Converting a TensorFlow DeepSpeech Model#
Danger
The code described here has been deprecated! Do not use it to avoid working with a legacy solution. It will be kept for some time to ensure backwards compatibility, but you should not use it in contemporary applications.
This guide describes a deprecated conversion method. The guide on the new and recommended method can be found in the Python tutorials.
DeepSpeech project provides an engine to train speech-to-text models.
Downloading the Pretrained DeepSpeech Model#
Create a directory where model and metagraph with pretrained weights will be stored:
mkdir deepspeech
cd deepspeech
Pre-trained English speech-to-text model is publicly available. To download the model, follow the instruction below:
For UNIX-like systems, run the following command:
wget -O - https://github.com/mozilla/DeepSpeech/archive/v0.8.2.tar.gz | tar xvfz - wget -O - https://github.com/mozilla/DeepSpeech/releases/download/v0.8.2/deepspeech-0.8.2-checkpoint.tar.gz | tar xvfz -
For Windows systems:
Download the archive with the model.
Download the TensorFlow MetaGraph with pre-trained weights.
Unpack it with a file archiver application.
Freezing the Model into a “*.pb File”#
After unpacking the archives above, you have to freeze the model. This requires TensorFlow version 1, which is not available under Python 3.8, so you need Python 3.7 or lower. Before freezing, deploy a virtual environment and install the required packages:
virtualenv --python=python3.7 venv-deep-speech
source venv-deep-speech/bin/activate
cd DeepSpeech-0.8.2
pip3 install -e .
Freeze the model with the following command:
python3 DeepSpeech.py --checkpoint_dir ../deepspeech-0.8.2-checkpoint --export_dir ../
After that, you will get the pretrained frozen model file output_graph.pb in the directory deepspeech created at
the beginning. The model contains the preprocessing and main parts. The first preprocessing part performs conversion of input
spectrogram into a form useful for speech recognition (mel). This part of the model is not convertible into
the IR because it contains unsupported operations AudioSpectrogram and Mfcc.
The main and most computationally expensive part of the model converts the preprocessed audio into text. There are two specificities with the supported part of the model.
The first is that the model contains an input with sequence length. So the model can be converted with a fixed input length shape, thus the model is not reshapable. Refer to the Using Shape Inference guide.
The second is that the frozen model still has two variables: previous_state_c and previous_state_h, figure
with the frozen *.pb model is below. It means that the model keeps training these variables at each inference.
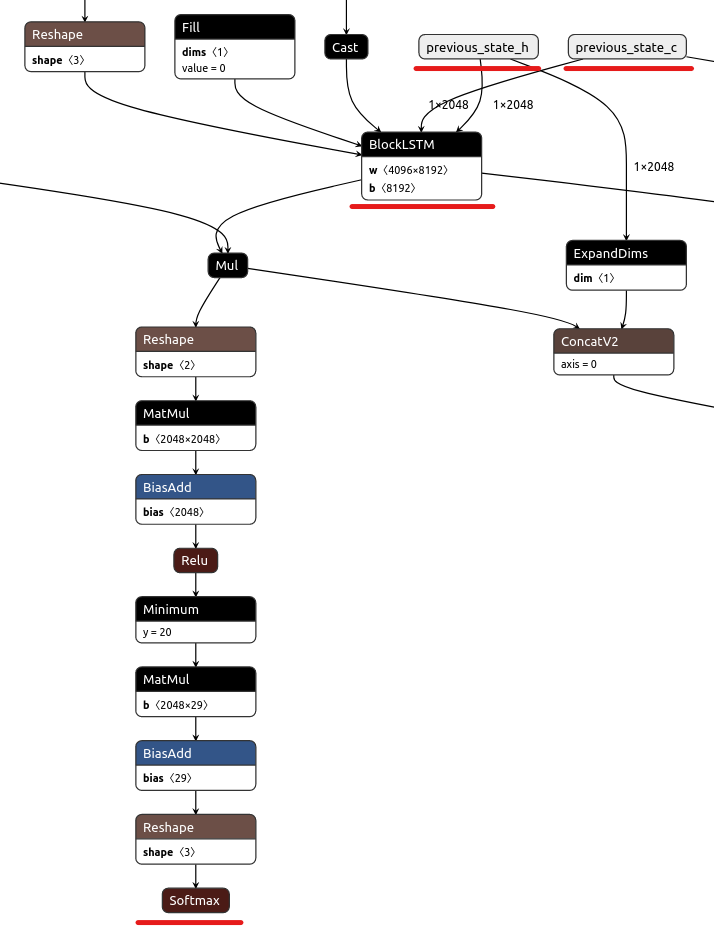
At the first inference, the variables are initialized with zero tensors. After execution, the results of the BlockLSTM
are assigned to cell state and hidden state, which are these two variables.
Converting the Main Part of DeepSpeech Model into OpenVINO IR#
Model conversion API assumes that the output model is for inference only. That is why you should cut previous_state_c and previous_state_h variables off and resolve keeping cell and hidden states on the application level.
There are certain limitations for the model conversion:
Time length (
time_len) and sequence length (seq_len) are equal.Original model cannot be reshaped, so you should keep original shapes.
To generate the IR, run model conversion with the following parameters:
mo \
--input_model output_graph.pb \
--input "input_lengths->[16],input_node[1,16,19,26],previous_state_h[1,2048],previous_state_c[1,2048]" \
--output "cudnn_lstm/rnn/multi_rnn_cell/cell_0/cudnn_compatible_lstm_cell/GatherNd_1,cudnn_lstm/rnn/multi_rnn_cell/cell_0/cudnn_compatible_lstm_cell/GatherNd,logits"
Where:
input_lengths->[16]Replaces the input node with name “input_lengths” with a constant tensor of shape [1] with a single integer value of 16. This means that the model now can consume input sequences of length 16 only.input_node[1 16 19 26],previous_state_h[1 2048],previous_state_c[1 2048]replaces the variables with a placeholder.output ".../GatherNd_1,.../GatherNd,logits"output node names.