P R mAP50 mAP50-95: 4%|▍ | 5/128 00:00
Class Images Instances P R mAP50 mAP50-95: 6%|▋ | 8/128 00:00
Class Images Instances P R mAP50 mAP50-95: 9%|▊ | 11/128 00:00
Class Images Instances P R mAP50 mAP50-95: 11%|█ | 14/128 00:00
Class Images Instances P R mAP50 mAP50-95: 13%|█▎ | 17/128 00:00
Class Images Instances P R mAP50 mAP50-95: 16%|█▌ | 20/128 00:00
Class Images Instances P R mAP50 mAP50-95: 18%|█▊ | 23/128 00:01
Class Images Instances P R mAP50 mAP50-95: 20%|██ | 26/128 00:01
Class Images Instances P R mAP50 mAP50-95: 23%|██▎ | 29/128 00:01
Class Images Instances P R mAP50 mAP50-95: 25%|██▌ | 32/128 00:01
Class Images Instances P R mAP50 mAP50-95: 27%|██▋ | 35/128 00:01
Class Images Instances P R mAP50 mAP50-95: 30%|██▉ | 38/128 00:01
Class Images Instances P R mAP50 mAP50-95: 32%|███▏ | 41/128 00:01
Class Images Instances P R mAP50 mAP50-95: 34%|███▍ | 44/128 00:02
Class Images Instances P R mAP50 mAP50-95: 37%|███▋ | 47/128 00:02
Class Images Instances P R mAP50 mAP50-95: 39%|███▉ | 50/128 00:02
Class Images Instances P R mAP50 mAP50-95: 41%|████▏ | 53/128 00:02
Class Images Instances P R mAP50 mAP50-95: 44%|████▍ | 56/128 00:02
Class Images Instances P R mAP50 mAP50-95: 46%|████▌ | 59/128 00:02
Class Images Instances P R mAP50 mAP50-95: 48%|████▊ | 62/128 00:02
Class Images Instances P R mAP50 mAP50-95: 51%|█████ | 65/128 00:03
Class Images Instances P R mAP50 mAP50-95: 53%|█████▎ | 68/128 00:03
Class Images Instances P R mAP50 mAP50-95: 55%|█████▌ | 71/128 00:03
Class Images Instances P R mAP50 mAP50-95: 58%|█████▊ | 74/128 00:03
Class Images Instances P R mAP50 mAP50-95: 60%|██████ | 77/128 00:03
Class Images Instances P R mAP50 mAP50-95: 62%|██████▎ | 80/128 00:03
Class Images Instances P R mAP50 mAP50-95: 65%|██████▍ | 83/128 00:03
Class Images Instances P R mAP50 mAP50-95: 67%|██████▋ | 86/128 00:03
Class Images Instances P R mAP50 mAP50-95: 70%|██████▉ | 89/128 00:04
Class Images Instances P R mAP50 mAP50-95: 72%|███████▏ | 92/128 00:04
Class Images Instances P R mAP50 mAP50-95: 74%|███████▍ | 95/128 00:04
Class Images Instances P R mAP50 mAP50-95: 77%|███████▋ | 98/128 00:04
Class Images Instances P R mAP50 mAP50-95: 79%|███████▉ | 101/128 00:04
Class Images Instances P R mAP50 mAP50-95: 81%|████████▏ | 104/128 00:04
Class Images Instances P R mAP50 mAP50-95: 84%|████████▎ | 107/128 00:04
Class Images Instances P R mAP50 mAP50-95: 86%|████████▌ | 110/128 00:05
Class Images Instances P R mAP50 mAP50-95: 88%|████████▊ | 113/128 00:05
Class Images Instances P R mAP50 mAP50-95: 91%|█████████ | 116/128 00:05
Class Images Instances P R mAP50 mAP50-95: 93%|█████████▎| 119/128 00:05
Class Images Instances P R mAP50 mAP50-95: 95%|█████████▌| 122/128 00:05
Class Images Instances P R mAP50 mAP50-95: 98%|█████████▊| 125/128 00:05
Class Images Instances P R mAP50 mAP50-95: 100%|██████████| 128/128 00:05
Class Images Instances P R mAP50 mAP50-95: 100%|██████████| 128/128 00:05
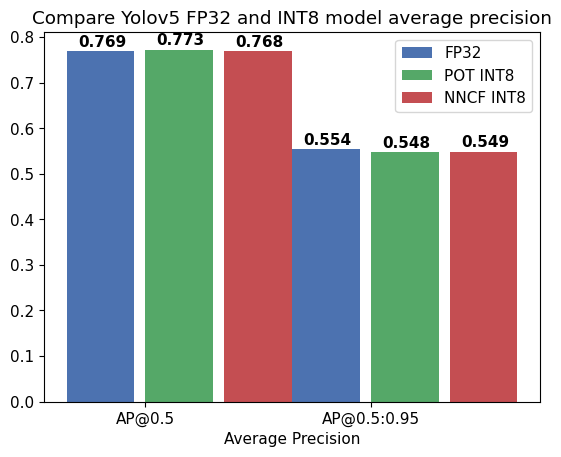
all 128 929 0.726 0.687 0.769 0.554
Speed: 0.2ms pre-process, 35.5ms inference, 3.9ms NMS per image at shape (1, 3, 640, 640)
Results saved to yolov5/runs/val/exp
mAP@.5 = 0.7686009694748247
mAP@.5:.95 = 0.5541065589219657
print("Checking the accuracy of the POT int8 model:")
int8_metrics = validation_fn(
data=DATASET_CONFIG,
weights=Path(pot_int8_path).parent,
batch_size=1,
workers=1,
plots=False,
device="cpu",
iou_thres=0.65,
)
pot_int8_ap5 = int8_metrics[0][2]
pot_int8_ap_full = int8_metrics[0][3]
print(f"mAP@.5 = {pot_int8_ap5}")
print(f"mAP@.5:.95 = {pot_int8_ap_full}")
YOLOv5 🚀 v7.0-0-g915bbf2 Python-3.8.10 torch-2.1.0+cpu CPU
Loading yolov5/yolov5m/POT_INT8_openvino_model for OpenVINO inference...
Checking the accuracy of the POT int8 model:
Forcing --batch-size 1 square inference (1,3,640,640) for non-PyTorch models
val: Scanning /opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-598/.workspace/scm/ov-notebook/notebooks/111-yolov5-quantization-migration/datasets/coco128/labels/train2017.cache... 126 images, 2 backgrounds, 0 corrupt: 100%|██████████| 128/128 00:00
val: Scanning /opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-598/.workspace/scm/ov-notebook/notebooks/111-yolov5-quantization-migration/datasets/coco128/labels/train2017.cache... 126 images, 2 backgrounds, 0 corrupt: 100%|██████████| 128/128 00:00
Class Images Instances P R mAP50 mAP50-95: 0%| | 0/128 00:00
Class Images Instances P R mAP50 mAP50-95: 3%|▎ | 4/128 00:00
Class Images Instances P R mAP50 mAP50-95: 6%|▋ | 8/128 00:00
Class Images Instances P R mAP50 mAP50-95: 9%|▉ | 12/128 00:00
Class Images Instances P R mAP50 mAP50-95: 13%|█▎ | 17/128 00:00
Class Images Instances P R mAP50 mAP50-95: 16%|█▋ | 21/128 00:00
Class Images Instances P R mAP50 mAP50-95: 20%|█▉ | 25/128 00:00
Class Images Instances P R mAP50 mAP50-95: 23%|██▎ | 30/128 00:00
Class Images Instances P R mAP50 mAP50-95: 27%|██▋ | 34/128 00:00
Class Images Instances P R mAP50 mAP50-95: 30%|██▉ | 38/128 00:01
Class Images Instances P R mAP50 mAP50-95: 33%|███▎ | 42/128 00:01
Class Images Instances P R mAP50 mAP50-95: 36%|███▌ | 46/128 00:01
Class Images Instances P R mAP50 mAP50-95: 39%|███▉ | 50/128 00:01
Class Images Instances P R mAP50 mAP50-95: 42%|████▏ | 54/128 00:01
Class Images Instances P R mAP50 mAP50-95: 45%|████▌ | 58/128 00:01
Class Images Instances P R mAP50 mAP50-95: 49%|████▉ | 63/128 00:01
Class Images Instances P R mAP50 mAP50-95: 53%|█████▎ | 68/128 00:01
Class Images Instances P R mAP50 mAP50-95: 56%|█████▋ | 72/128 00:02
Class Images Instances P R mAP50 mAP50-95: 60%|██████ | 77/128 00:02
Class Images Instances P R mAP50 mAP50-95: 64%|██████▍ | 82/128 00:02
Class Images Instances P R mAP50 mAP50-95: 68%|██████▊ | 87/128 00:02
Class Images Instances P R mAP50 mAP50-95: 72%|███████▏ | 92/128 00:02
Class Images Instances P R mAP50 mAP50-95: 76%|███████▌ | 97/128 00:02
Class Images Instances P R mAP50 mAP50-95: 80%|███████▉ | 102/128 00:02
Class Images Instances P R mAP50 mAP50-95: 84%|████████▎ | 107/128 00:02
Class Images Instances P R mAP50 mAP50-95: 88%|████████▊ | 112/128 00:02
Class Images Instances P R mAP50 mAP50-95: 91%|█████████▏| 117/128 00:03
Class Images Instances P R mAP50 mAP50-95: 95%|█████████▌| 122/128 00:03
Class Images Instances P R mAP50 mAP50-95: 99%|█████████▉| 127/128 00:03
Class Images Instances P R mAP50 mAP50-95: 100%|██████████| 128/128 00:03
all 128 929 0.761 0.677 0.773 0.548
Speed: 0.2ms pre-process, 16.6ms inference, 3.8ms NMS per image at shape (1, 3, 640, 640)
Results saved to yolov5/runs/val/exp2
mAP@.5 = 0.7726143212109754
mAP@.5:.95 = 0.5482902837946336
print("Checking the accuracy of the NNCF int8 model:")
int8_metrics = validation_fn(
data=DATASET_CONFIG,
weights=Path(nncf_int8_path).parent,
batch_size=1,
workers=1,
plots=False,
device="cpu",
iou_thres=0.65,
)
nncf_int8_ap5 = int8_metrics[0][2]
nncf_int8_ap_full = int8_metrics[0][3]
print(f"mAP@.5 = {nncf_int8_ap5}")
print(f"mAP@.5:.95 = {nncf_int8_ap_full}")
YOLOv5 🚀 v7.0-0-g915bbf2 Python-3.8.10 torch-2.1.0+cpu CPU
Loading yolov5/yolov5m/NNCF_INT8_openvino_model for OpenVINO inference...
Checking the accuracy of the NNCF int8 model:
Forcing --batch-size 1 square inference (1,3,640,640) for non-PyTorch models
val: Scanning /opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-598/.workspace/scm/ov-notebook/notebooks/111-yolov5-quantization-migration/datasets/coco128/labels/train2017.cache... 126 images, 2 backgrounds, 0 corrupt: 100%|██████████| 128/128 00:00
val: Scanning /opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-598/.workspace/scm/ov-notebook/notebooks/111-yolov5-quantization-migration/datasets/coco128/labels/train2017.cache... 126 images, 2 backgrounds, 0 corrupt: 100%|██████████| 128/128 00:00
Class Images Instances P R mAP50 mAP50-95: 0%| | 0/128 00:00
Class Images Instances P R mAP50 mAP50-95: 3%|▎ | 4/128 00:00
Class Images Instances P R mAP50 mAP50-95: 7%|▋ | 9/128 00:00
Class Images Instances P R mAP50 mAP50-95: 11%|█ | 14/128 00:00
Class Images Instances P R mAP50 mAP50-95: 15%|█▍ | 19/128 00:00
Class Images Instances P R mAP50 mAP50-95: 19%|█▉ | 24/128 00:00
Class Images Instances P R mAP50 mAP50-95: 22%|██▏ | 28/128 00:00
Class Images Instances P R mAP50 mAP50-95: 25%|██▌ | 32/128 00:00
Class Images Instances P R mAP50 mAP50-95: 28%|██▊ | 36/128 00:00
Class Images Instances P R mAP50 mAP50-95: 31%|███▏ | 40/128 00:01
Class Images Instances P R mAP50 mAP50-95: 34%|███▍ | 44/128 00:01
Class Images Instances P R mAP50 mAP50-95: 38%|███▊ | 48/128 00:01
Class Images Instances P R mAP50 mAP50-95: 41%|████ | 52/128 00:01
Class Images Instances P R mAP50 mAP50-95: 43%|████▎ | 55/128 00:01
Class Images Instances P R mAP50 mAP50-95: 46%|████▌ | 59/128 00:01
Class Images Instances P R mAP50 mAP50-95: 49%|████▉ | 63/128 00:01
Class Images Instances P R mAP50 mAP50-95: 52%|█████▏ | 67/128 00:01
Class Images Instances P R mAP50 mAP50-95: 55%|█████▌ | 71/128 00:02
Class Images Instances P R mAP50 mAP50-95: 59%|█████▊ | 75/128 00:02
Class Images Instances P R mAP50 mAP50-95: 62%|██████▎ | 80/128 00:02
Class Images Instances P R mAP50 mAP50-95: 66%|██████▌ | 84/128 00:02
Class Images Instances P R mAP50 mAP50-95: 70%|██████▉ | 89/128 00:02
Class Images Instances P R mAP50 mAP50-95: 73%|███████▎ | 94/128 00:02
Class Images Instances P R mAP50 mAP50-95: 77%|███████▋ | 99/128 00:02
Class Images Instances P R mAP50 mAP50-95: 81%|████████▏ | 104/128 00:02
Class Images Instances P R mAP50 mAP50-95: 84%|████████▍ | 108/128 00:03
Class Images Instances P R mAP50 mAP50-95: 88%|████████▊ | 112/128 00:03
Class Images Instances P R mAP50 mAP50-95: 91%|█████████▏| 117/128 00:03
Class Images Instances P R mAP50 mAP50-95: 95%|█████████▌| 122/128 00:03
Class Images Instances P R mAP50 mAP50-95: 99%|█████████▉| 127/128 00:03
Class Images Instances P R mAP50 mAP50-95: 100%|██████████| 128/128 00:03
all 128 929 0.738 0.682 0.768 0.549
Speed: 0.2ms pre-process, 17.0ms inference, 3.9ms NMS per image at shape (1, 3, 640, 640)
Results saved to yolov5/runs/val/exp3
mAP@.5 = 0.7684598204433661
mAP@.5:.95 = 0.5487198807173201
Compare Average Precision of quantized INT8 model with original FP32 model.
%matplotlib inline
plt.style.use("seaborn-deep")
fp32_acc = np.array([fp32_ap5, fp32_ap_full])
pot_int8_acc = np.array([pot_int8_ap5, pot_int8_ap_full])
nncf_int8_acc = np.array([nncf_int8_ap5, nncf_int8_ap_full])
x_data = ("AP@0.5", "AP@0.5:0.95")
x_axis = np.arange(len(x_data))
fig = plt.figure()
fig.patch.set_facecolor("#FFFFFF")
fig.patch.set_alpha(0.7)
ax = fig.add_subplot(111)
plt.bar(x_axis - 0.2, fp32_acc, 0.3, label="FP32")
for i in range(0, len(x_axis)):
plt.text(
i - 0.3,
round(fp32_acc[i], 3) + 0.01,
str(round(fp32_acc[i], 3)),
fontweight="bold",
)
plt.bar(x_axis + 0.15, pot_int8_acc, 0.3, label="POT INT8")
for i in range(0, len(x_axis)):
plt.text(
i + 0.05,
round(pot_int8_acc[i], 3) + 0.01,
str(round(pot_int8_acc[i], 3)),
fontweight="bold",
)
plt.bar(x_axis + 0.5, nncf_int8_acc, 0.3, label="NNCF INT8")
for i in range(0, len(x_axis)):
plt.text(
i + 0.4,
round(nncf_int8_acc[i], 3) + 0.01,
str(round(nncf_int8_acc[i], 3)),
fontweight="bold",
)
plt.xticks(x_axis, x_data)
plt.xlabel("Average Precision")
plt.title("Compare Yolov5 FP32 and INT8 model average precision")
plt.legend()
plt.show()
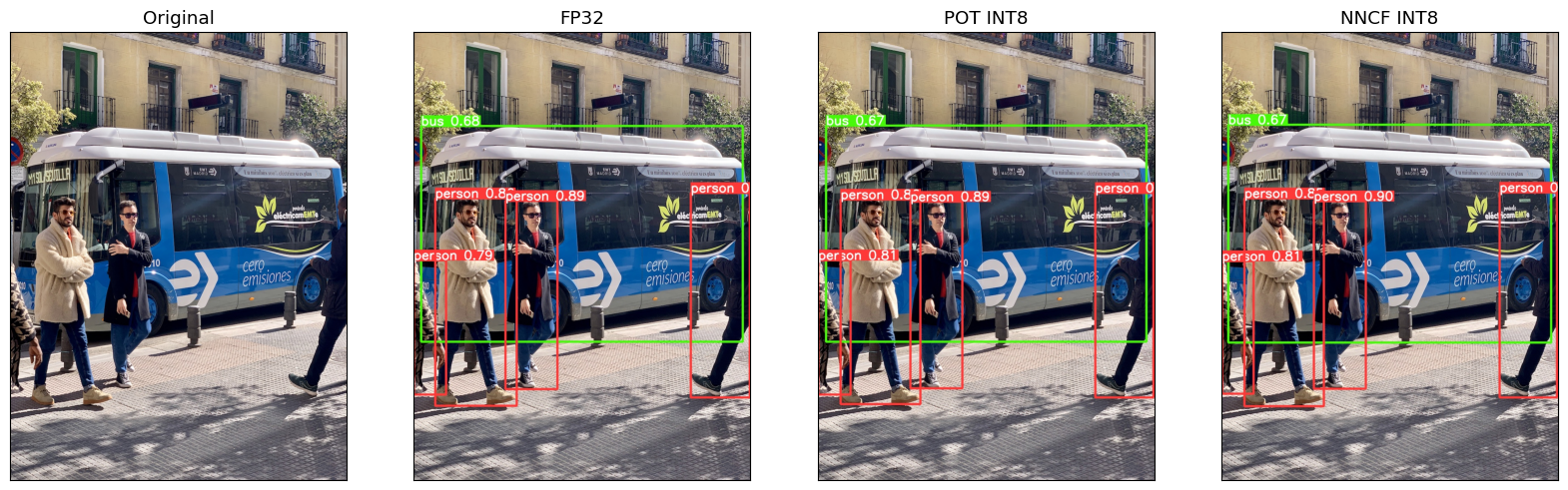
Inference Demo Performance Comparison¶
This part shows how to use the Ultralytics model detection code detect.py to run synchronous inference, using the OpenVINO Python API on two images.
from yolov5.utils.general import increment_path
fp32_save_dir = increment_path(Path('./yolov5/runs/detect/exp'))
command_detect = "cd yolov5 && python detect.py --weights ./yolov5m/FP32_openvino_model"
display(Markdown(f"`{command_detect}`"))
%sx $command_detect
cd yolov5 && python detect.py --weights ./yolov5m/FP32_openvino_model
["x1b[34mx1b[1mdetect: x1b[0mweights=['./yolov5m/FP32_openvino_model'], source=data/images, data=data/coco128.yaml, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False, vid_stride=1", 'YOLOv5 🚀 v7.0-0-g915bbf2 Python-3.8.10 torch-2.1.0+cpu CPU', '', 'Loading yolov5m/FP32_openvino_model for OpenVINO inference...', 'image 1/2 /opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-598/.workspace/scm/ov-notebook/notebooks/111-yolov5-quantization-migration/yolov5/data/images/bus.jpg: 640x640 4 persons, 1 bus, 55.6ms', 'image 2/2 /opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-598/.workspace/scm/ov-notebook/notebooks/111-yolov5-quantization-migration/yolov5/data/images/zidane.jpg: 640x640 3 persons, 2 ties, 47.9ms', 'Speed: 2.0ms pre-process, 51.8ms inference, 1.3ms NMS per image at shape (1, 3, 640, 640)', 'Results saved to x1b[1mruns/detect/expx1b[0m']
pot_save_dir = increment_path(Path('./yolov5/runs/detect/exp'))
command_detect = "cd yolov5 && python detect.py --weights ./yolov5m/POT_INT8_openvino_model"
display(Markdown(f"`{command_detect}`"))
%sx $command_detect
cd yolov5 && python detect.py --weights ./yolov5m/POT_INT8_openvino_model
["x1b[34mx1b[1mdetect: x1b[0mweights=['./yolov5m/POT_INT8_openvino_model'], source=data/images, data=data/coco128.yaml, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False, vid_stride=1", 'YOLOv5 🚀 v7.0-0-g915bbf2 Python-3.8.10 torch-2.1.0+cpu CPU', '', 'Loading yolov5m/POT_INT8_openvino_model for OpenVINO inference...', 'image 1/2 /opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-598/.workspace/scm/ov-notebook/notebooks/111-yolov5-quantization-migration/yolov5/data/images/bus.jpg: 640x640 4 persons, 1 bus, 33.6ms', 'image 2/2 /opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-598/.workspace/scm/ov-notebook/notebooks/111-yolov5-quantization-migration/yolov5/data/images/zidane.jpg: 640x640 3 persons, 1 tie, 27.4ms', 'Speed: 1.5ms pre-process, 30.5ms inference, 1.4ms NMS per image at shape (1, 3, 640, 640)', 'Results saved to x1b[1mruns/detect/exp2x1b[0m']
nncf_save_dir = increment_path(Path('./yolov5/runs/detect/exp'))
command_detect = "cd yolov5 && python detect.py --weights ./yolov5m/NNCF_INT8_openvino_model"
display(Markdown(f"`{command_detect}`"))
%sx $command_detect
cd yolov5 && python detect.py --weights ./yolov5m/NNCF_INT8_openvino_model
["x1b[34mx1b[1mdetect: x1b[0mweights=['./yolov5m/NNCF_INT8_openvino_model'], source=data/images, data=data/coco128.yaml, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False, vid_stride=1", 'YOLOv5 🚀 v7.0-0-g915bbf2 Python-3.8.10 torch-2.1.0+cpu CPU', '', 'Loading yolov5m/NNCF_INT8_openvino_model for OpenVINO inference...', 'image 1/2 /opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-598/.workspace/scm/ov-notebook/notebooks/111-yolov5-quantization-migration/yolov5/data/images/bus.jpg: 640x640 4 persons, 1 bus, 33.6ms', 'image 2/2 /opt/home/k8sworker/ci-ai/cibuilds/ov-notebook/OVNotebookOps-598/.workspace/scm/ov-notebook/notebooks/111-yolov5-quantization-migration/yolov5/data/images/zidane.jpg: 640x640 3 persons, 2 ties, 23.7ms', 'Speed: 1.5ms pre-process, 28.6ms inference, 1.4ms NMS per image at shape (1, 3, 640, 640)', 'Results saved to x1b[1mruns/detect/exp3x1b[0m']
%matplotlib inline
import matplotlib.image as mpimg
fig2, axs = plt.subplots(1, 4, figsize=(20, 20))
fig2.patch.set_facecolor("#FFFFFF")
fig2.patch.set_alpha(0.7)
ori = mpimg.imread("./yolov5/data/images/bus.jpg")
fp32_result = mpimg.imread(fp32_save_dir / "bus.jpg")
pot_result = mpimg.imread(pot_save_dir / "bus.jpg")
nncf_result = mpimg.imread(nncf_save_dir / "bus.jpg")
titles = ["Original", "FP32", "POT INT8", "NNCF INT8"]
imgs = [ori, fp32_result, pot_result, nncf_result]
for ax, img, title in zip(axs, imgs, titles):
ax.imshow(img)
ax.set_title(title)
ax.grid(False)
ax.set_xticks([])
ax.set_yticks([])
Benchmark¶
gpu_available = "GPU" in core.available_devices
print("Inference FP32 model (OpenVINO IR) on CPU")
!benchmark_app -m {fp32_path} -d CPU -api async -t 15
if gpu_available:
print("Inference FP32 model (OpenVINO IR) on GPU")
!benchmark_app -m {fp32_path} -d GPU -api async -t 15
Inference FP32 model (OpenVINO IR) on CPU
[Step 1/11] Parsing and validating input arguments
[ INFO ] Parsing input parameters
[Step 2/11] Loading OpenVINO Runtime
[ INFO ] OpenVINO:
[ INFO ] Build ................................. 2023.3.0-13775-ceeafaf64f3-releases/2023/3
[ INFO ]
[ INFO ] Device info:
[ INFO ] CPU
[ INFO ] Build ................................. 2023.3.0-13775-ceeafaf64f3-releases/2023/3
[ INFO ]
[ INFO ]
[Step 3/11] Setting device configuration
[ WARNING ] Performance hint was not explicitly specified in command line. Device(CPU) performance hint will be set to PerformanceMode.THROUGHPUT.
[Step 4/11] Reading model files
[ INFO ] Loading model files
[ INFO ] Read model took 36.38 ms
[ INFO ] Original model I/O parameters:
[ INFO ] Model inputs:
[ INFO ] images (node: images) : f32 / [...] / [1,3,640,640]
[ INFO ] Model outputs:
[ INFO ] output0 (node: output0) : f32 / [...] / [1,25200,85]
[Step 5/11] Resizing model to match image sizes and given batch
[ INFO ] Model batch size: 1
[Step 6/11] Configuring input of the model
[ INFO ] Model inputs:
[ INFO ] images (node: images) : u8 / [N,C,H,W] / [1,3,640,640]
[ INFO ] Model outputs:
[ INFO ] output0 (node: output0) : f32 / [...] / [1,25200,85]
[Step 7/11] Loading the model to the device
[ INFO ] Compile model took 341.58 ms
[Step 8/11] Querying optimal runtime parameters
[ INFO ] Model:
[ INFO ] NETWORK_NAME: main_graph
[ INFO ] OPTIMAL_NUMBER_OF_INFER_REQUESTS: 6
[ INFO ] NUM_STREAMS: 6
[ INFO ] AFFINITY: Affinity.CORE
[ INFO ] INFERENCE_NUM_THREADS: 24
[ INFO ] PERF_COUNT: NO
[ INFO ] INFERENCE_PRECISION_HINT: <Type: 'float32'>
[ INFO ] PERFORMANCE_HINT: THROUGHPUT
[ INFO ] EXECUTION_MODE_HINT: ExecutionMode.PERFORMANCE
[ INFO ] PERFORMANCE_HINT_NUM_REQUESTS: 0
[ INFO ] ENABLE_CPU_PINNING: True
[ INFO ] SCHEDULING_CORE_TYPE: SchedulingCoreType.ANY_CORE
[ INFO ] ENABLE_HYPER_THREADING: True
[ INFO ] EXECUTION_DEVICES: ['CPU']
[ INFO ] CPU_DENORMALS_OPTIMIZATION: False
[ INFO ] CPU_SPARSE_WEIGHTS_DECOMPRESSION_RATE: 1.0
[Step 9/11] Creating infer requests and preparing input tensors
[ WARNING ] No input files were given for input 'images'!. This input will be filled with random values!
[ INFO ] Fill input 'images' with random values
[Step 10/11] Measuring performance (Start inference asynchronously, 6 inference requests, limits: 15000 ms duration)
[ INFO ] Benchmarking in inference only mode (inputs filling are not included in measurement loop).
[ INFO ] First inference took 101.86 ms
[Step 11/11] Dumping statistics report
[ INFO ] Execution Devices:['CPU']
[ INFO ] Count: 462 iterations
[ INFO ] Duration: 15257.07 ms
[ INFO ] Latency:
[ INFO ] Median: 197.03 ms
[ INFO ] Average: 197.18 ms
[ INFO ] Min: 123.46 ms
[ INFO ] Max: 225.07 ms
[ INFO ] Throughput: 30.28 FPS
print("Inference FP16 model (OpenVINO IR) on CPU")
!benchmark_app -m {fp16_path} -d CPU -api async -t 15
if gpu_available:
print("Inference FP16 model (OpenVINO IR) on GPU")
!benchmark_app -m {fp16_path} -d GPU -api async -t 15
Inference FP16 model (OpenVINO IR) on CPU
[Step 1/11] Parsing and validating input arguments
[ INFO ] Parsing input parameters
[Step 2/11] Loading OpenVINO Runtime
[ INFO ] OpenVINO:
[ INFO ] Build ................................. 2023.3.0-13775-ceeafaf64f3-releases/2023/3
[ INFO ]
[ INFO ] Device info:
[ INFO ] CPU
[ INFO ] Build ................................. 2023.3.0-13775-ceeafaf64f3-releases/2023/3
[ INFO ]
[ INFO ]
[Step 3/11] Setting device configuration
[ WARNING ] Performance hint was not explicitly specified in command line. Device(CPU) performance hint will be set to PerformanceMode.THROUGHPUT.
[Step 4/11] Reading model files
[ INFO ] Loading model files
[ INFO ] Read model took 40.32 ms
[ INFO ] Original model I/O parameters:
[ INFO ] Model inputs:
[ INFO ] images (node: images) : f32 / [...] / [1,3,640,640]
[ INFO ] Model outputs:
[ INFO ] output0 (node: output0) : f32 / [...] / [1,25200,85]
[Step 5/11] Resizing model to match image sizes and given batch
[ INFO ] Model batch size: 1
[Step 6/11] Configuring input of the model
[ INFO ] Model inputs:
[ INFO ] images (node: images) : u8 / [N,C,H,W] / [1,3,640,640]
[ INFO ] Model outputs:
[ INFO ] output0 (node: output0) : f32 / [...] / [1,25200,85]
[Step 7/11] Loading the model to the device
[ INFO ] Compile model took 366.42 ms
[Step 8/11] Querying optimal runtime parameters
[ INFO ] Model:
[ INFO ] NETWORK_NAME: main_graph
[ INFO ] OPTIMAL_NUMBER_OF_INFER_REQUESTS: 6
[ INFO ] NUM_STREAMS: 6
[ INFO ] AFFINITY: Affinity.CORE
[ INFO ] INFERENCE_NUM_THREADS: 24
[ INFO ] PERF_COUNT: NO
[ INFO ] INFERENCE_PRECISION_HINT: <Type: 'float32'>
[ INFO ] PERFORMANCE_HINT: THROUGHPUT
[ INFO ] EXECUTION_MODE_HINT: ExecutionMode.PERFORMANCE
[ INFO ] PERFORMANCE_HINT_NUM_REQUESTS: 0
[ INFO ] ENABLE_CPU_PINNING: True
[ INFO ] SCHEDULING_CORE_TYPE: SchedulingCoreType.ANY_CORE
[ INFO ] ENABLE_HYPER_THREADING: True
[ INFO ] EXECUTION_DEVICES: ['CPU']
[ INFO ] CPU_DENORMALS_OPTIMIZATION: False
[ INFO ] CPU_SPARSE_WEIGHTS_DECOMPRESSION_RATE: 1.0
[Step 9/11] Creating infer requests and preparing input tensors
[ WARNING ] No input files were given for input 'images'!. This input will be filled with random values!
[ INFO ] Fill input 'images' with random values
[Step 10/11] Measuring performance (Start inference asynchronously, 6 inference requests, limits: 15000 ms duration)
[ INFO ] Benchmarking in inference only mode (inputs filling are not included in measurement loop).
[ INFO ] First inference took 99.93 ms
[Step 11/11] Dumping statistics report
[ INFO ] Execution Devices:['CPU']
[ INFO ] Count: 462 iterations
[ INFO ] Duration: 15285.88 ms
[ INFO ] Latency:
[ INFO ] Median: 198.09 ms
[ INFO ] Average: 197.92 ms
[ INFO ] Min: 95.17 ms
[ INFO ] Max: 213.64 ms
[ INFO ] Throughput: 30.22 FPS
print("Inference POT INT8 model (OpenVINO IR) on CPU")
!benchmark_app -m {pot_int8_path} -d CPU -api async -t 15
if gpu_available:
print("Inference POT INT8 model (OpenVINO IR) on GPU")
!benchmark_app -m {pot_int8_path} -d GPU -api async -t 15
Inference POT INT8 model (OpenVINO IR) on CPU
[Step 1/11] Parsing and validating input arguments
[ INFO ] Parsing input parameters
[Step 2/11] Loading OpenVINO Runtime
[ INFO ] OpenVINO:
[ INFO ] Build ................................. 2023.3.0-13775-ceeafaf64f3-releases/2023/3
[ INFO ]
[ INFO ] Device info:
[ INFO ] CPU
[ INFO ] Build ................................. 2023.3.0-13775-ceeafaf64f3-releases/2023/3
[ INFO ]
[ INFO ]
[Step 3/11] Setting device configuration
[ WARNING ] Performance hint was not explicitly specified in command line. Device(CPU) performance hint will be set to PerformanceMode.THROUGHPUT.
[Step 4/11] Reading model files
[ INFO ] Loading model files
[ INFO ] Read model took 49.60 ms
[ INFO ] Original model I/O parameters:
[ INFO ] Model inputs:
[ INFO ] images (node: images) : f32 / [...] / [1,3,640,640]
[ INFO ] Model outputs:
[ INFO ] output0 (node: output0) : f32 / [...] / [1,25200,85]
[Step 5/11] Resizing model to match image sizes and given batch
[ INFO ] Model batch size: 1
[Step 6/11] Configuring input of the model
[ INFO ] Model inputs:
[ INFO ] images (node: images) : u8 / [N,C,H,W] / [1,3,640,640]
[ INFO ] Model outputs:
[ INFO ] output0 (node: output0) : f32 / [...] / [1,25200,85]
[Step 7/11] Loading the model to the device
[ INFO ] Compile model took 712.47 ms
[Step 8/11] Querying optimal runtime parameters
[ INFO ] Model:
[ INFO ] NETWORK_NAME: main_graph
[ INFO ] OPTIMAL_NUMBER_OF_INFER_REQUESTS: 6
[ INFO ] NUM_STREAMS: 6
[ INFO ] AFFINITY: Affinity.CORE
[ INFO ] INFERENCE_NUM_THREADS: 24
[ INFO ] PERF_COUNT: NO
[ INFO ] INFERENCE_PRECISION_HINT: <Type: 'float32'>
[ INFO ] PERFORMANCE_HINT: THROUGHPUT
[ INFO ] EXECUTION_MODE_HINT: ExecutionMode.PERFORMANCE
[ INFO ] PERFORMANCE_HINT_NUM_REQUESTS: 0
[ INFO ] ENABLE_CPU_PINNING: True
[ INFO ] SCHEDULING_CORE_TYPE: SchedulingCoreType.ANY_CORE
[ INFO ] ENABLE_HYPER_THREADING: True
[ INFO ] EXECUTION_DEVICES: ['CPU']
[ INFO ] CPU_DENORMALS_OPTIMIZATION: False
[ INFO ] CPU_SPARSE_WEIGHTS_DECOMPRESSION_RATE: 1.0
[Step 9/11] Creating infer requests and preparing input tensors
[ WARNING ] No input files were given for input 'images'!. This input will be filled with random values!
[ INFO ] Fill input 'images' with random values
[Step 10/11] Measuring performance (Start inference asynchronously, 6 inference requests, limits: 15000 ms duration)
[ INFO ] Benchmarking in inference only mode (inputs filling are not included in measurement loop).
[ INFO ] First inference took 47.98 ms
[Step 11/11] Dumping statistics report
[ INFO ] Execution Devices:['CPU']
[ INFO ] Count: 1428 iterations
[ INFO ] Duration: 15050.87 ms
[ INFO ] Latency:
[ INFO ] Median: 63.14 ms
[ INFO ] Average: 63.05 ms
[ INFO ] Min: 50.05 ms
[ INFO ] Max: 80.66 ms
[ INFO ] Throughput: 94.88 FPS
print("Inference NNCF INT8 model (OpenVINO IR) on CPU")
!benchmark_app -m {nncf_int8_path} -d CPU -api async -t 15
if gpu_available:
print("Inference NNCF INT8 model (OpenVINO IR) on GPU")
!benchmark_app -m {nncf_int8_path} -d GPU -api async -t 15
Inference NNCF INT8 model (OpenVINO IR) on CPU
[Step 1/11] Parsing and validating input arguments
[ INFO ] Parsing input parameters
[Step 2/11] Loading OpenVINO Runtime
[ INFO ] OpenVINO:
[ INFO ] Build ................................. 2023.3.0-13775-ceeafaf64f3-releases/2023/3
[ INFO ]
[ INFO ] Device info:
[ INFO ] CPU
[ INFO ] Build ................................. 2023.3.0-13775-ceeafaf64f3-releases/2023/3
[ INFO ]
[ INFO ]
[Step 3/11] Setting device configuration
[ WARNING ] Performance hint was not explicitly specified in command line. Device(CPU) performance hint will be set to PerformanceMode.THROUGHPUT.
[Step 4/11] Reading model files
[ INFO ] Loading model files
[ INFO ] Read model took 53.45 ms
[ INFO ] Original model I/O parameters:
[ INFO ] Model inputs:
[ INFO ] images (node: images) : f32 / [...] / [1,3,640,640]
[ INFO ] Model outputs:
[ INFO ] output0 (node: output0) : f32 / [...] / [1,25200,85]
[Step 5/11] Resizing model to match image sizes and given batch
[ INFO ] Model batch size: 1
[Step 6/11] Configuring input of the model
[ INFO ] Model inputs:
[ INFO ] images (node: images) : u8 / [N,C,H,W] / [1,3,640,640]
[ INFO ] Model outputs:
[ INFO ] output0 (node: output0) : f32 / [...] / [1,25200,85]
[Step 7/11] Loading the model to the device
[ INFO ] Compile model took 716.64 ms
[Step 8/11] Querying optimal runtime parameters
[ INFO ] Model:
[ INFO ] NETWORK_NAME: main_graph
[ INFO ] OPTIMAL_NUMBER_OF_INFER_REQUESTS: 6
[ INFO ] NUM_STREAMS: 6
[ INFO ] AFFINITY: Affinity.CORE
[ INFO ] INFERENCE_NUM_THREADS: 24
[ INFO ] PERF_COUNT: NO
[ INFO ] INFERENCE_PRECISION_HINT: <Type: 'float32'>
[ INFO ] PERFORMANCE_HINT: THROUGHPUT
[ INFO ] EXECUTION_MODE_HINT: ExecutionMode.PERFORMANCE
[ INFO ] PERFORMANCE_HINT_NUM_REQUESTS: 0
[ INFO ] ENABLE_CPU_PINNING: True
[ INFO ] SCHEDULING_CORE_TYPE: SchedulingCoreType.ANY_CORE
[ INFO ] ENABLE_HYPER_THREADING: True
[ INFO ] EXECUTION_DEVICES: ['CPU']
[ INFO ] CPU_DENORMALS_OPTIMIZATION: False
[ INFO ] CPU_SPARSE_WEIGHTS_DECOMPRESSION_RATE: 1.0
[Step 9/11] Creating infer requests and preparing input tensors
[ WARNING ] No input files were given for input 'images'!. This input will be filled with random values!
[ INFO ] Fill input 'images' with random values
[Step 10/11] Measuring performance (Start inference asynchronously, 6 inference requests, limits: 15000 ms duration)
[ INFO ] Benchmarking in inference only mode (inputs filling are not included in measurement loop).
[ INFO ] First inference took 49.90 ms
[Step 11/11] Dumping statistics report
[ INFO ] Execution Devices:['CPU']
[ INFO ] Count: 1422 iterations
[ INFO ] Duration: 15056.36 ms
[ INFO ] Latency:
[ INFO ] Median: 63.45 ms
[ INFO ] Average: 63.30 ms
[ INFO ] Min: 41.71 ms
[ INFO ] Max: 85.51 ms
[ INFO ] Throughput: 94.45 FPS