Image-to-Video synthesis with AnimateAnyone and OpenVINO#
This Jupyter notebook can be launched after a local installation only.

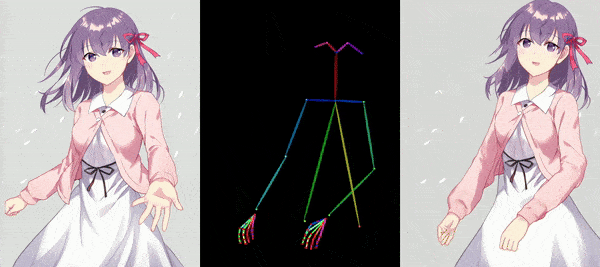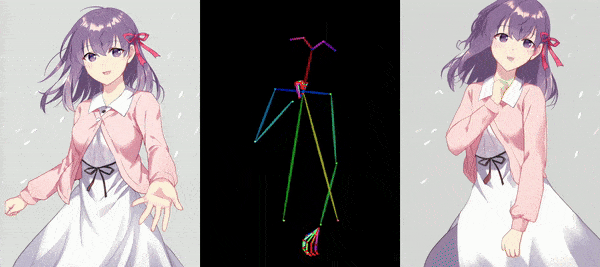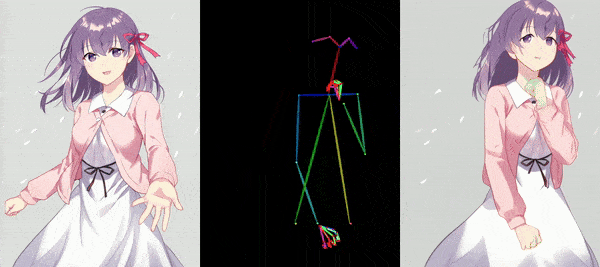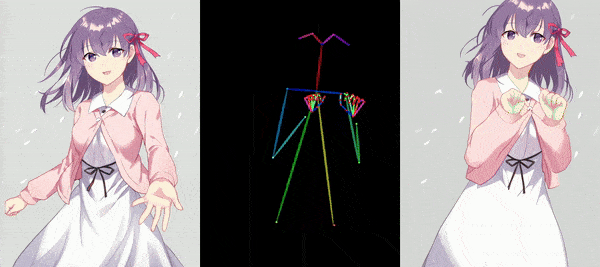
AnimateAnyone tackles the task of generating animation sequences from a single character image. It builds upon diffusion models pre-trained on vast character image datasets.
The core of AnimateAnyone is a diffusion model pre-trained on a massive dataset of character images. This model learns the underlying character representation and distribution, allowing for realistic and diverse character animation. To capture the specific details and characteristics of the input character image, AnimateAnyone incorporates a ReferenceNet module. This module acts like an attention mechanism, focusing on the input image and guiding the animation process to stay consistent with the original character’s appearance. AnimateAnyone enables control over the character’s pose during animation. This might involve using techniques like parametric pose embedding or direct pose vector input, allowing for the creation of various character actions and movements. To ensure smooth transitions and temporal coherence throughout the animation sequence, AnimateAnyone incorporates temporal modeling techniques. This may involve recurrent architectures like LSTMs or transformers that capture the temporal dependencies between video frames.
Overall, AnimateAnyone combines a powerful pre-trained diffusion model with a character-specific attention mechanism (ReferenceNet), pose guidance, and temporal modeling to achieve controllable, high-fidelity character animation from a single image.
Learn more in GitHub repo and paper.
<p style="font-size:1.25em"><b>! WARNING !</b></p>
<p>
This tutorial requires at least <b>96 GB</b> of RAM for model conversion and <b>40 GB</b> for inference. Changing the values of <code>HEIGHT</code>, <code>WIDTH</code> and <code>VIDEO_LENGTH</code> variables will change the memory consumption but will also affect accuracy.
</p>
Table of contents:
This is a self-contained example that relies solely on its own code.
We recommend running the notebook in a virtual environment. You only need a Jupyter server to start. For details, please refer to Installation Guide.
Prerequisites#
from pathlib import Path
import requests
%pip install -q "torch>=2.1" torchvision einops omegaconf "diffusers<=0.24" "huggingface-hub<0.26.0" transformers av accelerate "gradio>=4.19" --extra-index-url "https://download.pytorch.org/whl/cpu"
%pip install -q "openvino>=2024.0" "nncf>=2.9.0"
helpers = ["skip_kernel_extension.py", "notebook_utils.py", "cmd_helper.py"]
for file_name in helpers:
if not Path(file_name).exists():
r = requests.get(
url=f"https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/utils/{file_name}",
)
open(file_name, "w").write(r.text)
from cmd_helper import clone_repo
clone_repo("https://github.com/itrushkin/Moore-AnimateAnyone.git")
%load_ext skip_kernel_extension
# Read more about telemetry collection at https://github.com/openvinotoolkit/openvino_notebooks?tab=readme-ov-file#-telemetry
from notebook_utils import collect_telemetry
collect_telemetry("animate-anyone.ipynb")
Note: you may need to restart the kernel to use updated packages.
Note: you may need to restart the kernel to use updated packages.
Note that we clone a fork of original repo with tweaked forward methods.
MODEL_DIR = Path("models")
VAE_ENCODER_PATH = MODEL_DIR / "vae_encoder.xml"
VAE_DECODER_PATH = MODEL_DIR / "vae_decoder.xml"
REFERENCE_UNET_PATH = MODEL_DIR / "reference_unet.xml"
DENOISING_UNET_PATH = MODEL_DIR / "denoising_unet.xml"
POSE_GUIDER_PATH = MODEL_DIR / "pose_guider.xml"
IMAGE_ENCODER_PATH = MODEL_DIR / "image_encoder.xml"
WIDTH = 448
HEIGHT = 512
VIDEO_LENGTH = 24
SHOULD_CONVERT = not all(
p.exists()
for p in [
VAE_ENCODER_PATH,
VAE_DECODER_PATH,
REFERENCE_UNET_PATH,
DENOISING_UNET_PATH,
POSE_GUIDER_PATH,
IMAGE_ENCODER_PATH,
]
)
from datetime import datetime
from typing import Optional, Union, List, Callable
import math
from PIL import Image
import openvino as ov
from torchvision import transforms
from einops import repeat
from tqdm.auto import tqdm
from einops import rearrange
from omegaconf import OmegaConf
from diffusers import DDIMScheduler
from diffusers.image_processor import VaeImageProcessor
from transformers import CLIPImageProcessor
import torch
from src.pipelines.pipeline_pose2vid_long import Pose2VideoPipeline
from src.utils.util import get_fps, read_frames
from src.utils.util import save_videos_grid
from src.pipelines.context import get_context_scheduler
/opt/home/k8sworker/ci-ai/cibuilds/jobs/ov-notebook/jobs/OVNotebookOps/builds/875/archive/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/diffusers/utils/outputs.py:63: FutureWarning: torch.utils._pytree._register_pytree_node is deprecated. Please use torch.utils._pytree.register_pytree_node instead. torch.utils._pytree._register_pytree_node( /opt/home/k8sworker/ci-ai/cibuilds/jobs/ov-notebook/jobs/OVNotebookOps/builds/875/archive/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/diffusers/utils/outputs.py:63: FutureWarning: torch.utils._pytree._register_pytree_node is deprecated. Please use torch.utils._pytree.register_pytree_node instead. torch.utils._pytree._register_pytree_node(
%%skip not $SHOULD_CONVERT
from pathlib import PurePosixPath
import gc
import warnings
from typing import Dict, Any
from diffusers import AutoencoderKL
from huggingface_hub import hf_hub_download, snapshot_download
from transformers import CLIPVisionModelWithProjection
import nncf
from src.models.unet_2d_condition import UNet2DConditionModel
from src.models.unet_3d import UNet3DConditionModel
from src.models.pose_guider import PoseGuider
INFO:nncf:NNCF initialized successfully. Supported frameworks detected: torch, openvino
Prepare base model#
%%skip not $SHOULD_CONVERT
local_dir = Path("./pretrained_weights/stable-diffusion-v1-5")
local_dir.mkdir(parents=True, exist_ok=True)
for hub_file in ["unet/config.json", "unet/diffusion_pytorch_model.bin"]:
saved_path = local_dir / hub_file
if saved_path.exists():
continue
hf_hub_download(
repo_id="botp/stable-diffusion-v1-5",
subfolder=PurePosixPath(saved_path.parent.name),
filename=PurePosixPath(saved_path.name),
local_dir=local_dir,
)
diffusion_pytorch_model.bin: 0%| | 0.00/3.44G [00:00<?, ?B/s]
Prepare image encoder#
%%skip not $SHOULD_CONVERT
local_dir = Path("./pretrained_weights")
local_dir.mkdir(parents=True, exist_ok=True)
for hub_file in ["image_encoder/config.json", "image_encoder/pytorch_model.bin"]:
saved_path = local_dir / hub_file
if saved_path.exists():
continue
hf_hub_download(
repo_id="lambdalabs/sd-image-variations-diffusers",
subfolder=PurePosixPath(saved_path.parent.name),
filename=PurePosixPath(saved_path.name),
local_dir=local_dir,
)
image_encoder/config.json: 0%| | 0.00/703 [00:00<?, ?B/s]
pytorch_model.bin: 0%| | 0.00/1.22G [00:00<?, ?B/s]
Download weights#
%%skip not $SHOULD_CONVERT
snapshot_download(
repo_id="stabilityai/sd-vae-ft-mse", local_dir="./pretrained_weights/sd-vae-ft-mse"
)
snapshot_download(
repo_id="patrolli/AnimateAnyone",
local_dir="./pretrained_weights",
)
Fetching 5 files: 0%| | 0/5 [00:00<?, ?it/s]
.gitattributes: 0%| | 0.00/1.46k [00:00<?, ?B/s]
README.md: 0%| | 0.00/6.84k [00:00<?, ?B/s]
diffusion_pytorch_model.bin: 0%| | 0.00/335M [00:00<?, ?B/s]
Fetching 6 files: 0%| | 0/6 [00:00<?, ?it/s]
.gitattributes: 0%| | 0.00/1.52k [00:00<?, ?B/s]
denoising_unet.pth: 0%| | 0.00/3.44G [00:00<?, ?B/s]
motion_module.pth: 0%| | 0.00/1.82G [00:00<?, ?B/s]
pose_guider.pth: 0%| | 0.00/4.35M [00:00<?, ?B/s]
README.md: 0%| | 0.00/154 [00:00<?, ?B/s]
reference_unet.pth: 0%| | 0.00/3.44G [00:00<?, ?B/s]
config = OmegaConf.load("Moore-AnimateAnyone/configs/prompts/animation.yaml")
infer_config = OmegaConf.load("Moore-AnimateAnyone/" + config.inference_config)
Initialize models#
%%skip not $SHOULD_CONVERT
vae = AutoencoderKL.from_pretrained(config.pretrained_vae_path)
reference_unet = UNet2DConditionModel.from_pretrained(config.pretrained_base_model_path, subfolder="unet")
denoising_unet = UNet3DConditionModel.from_pretrained_2d(
config.pretrained_base_model_path,
config.motion_module_path,
subfolder="unet",
unet_additional_kwargs=infer_config.unet_additional_kwargs,
)
pose_guider = PoseGuider(320, block_out_channels=(16, 32, 96, 256))
image_enc = CLIPVisionModelWithProjection.from_pretrained(config.image_encoder_path)
NUM_CHANNELS_LATENTS = denoising_unet.config.in_channels
/opt/home/k8sworker/ci-ai/cibuilds/jobs/ov-notebook/jobs/OVNotebookOps/builds/875/archive/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/diffusers/models/modeling_utils.py:109: FutureWarning: You are using torch.load with weights_only=False (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See pytorch/pytorch for more details). In a future release, the default value for weights_only will be flipped to True. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via torch.serialization.add_safe_globals. We recommend you start setting weights_only=True for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature. return torch.load(checkpoint_file, map_location="cpu") Some weights of the model checkpoint were not used when initializing UNet2DConditionModel: ['conv_norm_out.weight, conv_norm_out.bias, conv_out.weight, conv_out.bias']
Load pretrained weights#
%%skip not $SHOULD_CONVERT
denoising_unet.load_state_dict(
torch.load(config.denoising_unet_path, map_location="cpu"),
strict=False,
)
reference_unet.load_state_dict(
torch.load(config.reference_unet_path, map_location="cpu"),
)
pose_guider.load_state_dict(
torch.load(config.pose_guider_path, map_location="cpu"),
)
<string>:2: FutureWarning: You are using torch.load with weights_only=False (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See pytorch/pytorch for more details). In a future release, the default value for weights_only will be flipped to True. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via torch.serialization.add_safe_globals. We recommend you start setting weights_only=True for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature. <string>:6: FutureWarning: You are using torch.load with weights_only=False (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See pytorch/pytorch for more details). In a future release, the default value for weights_only will be flipped to True. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via torch.serialization.add_safe_globals. We recommend you start setting weights_only=True for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature. <string>:9: FutureWarning: You are using torch.load with weights_only=False (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See pytorch/pytorch for more details). In a future release, the default value for weights_only will be flipped to True. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via torch.serialization.add_safe_globals. We recommend you start setting weights_only=True for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature.
Convert model to OpenVINO IR#
The pose sequence is initially encoded using Pose Guider and fused with multi-frame noise, followed by the Denoising UNet conducting the denoising process for video generation. The computational block of the Denoising UNet consists of Spatial-Attention, Cross-Attention, and Temporal-Attention, as illustrated in the dashed box on the right. The integration of reference image involves two aspects. Firstly, detailed features are extracted through ReferenceNet and utilized for Spatial-Attention. Secondly, semantic features are extracted through the CLIP image encoder for Cross-Attention. Temporal-Attention operates in the temporal dimension. Finally, the VAE decoder decodes the result into a video clip.
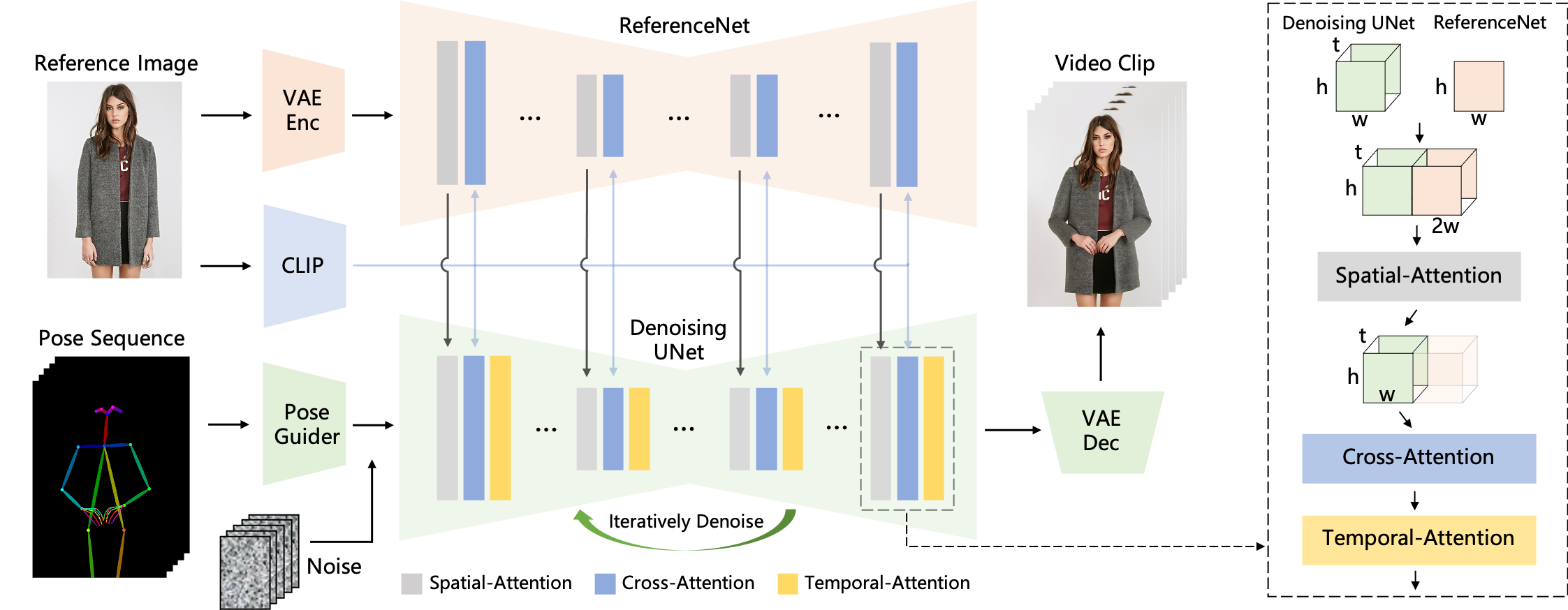
The pipeline contains 6 PyTorch modules:
VAE encoder
VAE decoder
Image encoder
Reference UNet
Denoising UNet
Pose Guider
For reducing memory consumption, weights compression optimization can be applied using NNCF. Weight compression aims to reduce the memory footprint of a model. models, which require extensive memory to store the weights during inference, can benefit from weight compression in the following ways:
enabling the inference of exceptionally large models that cannot be accommodated in the memory of the device;
improving the inference performance of the models by reducing the latency of the memory access when computing the operations with weights, for example, Linear layers.
Neural Network Compression Framework (NNCF) provides 4-bit / 8-bit mixed weight quantization as a compression method. The main difference between weights compression and full model quantization (post-training quantization) is that activations remain floating-point in the case of weights compression which leads to a better accuracy. In addition, weight compression is data-free and does not require a calibration dataset, making it easy to use.
nncf.compress_weights function can be used for performing weights
compression. The function accepts an OpenVINO model and other
compression parameters.
More details about weights compression can be found in OpenVINO documentation.
%%skip not $SHOULD_CONVERT
def cleanup_torchscript_cache():
"""
Helper for removing cached model representation
"""
torch._C._jit_clear_class_registry()
torch.jit._recursive.concrete_type_store = torch.jit._recursive.ConcreteTypeStore()
torch.jit._state._clear_class_state()
%%skip not $SHOULD_CONVERT
warnings.simplefilter("ignore", torch.jit.TracerWarning)
VAE#
The VAE model has two parts, an encoder and a decoder. The encoder is used to convert the image into a low dimensional latent representation, which will serve as the input to the U-Net model. The decoder, conversely, transforms the latent representation back into an image.
During latent diffusion training, the encoder is used to get the latent representations (latents) of the images for the forward diffusion process, which applies more and more noise at each step. During inference, the denoised latents generated by the reverse diffusion process are converted back into images using the VAE decoder.
As the encoder and the decoder are used independently in different parts of the pipeline, it will be better to convert them to separate models.
%%skip not $SHOULD_CONVERT
if not VAE_ENCODER_PATH.exists():
class VaeEncoder(torch.nn.Module):
def __init__(self, vae):
super().__init__()
self.vae = vae
def forward(self, x):
return self.vae.encode(x).latent_dist.mean
vae.eval()
with torch.no_grad():
vae_encoder = ov.convert_model(VaeEncoder(vae), example_input=torch.zeros(1,3,512,448))
vae_encoder = nncf.compress_weights(vae_encoder)
ov.save_model(vae_encoder, VAE_ENCODER_PATH)
del vae_encoder
cleanup_torchscript_cache()
INFO:nncf:Statistics of the bitwidth distribution:
┍━━━━━━━━━━━━━━━━┯━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┯━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┑
│ Num bits (N) │ % all parameters (layers) │ % ratio-defining parameters (layers) │
┝━━━━━━━━━━━━━━━━┿━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┿━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┥
│ 8 │ 100% (32 / 32) │ 100% (32 / 32) │
┕━━━━━━━━━━━━━━━━┷━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┷━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┙
Output()
%%skip not $SHOULD_CONVERT
if not VAE_DECODER_PATH.exists():
class VaeDecoder(torch.nn.Module):
def __init__(self, vae):
super().__init__()
self.vae = vae
def forward(self, z):
return self.vae.decode(z).sample
vae.eval()
with torch.no_grad():
vae_decoder = ov.convert_model(VaeDecoder(vae), example_input=torch.zeros(1,4,HEIGHT//8,WIDTH//8))
vae_decoder = nncf.compress_weights(vae_decoder)
ov.save_model(vae_decoder, VAE_DECODER_PATH)
del vae_decoder
cleanup_torchscript_cache()
del vae
gc.collect()
INFO:nncf:Statistics of the bitwidth distribution:
┍━━━━━━━━━━━━━━━━┯━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┯━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┑
│ Num bits (N) │ % all parameters (layers) │ % ratio-defining parameters (layers) │
┝━━━━━━━━━━━━━━━━┿━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┿━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┥
│ 8 │ 100% (40 / 40) │ 100% (40 / 40) │
┕━━━━━━━━━━━━━━━━┷━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┷━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┙
Output()
Reference UNet#
Pipeline extracts reference attention features from all transformer blocks inside Reference UNet model. We call the original forward pass to obtain shapes of the outputs as they will be used in the next pipeline step.
%%skip not $SHOULD_CONVERT
if not REFERENCE_UNET_PATH.exists():
class ReferenceUNetWrapper(torch.nn.Module):
def __init__(self, reference_unet):
super().__init__()
self.reference_unet = reference_unet
def forward(self, sample, timestep, encoder_hidden_states):
return self.reference_unet(sample, timestep, encoder_hidden_states, return_dict=False)[1]
sample = torch.zeros(2, 4, HEIGHT // 8, WIDTH // 8)
timestep = torch.tensor(0)
encoder_hidden_states = torch.zeros(2, 1, 768)
reference_unet.eval()
with torch.no_grad():
wrapper = ReferenceUNetWrapper(reference_unet)
example_input = (sample, timestep, encoder_hidden_states)
ref_features_shapes = {k: v.shape for k, v in wrapper(*example_input).items()}
ov_reference_unet = ov.convert_model(
wrapper,
example_input=example_input,
)
ov_reference_unet = nncf.compress_weights(ov_reference_unet)
ov.save_model(ov_reference_unet, REFERENCE_UNET_PATH)
del ov_reference_unet
del wrapper
cleanup_torchscript_cache()
del reference_unet
gc.collect()
INFO:nncf:Statistics of the bitwidth distribution:
┍━━━━━━━━━━━━━━━━┯━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┯━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┑
│ Num bits (N) │ % all parameters (layers) │ % ratio-defining parameters (layers) │
┝━━━━━━━━━━━━━━━━┿━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┿━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┥
│ 8 │ 100% (270 / 270) │ 100% (270 / 270) │
┕━━━━━━━━━━━━━━━━┷━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┷━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┙
Output()
Denoising UNet#
Denoising UNet is the main part of all diffusion pipelines. This model consumes the majority of memory, so we need to reduce its size as much as possible.
Here we make all shapes static meaning that the size of the video will be constant.
Also, we use the ref_features input with the same tensor shapes as
output of Reference UNet model on the previous
step.
%%skip not $SHOULD_CONVERT
if not DENOISING_UNET_PATH.exists():
class DenoisingUNetWrapper(torch.nn.Module):
def __init__(self, denoising_unet):
super().__init__()
self.denoising_unet = denoising_unet
def forward(
self,
sample,
timestep,
encoder_hidden_states,
pose_cond_fea,
ref_features
):
return self.denoising_unet(
sample,
timestep,
encoder_hidden_states,
ref_features,
pose_cond_fea=pose_cond_fea,
return_dict=False)
example_input = {
"sample": torch.zeros(2, 4, VIDEO_LENGTH, HEIGHT // 8, WIDTH // 8),
"timestep": torch.tensor(999),
"encoder_hidden_states": torch.zeros(2,1,768),
"pose_cond_fea": torch.zeros(2, 320, VIDEO_LENGTH, HEIGHT // 8, WIDTH // 8),
"ref_features": {k: torch.zeros(shape) for k, shape in ref_features_shapes.items()}
}
denoising_unet.eval()
with torch.no_grad():
ov_denoising_unet = ov.convert_model(
DenoisingUNetWrapper(denoising_unet),
example_input=tuple(example_input.values())
)
ov_denoising_unet.inputs[0].get_node().set_partial_shape(ov.PartialShape((2, 4, VIDEO_LENGTH, HEIGHT // 8, WIDTH // 8)))
ov_denoising_unet.inputs[2].get_node().set_partial_shape(ov.PartialShape((2, 1, 768)))
ov_denoising_unet.inputs[3].get_node().set_partial_shape(ov.PartialShape((2, 320, VIDEO_LENGTH, HEIGHT // 8, WIDTH // 8)))
for ov_input, shape in zip(ov_denoising_unet.inputs[4:], ref_features_shapes.values()):
ov_input.get_node().set_partial_shape(ov.PartialShape(shape))
ov_input.get_node().set_element_type(ov.Type.f32)
ov_denoising_unet.validate_nodes_and_infer_types()
ov_denoising_unet = nncf.compress_weights(ov_denoising_unet)
ov.save_model(ov_denoising_unet, DENOISING_UNET_PATH)
del ov_denoising_unet
cleanup_torchscript_cache()
del denoising_unet
gc.collect()
INFO:nncf:Statistics of the bitwidth distribution:
┍━━━━━━━━━━━━━━━━┯━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┯━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┑
│ Num bits (N) │ % all parameters (layers) │ % ratio-defining parameters (layers) │
┝━━━━━━━━━━━━━━━━┿━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┿━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┥
│ 8 │ 100% (534 / 534) │ 100% (534 / 534) │
┕━━━━━━━━━━━━━━━━┷━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┷━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┙
Output()
Pose Guider#
To ensure pose controllability, a lightweight pose guider is devised to efficiently integrate pose control signals into the denoising process.
%%skip not $SHOULD_CONVERT
if not POSE_GUIDER_PATH.exists():
pose_guider.eval()
with torch.no_grad():
ov_pose_guider = ov.convert_model(pose_guider, example_input=torch.zeros(1, 3, VIDEO_LENGTH, HEIGHT, WIDTH))
ov_pose_guider = nncf.compress_weights(ov_pose_guider)
ov.save_model(ov_pose_guider, POSE_GUIDER_PATH)
del ov_pose_guider
cleanup_torchscript_cache()
del pose_guider
gc.collect()
INFO:nncf:Statistics of the bitwidth distribution:
┍━━━━━━━━━━━━━━━━┯━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┯━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┑
│ Num bits (N) │ % all parameters (layers) │ % ratio-defining parameters (layers) │
┝━━━━━━━━━━━━━━━━┿━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┿━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┥
│ 8 │ 100% (8 / 8) │ 100% (8 / 8) │
┕━━━━━━━━━━━━━━━━┷━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┷━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┙
Output()
Image Encoder#
Pipeline uses CLIP image encoder to generate encoder hidden states required for both reference and denoising UNets.
%%skip not $SHOULD_CONVERT
if not IMAGE_ENCODER_PATH.exists():
image_enc.eval()
with torch.no_grad():
ov_image_encoder = ov.convert_model(image_enc, example_input=torch.zeros(1, 3, 224, 224), input=(1, 3, 224, 224))
ov_image_encoder = nncf.compress_weights(ov_image_encoder)
ov.save_model(ov_image_encoder, IMAGE_ENCODER_PATH)
del ov_image_encoder
cleanup_torchscript_cache()
del image_enc
gc.collect()
/opt/home/k8sworker/ci-ai/cibuilds/jobs/ov-notebook/jobs/OVNotebookOps/builds/875/archive/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/transformers/modeling_utils.py:5006: FutureWarning: _is_quantized_training_enabled is going to be deprecated in transformers 4.39.0. Please use model.hf_quantizer.is_trainable instead warnings.warn( loss_type=None was set in the config but it is unrecognised.Using the default loss: ForCausalLMLoss.
INFO:nncf:Statistics of the bitwidth distribution:
┍━━━━━━━━━━━━━━━━┯━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┯━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┑
│ Num bits (N) │ % all parameters (layers) │ % ratio-defining parameters (layers) │
┝━━━━━━━━━━━━━━━━┿━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┿━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┥
│ 8 │ 100% (146 / 146) │ 100% (146 / 146) │
┕━━━━━━━━━━━━━━━━┷━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┷━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┙
Output()
Inference#
We inherit from the original pipeline modifying the calls to our models to match OpenVINO format.
core = ov.Core()
Select inference device#
For starting work, please select inference device from dropdown list.
from notebook_utils import device_widget
device = device_widget()
class OVPose2VideoPipeline(Pose2VideoPipeline):
def __init__(
self,
vae_encoder_path=VAE_ENCODER_PATH,
vae_decoder_path=VAE_DECODER_PATH,
image_encoder_path=IMAGE_ENCODER_PATH,
reference_unet_path=REFERENCE_UNET_PATH,
denoising_unet_path=DENOISING_UNET_PATH,
pose_guider_path=POSE_GUIDER_PATH,
device=device.value,
):
self.vae_encoder = core.compile_model(vae_encoder_path, device)
self.vae_decoder = core.compile_model(vae_decoder_path, device)
self.image_encoder = core.compile_model(image_encoder_path, device)
self.reference_unet = core.compile_model(reference_unet_path, device)
self.denoising_unet = core.compile_model(denoising_unet_path, device)
self.pose_guider = core.compile_model(pose_guider_path, device)
self.scheduler = DDIMScheduler(**OmegaConf.to_container(infer_config.noise_scheduler_kwargs))
self.vae_scale_factor = 8
self.clip_image_processor = CLIPImageProcessor()
self.ref_image_processor = VaeImageProcessor(do_convert_rgb=True)
self.cond_image_processor = VaeImageProcessor(do_convert_rgb=True, do_normalize=False)
def decode_latents(self, latents):
video_length = latents.shape[2]
latents = 1 / 0.18215 * latents
latents = rearrange(latents, "b c f h w -> (b f) c h w")
# video = self.vae.decode(latents).sample
video = []
for frame_idx in tqdm(range(latents.shape[0])):
video.append(torch.from_numpy(self.vae_decoder(latents[frame_idx : frame_idx + 1])[0]))
video = torch.cat(video)
video = rearrange(video, "(b f) c h w -> b c f h w", f=video_length)
video = (video / 2 + 0.5).clamp(0, 1)
# we always cast to float32 as this does not cause significant overhead and is compatible with bfloa16
video = video.cpu().float().numpy()
return video
def __call__(
self,
ref_image,
pose_images,
width,
height,
video_length,
num_inference_steps=30,
guidance_scale=3.5,
num_images_per_prompt=1,
eta: float = 0.0,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
output_type: Optional[str] = "tensor",
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: Optional[int] = 1,
context_schedule="uniform",
context_frames=24,
context_stride=1,
context_overlap=4,
context_batch_size=1,
interpolation_factor=1,
**kwargs,
):
do_classifier_free_guidance = guidance_scale > 1.0
# Prepare timesteps
self.scheduler.set_timesteps(num_inference_steps)
timesteps = self.scheduler.timesteps
batch_size = 1
# Prepare clip image embeds
clip_image = self.clip_image_processor.preprocess(ref_image.resize((224, 224)), return_tensors="pt").pixel_values
clip_image_embeds = self.image_encoder(clip_image)["image_embeds"]
clip_image_embeds = torch.from_numpy(clip_image_embeds)
encoder_hidden_states = clip_image_embeds.unsqueeze(1)
uncond_encoder_hidden_states = torch.zeros_like(encoder_hidden_states)
if do_classifier_free_guidance:
encoder_hidden_states = torch.cat([uncond_encoder_hidden_states, encoder_hidden_states], dim=0)
latents = self.prepare_latents(
batch_size * num_images_per_prompt,
4,
width,
height,
video_length,
clip_image_embeds.dtype,
torch.device("cpu"),
generator,
)
# Prepare extra step kwargs.
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
# Prepare ref image latents
ref_image_tensor = self.ref_image_processor.preprocess(ref_image, height=height, width=width) # (bs, c, width, height)
ref_image_latents = self.vae_encoder(ref_image_tensor)[0]
ref_image_latents = ref_image_latents * 0.18215 # (b, 4, h, w)
ref_image_latents = torch.from_numpy(ref_image_latents)
# Prepare a list of pose condition images
pose_cond_tensor_list = []
for pose_image in pose_images:
pose_cond_tensor = self.cond_image_processor.preprocess(pose_image, height=height, width=width)
pose_cond_tensor = pose_cond_tensor.unsqueeze(2) # (bs, c, 1, h, w)
pose_cond_tensor_list.append(pose_cond_tensor)
pose_cond_tensor = torch.cat(pose_cond_tensor_list, dim=2) # (bs, c, t, h, w)
pose_fea = self.pose_guider(pose_cond_tensor)[0]
pose_fea = torch.from_numpy(pose_fea)
context_scheduler = get_context_scheduler(context_schedule)
# denoising loop
num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
noise_pred = torch.zeros(
(
latents.shape[0] * (2 if do_classifier_free_guidance else 1),
*latents.shape[1:],
),
device=latents.device,
dtype=latents.dtype,
)
counter = torch.zeros(
(1, 1, latents.shape[2], 1, 1),
device=latents.device,
dtype=latents.dtype,
)
# 1. Forward reference image
if i == 0:
ref_features = self.reference_unet(
(
ref_image_latents.repeat((2 if do_classifier_free_guidance else 1), 1, 1, 1),
torch.zeros_like(t),
# t,
encoder_hidden_states,
)
).values()
context_queue = list(
context_scheduler(
0,
num_inference_steps,
latents.shape[2],
context_frames,
context_stride,
0,
)
)
num_context_batches = math.ceil(len(context_queue) / context_batch_size)
context_queue = list(
context_scheduler(
0,
num_inference_steps,
latents.shape[2],
context_frames,
context_stride,
context_overlap,
)
)
num_context_batches = math.ceil(len(context_queue) / context_batch_size)
global_context = []
for i in range(num_context_batches):
global_context.append(context_queue[i * context_batch_size : (i + 1) * context_batch_size])
for context in global_context:
# 3.1 expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents[:, :, c] for c in context]).repeat(2 if do_classifier_free_guidance else 1, 1, 1, 1, 1)
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
b, c, f, h, w = latent_model_input.shape
latent_pose_input = torch.cat([pose_fea[:, :, c] for c in context]).repeat(2 if do_classifier_free_guidance else 1, 1, 1, 1, 1)
pred = self.denoising_unet(
(
latent_model_input,
t,
encoder_hidden_states[:b],
latent_pose_input,
*ref_features,
)
)[0]
for j, c in enumerate(context):
noise_pred[:, :, c] = noise_pred[:, :, c] + pred
counter[:, :, c] = counter[:, :, c] + 1
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = (noise_pred / counter).chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
progress_bar.update()
if callback is not None and i % callback_steps == 0:
step_idx = i // getattr(self.scheduler, "order", 1)
callback(step_idx, t, latents)
if interpolation_factor > 0:
latents = self.interpolate_latents(latents, interpolation_factor, latents.device)
# Post-processing
images = self.decode_latents(latents) # (b, c, f, h, w)
# Convert to tensor
if output_type == "tensor":
images = torch.from_numpy(images)
return images
pipe = OVPose2VideoPipeline()
pose_images = read_frames("Moore-AnimateAnyone/configs/inference/pose_videos/anyone-video-2_kps.mp4")
src_fps = get_fps("Moore-AnimateAnyone/configs/inference/pose_videos/anyone-video-2_kps.mp4")
ref_image = Image.open("Moore-AnimateAnyone/configs/inference/ref_images/anyone-5.png").convert("RGB")
pose_list = []
for pose_image_pil in pose_images[:VIDEO_LENGTH]:
pose_list.append(pose_image_pil)
video = pipe(
ref_image,
pose_list,
width=WIDTH,
height=HEIGHT,
video_length=VIDEO_LENGTH,
)
0%| | 0/30 [00:00<?, ?it/s]
0%| | 0/24 [00:00<?, ?it/s]
Video post-processing#
new_h, new_w = video.shape[-2:]
pose_transform = transforms.Compose([transforms.Resize((new_h, new_w)), transforms.ToTensor()])
pose_tensor_list = []
for pose_image_pil in pose_images[:VIDEO_LENGTH]:
pose_tensor_list.append(pose_transform(pose_image_pil))
ref_image_tensor = pose_transform(ref_image) # (c, h, w)
ref_image_tensor = ref_image_tensor.unsqueeze(1).unsqueeze(0) # (1, c, 1, h, w)
ref_image_tensor = repeat(ref_image_tensor, "b c f h w -> b c (repeat f) h w", repeat=VIDEO_LENGTH)
pose_tensor = torch.stack(pose_tensor_list, dim=0) # (f, c, h, w)
pose_tensor = pose_tensor.transpose(0, 1)
pose_tensor = pose_tensor.unsqueeze(0)
video = torch.cat([ref_image_tensor, pose_tensor, video], dim=0)
save_dir = Path("./output")
save_dir.mkdir(parents=True, exist_ok=True)
date_str = datetime.now().strftime("%Y%m%d")
time_str = datetime.now().strftime("%H%M")
out_path = save_dir / f"{date_str}T{time_str}.mp4"
save_videos_grid(
video,
str(out_path),
n_rows=3,
fps=src_fps,
)
from IPython.display import Video
Video(out_path, embed=True)
Interactive inference#
import gradio as gr
def generate(
img,
pose_vid,
seed,
guidance_scale,
num_inference_steps,
_=gr.Progress(track_tqdm=True),
):
generator = torch.Generator().manual_seed(seed)
pose_list = read_frames(pose_vid)[:VIDEO_LENGTH]
video = pipe(
img,
pose_list,
width=WIDTH,
height=HEIGHT,
video_length=VIDEO_LENGTH,
generator=generator,
guidance_scale=guidance_scale,
num_inference_steps=num_inference_steps,
)
new_h, new_w = video.shape[-2:]
pose_transform = transforms.Compose([transforms.Resize((new_h, new_w)), transforms.ToTensor()])
pose_tensor_list = []
for pose_image_pil in pose_list:
pose_tensor_list.append(pose_transform(pose_image_pil))
ref_image_tensor = pose_transform(img) # (c, h, w)
ref_image_tensor = ref_image_tensor.unsqueeze(1).unsqueeze(0) # (1, c, 1, h, w)
ref_image_tensor = repeat(ref_image_tensor, "b c f h w -> b c (repeat f) h w", repeat=VIDEO_LENGTH)
pose_tensor = torch.stack(pose_tensor_list, dim=0) # (f, c, h, w)
pose_tensor = pose_tensor.transpose(0, 1)
pose_tensor = pose_tensor.unsqueeze(0)
video = torch.cat([ref_image_tensor, pose_tensor, video], dim=0)
save_dir = Path("./output/gradio")
save_dir.mkdir(parents=True, exist_ok=True)
date_str = datetime.now().strftime("%Y%m%d")
time_str = datetime.now().strftime("%H%M")
out_path = save_dir / f"{date_str}T{time_str}.mp4"
save_videos_grid(
video,
str(out_path),
n_rows=3,
fps=12,
)
return out_path
if not Path("gradio_helper.py").exists():
r = requests.get(url="https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/notebooks/animate-anyone/gradio_helper.py")
open("gradio_helper.py", "w").write(r.text)
from gradio_helper import make_demo
demo = make_demo(fn=generate)
try:
demo.queue().launch(debug=False)
except Exception:
demo.queue().launch(debug=False, share=True)
# if you are launching remotely, specify server_name and server_port
# demo.launch(server_name='your server name', server_port='server port in int')
# Read more in the docs: https://gradio.app/docs/"
Running on local URL: http://127.0.0.1:7860 To create a public link, set share=True in launch().