Controllable Music Generation with MusicGen and OpenVINO#
This Jupyter notebook can be launched on-line, opening an interactive environment in a browser window. You can also make a local installation. Choose one of the following options:



MusicGen is a single-stage auto-regressive Transformer model capable of generating high-quality music samples conditioned on text descriptions or audio prompts. The text prompt is passed to a text encoder model (T5) to obtain a sequence of hidden-state representations. These hidden states are fed to MusicGen, which predicts discrete audio tokens (audio codes). Finally, audio tokens are then decoded using an audio compression model (EnCodec) to recover the audio waveform.
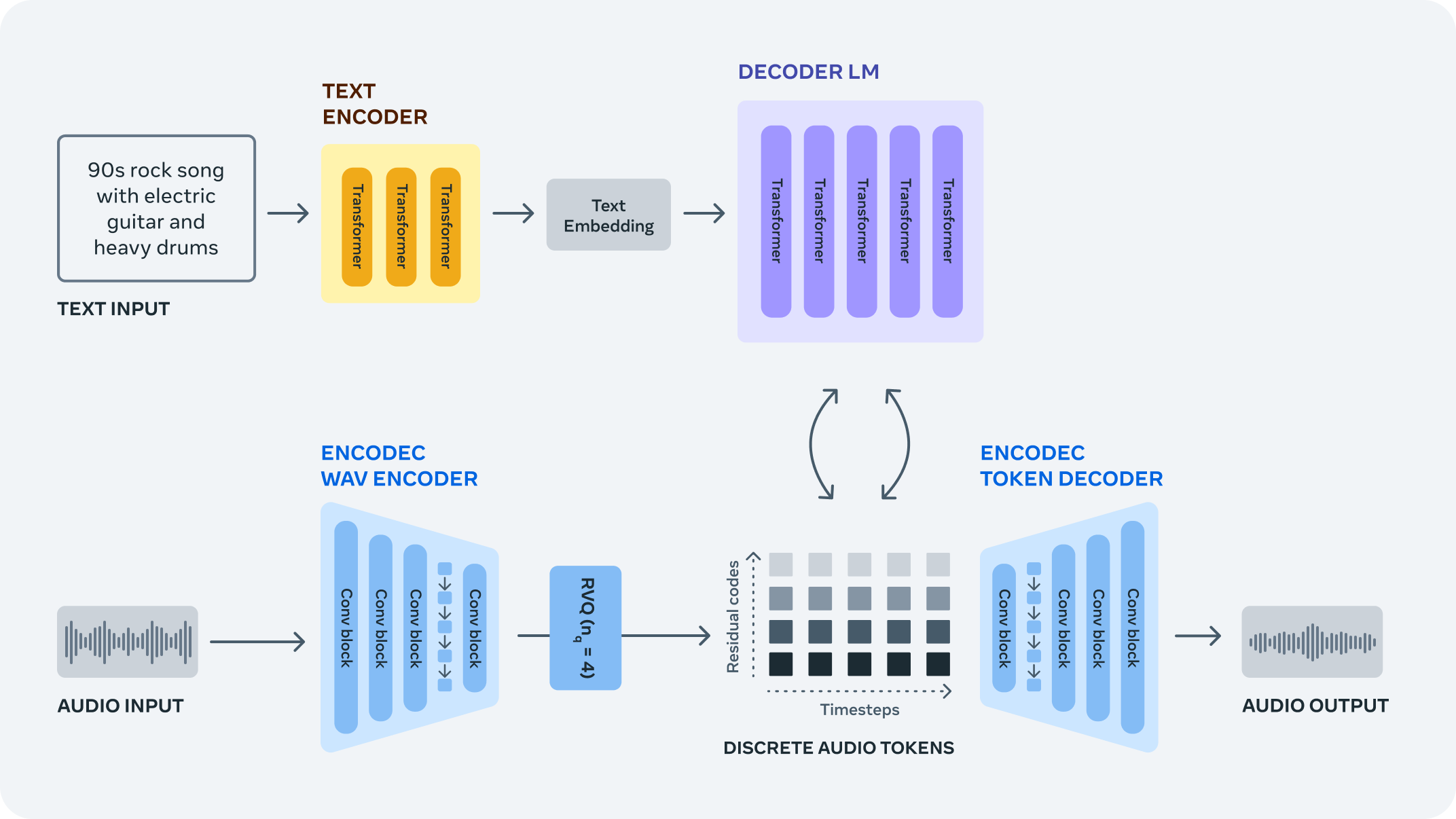
pipeline#
The MusicGen model does not require a self-supervised semantic representation of the text/audio prompts; it operates over several streams of compressed discrete music representation with efficient token interleaving patterns, thus eliminating the need to cascade multiple models to predict a set of codebooks (e.g. hierarchically or upsampling). Unlike prior models addressing music generation, it is able to generate all the codebooks in a single forward pass.
In this tutorial, we consider how to run the MusicGen model using OpenVINO.
We will use a model implementation from the Hugging Face Transformers library.
Table of contents:
Installation Instructions#
This is a self-contained example that relies solely on its own code.
We recommend running the notebook in a virtual environment. You only need a Jupyter server to start. For details, please refer to Installation Guide.
Prerequisites#
Install requirements#
%pip install -q "openvino>=2023.3.0"
%pip install -q "torch>=2.1" "gradio>=4.19" "transformers" packaging --extra-index-url https://download.pytorch.org/whl/cpu
Imports#
from collections import namedtuple
from functools import partial
import gc
from pathlib import Path
from typing import Optional, Tuple
import warnings
from IPython.display import Audio
import openvino as ov
import numpy as np
import torch
from torch.jit import TracerWarning
from transformers import AutoProcessor, MusicgenForConditionalGeneration
from transformers.modeling_outputs import (
BaseModelOutputWithPastAndCrossAttentions,
CausalLMOutputWithCrossAttentions,
)
# Ignore tracing warnings
warnings.filterwarnings("ignore", category=TracerWarning)
MusicGen in HF Transformers#
To work with
MusicGen by Meta
AI, we will use Hugging Face Transformers
package. Transformers
package exposes the MusicgenForConditionalGeneration class,
simplifying the model instantiation and weights loading. The code below
demonstrates how to create a MusicgenForConditionalGeneration and
generate a text-conditioned music sample.
import sys
from packaging.version import parse
if sys.version_info < (3, 8):
import importlib_metadata
else:
import importlib.metadata as importlib_metadata
loading_kwargs = {}
if parse(importlib_metadata.version("transformers")) >= parse("4.40.0"):
loading_kwargs["attn_implementation"] = "eager"
# Load the pipeline
model = MusicgenForConditionalGeneration.from_pretrained("facebook/musicgen-small", torchscript=True, return_dict=False, **loading_kwargs)
In the cell below user is free to change the desired music sample length.
sample_length = 8 # seconds
n_tokens = sample_length * model.config.audio_encoder.frame_rate + 3
sampling_rate = model.config.audio_encoder.sampling_rate
print("Sampling rate is", sampling_rate, "Hz")
model.to("cpu")
model.eval();
Sampling rate is 32000 Hz
Original Pipeline Inference#
Text Preprocessing prepares the text prompt to be fed into the model,
the processor object abstracts this step for us. Text tokenization
is performed under the hood, it assigning tokens or IDs to the words; in
other words, token IDs are just indices of the words in the model
vocabulary. It helps the model understand the context of a sentence.
processor = AutoProcessor.from_pretrained("facebook/musicgen-small")
inputs = processor(
text=["80s pop track with bassy drums and synth"],
return_tensors="pt",
)
audio_values = model.generate(**inputs, do_sample=True, guidance_scale=3, max_new_tokens=n_tokens)
Audio(audio_values[0].cpu().numpy(), rate=sampling_rate)
Convert models to OpenVINO Intermediate representation (IR) format#
Model conversion API enables direct conversion of PyTorch models. We
will utilize the openvino.convert_model method to acquire OpenVINO
IR versions of the models. The method requires a model object and
example input for model tracing. Under the hood, the converter will use
the PyTorch JIT compiler, to build a frozen model graph.
The pipeline consists of three important parts:
The T5 text encoder that translates user prompts into vectors in the latent space that the next model - the MusicGen decoder can utilize.
The MusicGen Language Model that auto-regressively generates audio tokens (codes).
The EnCodec model (we will use only the decoder part of it) is used to decode the audio waveform from the audio tokens predicted by the MusicGen Language Model.
Let us convert each model step by step.
0. Set Up Variables#
models_dir = Path("./models")
t5_ir_path = models_dir / "t5.xml"
musicgen_0_ir_path = models_dir / "mg_0.xml"
musicgen_ir_path = models_dir / "mg.xml"
audio_decoder_ir_path = models_dir / "encodec.xml"
1. Convert Text Encoder#
The text encoder is responsible for converting the input prompt, such as “90s rock song with loud guitars and heavy drums” into an embedding space that can be fed to the next model. Typically, it is a transformer-based encoder that maps a sequence of input tokens to a sequence of text embeddings.
The input for the text encoder consists of a tensor input_ids, which
contains token indices from the text processed by the tokenizer and
attention_mask that we will ignore as we will process one prompt at
a time and this vector will just consist of ones.
We use OpenVINO Converter (OVC) below to convert the PyTorch model to the OpenVINO Intermediate Representation format (IR), which you can infer later with OpenVINO runtime
if not t5_ir_path.exists():
t5_ov = ov.convert_model(model.text_encoder, example_input={"input_ids": inputs["input_ids"]})
ov.save_model(t5_ov, t5_ir_path)
del t5_ov
gc.collect()
2. Convert MusicGen Language Model#
This model is the central part of the whole pipeline, it takes the embedded text representation and generates audio codes that can be then decoded into actual music. The model outputs several streams of audio codes - tokens sampled from the pre-trained codebooks representing music efficiently with a lower frame rate. The model employs innovative codes intervaling strategy, that makes single-stage generation possible.
On the 0th generation step the model accepts input_ids representing
the indices of audio codes, encoder_hidden_states and
encoder_attention_mask that were provided by the text encoder.
# Set model config `torchscript` to True, so the model returns a tuple as output
model.decoder.config.torchscript = True
if not musicgen_0_ir_path.exists():
decoder_input = {
"input_ids": torch.ones(8, 1, dtype=torch.int64),
"encoder_hidden_states": torch.ones(2, 12, 1024, dtype=torch.float32),
"encoder_attention_mask": torch.ones(2, 12, dtype=torch.int64),
}
mg_ov_0_step = ov.convert_model(model.decoder, example_input=decoder_input)
ov.save_model(mg_ov_0_step, musicgen_0_ir_path)
del mg_ov_0_step
gc.collect()
On further iterations, the model is also provided with a
past_key_values argument that contains previous outputs of the
attention block, it allows us to save on computations. But for us, it
means that the signature of the model’s forward method changed.
Models in OpenVINO IR have frozen calculation graphs and do not allow
optional arguments, that is why the MusicGen model must be converted a
second time, with an increased number of inputs.
# Add additional argument to the example_input dict
if not musicgen_ir_path.exists():
# Add `past_key_values` to the converted model signature
decoder_input["past_key_values"] = tuple(
[
(
torch.ones(2, 16, 1, 64, dtype=torch.float32),
torch.ones(2, 16, 1, 64, dtype=torch.float32),
torch.ones(2, 16, 12, 64, dtype=torch.float32),
torch.ones(2, 16, 12, 64, dtype=torch.float32),
)
]
* 24
)
mg_ov = ov.convert_model(model.decoder, example_input=decoder_input)
for input in mg_ov.inputs[3:]:
input.get_node().set_partial_shape(ov.PartialShape([-1, 16, -1, 64]))
input.get_node().set_element_type(ov.Type.f32)
mg_ov.validate_nodes_and_infer_types()
ov.save_model(mg_ov, musicgen_ir_path)
del mg_ov
gc.collect()
3. Convert Audio Decoder#
The audio decoder which is a part of the EnCodec model is used to recover the audio waveform from the audio tokens predicted by the MusicGen decoder. To learn more about the model please refer to the corresponding OpenVINO example.
if not audio_decoder_ir_path.exists():
class AudioDecoder(torch.nn.Module):
def __init__(self, model):
super().__init__()
self.model = model
def forward(self, output_ids):
return self.model.decode(output_ids, [None])
audio_decoder_input = {"output_ids": torch.ones((1, 1, 4, n_tokens - 3), dtype=torch.int64)}
with torch.no_grad():
audio_decoder_ov = ov.convert_model(AudioDecoder(model.audio_encoder), example_input=audio_decoder_input)
ov.save_model(audio_decoder_ov, audio_decoder_ir_path)
del audio_decoder_ov
gc.collect()
Embedding the converted models into the original pipeline#
OpenVINO™ Runtime Python API is used to compile the model in OpenVINO IR
format. The
Core
class provides access to the OpenVINO Runtime API. The core object,
which is an instance of the Core class represents the API and it is
used to compile the model.
core = ov.Core()
Select inference device#
Select device that will be used to do models inference using OpenVINO from the dropdown list:
import requests
if not Path("notebook_utils.py").exists():
r = requests.get(
url="https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/utils/notebook_utils.py",
)
open("notebook_utils.py", "w").write(r.text)
from notebook_utils import device_widget
device = device_widget()
device
# Read more about telemetry collection at https://github.com/openvinotoolkit/openvino_notebooks?tab=readme-ov-file#-telemetry
from notebook_utils import collect_telemetry
collect_telemetry("music-generation.ipynb")
Dropdown(description='Device:', index=3, options=('CPU', 'GPU.0', 'GPU.1', 'AUTO'), value='AUTO')
Adapt OpenVINO models to the original pipeline#
Here we create wrapper classes for all three OpenVINO models that we
want to embed in the original inference pipeline. Here are some of the
things to consider when adapting an OV model: - Make sure that
parameters passed by the original pipeline are forwarded to the compiled
OV model properly; sometimes the OV model uses only a portion of the
input arguments and some are ignored, sometimes you need to convert the
argument to another data type or unwrap some data structures such as
tuples or dictionaries. - Guarantee that the wrapper class returns
results to the pipeline in an expected format. In the example below you
can see how we pack OV model outputs into special classes declared in
the HF repo. - Pay attention to the model method used in the original
pipeline for calling the model - it may be not the forward method!
Refer to the AudioDecoderWrapper to see how we wrap OV model
inference into the decode method.
class TextEncoderWrapper(torch.nn.Module):
def __init__(self, encoder_ir, config):
super().__init__()
self.encoder = core.compile_model(encoder_ir, device.value)
self.config = config
def forward(self, input_ids, **kwargs):
last_hidden_state = self.encoder(input_ids)[self.encoder.outputs[0]]
last_hidden_state = torch.tensor(last_hidden_state)
return BaseModelOutputWithPastAndCrossAttentions(last_hidden_state=last_hidden_state)
class MusicGenWrapper(torch.nn.Module):
def __init__(
self,
music_gen_lm_0_ir,
music_gen_lm_ir,
config,
num_codebooks,
build_delay_pattern_mask,
apply_delay_pattern_mask,
):
super().__init__()
self.music_gen_lm_0 = core.compile_model(music_gen_lm_0_ir, device.value)
self.music_gen_lm = core.compile_model(music_gen_lm_ir, device.value)
self.config = config
self.num_codebooks = num_codebooks
self.build_delay_pattern_mask = build_delay_pattern_mask
self.apply_delay_pattern_mask = apply_delay_pattern_mask
def forward(
self,
input_ids: torch.LongTensor = None,
encoder_hidden_states: torch.FloatTensor = None,
encoder_attention_mask: torch.LongTensor = None,
past_key_values: Optional[Tuple[torch.FloatTensor]] = None,
**kwargs
):
if past_key_values is None:
model = self.music_gen_lm_0
arguments = (input_ids, encoder_hidden_states, encoder_attention_mask)
else:
model = self.music_gen_lm
arguments = (
input_ids,
encoder_hidden_states,
encoder_attention_mask,
*past_key_values,
)
output = model(arguments)
return CausalLMOutputWithCrossAttentions(
logits=torch.tensor(output[model.outputs[0]]),
past_key_values=tuple([output[model.outputs[i]] for i in range(1, 97)]),
)
class AudioDecoderWrapper(torch.nn.Module):
def __init__(self, decoder_ir, config):
super().__init__()
self.decoder = core.compile_model(decoder_ir, device.value)
self.config = config
self.output_type = namedtuple("AudioDecoderOutput", ["audio_values"])
def decode(self, output_ids, audio_scales):
output = self.decoder(output_ids)[self.decoder.outputs[0]]
return self.output_type(audio_values=torch.tensor(output))
Now we initialize the wrapper objects and load them to the HF pipeline
text_encode_ov = TextEncoderWrapper(t5_ir_path, model.text_encoder.config)
musicgen_decoder_ov = MusicGenWrapper(
musicgen_0_ir_path,
musicgen_ir_path,
model.decoder.config,
model.decoder.num_codebooks,
model.decoder.build_delay_pattern_mask,
model.decoder.apply_delay_pattern_mask,
)
audio_encoder_ov = AudioDecoderWrapper(audio_decoder_ir_path, model.audio_encoder.config)
del model.text_encoder
del model.decoder
del model.audio_encoder
gc.collect()
model.text_encoder = text_encode_ov
model.decoder = musicgen_decoder_ov
model.audio_encoder = audio_encoder_ov
def prepare_inputs_for_generation(
self,
decoder_input_ids,
past_key_values=None,
attention_mask=None,
head_mask=None,
decoder_attention_mask=None,
decoder_head_mask=None,
cross_attn_head_mask=None,
use_cache=None,
encoder_outputs=None,
decoder_delay_pattern_mask=None,
guidance_scale=None,
**kwargs,
):
if decoder_delay_pattern_mask is None:
(
decoder_input_ids,
decoder_delay_pattern_mask,
) = self.decoder.build_delay_pattern_mask(
decoder_input_ids,
self.generation_config.pad_token_id,
max_length=self.generation_config.max_length,
)
# apply the delay pattern mask
decoder_input_ids = self.decoder.apply_delay_pattern_mask(decoder_input_ids, decoder_delay_pattern_mask)
if guidance_scale is not None and guidance_scale > 1:
# for classifier free guidance we need to replicate the decoder args across the batch dim (we'll split these
# before sampling)
decoder_input_ids = decoder_input_ids.repeat((2, 1))
if decoder_attention_mask is not None:
decoder_attention_mask = decoder_attention_mask.repeat((2, 1))
if past_key_values is not None:
# cut decoder_input_ids if past is used
decoder_input_ids = decoder_input_ids[:, -1:]
return {
"input_ids": None, # encoder_outputs is defined. input_ids not needed
"encoder_outputs": encoder_outputs,
"past_key_values": past_key_values,
"decoder_input_ids": decoder_input_ids,
"attention_mask": attention_mask,
"decoder_attention_mask": decoder_attention_mask,
"head_mask": head_mask,
"decoder_head_mask": decoder_head_mask,
"cross_attn_head_mask": cross_attn_head_mask,
"use_cache": use_cache,
}
model.prepare_inputs_for_generation = partial(prepare_inputs_for_generation, model)
We can now infer the pipeline backed by OpenVINO models.
processor = AutoProcessor.from_pretrained("facebook/musicgen-small")
inputs = processor(
text=["80s pop track with bassy drums and synth"],
return_tensors="pt",
)
audio_values = model.generate(**inputs, do_sample=True, guidance_scale=3, max_new_tokens=n_tokens)
Audio(audio_values[0].cpu().numpy(), rate=sampling_rate)
Try out the converted pipeline#
The demo app below is created using Gradio package
def _generate(prompt):
inputs = processor(
text=[
prompt,
],
padding=True,
return_tensors="pt",
)
audio_values = model.generate(**inputs, do_sample=True, guidance_scale=3, max_new_tokens=n_tokens)
waveform = audio_values[0].cpu().squeeze() * 2**15
return (sampling_rate, waveform.numpy().astype(np.int16))
import gradio as gr
demo = gr.Interface(
fn=_generate,
inputs=[
gr.Textbox(label="Text Prompt"),
],
outputs=["audio"],
examples=[
["80s pop track with bassy drums and synth"],
["Earthy tones, environmentally conscious, ukulele-infused, harmonic, breezy, easygoing, organic instrumentation, gentle grooves"],
["90s rock song with loud guitars and heavy drums"],
["Heartful EDM with beautiful synths and chords"],
],
allow_flagging="never",
)
try:
demo.launch(debug=True)
except Exception:
demo.launch(share=True, debug=True)
# If you are launching remotely, specify server_name and server_port
# EXAMPLE: `demo.launch(server_name='your server name', server_port='server port in int')`
# To learn more please refer to the Gradio docs: https://gradio.app/docs/