Object segmentations with EfficientSAM and OpenVINO#
This Jupyter notebook can be launched after a local installation only.

Segment Anything Model (SAM) has emerged as a powerful tool for numerous vision applications. A key component that drives the impressive performance for zero-shot transfer and high versatility is a super large Transformer model trained on the extensive high-quality SA-1B dataset. While beneficial, the huge computation cost of SAM model has limited its applications to wider real-world applications. To address this limitation, EfficientSAMs, light-weight SAM models that exhibit decent performance with largely reduced complexity, were proposed. The idea behind EfficientSAM is based on leveraging masked image pretraining, SAMI, which learns to reconstruct features from SAM image encoder for effective visual representation learning.
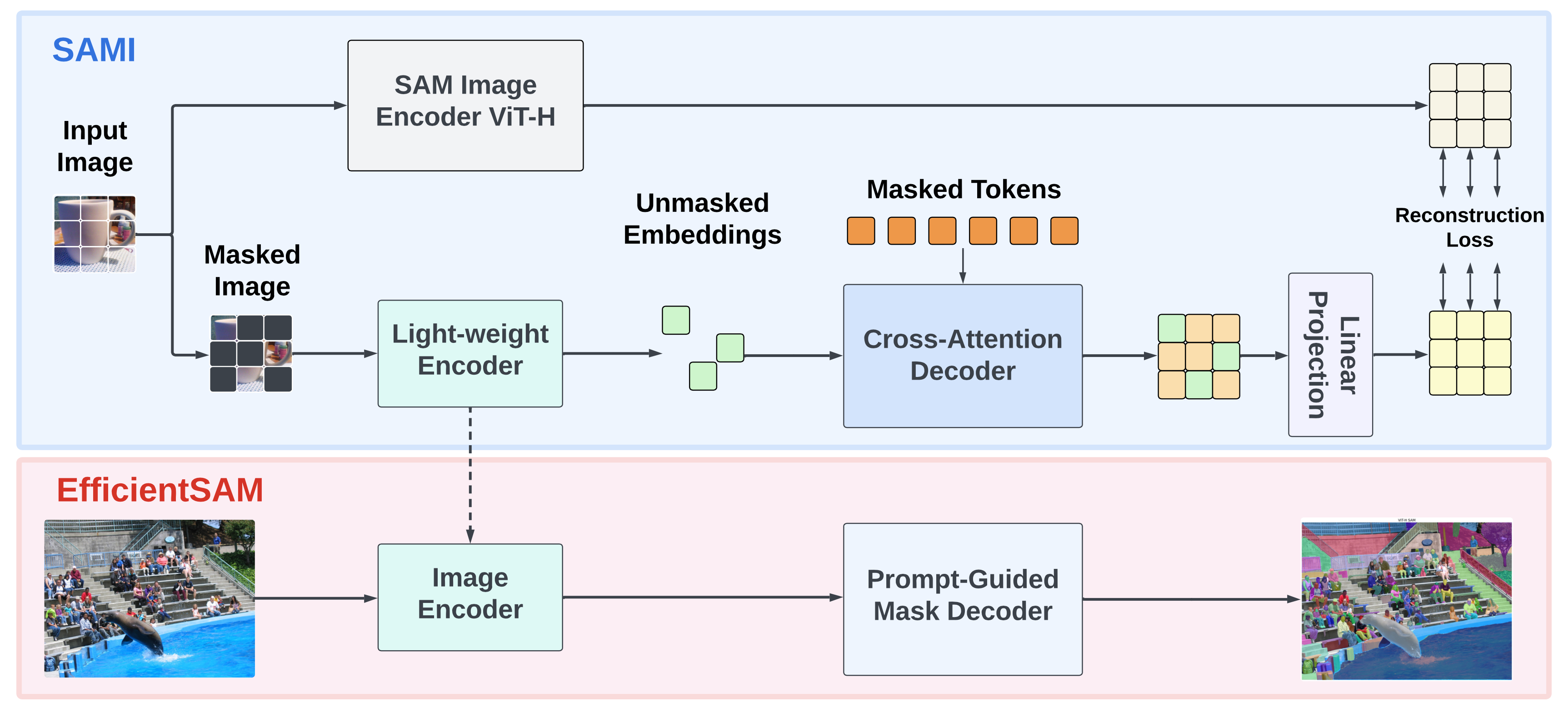
overview.png#
More details about model can be found in paper, model web page and original repository
In this tutorial we consider how to convert and run EfficientSAM using OpenVINO. We also demonstrate how to quantize model using NNCF
Table of contents:
Installation Instructions#
This is a self-contained example that relies solely on its own code.
We recommend running the notebook in a virtual environment. You only need a Jupyter server to start. For details, please refer to Installation Guide.
Prerequisites#
import platform
%pip install -q "openvino>=2024.5.0" "nncf>=2.14.0"
%pip install -q "torch>=2.2.0" "torchaudio>=2.2.0" "torchvision>=0.17.0" --extra-index-url https://download.pytorch.org/whl/cpu
%pip install -q opencv-python "gradio>=4.13" "matplotlib>=3.4" tqdm
if platform.system() == "Darwin":
%pip install -q "numpy<2.0.0"
ERROR: Could not find a version that satisfies the requirement openvino>=2024.5.0 (from versions: 2021.3.0, 2021.4.0, 2021.4.1, 2021.4.2, 2022.1.0, 2022.2.0, 2022.3.0, 2022.3.1, 2022.3.2, 2023.0.0.dev20230119, 2023.0.0.dev20230217, 2023.0.0.dev20230407, 2023.0.0.dev20230427, 2023.0.0, 2023.0.1, 2023.0.2, 2023.1.0.dev20230623, 2023.1.0.dev20230728, 2023.1.0.dev20230811, 2023.1.0, 2023.2.0.dev20230922, 2023.2.0, 2023.3.0, 2024.0.0, 2024.1.0, 2024.2.0, 2024.3.0, 2024.4.0, 2024.4.1.dev20240926)
ERROR: No matching distribution found for openvino>=2024.5.0
Note: you may need to restart the kernel to use updated packages.
Note: you may need to restart the kernel to use updated packages.
Note: you may need to restart the kernel to use updated packages.
import requests
from pathlib import Path
if not Path("cmd_helper.py").exists():
r = requests.get(
url="https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/utils/cmd_helper.py",
)
open("cmd_helper.py", "w").write(r.text)
from cmd_helper import clone_repo
repo_dir = clone_repo("https://github.com/yformer/EfficientSAM.git")
%cd $repo_dir
if not Path("notebook_utils.py").exists():
r = requests.get(
url="https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/utils/notebook_utils.py",
)
open("notebook_utils.py", "w").write(r.text)
from notebook_utils import download_file, device_widget, quantization_widget # noqa: F401
# Read more about telemetry collection at https://github.com/openvinotoolkit/openvino_notebooks?tab=readme-ov-file#-telemetry
from notebook_utils import collect_telemetry
collect_telemetry("efficient-sam.ipynb")
/opt/home/k8sworker/ci-ai/cibuilds/jobs/ov-notebook/jobs/OVNotebookOps/builds/875/archive/.workspace/scm/ov-notebook/notebooks/efficient-sam/EfficientSAM
Load PyTorch model#
There are several models available in the repository:
efficient-sam-vitt - EfficientSAM with Vision Transformer Tiny (VIT-T) as image encoder. The smallest and fastest model from EfficientSAM family.
efficient-sam-vits - EfficientSAM with Vision Transformer Small (VIT-S) as image encoder. Heavier than efficient-sam-vitt, but more accurate model.
EfficientSAM provides a unified interface for interaction with models. It means that all provided steps in the notebook for conversion and running the model will be the same for all models. Below, you can select one of them as example.
from efficient_sam.build_efficient_sam import (
build_efficient_sam_vitt,
build_efficient_sam_vits,
)
import zipfile
MODELS_LIST = {
"efficient-sam-vitt": build_efficient_sam_vitt,
"efficient-sam-vits": build_efficient_sam_vits,
}
# Since EfficientSAM-S checkpoint file is >100MB, we store the zip file.
with zipfile.ZipFile("weights/efficient_sam_vits.pt.zip", "r") as zip_ref:
zip_ref.extractall("weights")
Select one from supported models:
import ipywidgets as widgets
model_ids = list(MODELS_LIST)
model_id = widgets.Dropdown(
options=model_ids,
value=model_ids[0],
description="Model:",
disabled=False,
)
model_id
Dropdown(description='Model:', options=('efficient-sam-vitt', 'efficient-sam-vits'), value='efficient-sam-vitt…
build PyTorch model
pt_model = MODELS_LIST[model_id.value]()
pt_model.eval();
/opt/home/k8sworker/ci-ai/cibuilds/jobs/ov-notebook/jobs/OVNotebookOps/builds/875/archive/.workspace/scm/ov-notebook/notebooks/efficient-sam/EfficientSAM/efficient_sam/efficient_sam.py:303: FutureWarning: You are using torch.load with weights_only=False (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See pytorch/pytorch for more details). In a future release, the default value for weights_only will be flipped to True. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via torch.serialization.add_safe_globals. We recommend you start setting weights_only=True for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature. state_dict = torch.load(f, map_location="cpu")
Run PyTorch model inference#
Now, when we selected and loaded PyTorch model, we can check its result
Prepare input data#
First of all, we should prepare input data for model. Model has 3 inputs: * image tensor - tensor with normalized input image. * input points - tensor with user provided points. It maybe just some specific points on the image (e.g. provided by user clicks on the screen) or bounding box coordinates in format left-top angle point and right-bottom angle pint. * input labels - tensor with definition of point type for each provided point, 1 - for regular point, 2 - left-top point of bounding box, 3 - right-bottom point of bounding box.
from PIL import Image
image_path = "figs/examples/dogs.jpg"
image = Image.open(image_path)
image

Define helpers for input and output processing#
The code below defines helpers for preparing model input and postprocess inference results. The input format is accepted by the model described above. The model predicts mask logits for each pixel on the image and intersection over union score for each area, how close it is to provided points. We also provided some helper function for results visualization.
import torch
import matplotlib.pyplot as plt
import numpy as np
def prepare_input(input_image, points, labels, torch_tensor=True):
img_tensor = np.ascontiguousarray(input_image)[None, ...].astype(np.float32) / 255
img_tensor = np.transpose(img_tensor, (0, 3, 1, 2))
pts_sampled = np.reshape(np.ascontiguousarray(points), [1, 1, -1, 2])
pts_labels = np.reshape(np.ascontiguousarray(labels), [1, 1, -1])
if torch_tensor:
img_tensor = torch.from_numpy(img_tensor)
pts_sampled = torch.from_numpy(pts_sampled)
pts_labels = torch.from_numpy(pts_labels)
return img_tensor, pts_sampled, pts_labels
def postprocess_results(predicted_iou, predicted_logits):
sorted_ids = np.argsort(-predicted_iou, axis=-1)
predicted_iou = np.take_along_axis(predicted_iou, sorted_ids, axis=2)
predicted_logits = np.take_along_axis(predicted_logits, sorted_ids[..., None, None], axis=2)
return predicted_logits[0, 0, 0, :, :] >= 0
def show_points(coords, labels, ax, marker_size=375):
pos_points = coords[labels == 1]
neg_points = coords[labels == 0]
ax.scatter(
pos_points[:, 0],
pos_points[:, 1],
color="green",
marker="*",
s=marker_size,
edgecolor="white",
linewidth=1.25,
)
ax.scatter(
neg_points[:, 0],
neg_points[:, 1],
color="red",
marker="*",
s=marker_size,
edgecolor="white",
linewidth=1.25,
)
def show_box(box, ax):
x0, y0 = box[0], box[1]
w, h = box[2] - box[0], box[3] - box[1]
ax.add_patch(plt.Rectangle((x0, y0), w, h, edgecolor="yellow", facecolor=(0, 0, 0, 0), lw=5))
def show_anns(mask, ax):
ax.set_autoscale_on(False)
img = np.ones((mask.shape[0], mask.shape[1], 4))
img[:, :, 3] = 0
# for ann in mask:
# m = ann
color_mask = np.concatenate([np.random.random(3), [0.5]])
img[mask] = color_mask
ax.imshow(img)
The complete model inference example demonstrated below
input_points = [[580, 350], [650, 350]]
input_labels = [1, 1]
example_input = prepare_input(image, input_points, input_labels)
predicted_logits, predicted_iou = pt_model(*example_input)
predicted_mask = postprocess_results(predicted_iou.detach().numpy(), predicted_logits.detach().numpy())
image = Image.open(image_path)
plt.figure(figsize=(20, 20))
plt.axis("off")
plt.imshow(image)
show_points(np.array(input_points), np.array(input_labels), plt.gca())
plt.figure(figsize=(20, 20))
plt.axis("off")
plt.imshow(image)
show_anns(predicted_mask, plt.gca())
plt.title(f"PyTorch {model_id.value}", fontsize=18)
plt.show()


Convert model to OpenVINO IR format#
OpenVINO supports PyTorch models via conversion in Intermediate
Representation (IR) format using OpenVINO Model Conversion
API.
openvino.convert_model function accepts instance of PyTorch model
and example input (that helps in correct model operation tracing and
shape inference) and returns openvino.Model object that represents
model in OpenVINO framework. This openvino.Model is ready for
loading on the device using ov.Core.compile_model or can be saved on
disk using openvino.save_model.
import openvino as ov
core = ov.Core()
ov_model_path = Path(f"{model_id.value}.xml")
if not ov_model_path.exists():
ov_model = ov.convert_model(pt_model, example_input=example_input)
ov.save_model(ov_model, ov_model_path)
else:
ov_model = core.read_model(ov_model_path)
/opt/home/k8sworker/ci-ai/cibuilds/jobs/ov-notebook/jobs/OVNotebookOps/builds/875/archive/.workspace/scm/ov-notebook/notebooks/efficient-sam/EfficientSAM/efficient_sam/efficient_sam.py:220: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
if (
/opt/home/k8sworker/ci-ai/cibuilds/jobs/ov-notebook/jobs/OVNotebookOps/builds/875/archive/.workspace/scm/ov-notebook/notebooks/efficient-sam/EfficientSAM/efficient_sam/efficient_sam_encoder.py:241: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
assert (
/opt/home/k8sworker/ci-ai/cibuilds/jobs/ov-notebook/jobs/OVNotebookOps/builds/875/archive/.workspace/scm/ov-notebook/notebooks/efficient-sam/EfficientSAM/efficient_sam/efficient_sam_encoder.py:163: TracerWarning: Converting a tensor to a Python float might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
size = int(math.sqrt(xy_num))
/opt/home/k8sworker/ci-ai/cibuilds/jobs/ov-notebook/jobs/OVNotebookOps/builds/875/archive/.workspace/scm/ov-notebook/notebooks/efficient-sam/EfficientSAM/efficient_sam/efficient_sam_encoder.py:164: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
assert size * size == xy_num
/opt/home/k8sworker/ci-ai/cibuilds/jobs/ov-notebook/jobs/OVNotebookOps/builds/875/archive/.workspace/scm/ov-notebook/notebooks/efficient-sam/EfficientSAM/efficient_sam/efficient_sam_encoder.py:166: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
if size != h or size != w:
/opt/home/k8sworker/ci-ai/cibuilds/jobs/ov-notebook/jobs/OVNotebookOps/builds/875/archive/.workspace/scm/ov-notebook/notebooks/efficient-sam/EfficientSAM/efficient_sam/efficient_sam_encoder.py:251: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
assert x.shape[2] == num_patches
/opt/home/k8sworker/ci-ai/cibuilds/jobs/ov-notebook/jobs/OVNotebookOps/builds/875/archive/.workspace/scm/ov-notebook/notebooks/efficient-sam/EfficientSAM/efficient_sam/efficient_sam.py:85: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
if num_pts > self.decoder_max_num_input_points:
/opt/home/k8sworker/ci-ai/cibuilds/jobs/ov-notebook/jobs/OVNotebookOps/builds/875/archive/.workspace/scm/ov-notebook/notebooks/efficient-sam/EfficientSAM/efficient_sam/efficient_sam.py:92: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
elif num_pts < self.decoder_max_num_input_points:
/opt/home/k8sworker/ci-ai/cibuilds/jobs/ov-notebook/jobs/OVNotebookOps/builds/875/archive/.workspace/scm/ov-notebook/notebooks/efficient-sam/EfficientSAM/efficient_sam/efficient_sam.py:126: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
if output_w > 0 and output_h > 0:
Run OpenVINO model inference#
Select inference device from dropdown list#
device = device_widget()
device
Dropdown(description='Device:', index=1, options=('CPU', 'AUTO'), value='AUTO')
Compile OpenVINO model#
compiled_model = core.compile_model(ov_model, device.value)
Inference and visualize result#
Now, we can take a look on OpenVINO model prediction
example_input = prepare_input(image, input_points, input_labels, torch_tensor=False)
result = compiled_model(example_input)
predicted_logits, predicted_iou = result[0], result[1]
predicted_mask = postprocess_results(predicted_iou, predicted_logits)
plt.figure(figsize=(20, 20))
plt.axis("off")
plt.imshow(image)
show_points(np.array(input_points), np.array(input_labels), plt.gca())
plt.figure(figsize=(20, 20))
plt.axis("off")
plt.imshow(image)
show_anns(predicted_mask, plt.gca())
plt.title(f"OpenVINO {model_id.value}", fontsize=18)
plt.show()


Quantization#
NNCF enables post-training quantization by adding the quantization layers into the model graph and then using a subset of the training dataset to initialize the parameters of these additional quantization layers. The framework is designed so that modifications to your original training code are minor.
The optimization process contains the following steps:
Create a calibration dataset for quantization.
Run
nncf.quantizeto obtain quantized encoder and decoder models.Serialize the
INT8model usingopenvino.save_modelfunction.
Note: Quantization is time and memory consuming operation. Running quantization code below may take some time.
Please select below whether you would like to run EfficientSAM quantization.
to_quantize = quantization_widget()
to_quantize
Checkbox(value=True, description='Quantization')
# Fetch `skip_kernel_extension` module
import requests
r = requests.get(
url="https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/utils/skip_kernel_extension.py",
)
open("skip_kernel_extension.py", "w").write(r.text)
%load_ext skip_kernel_extension
Prepare calibration datasets#
The first step is to prepare calibration datasets for quantization. We will use coco128 dataset for quantization. Usually, this dataset used for solving object detection task and its annotation provides box coordinates for images. In our case, box coordinates will serve as input points for object segmentation, the code below downloads dataset and creates DataLoader for preparing inputs for EfficientSAM model.
%%skip not $to_quantize.value
from zipfile import ZipFile
DATA_URL = "https://ultralytics.com/assets/coco128.zip"
OUT_DIR = Path('.')
download_file(DATA_URL, directory=OUT_DIR, show_progress=True)
if not (OUT_DIR / "coco128/images/train2017").exists():
with ZipFile('coco128.zip' , "r") as zip_ref:
zip_ref.extractall(OUT_DIR)
coco128.zip: 0%| | 0.00/6.66M [00:00<?, ?B/s]
%%skip not $to_quantize.value
import torch.utils.data as data
class COCOLoader(data.Dataset):
def __init__(self, images_path):
self.images = list(Path(images_path).iterdir())
self.labels_dir = images_path.parents[1] / 'labels' / images_path.name
def get_points(self, image_path, image_width, image_height):
file_name = image_path.name.replace('.jpg', '.txt')
label_file = self.labels_dir / file_name
if not label_file.exists():
x1, x2 = np.random.randint(low=0, high=image_width, size=(2, ))
y1, y2 = np.random.randint(low=0, high=image_height, size=(2, ))
else:
with label_file.open("r") as f:
box_line = f.readline()
_, x1, y1, x2, y2 = box_line.split()
x1 = int(float(x1) * image_width)
y1 = int(float(y1) * image_height)
x2 = int(float(x2) * image_width)
y2 = int(float(y2) * image_height)
return [[x1, y1], [x2, y2]]
def __getitem__(self, index):
image_path = self.images[index]
image = Image.open(image_path)
image = image.convert('RGB')
w, h = image.size
points = self.get_points(image_path, w, h)
labels = [1, 1] if index % 2 == 0 else [2, 3]
batched_images, batched_points, batched_point_labels = prepare_input(image, points, labels, torch_tensor=False)
return {'batched_images': np.ascontiguousarray(batched_images)[0], 'batched_points': np.ascontiguousarray(batched_points)[0], 'batched_point_labels': np.ascontiguousarray(batched_point_labels)[0]}
def __len__(self):
return len(self.images)
%%skip not $to_quantize.value
coco_dataset = COCOLoader(OUT_DIR / 'coco128/images/train2017')
calibration_loader = torch.utils.data.DataLoader(coco_dataset)
Run Model Quantization#
The nncf.quantize function provides an interface for model
quantization. It requires an instance of the OpenVINO Model and
quantization dataset. Optionally, some additional parameters for the
configuration quantization process (number of samples for quantization,
preset, ignored scope, etc.) can be provided. EfficientSAM contains
non-ReLU activation functions, which require asymmetric quantization of
activations. To achieve a better result, we will use a mixed
quantization preset. Model encoder part is based on Vision
Transformer architecture for activating special optimizations for this
architecture type, we should specify transformer in model_type.
%%skip not $to_quantize.value
import nncf
calibration_dataset = nncf.Dataset(calibration_loader)
model = core.read_model(ov_model_path)
quantized_model = nncf.quantize(model,
calibration_dataset,
model_type=nncf.parameters.ModelType.TRANSFORMER,
subset_size=128)
print("model quantization finished")
INFO:nncf:NNCF initialized successfully. Supported frameworks detected: torch, tensorflow, onnx, openvino
2025-02-04 02:16:14.399301: I tensorflow/core/util/port.cc:110] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable TF_ENABLE_ONEDNN_OPTS=0. 2025-02-04 02:16:14.434747: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations. To enable the following instructions: AVX2 AVX512F AVX512_VNNI FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags. 2025-02-04 02:16:15.084214: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
Output()
Output()
Output()
Output()
model quantization finished
Verify quantized model inference#
%%skip not $to_quantize.value
compiled_model = core.compile_model(quantized_model, device.value)
result = compiled_model(example_input)
predicted_logits, predicted_iou = result[0], result[1]
predicted_mask = postprocess_results(predicted_iou, predicted_logits)
plt.figure(figsize=(20, 20))
plt.axis("off")
plt.imshow(image)
show_points(np.array(input_points), np.array(input_labels), plt.gca())
plt.figure(figsize=(20, 20))
plt.axis("off")
plt.imshow(image)
show_anns(predicted_mask, plt.gca())
plt.title(f"OpenVINO INT8 {model_id.value}", fontsize=18)
plt.show()


Save quantize model on disk#
%%skip not $to_quantize.value
quantized_model_path = Path(f"{model_id.value}_int8.xml")
ov.save_model(quantized_model, quantized_model_path)
Compare quantized model size#
%%skip not $to_quantize.value
fp16_weights = ov_model_path.with_suffix('.bin')
quantized_weights = quantized_model_path.with_suffix('.bin')
print(f"Size of FP16 model is {fp16_weights.stat().st_size / 1024 / 1024:.2f} MB")
print(f"Size of INT8 quantized model is {quantized_weights.stat().st_size / 1024 / 1024:.2f} MB")
print(f"Compression rate for INT8 model: {fp16_weights.stat().st_size / quantized_weights.stat().st_size:.3f}")
Size of FP16 model is 21.50 MB
Size of INT8 quantized model is 11.08 MB
Compression rate for INT8 model: 1.941
Compare inference time of the FP16 and INT8 models#
To measure the inference performance of the FP16 and INT8
models, we use bencmark_app.
NOTE: For the most accurate performance estimation, it is recommended to run
benchmark_appin a terminal/command prompt after closing other applications.
!benchmark_app -m $ov_model_path -d $device.value -data_shape "batched_images[1,3,512,512],batched_points[1,1,2,2],batched_point_labels[1,1,2]" -t 15
[Step 1/11] Parsing and validating input arguments [ INFO ] Parsing input parameters [Step 2/11] Loading OpenVINO Runtime [ INFO ] OpenVINO: [ INFO ] Build ................................. 2024.4.0-16579-c3152d32c9c-releases/2024/4 [ INFO ] [ INFO ] Device info: [ INFO ] AUTO [ INFO ] Build ................................. 2024.4.0-16579-c3152d32c9c-releases/2024/4 [ INFO ] [ INFO ] [Step 3/11] Setting device configuration [ WARNING ] Performance hint was not explicitly specified in command line. Device(AUTO) performance hint will be set to PerformanceMode.THROUGHPUT. [Step 4/11] Reading model files [ INFO ] Loading model files [ INFO ] Read model took 30.05 ms [ INFO ] Original model I/O parameters: [ INFO ] Model inputs: [ INFO ] batched_images (node: batched_images) : f32 / [...] / [?,?,?,?] [ INFO ] batched_points (node: batched_points) : i64 / [...] / [?,?,?,?] [ INFO ] batched_point_labels (node: batched_point_labels) : i64 / [...] / [?,?,?] [ INFO ] Model outputs: [ INFO ] *NO_NAME* (node: aten::reshape/Reshape_3) : f32 / [...] / [?,?,?,?,?] [ INFO ] *NO_NAME* (node: aten::reshape/Reshape_2) : f32 / [...] / [?,?,?] [Step 5/11] Resizing model to match image sizes and given batch [ INFO ] Model batch size: 1 [Step 6/11] Configuring input of the model [ INFO ] Model inputs: [ INFO ] batched_images (node: batched_images) : f32 / [...] / [?,?,?,?] [ INFO ] batched_points (node: batched_points) : i64 / [...] / [?,?,?,?] [ INFO ] batched_point_labels (node: batched_point_labels) : i64 / [...] / [?,?,?] [ INFO ] Model outputs: [ INFO ] *NO_NAME* (node: aten::reshape/Reshape_3) : f32 / [...] / [?,?,?,?,?] [ INFO ] *NO_NAME* (node: aten::reshape/Reshape_2) : f32 / [...] / [?,?,?] [Step 7/11] Loading the model to the device [ INFO ] Compile model took 1420.20 ms [Step 8/11] Querying optimal runtime parameters [ INFO ] Model: [ INFO ] NETWORK_NAME: Model0 [ INFO ] EXECUTION_DEVICES: ['CPU'] [ INFO ] PERFORMANCE_HINT: PerformanceMode.THROUGHPUT [ INFO ] OPTIMAL_NUMBER_OF_INFER_REQUESTS: 6 [ INFO ] MULTI_DEVICE_PRIORITIES: CPU [ INFO ] CPU: [ INFO ] AFFINITY: Affinity.CORE [ INFO ] CPU_DENORMALS_OPTIMIZATION: False [ INFO ] CPU_SPARSE_WEIGHTS_DECOMPRESSION_RATE: 1.0 [ INFO ] DYNAMIC_QUANTIZATION_GROUP_SIZE: 32 [ INFO ] ENABLE_CPU_PINNING: True [ INFO ] ENABLE_HYPER_THREADING: True [ INFO ] EXECUTION_DEVICES: ['CPU'] [ INFO ] EXECUTION_MODE_HINT: ExecutionMode.PERFORMANCE [ INFO ] INFERENCE_NUM_THREADS: 24 [ INFO ] INFERENCE_PRECISION_HINT: <Type: 'float32'> [ INFO ] KV_CACHE_PRECISION: <Type: 'float16'> [ INFO ] LOG_LEVEL: Level.NO [ INFO ] MODEL_DISTRIBUTION_POLICY: set() [ INFO ] NETWORK_NAME: Model0 [ INFO ] NUM_STREAMS: 6 [ INFO ] OPTIMAL_NUMBER_OF_INFER_REQUESTS: 6 [ INFO ] PERFORMANCE_HINT: THROUGHPUT [ INFO ] PERFORMANCE_HINT_NUM_REQUESTS: 0 [ INFO ] PERF_COUNT: NO [ INFO ] SCHEDULING_CORE_TYPE: SchedulingCoreType.ANY_CORE [ INFO ] MODEL_PRIORITY: Priority.MEDIUM [ INFO ] LOADED_FROM_CACHE: False [ INFO ] PERF_COUNT: False [Step 9/11] Creating infer requests and preparing input tensors [ WARNING ] No input files were given for input 'batched_images'!. This input will be filled with random values! [ WARNING ] No input files were given for input 'batched_points'!. This input will be filled with random values! [ WARNING ] No input files were given for input 'batched_point_labels'!. This input will be filled with random values! [ INFO ] Fill input 'batched_images' with random values [ INFO ] Fill input 'batched_points' with random values [ INFO ] Fill input 'batched_point_labels' with random values [Step 10/11] Measuring performance (Start inference asynchronously, 6 inference requests, limits: 15000 ms duration) [ INFO ] Benchmarking in full mode (inputs filling are included in measurement loop). [ INFO ] First inference took 795.15 ms [Step 11/11] Dumping statistics report [ INFO ] Execution Devices:['CPU'] [ INFO ] Count: 53 iterations [ INFO ] Duration: 16627.52 ms [ INFO ] Latency: [ INFO ] Median: 1878.09 ms [ INFO ] Average: 1853.13 ms [ INFO ] Min: 1337.08 ms [ INFO ] Max: 2026.48 ms [ INFO ] Throughput: 3.19 FPS
if to_quantize.value:
!benchmark_app -m $quantized_model_path -d $device.value -data_shape "batched_images[1,3,512,512],batched_points[1,1,2,2],batched_point_labels[1,1,2]" -t 15
[Step 1/11] Parsing and validating input arguments [ INFO ] Parsing input parameters [Step 2/11] Loading OpenVINO Runtime [ INFO ] OpenVINO: [ INFO ] Build ................................. 2024.4.0-16579-c3152d32c9c-releases/2024/4 [ INFO ] [ INFO ] Device info: [ INFO ] AUTO [ INFO ] Build ................................. 2024.4.0-16579-c3152d32c9c-releases/2024/4 [ INFO ] [ INFO ] [Step 3/11] Setting device configuration [ WARNING ] Performance hint was not explicitly specified in command line. Device(AUTO) performance hint will be set to PerformanceMode.THROUGHPUT. [Step 4/11] Reading model files [ INFO ] Loading model files [ INFO ] Read model took 44.76 ms [ INFO ] Original model I/O parameters: [ INFO ] Model inputs: [ INFO ] batched_images (node: batched_images) : f32 / [...] / [?,?,?,?] [ INFO ] batched_points (node: batched_points) : i64 / [...] / [?,?,?,?] [ INFO ] batched_point_labels (node: batched_point_labels) : i64 / [...] / [?,?,?] [ INFO ] Model outputs: [ INFO ] *NO_NAME* (node: aten::reshape/Reshape_3) : f32 / [...] / [?,?,?,?,?] [ INFO ] *NO_NAME* (node: aten::reshape/Reshape_2) : f32 / [...] / [?,?,?] [Step 5/11] Resizing model to match image sizes and given batch [ INFO ] Model batch size: 1 [Step 6/11] Configuring input of the model [ INFO ] Model inputs: [ INFO ] batched_images (node: batched_images) : f32 / [...] / [?,?,?,?] [ INFO ] batched_points (node: batched_points) : i64 / [...] / [?,?,?,?] [ INFO ] batched_point_labels (node: batched_point_labels) : i64 / [...] / [?,?,?] [ INFO ] Model outputs: [ INFO ] *NO_NAME* (node: aten::reshape/Reshape_3) : f32 / [...] / [?,?,?,?,?] [ INFO ] *NO_NAME* (node: aten::reshape/Reshape_2) : f32 / [...] / [?,?,?] [Step 7/11] Loading the model to the device [ INFO ] Compile model took 1630.00 ms [Step 8/11] Querying optimal runtime parameters [ INFO ] Model: [ INFO ] NETWORK_NAME: Model0 [ INFO ] EXECUTION_DEVICES: ['CPU'] [ INFO ] PERFORMANCE_HINT: PerformanceMode.THROUGHPUT [ INFO ] OPTIMAL_NUMBER_OF_INFER_REQUESTS: 6 [ INFO ] MULTI_DEVICE_PRIORITIES: CPU [ INFO ] CPU: [ INFO ] AFFINITY: Affinity.CORE [ INFO ] CPU_DENORMALS_OPTIMIZATION: False [ INFO ] CPU_SPARSE_WEIGHTS_DECOMPRESSION_RATE: 1.0 [ INFO ] DYNAMIC_QUANTIZATION_GROUP_SIZE: 32 [ INFO ] ENABLE_CPU_PINNING: True [ INFO ] ENABLE_HYPER_THREADING: True [ INFO ] EXECUTION_DEVICES: ['CPU'] [ INFO ] EXECUTION_MODE_HINT: ExecutionMode.PERFORMANCE [ INFO ] INFERENCE_NUM_THREADS: 24 [ INFO ] INFERENCE_PRECISION_HINT: <Type: 'float32'> [ INFO ] KV_CACHE_PRECISION: <Type: 'float16'> [ INFO ] LOG_LEVEL: Level.NO [ INFO ] MODEL_DISTRIBUTION_POLICY: set() [ INFO ] NETWORK_NAME: Model0 [ INFO ] NUM_STREAMS: 6 [ INFO ] OPTIMAL_NUMBER_OF_INFER_REQUESTS: 6 [ INFO ] PERFORMANCE_HINT: THROUGHPUT [ INFO ] PERFORMANCE_HINT_NUM_REQUESTS: 0 [ INFO ] PERF_COUNT: NO [ INFO ] SCHEDULING_CORE_TYPE: SchedulingCoreType.ANY_CORE [ INFO ] MODEL_PRIORITY: Priority.MEDIUM [ INFO ] LOADED_FROM_CACHE: False [ INFO ] PERF_COUNT: False [Step 9/11] Creating infer requests and preparing input tensors [ WARNING ] No input files were given for input 'batched_images'!. This input will be filled with random values! [ WARNING ] No input files were given for input 'batched_points'!. This input will be filled with random values! [ WARNING ] No input files were given for input 'batched_point_labels'!. This input will be filled with random values! [ INFO ] Fill input 'batched_images' with random values [ INFO ] Fill input 'batched_points' with random values [ INFO ] Fill input 'batched_point_labels' with random values [Step 10/11] Measuring performance (Start inference asynchronously, 6 inference requests, limits: 15000 ms duration) [ INFO ] Benchmarking in full mode (inputs filling are included in measurement loop). [ INFO ] First inference took 574.01 ms [Step 11/11] Dumping statistics report [ INFO ] Execution Devices:['CPU'] [ INFO ] Count: 55 iterations [ INFO ] Duration: 15877.41 ms [ INFO ] Latency: [ INFO ] Median: 1710.77 ms [ INFO ] Average: 1697.13 ms [ INFO ] Min: 583.87 ms [ INFO ] Max: 1826.89 ms [ INFO ] Throughput: 3.46 FPS
Interactive segmentation demo#
import numpy as np
from PIL import Image
import cv2
import matplotlib.pyplot as plt
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def format_results(masks, scores, logits, filter=0):
annotations = []
n = len(scores)
for i in range(n):
annotation = {}
mask = masks[i]
tmp = np.where(mask != 0)
if np.sum(mask) < filter:
continue
annotation["id"] = i
annotation["segmentation"] = mask
annotation["bbox"] = [
np.min(tmp[0]),
np.min(tmp[1]),
np.max(tmp[1]),
np.max(tmp[0]),
]
annotation["score"] = scores[i]
annotation["area"] = annotation["segmentation"].sum()
annotations.append(annotation)
return annotations
def point_prompt(masks, points, point_label, target_height, target_width): # numpy
h = masks[0]["segmentation"].shape[0]
w = masks[0]["segmentation"].shape[1]
if h != target_height or w != target_width:
points = [[int(point[0] * w / target_width), int(point[1] * h / target_height)] for point in points]
onemask = np.zeros((h, w))
for i, annotation in enumerate(masks):
if isinstance(annotation, dict):
mask = annotation["segmentation"]
else:
mask = annotation
for i, point in enumerate(points):
if point[1] < mask.shape[0] and point[0] < mask.shape[1]:
if mask[point[1], point[0]] == 1 and point_label[i] == 1:
onemask += mask
if mask[point[1], point[0]] == 1 and point_label[i] == 0:
onemask -= mask
onemask = onemask >= 1
return onemask, 0
def show_mask(
annotation,
ax,
random_color=False,
bbox=None,
retinamask=True,
target_height=960,
target_width=960,
):
mask_sum = annotation.shape[0]
height = annotation.shape[1]
weight = annotation.shape[2]
# annotation is sorted by area
areas = np.sum(annotation, axis=(1, 2))
sorted_indices = np.argsort(areas)[::1]
annotation = annotation[sorted_indices]
index = (annotation != 0).argmax(axis=0)
if random_color:
color = np.random.random((mask_sum, 1, 1, 3))
else:
color = np.ones((mask_sum, 1, 1, 3)) * np.array([30 / 255, 144 / 255, 255 / 255])
transparency = np.ones((mask_sum, 1, 1, 1)) * 0.6
visual = np.concatenate([color, transparency], axis=-1)
mask_image = np.expand_dims(annotation, -1) * visual
mask = np.zeros((height, weight, 4))
h_indices, w_indices = np.meshgrid(np.arange(height), np.arange(weight), indexing="ij")
indices = (index[h_indices, w_indices], h_indices, w_indices, slice(None))
mask[h_indices, w_indices, :] = mask_image[indices]
if bbox is not None:
x1, y1, x2, y2 = bbox
ax.add_patch(plt.Rectangle((x1, y1), x2 - x1, y2 - y1, fill=False, edgecolor="b", linewidth=1))
if not retinamask:
mask = cv2.resize(mask, (target_width, target_height), interpolation=cv2.INTER_NEAREST)
return mask
def process(
annotations,
image,
scale,
better_quality=False,
mask_random_color=True,
bbox=None,
points=None,
use_retina=True,
withContours=True,
):
if isinstance(annotations[0], dict):
annotations = [annotation["segmentation"] for annotation in annotations]
original_h = image.height
original_w = image.width
if better_quality:
if isinstance(annotations[0], torch.Tensor):
annotations = np.array(annotations)
for i, mask in enumerate(annotations):
mask = cv2.morphologyEx(mask.astype(np.uint8), cv2.MORPH_CLOSE, np.ones((3, 3), np.uint8))
annotations[i] = cv2.morphologyEx(mask.astype(np.uint8), cv2.MORPH_OPEN, np.ones((8, 8), np.uint8))
annotations = np.array(annotations)
inner_mask = show_mask(
annotations,
plt.gca(),
random_color=mask_random_color,
bbox=bbox,
retinamask=use_retina,
target_height=original_h,
target_width=original_w,
)
if isinstance(annotations, torch.Tensor):
annotations = annotations.cpu().numpy()
if withContours:
contour_all = []
temp = np.zeros((original_h, original_w, 1))
for i, mask in enumerate(annotations):
if isinstance(mask, dict):
mask = mask["segmentation"]
annotation = mask.astype(np.uint8)
if not use_retina:
annotation = cv2.resize(
annotation,
(original_w, original_h),
interpolation=cv2.INTER_NEAREST,
)
contours, _ = cv2.findContours(annotation, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
for contour in contours:
contour_all.append(contour)
cv2.drawContours(temp, contour_all, -1, (255, 255, 255), 2 // scale)
color = np.array([0 / 255, 0 / 255, 255 / 255, 0.9])
contour_mask = temp / 255 * color.reshape(1, 1, -1)
image = image.convert("RGBA")
overlay_inner = Image.fromarray((inner_mask * 255).astype(np.uint8), "RGBA")
image.paste(overlay_inner, (0, 0), overlay_inner)
if withContours:
overlay_contour = Image.fromarray((contour_mask * 255).astype(np.uint8), "RGBA")
image.paste(overlay_contour, (0, 0), overlay_contour)
return image
def segment_with_boxs(
image,
seg_image,
global_points,
global_point_label,
input_size=1024,
better_quality=False,
withContours=True,
use_retina=True,
mask_random_color=True,
):
if global_points is None or len(global_points) < 2 or global_points[0] is None:
return image, global_points, global_point_label
input_size = int(input_size)
w, h = image.size
scale = input_size / max(w, h)
new_w = int(w * scale)
new_h = int(h * scale)
image = image.resize((new_w, new_h))
scaled_points = np.array([[int(x * scale) for x in point] for point in global_points])
scaled_points = scaled_points[:2]
scaled_point_label = np.array(global_point_label)[:2]
if scaled_points.size == 0 and scaled_point_label.size == 0:
return image, global_points, global_point_label
nd_image = np.array(image)
img_tensor = nd_image.astype(np.float32) / 255
img_tensor = np.transpose(img_tensor, (2, 0, 1))
pts_sampled = np.reshape(scaled_points, [1, 1, -1, 2])
pts_sampled = pts_sampled[:, :, :2, :]
pts_labels = np.reshape(np.array([2, 3]), [1, 1, 2])
results = compiled_model([img_tensor[None, ...], pts_sampled, pts_labels])
predicted_logits = results[0]
predicted_iou = results[1]
all_masks = sigmoid(predicted_logits[0, 0, :, :, :]) >= 0.5
predicted_iou = predicted_iou[0, 0, ...]
max_predicted_iou = -1
selected_mask_using_predicted_iou = None
selected_predicted_iou = None
for m in range(all_masks.shape[0]):
curr_predicted_iou = predicted_iou[m]
if curr_predicted_iou > max_predicted_iou or selected_mask_using_predicted_iou is None:
max_predicted_iou = curr_predicted_iou
selected_mask_using_predicted_iou = all_masks[m : m + 1]
selected_predicted_iou = predicted_iou[m : m + 1]
results = format_results(selected_mask_using_predicted_iou, selected_predicted_iou, predicted_logits, 0)
annotations = results[0]["segmentation"]
annotations = np.array([annotations])
fig = process(
annotations=annotations,
image=image,
scale=(1024 // input_size),
better_quality=better_quality,
mask_random_color=mask_random_color,
use_retina=use_retina,
bbox=scaled_points.reshape([4]),
withContours=withContours,
)
global_points = []
global_point_label = []
return fig, global_points, global_point_label
def segment_with_points(
image,
global_points,
global_point_label,
input_size=1024,
better_quality=False,
withContours=True,
use_retina=True,
mask_random_color=True,
):
input_size = int(input_size)
w, h = image.size
scale = input_size / max(w, h)
new_w = int(w * scale)
new_h = int(h * scale)
image = image.resize((new_w, new_h))
if global_points is None or len(global_points) < 1 or global_points[0] is None:
return image, global_points, global_point_label
scaled_points = np.array([[int(x * scale) for x in point] for point in global_points])
scaled_point_label = np.array(global_point_label)
if scaled_points.size == 0 and scaled_point_label.size == 0:
return image, global_points, global_point_label
nd_image = np.array(image)
img_tensor = (nd_image).astype(np.float32) / 255
img_tensor = np.transpose(img_tensor, (2, 0, 1))
pts_sampled = np.reshape(scaled_points, [1, 1, -1, 2])
pts_labels = np.reshape(np.array(global_point_label), [1, 1, -1])
results = compiled_model([img_tensor[None, ...], pts_sampled, pts_labels])
predicted_logits = results[0]
predicted_iou = results[1]
all_masks = sigmoid(predicted_logits[0, 0, :, :, :]) >= 0.5
predicted_iou = predicted_iou[0, 0, ...]
results = format_results(all_masks, predicted_iou, predicted_logits, 0)
annotations, _ = point_prompt(results, scaled_points, scaled_point_label, new_h, new_w)
annotations = np.array([annotations])
fig = process(
annotations=annotations,
image=image,
scale=(1024 // input_size),
better_quality=better_quality,
mask_random_color=mask_random_color,
points=scaled_points,
bbox=None,
use_retina=use_retina,
withContours=withContours,
)
global_points = []
global_point_label = []
# return fig, None
return fig, global_points, global_point_label
# Go back to the efficient-sam notebook directory
%cd ..
if not Path("gradio_helper.py").exists():
r = requests.get(url="https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/notebooks/efficient-sam/gradio_helper.py")
open("gradio_helper.py", "w").write(r.text)
from gradio_helper import make_demo
demo = make_demo(segment_with_point_fn=segment_with_points, segment_with_box_fn=segment_with_boxs)
try:
demo.queue().launch(debug=False)
except Exception:
demo.queue().launch(share=True, debug=False)
# if you are launching remotely, specify server_name and server_port
# demo.launch(server_name='your server name', server_port='server port in int')
# Read more in the docs: https://gradio.app/docs/
/opt/home/k8sworker/ci-ai/cibuilds/jobs/ov-notebook/jobs/OVNotebookOps/builds/875/archive/.workspace/scm/ov-notebook/notebooks/efficient-sam Running on local URL: http://127.0.0.1:7860 To create a public link, set share=True in launch().