Florence-2: Open Source Vision Foundation Model#
This Jupyter notebook can be launched after a local installation only.

Florence-2 is a lightweight vision-language foundation model developed by Microsoft Azure AI and open-sourced under the MIT license. It aims to achieve a unified, prompt-based representation for diverse vision and vision-language tasks, including captioning, object detection, grounding, and segmentation. Despite its compact size, Florence-2 rivals much larger models like Kosmos-2 in performance. Florence-2 represents a significant advancement in vision-language models by combining lightweight architecture with robust capabilities, making it highly accessible and versatile. Its unified representation approach, supported by the extensive FLD-5B dataset, enables it to excel in multiple vision tasks without the need for separate models. This efficiency makes Florence-2 a strong contender for real-world applications, particularly on devices with limited resources.
More details about model can be found in model’s resources collection and original paper
In this tutorial we consider how to convert and run Florence2 using OpenVINO.
Table of contents:
Installation Instructions#
This is a self-contained example that relies solely on its own code.
We recommend running the notebook in a virtual environment. You only need a Jupyter server to start. For details, please refer to Installation Guide.
Prerequisites#
%pip install -q "einops" "torch>2.1" "torchvision" "matplotlib>=3.4" "timm>=0.9.8" "transformers>=4.41" "pillow" "gradio>=4.19" --extra-index-url https://download.pytorch.org/whl/cpu
%pip install -q -U --pre "openvino>=2024.6" --extra-index-url https://storage.openvinotoolkit.org/simple/wheels/pre-release
Note: you may need to restart the kernel to use updated packages.
ERROR: Could not find a version that satisfies the requirement openvino>=2024.6 (from versions: 2021.3.0, 2021.4.0, 2021.4.1, 2021.4.2, 2022.1.0, 2022.2.0, 2022.3.0, 2022.3.1, 2022.3.2, 2023.0.0.dev20230119, 2023.0.0.dev20230217, 2023.0.0.dev20230407, 2023.0.0.dev20230427, 2023.0.0, 2023.0.1, 2023.0.2, 2023.1.0.dev20230623, 2023.1.0.dev20230728, 2023.1.0.dev20230811, 2023.1.0, 2023.2.0.dev20230922, 2023.2.0, 2023.3.0, 2024.0.0.dev20240215, 2024.0.0rc2, 2024.0.0, 2024.1.0rc2, 2024.1.0, 2024.2.0rc1, 2024.2.0rc2, 2024.2.0, 2024.3.0.dev20240807, 2024.3.0rc1, 2024.3.0rc2, 2024.3.0, 2024.4.0rc1, 2024.4.0rc2, 2024.4.0, 2024.4.1.dev20240926, 2024.4.1rc1)
ERROR: No matching distribution found for openvino>=2024.6
Note: you may need to restart the kernel to use updated packages.
import requests
from pathlib import Path
if not Path("ov_florence2_helper.py").exists():
r = requests.get(url="https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/notebooks/florence2/ov_florence2_helper.py")
open("ov_florence2_helper.py", "w").write(r.text)
if not Path("gradio_helper.py").exists():
r = requests.get(url="https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/notebooks/florence2/gradio_helper.py")
open("gradio_helper.py", "w").write(r.text)
if not Path("notebook_utils.py").exists():
r = requests.get(url="https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/utils/notebook_utils.py")
open("notebook_utils.py", "w").write(r.text)
# Read more about telemetry collection at https://github.com/openvinotoolkit/openvino_notebooks?tab=readme-ov-file#-telemetry
from notebook_utils import collect_telemetry
collect_telemetry("florence2.ipynb")
Select model#
The Florence-2 series consists of two models: Florence-2-base and Florence-2-large, with 0.23 billion and 0.77 billion parameters, respectively. Additionally, authors provide finetuned on collection of downstream tasks model versions. In this tutorial you can select one of available model. By default, we will use Florence-2-base-ft.
from ov_florence2_helper import convert_florence2, get_model_selector
model_selector = get_model_selector()
model_selector
2025-02-04 02:29:03.827716: I tensorflow/core/util/port.cc:110] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable TF_ENABLE_ONEDNN_OPTS=0. 2025-02-04 02:29:03.861899: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations. To enable the following instructions: AVX2 AVX512F AVX512_VNNI FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags. 2025-02-04 02:29:04.528243: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
Dropdown(description='Model:', options=('microsoft/Florence-2-base-ft', 'microsoft/Florence-2-base', 'microsof…
Convert model#
Florence2 is PyTorch model. OpenVINO supports PyTorch models via
conversion to OpenVINO Intermediate Representation (IR). OpenVINO model
conversion
API
should be used for these purposes. ov.convert_model function accepts
original PyTorch model instance and example input for tracing and
returns ov.Model representing this model in OpenVINO framework.
Converted model can be used for saving on disk using ov.save_model
function or directly loading on device using core.complie_model.
ov_florence2_helper.py script contains helper function for model
conversion, please check its content if you interested in conversion
details.
Click here for more detailed explanation of conversion steps The model takes images and task prompts as input, generating the desired results in text format. It uses a DaViT vision encoder to convert images into visual token embeddings. These are then concatenated with BERT-generated text embeddings and processed by a transformer-based multi-modal encoder-decoder to generate the response.
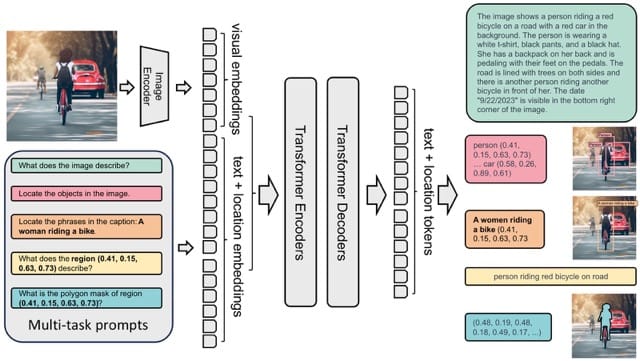
To sum up above, model consists of 4 parts:
Image Encoder for transforming input images into flattened visual token embeddings.
Input Embedding for conversion input text tokens or task description into embedding space.
Encoder and Decoder for generation answer based on input embeddings provided by Image Encoder and Input Embedding models. The model employs a seq2seq framework, seamlessly integrating the image encoder with a multi-modality encoder-decoder.
We will convert each part separately, then combine them in inference pipeline.
model_id = model_selector.value
model_path = Path(model_id.split("/")[-1])
# Uncomment the line to see conversion code
# ??convert_florence2
convert_florence2(model_id, model_path)
⌛ microsoft/Florence-2-base-ft conversion started. Be patient, it may takes some time.
⌛ Load Original model
Fetching 15 files: 0%| | 0/15 [00:00<?, ?it/s]
LICENSE: 0%| | 0.00/1.14k [00:00<?, ?B/s]
SECURITY.md: 0%| | 0.00/2.66k [00:00<?, ?B/s]
SUPPORT.md: 0%| | 0.00/1.24k [00:00<?, ?B/s]
config.json: 0%| | 0.00/2.43k [00:00<?, ?B/s]
README.md: 0%| | 0.00/14.8k [00:00<?, ?B/s]
CODE_OF_CONDUCT.md: 0%| | 0.00/444 [00:00<?, ?B/s]
configuration_florence2.py: 0%| | 0.00/15.1k [00:00<?, ?B/s]
.gitattributes: 0%| | 0.00/1.56k [00:00<?, ?B/s]
modeling_florence2.py: 0%| | 0.00/127k [00:00<?, ?B/s]
preprocessor_config.json: 0%| | 0.00/806 [00:00<?, ?B/s]
processing_florence2.py: 0%| | 0.00/46.4k [00:00<?, ?B/s]
tokenizer_config.json: 0%| | 0.00/34.0 [00:00<?, ?B/s]
tokenizer.json: 0%| | 0.00/1.36M [00:00<?, ?B/s]
pytorch_model.bin: 0%| | 0.00/464M [00:00<?, ?B/s]
vocab.json: 0%| | 0.00/1.10M [00:00<?, ?B/s]
/opt/home/k8sworker/ci-ai/cibuilds/jobs/ov-notebook/jobs/OVNotebookOps/builds/875/archive/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/timm/models/layers/__init__.py:48: FutureWarning: Importing from timm.models.layers is deprecated, please import via timm.layers
warnings.warn(f"Importing from {__name__} is deprecated, please import via timm.layers", FutureWarning)
Florence2LanguageForConditionalGeneration has generative capabilities, as prepare_inputs_for_generation is explicitly overwritten. However, it doesn't directly inherit from GenerationMixin. From 👉v4.50👈 onwards, PreTrainedModel will NOT inherit from GenerationMixin, and this model will lose the ability to call generate and other related functions.
- If you're using trust_remote_code=True, you can get rid of this warning by loading the model with an auto class. See https://huggingface.co/docs/transformers/en/model_doc/auto#auto-classes
- If you are the owner of the model architecture code, please modify your model class such that it inherits from GenerationMixin (after PreTrainedModel, otherwise you'll get an exception).
- If you are not the owner of the model architecture class, please contact the model code owner to update it.
✅ Original model successfully loaded
⌛ Image Embeddings conversion started
WARNING:tensorflow:Please fix your imports. Module tensorflow.python.training.tracking.base has been moved to tensorflow.python.trackable.base. The old module will be deleted in version 2.11.
[ WARNING ] Please fix your imports. Module %s has been moved to %s. The old module will be deleted in version %s. /opt/home/k8sworker/ci-ai/cibuilds/jobs/ov-notebook/jobs/OVNotebookOps/builds/875/archive/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/transformers/modeling_utils.py:5006: FutureWarning: _is_quantized_training_enabled is going to be deprecated in transformers 4.39.0. Please use model.hf_quantizer.is_trainable instead warnings.warn( loss_type=None was set in the config but it is unrecognised.Using the default loss: ForCausalLMLoss. /opt/home/k8sworker/.cache/huggingface/modules/transformers_modules/chkpt/modeling_florence2.py:277: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs! assert N == H * W /opt/home/k8sworker/.cache/huggingface/modules/transformers_modules/chkpt/modeling_florence2.py:427: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs! assert L == H * W, "input feature has wrong size" /opt/home/k8sworker/.cache/huggingface/modules/transformers_modules/chkpt/modeling_florence2.py:460: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs! if pad_r > 0 or pad_b > 0: /opt/home/k8sworker/.cache/huggingface/modules/transformers_modules/chkpt/modeling_florence2.py:349: TracerWarning: Converting a tensor to a Python float might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs! q = q * (float(N) ** -0.5) /opt/home/k8sworker/.cache/huggingface/modules/transformers_modules/chkpt/modeling_florence2.py:2610: TracerWarning: Converting a tensor to a Python integer might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs! h, w = int(num_tokens ** 0.5), int(num_tokens ** 0.5) /opt/home/k8sworker/.cache/huggingface/modules/transformers_modules/chkpt/modeling_florence2.py:2611: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs! assert h * w == num_tokens, 'only support square feature maps for now' /opt/home/k8sworker/.cache/huggingface/modules/transformers_modules/chkpt/modeling_florence2.py:151: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs! assert len_seq <= self.max_seq_len
✅ Image Embeddings successfuly converted
⌛ Text Embedding conversion started
✅ Text Embedding conversion started
⌛ Encoder conversion started
/opt/home/k8sworker/.cache/huggingface/modules/transformers_modules/chkpt/modeling_florence2.py:1218: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
if attn_output.size() != (bsz, self.num_heads, tgt_len, self.head_dim):
✅ Encoder conversion finished
⌛ Decoder conversion started
/opt/home/k8sworker/ci-ai/cibuilds/jobs/ov-notebook/jobs/OVNotebookOps/builds/875/archive/.workspace/scm/ov-notebook/.venv/lib/python3.8/site-packages/transformers/modeling_attn_mask_utils.py:88: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
if input_shape[-1] > 1 or self.sliding_window is not None:
/opt/home/k8sworker/.cache/huggingface/modules/transformers_modules/chkpt/modeling_florence2.py:1205: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
is_causal = True if self.is_causal and attention_mask is None and tgt_len > 1 else False
/opt/home/k8sworker/.cache/huggingface/modules/transformers_modules/chkpt/modeling_florence2.py:1167: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
if (
✅ Decoder conversion finished
✅ microsoft/Florence-2-base-ft already converted and can be found in Florence-2-base-ft
Select inference device#
from notebook_utils import device_widget
device = device_widget()
device
Dropdown(description='Device:', index=1, options=('CPU', 'AUTO'), value='AUTO')
Run model inference#
OvFlorence2Model class defined in ov_florence2_helper.py
provides convenient way for running model. It accepts directory with
converted model and inference device as arguments. For running model we
will use generate method.
from ov_florence2_helper import OVFlorence2Model
# Uncomment the line to see model class code
# ??OVFlorence2Model
model = OVFlorence2Model(model_path, device.value)
Additionally, for model usage we also need Processor class, that
distributed with original model and can be loaded using
AutoProcessor from transformers library. Processor is
responsible for input data preparation and decoding model output.
import requests
from PIL import Image
from transformers import AutoProcessor
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
prompt = "<OD>"
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/car.jpg?download=true"
image = Image.open(requests.get(url, stream=True).raw)
image

Let’s check model capabilities in Object Detection.
inputs = processor(text=prompt, images=image, return_tensors="pt")
generated_ids = model.generate(input_ids=inputs["input_ids"], pixel_values=inputs["pixel_values"], max_new_tokens=1024, do_sample=False, num_beams=3)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=False)[0]
parsed_answer = processor.post_process_generation(generated_text, task="<OD>", image_size=(image.width, image.height))
from gradio_helper import plot_bbox
fig = plot_bbox(image, parsed_answer["<OD>"])

More model capabilities will be demonstrated in interactive demo.
Interactive Demo#
In this section, you can see model in action on various of supported vision tasks. Please provide input image or select one from examples and specify task (Please note, that some of them may additionally requires to provide text input, e.g. description for region for segmentation or phrase for grounding).
Click here for more detailed info about supported tasks Florence-2 is designed to handle a variety of vision and vision-language tasks through its unified, prompt-based representation. The key vision tasks performed by Florence-2 include:
Caption: Generating brief textual descriptions of images, capturing the essence of the scene.
Detailed Caption: Producing more elaborate textual descriptions, providing richer information about the image.
More Detailed Caption: Creating comprehensive textual descriptions that include extensive details about the image.
Region Proposal: Identifying regions of interest within an image to focus on specific areas.
Object Detection: Locating and identifying objects within an image, providing bounding boxes and labels for each detected object.
Dense Region Caption: Generating textual descriptions for densely packed regions within an image.
Phrase Grounding: Associating phrases in a text description with specific regions in an image, linking textual descriptions to visual elements.
Referring Expression Segmentation: Identifying regions in an image that correspond to natural language expressions, making it adept at tasks that require fine-grained visual-textual alignment.Segmenting regions in an image based on referring expressions, providing detailed object boundaries.
Open Vocabulary Detection: Detecting objects in an image using a flexible and extensive vocabulary.
Region to Text: Converting regions of an image into corresponding textual descriptions.
Text Detection and Recognition: Detecting and recognizing text within an image, providing both text and region information.
from gradio_helper import make_demo
demo = make_demo(model, processor)
try:
demo.launch(debug=False, height=600)
except Exception:
demo.launch(debug=False, share=True, height=600)
# if you are launching remotely, specify server_name and server_port
# demo.launch(server_name='your server name', server_port='server port in int')
# Read more in the docs: https://gradio.app/docs/
Running on local URL: http://127.0.0.1:7860 To create a public link, set share=True in launch().