Create an LLM-powered Chatbot using OpenVINO#
This Jupyter notebook can be launched after a local installation only.

In the rapidly evolving world of artificial intelligence (AI), chatbots have emerged as powerful tools for businesses to enhance customer interactions and streamline operations. Large Language Models (LLMs) are artificial intelligence systems that can understand and generate human language. They use deep learning algorithms and massive amounts of data to learn the nuances of language and produce coherent and relevant responses. While a decent intent-based chatbot can answer basic, one-touch inquiries like order management, FAQs, and policy questions, LLM chatbots can tackle more complex, multi-touch questions. LLM enables chatbots to provide support in a conversational manner, similar to how humans do, through contextual memory. Leveraging the capabilities of Language Models, chatbots are becoming increasingly intelligent, capable of understanding and responding to human language with remarkable accuracy.
Previously, we already discussed how to build an instruction-following pipeline using OpenVINO and Optimum Intel, please check out Dolly example for reference. In this tutorial, we consider how to use the power of OpenVINO for running Large Language Models for chat. We will use a pre-trained model from the Hugging Face Transformers library. To simplify the user experience, the Hugging Face Optimum Intel library is used to convert the models to OpenVINO™ IR format and to create inference pipeline. The inference pipeline can also be created using OpenVINO Generate API, the example of that, please, see in the notebook LLM chatbot with OpenVINO Generate API
The tutorial consists of the following steps:
Install prerequisites
Download and convert the model from a public source using the OpenVINO integration with Hugging Face Optimum.
Compress model weights to 4-bit or 8-bit data types using NNCF
Create a chat inference pipeline
Run chat pipeline
Table of contents:
Installation Instructions#
This is a self-contained example that relies solely on its own code.
We recommend running the notebook in a virtual environment. You only need a Jupyter server to start. For details, please refer to Installation Guide.
Prerequisites#
Install required dependencies
import os
import platform
os.environ["GIT_CLONE_PROTECTION_ACTIVE"] = "false"
%pip install -Uq pip
%pip uninstall -q -y optimum optimum-intel
%pip install --pre -Uq "openvino>=2024.2.0" openvino-tokenizers[transformers] --extra-index-url https://storage.openvinotoolkit.org/simple/wheels/nightly
%pip install -q --extra-index-url https://download.pytorch.org/whl/cpu\
"git+https://github.com/huggingface/optimum-intel.git"\
"nncf==2.14.1"\
"torch>=2.1"\
"datasets" \
"accelerate" \
"gradio>=4.19" \
"huggingface-hub>=0.26.5" \
"einops" "transformers>=4.43.1" "transformers_stream_generator" "tiktoken" "bitsandbytes"
if platform.system() == "Darwin":
%pip install -q "numpy<2.0.0"
import os
from pathlib import Path
import requests
import shutil
# fetch model configuration
config_shared_path = Path("../../utils/llm_config.py")
config_dst_path = Path("llm_config.py")
if not config_dst_path.exists():
if config_shared_path.exists():
try:
os.symlink(config_shared_path, config_dst_path)
except Exception:
shutil.copy(config_shared_path, config_dst_path)
else:
r = requests.get(url="https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/utils/llm_config.py")
with open("llm_config.py", "w", encoding="utf-8") as f:
f.write(r.text)
elif not os.path.islink(config_dst_path):
print("LLM config will be updated")
if config_shared_path.exists():
shutil.copy(config_shared_path, config_dst_path)
else:
r = requests.get(url="https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/utils/llm_config.py")
with open("llm_config.py", "w", encoding="utf-8") as f:
f.write(r.text)
Select model for inference#
The tutorial supports different models, you can select one from the provided options to compare the quality of open source LLM solutions. >Note: conversion of some models can require additional actions from user side and at least 64GB RAM for conversion.
Click here to see available models options
tiny-llama-1b-chat - This is the chat model finetuned on top of TinyLlama/TinyLlama-1.1B-intermediate-step-1431k-3T. The TinyLlama project aims to pretrain a 1.1B Llama model on 3 trillion tokens with the adoption of the same architecture and tokenizer as Llama 2. This means TinyLlama can be plugged and played in many open-source projects built upon Llama. Besides, TinyLlama is compact with only 1.1B parameters. This compactness allows it to cater to a multitude of applications demanding a restricted computation and memory footprint. More details about model can be found in model card
minicpm-2b-dpo - MiniCPM is an End-Size LLM developed by ModelBest Inc. and TsinghuaNLP, with only 2.4B parameters excluding embeddings. After Direct Preference Optimization (DPO) fine-tuning, MiniCPM outperforms many popular 7b, 13b and 70b models. More details can be found in model_card.
minicpm3-4b - MiniCPM3-4B is the 3rd generation of MiniCPM series. The overall performance of MiniCPM3-4B surpasses Phi-3.5-mini-Instruct, being comparable with many recent 7B~9B models.Compared to previous generations, MiniCPM3-4B has a more powerful and versatile skill set to enable more general usage. More details can be found in model card.
gemma-2b-it - Gemma is a family of lightweight, state-of-the-art open models from Google, built from the same research and technology used to create the Gemini models. They are text-to-text, decoder-only large language models, available in English, with open weights, pre-trained variants, and instruction-tuned variants. Gemma models are well-suited for a variety of text generation tasks, including question answering, summarization, and reasoning. This model is instruction-tuned version of 2B parameters model. More details about model can be found in model card. >Note: run model with demo, you will need to accept license agreement. >You must be a registered user in Hugging Face Hub. Please visit HuggingFace model card, carefully read terms of usage and click accept button. You will need to use an access token for the code below to run. For more information on access tokens, refer to this section of the documentation. >You can login on Hugging Face Hub in notebook environment, using following code:
## login to huggingfacehub to get access to pretrained model
from huggingface_hub import notebook_login, whoami
try:
whoami()
print('Authorization token already provided')
except OSError:
notebook_login()
gemma-2-2b-it - Gemma2 is the second generation of a Gemma family of lightweight, state-of-the-art open models from Google, built from the same research and technology used to create the Gemini models. They are text-to-text, decoder-only large language models, available in English, with open weights, pre-trained variants, and instruction-tuned variants. Gemma models are well-suited for a variety of text generation tasks, including question answering, summarization, and reasoning. This model is instruction-tuned version of 2B parameters model. More details about model can be found in model card. >Note: run model with demo, you will need to accept license agreement. >You must be a registered user in Hugging Face Hub. Please visit HuggingFace model card, carefully read terms of usage and click accept button. You will need to use an access token for the code below to run. For more information on access tokens, refer to this section of the documentation. >You can login on Hugging Face Hub in notebook environment, using following code:
# login to huggingfacehub to get access to pretrained model
from huggingface_hub import notebook_login, whoami
try:
whoami()
print('Authorization token already provided')
except OSError:
notebook_login()
phi-3-mini-instruct - The Phi-3-Mini is a 3.8B parameters, lightweight, state-of-the-art open model trained with the Phi-3 datasets that includes both synthetic data and the filtered publicly available websites data with a focus on high-quality and reasoning dense properties. More details about model can be found in model card, Microsoft blog and technical report.
phi-3.5-mini-instruct - Phi-3.5-mini is a lightweight, state-of-the-art open model built upon datasets used for Phi-3 - synthetic data and filtered publicly available websites - with a focus on very high-quality, reasoning dense data. The model belongs to the Phi-3 model family and supports 128K token context length. The model underwent a rigorous enhancement process, incorporating both supervised fine-tuning, proximal policy optimization, and direct preference optimization to ensure precise instruction adherence and robust safety measures. More details about model can be found in model card, Microsoft blog and technical report.
phi-4 - Phi-4 is 14B model that built upon a blend of synthetic datasets, data from filtered public domain websites, and acquired academic books and Q&A datasets. The goal of this approach was to ensure that small capable models were trained with data focused on high quality and advanced reasoning. Phi-4 underwent a rigorous enhancement and alignment process, incorporating both supervised fine-tuning and direct preference optimization to ensure precise instruction adherence and robust safety measures. More details about model can be found in model_card, technical report and Microsoft blog.
red-pajama-3b-chat - A 2.8B parameter pre-trained language model based on GPT-NEOX architecture. It was developed by Together Computer and leaders from the open-source AI community. The model is fine-tuned on OASST1 and Dolly2 datasets to enhance chatting ability. More details about model can be found in HuggingFace model card.
gemma-7b-it - Gemma is a family of lightweight, state-of-the-art open models from Google, built from the same research and technology used to create the Gemini models. They are text-to-text, decoder-only large language models, available in English, with open weights, pre-trained variants, and instruction-tuned variants. Gemma models are well-suited for a variety of text generation tasks, including question answering, summarization, and reasoning. This model is instruction-tuned version of 7B parameters model. More details about model can be found in model card. >Note: run model with demo, you will need to accept license agreement. >You must be a registered user in Hugging Face Hub. Please visit HuggingFace model card, carefully read terms of usage and click accept button. You will need to use an access token for the code below to run. For more information on access tokens, refer to this section of the documentation. >You can login on Hugging Face Hub in notebook environment, using following code:
## login to huggingfacehub to get access to pretrained model
from huggingface_hub import notebook_login, whoami
try:
whoami()
print('Authorization token already provided')
except OSError:
notebook_login()
gemma-2-9b-it - Gemma2 is the second generation of a Gemma family of lightweight, state-of-the-art open models from Google, built from the same research and technology used to create the Gemini models. They are text-to-text, decoder-only large language models, available in English, with open weights, pre-trained variants, and instruction-tuned variants. Gemma models are well-suited for a variety of text generation tasks, including question answering, summarization, and reasoning. This model is instruction-tuned version of 9B parameters model. More details about model can be found in model card. >Note: run model with demo, you will need to accept license agreement. >You must be a registered user in Hugging Face Hub. Please visit HuggingFace model card, carefully read terms of usage and click accept button. You will need to use an access token for the code below to run. For more information on access tokens, refer to this section of the documentation. >You can login on Hugging Face Hub in notebook environment, using following code:
# login to huggingfacehub to get access to pretrained model
from huggingface_hub import notebook_login, whoami
try:
whoami()
print('Authorization token already provided')
except OSError:
notebook_login()
llama-2-7b-chat - LLama 2 is the second generation of LLama models developed by Meta. Llama 2 is a collection of pre-trained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters. llama-2-7b-chat is 7 billions parameters version of LLama 2 finetuned and optimized for dialogue use case. More details about model can be found in the paper, repository and HuggingFace model card. >Note: run model with demo, you will need to accept license agreement. >You must be a registered user in Hugging Face Hub. Please visit HuggingFace model card, carefully read terms of usage and click accept button. You will need to use an access token for the code below to run. For more information on access tokens, refer to this section of the documentation. >You can login on Hugging Face Hub in notebook environment, using following code:
## login to huggingfacehub to get access to pretrained model
from huggingface_hub import notebook_login, whoami
try:
whoami()
print('Authorization token already provided')
except OSError:
notebook_login()
llama-3-8b-instruct - Llama 3 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align with human preferences for helpfulness and safety. The Llama 3 instruction tuned models are optimized for dialogue use cases and outperform many of the available open source chat models on common industry benchmarks. More details about model can be found in Meta blog post, model website and model card. >Note: run model with demo, you will need to accept license agreement. >You must be a registered user in Hugging Face Hub. Please visit HuggingFace model card, carefully read terms of usage and click accept button. You will need to use an access token for the code below to run. For more information on access tokens, refer to this section of the documentation. >You can login on Hugging Face Hub in notebook environment, using following code:
## login to huggingfacehub to get access to pretrained model
from huggingface_hub import notebook_login, whoami
try:
whoami()
print('Authorization token already provided')
except OSError:
notebook_login()
llama-3.1-8b-instruct - The Llama 3.1 instruction tuned text only models (8B, 70B, 405B) are optimized for multilingual dialogue use cases and outperform many of the available open source and closed chat models on common industry benchmarks. More details about model can be found in Meta blog post, model website and model card. >Note: run model with demo, you will need to accept license agreement. >You must be a registered user in Hugging Face Hub. Please visit HuggingFace model card, carefully read terms of usage and click accept button. You will need to use an access token for the code below to run. For more information on access tokens, refer to this section of the documentation. >You can login on Hugging Face Hub in notebook environment, using following code:
## login to huggingfacehub to get access to pretrained model
from huggingface_hub import notebook_login, whoami
try:
whoami()
print('Authorization token already provided')
except OSError:
notebook_login()
qwen2.5-0.5b-instruct/qwen2.5-1.5b-instruct/qwen2.5-3b-instruct/qwen2.5-7b-instruct/qwen2.5-14b-instruct - Qwen2.5 is the latest series of Qwen large language models. Comparing with Qwen2, Qwen2.5 series brings significant improvements in coding, mathematics and general knowledge skills. Additionally, it brings long-context and multiple languages support including Chinese, English, French, Spanish, Portuguese, German, Italian, Russian, Japanese, Korean, Vietnamese, Thai, Arabic, and more. For more details, please refer to model_card, blog, GitHub, and Documentation.
qwen-7b-chat - Qwen-7B is the 7B-parameter version of the large language model series, Qwen (abbr. Tongyi Qianwen), proposed by Alibaba Cloud. Qwen-7B is a Transformer-based large language model, which is pretrained on a large volume of data, including web texts, books, codes, etc. For more details about Qwen, please refer to the GitHub code repository.
mpt-7b-chat - MPT-7B is part of the family of MosaicPretrainedTransformer (MPT) models, which use a modified transformer architecture optimized for efficient training and inference. These architectural changes include performance-optimized layer implementations and the elimination of context length limits by replacing positional embeddings with Attention with Linear Biases (ALiBi). Thanks to these modifications, MPT models can be trained with high throughput efficiency and stable convergence. MPT-7B-chat is a chatbot-like model for dialogue generation. It was built by finetuning MPT-7B on the ShareGPT-Vicuna, HC3, Alpaca, HH-RLHF, and Evol-Instruct datasets. More details about the model can be found in blog post, repository and HuggingFace model card.
chatglm3-6b - ChatGLM3-6B is the latest open-source model in the ChatGLM series. While retaining many excellent features such as smooth dialogue and low deployment threshold from the previous two generations, ChatGLM3-6B employs a more diverse training dataset, more sufficient training steps, and a more reasonable training strategy. ChatGLM3-6B adopts a newly designed Prompt format, in addition to the normal multi-turn dialogue. You can find more details about model in the model card
mistral-7b - The Mistral-7B-v0.1 Large Language Model (LLM) is a pretrained generative text model with 7 billion parameters. You can find more details about model in the model card, paper and release blog post.
zephyr-7b-beta - Zephyr is a series of language models that are trained to act as helpful assistants. Zephyr-7B-beta is the second model in the series, and is a fine-tuned version of mistralai/Mistral-7B-v0.1 that was trained on on a mix of publicly available, synthetic datasets using Direct Preference Optimization (DPO). You can find more details about model in technical report and HuggingFace model card.
neural-chat-7b-v3-1 - Mistral-7b model fine-tuned using Intel Gaudi. The model fine-tuned on the open source dataset Open-Orca/SlimOrca and aligned with Direct Preference Optimization (DPO) algorithm. More details can be found in model card and blog post.
notus-7b-v1 - Notus is a collection of fine-tuned models using Direct Preference Optimization (DPO). and related RLHF techniques. This model is the first version, fine-tuned with DPO over zephyr-7b-sft. Following a data-first approach, the only difference between Notus-7B-v1 and Zephyr-7B-beta is the preference dataset used for dDPO. Proposed approach for dataset creation helps to effectively fine-tune Notus-7b that surpasses Zephyr-7B-beta and Claude 2 on AlpacaEval. More details about model can be found in model card.
youri-7b-chat - Youri-7b-chat is a Llama2 based model. Rinna Co., Ltd. conducted further pre-training for the Llama2 model with a mixture of English and Japanese datasets to improve Japanese task capability. The model is publicly released on Hugging Face hub. You can find detailed information at the rinna/youri-7b-chat project page.
baichuan2-7b-chat - Baichuan 2 is the new generation of large-scale open-source language models launched by Baichuan Intelligence inc. It is trained on a high-quality corpus with 2.6 trillion tokens and has achieved the best performance in authoritative Chinese and English benchmarks of the same size.
internlm2-chat-1.8b - InternLM2 is the second generation InternLM series. Compared to the previous generation model, it shows significant improvements in various capabilities, including reasoning, mathematics, and coding. More details about model can be found in model repository.
glm-4-9b-chat - GLM-4-9B is the open-source version of the latest generation of pre-trained models in the GLM-4 series launched by Zhipu AI. In the evaluation of data sets in semantics, mathematics, reasoning, code, and knowledge, GLM-4-9B and its human preference-aligned version GLM-4-9B-Chat have shown superior performance beyond Llama-3-8B. In addition to multi-round conversations, GLM-4-9B-Chat also has advanced features such as web browsing, code execution, custom tool calls (Function Call), and long text reasoning (supporting up to 128K context). More details about model can be found in model card, technical report and repository
DeepSeek-R1-Distill-Qwen-1.5B - Qwen2.5-1.5B fine-tuned using the reasoning data generated by DeepSeek-R1. You can find more info in model card
DeepSeek-R1-Distill-Qwen-7B - Qwen2.5-7B fine-tuned using the reasoning data generated by DeepSeek-R1. You can find more info in model card
DeepSeek-R1-Distill-Llama-8B - Llama-3.1-8B fine-tuned using the reasoning data generated by DeepSeek-R1. You can find more info in model card
from llm_config import SUPPORTED_LLM_MODELS
import ipywidgets as widgets
model_languages = list(SUPPORTED_LLM_MODELS)
model_language = widgets.Dropdown(
options=model_languages,
value=model_languages[0],
description="Model Language:",
disabled=False,
)
model_language
Dropdown(description='Model Language:', options=('English', 'Chinese', 'Japanese'), value='English')
model_ids = list(SUPPORTED_LLM_MODELS[model_language.value])
model_id = widgets.Dropdown(
options=model_ids,
value=model_ids[0],
description="Model:",
disabled=False,
)
model_id
Dropdown(description='Model:', options=('qwen2-0.5b-instruct', 'tiny-llama-1b-chat', 'qwen2-1.5b-instruct', 'g…
model_configuration = SUPPORTED_LLM_MODELS[model_language.value][model_id.value]
print(f"Selected model {model_id.value}")
Selected model qwen2-0.5b-instruct
Convert model using Optimum-CLI tool#
Optimum Intel is the interface between the Transformers and Diffusers libraries and OpenVINO to accelerate end-to-end pipelines on Intel architectures. It provides ease-to-use cli interface for exporting models to OpenVINO Intermediate Representation (IR) format.
The command bellow demonstrates basic command for model export with
optimum-cli
optimum-cli export openvino --model <model_id_or_path> --task <task> <out_dir>
where --model argument is model id from HuggingFace Hub or local
directory with model (saved using .save_pretrained method),
--task is one of supported
task
that exported model should solve. For LLMs it will be
text-generation-with-past. If model initialization requires to use
remote code, --trust-remote-code flag additionally should be passed.
Compress model weights#
The Weights Compression algorithm is aimed at compressing the weights of the models and can be used to optimize the model footprint and performance of large models where the size of weights is relatively larger than the size of activations, for example, Large Language Models (LLM). Compared to INT8 compression, INT4 compression improves performance even more, but introduces a minor drop in prediction quality.
Weights Compression using Optimum-CLI#
You can also apply fp16, 8-bit or 4-bit weight compression on the
Linear, Convolutional and Embedding layers when exporting your model
with the CLI by setting --weight-format to respectively fp16, int8
or int4. This type of optimization allows to reduce the memory footprint
and inference latency. By default the quantization scheme for int8/int4
will be
asymmetric,
to make it
symmetric
you can add --sym.
For INT4 quantization you can also specify the following arguments :
The
--group-sizeparameter will define the group size to use for quantization, -1 it will results in per-column quantization.The
--ratioparameter controls the ratio between 4-bit and 8-bit quantization. If set to 0.9, it means that 90% of the layers will be quantized to int4 while 10% will be quantized to int8.
Smaller group_size and ratio values usually improve accuracy at the sacrifice of the model size and inference latency.
Note: There may be no speedup for INT4/INT8 compressed models on dGPU.
from IPython.display import Markdown, display
prepare_int4_model = widgets.Checkbox(
value=True,
description="Prepare INT4 model",
disabled=False,
)
prepare_int8_model = widgets.Checkbox(
value=False,
description="Prepare INT8 model",
disabled=False,
)
prepare_fp16_model = widgets.Checkbox(
value=False,
description="Prepare FP16 model",
disabled=False,
)
display(prepare_int4_model)
display(prepare_int8_model)
display(prepare_fp16_model)
Checkbox(value=True, description='Prepare INT4 model')
Checkbox(value=False, description='Prepare INT8 model')
Checkbox(value=False, description='Prepare FP16 model')
Weight compression with AWQ#
Activation-aware Weight
Quantization (AWQ) is an algorithm
that tunes model weights for more accurate INT4 compression. It slightly
improves generation quality of compressed LLMs, but requires significant
additional time for tuning weights on a calibration dataset. We use
wikitext-2-raw-v1/train subset of the
Wikitext
dataset for calibration.
Below you can enable AWQ to be additionally applied during model export with INT4 precision.
Note: Applying AWQ requires significant memory and time.
Note: It is possible that there will be no matching patterns in the model to apply AWQ, in such case it will be skipped.
enable_awq = widgets.Checkbox(
value=False,
description="Enable AWQ",
disabled=not prepare_int4_model.value,
)
display(enable_awq)
Checkbox(value=False, description='Enable AWQ')
We can now save floating point and compressed model variants
from pathlib import Path
pt_model_id = model_configuration["model_id"]
pt_model_name = model_id.value.split("-")[0]
fp16_model_dir = Path(model_id.value) / "FP16"
int8_model_dir = Path(model_id.value) / "INT8_compressed_weights"
int4_model_dir = Path(model_id.value) / "INT4_compressed_weights"
def convert_to_fp16():
if (fp16_model_dir / "openvino_model.xml").exists():
return
remote_code = model_configuration.get("remote_code", False)
export_command_base = "optimum-cli export openvino --model {} --task text-generation-with-past --weight-format fp16".format(pt_model_id)
if remote_code:
export_command_base += " --trust-remote-code"
export_command = export_command_base + " " + str(fp16_model_dir)
display(Markdown("**Export command:**"))
display(Markdown(f"`{export_command}`"))
! $export_command
def convert_to_int8():
if (int8_model_dir / "openvino_model.xml").exists():
return
int8_model_dir.mkdir(parents=True, exist_ok=True)
remote_code = model_configuration.get("remote_code", False)
export_command_base = "optimum-cli export openvino --model {} --task text-generation-with-past --weight-format int8".format(pt_model_id)
if remote_code:
export_command_base += " --trust-remote-code"
export_command = export_command_base + " " + str(int8_model_dir)
display(Markdown("**Export command:**"))
display(Markdown(f"`{export_command}`"))
! $export_command
def convert_to_int4():
compression_configs = {
"zephyr-7b-beta": {
"sym": True,
"group_size": 64,
"ratio": 0.6,
},
"mistral-7b": {
"sym": True,
"group_size": 64,
"ratio": 0.6,
},
"minicpm-2b-dpo": {
"sym": True,
"group_size": 64,
"ratio": 0.6,
},
"gemma-2b-it": {
"sym": True,
"group_size": 64,
"ratio": 0.6,
},
"notus-7b-v1": {
"sym": True,
"group_size": 64,
"ratio": 0.6,
},
"neural-chat-7b-v3-1": {
"sym": True,
"group_size": 64,
"ratio": 0.6,
},
"llama-2-chat-7b": {
"sym": True,
"group_size": 128,
"ratio": 0.8,
},
"llama-3-8b-instruct": {
"sym": True,
"group_size": 128,
"ratio": 0.8,
},
"llama-3.1-8b-instruct": {
"sym": True,
"group_size": 128,
"ratio": 1.0,
},
"gemma-7b-it": {
"sym": True,
"group_size": 128,
"ratio": 0.8,
},
"chatglm2-6b": {
"sym": True,
"group_size": 128,
"ratio": 0.72,
},
"qwen-7b-chat": {"sym": True, "group_size": 128, "ratio": 0.6},
"red-pajama-3b-chat": {
"sym": False,
"group_size": 128,
"ratio": 0.5,
},
"qwen2.5-7b-instruct": {"sym": True, "group_size": 128, "ratio": 1.0},
"qwen2.5-3b-instruct": {"sym": True, "group_size": 128, "ratio": 1.0},
"qwen2.5-14b-instruct": {"sym": True, "group_size": 128, "ratio": 1.0},
"qwen2.5-1.5b-instruct": {"sym": True, "group_size": 128, "ratio": 1.0},
"qwen2.5-0.5b-instruct": {"sym": True, "group_size": 128, "ratio": 1.0},
"default": {
"sym": False,
"group_size": 128,
"ratio": 0.8,
},
}
model_compression_params = compression_configs.get(model_id.value, compression_configs["default"])
if (int4_model_dir / "openvino_model.xml").exists():
return
remote_code = model_configuration.get("remote_code", False)
export_command_base = "optimum-cli export openvino --model {} --task text-generation-with-past --weight-format int4".format(pt_model_id)
int4_compression_args = " --group-size {} --ratio {}".format(model_compression_params["group_size"], model_compression_params["ratio"])
if model_compression_params["sym"]:
int4_compression_args += " --sym"
if enable_awq.value:
int4_compression_args += " --awq --dataset wikitext2 --num-samples 128"
export_command_base += int4_compression_args
if remote_code:
export_command_base += " --trust-remote-code"
export_command = export_command_base + " " + str(int4_model_dir)
display(Markdown("**Export command:**"))
display(Markdown(f"`{export_command}`"))
! $export_command
if prepare_fp16_model.value:
convert_to_fp16()
if prepare_int8_model.value:
convert_to_int8()
if prepare_int4_model.value:
convert_to_int4()
Let’s compare model size for different compression types
fp16_weights = fp16_model_dir / "openvino_model.bin"
int8_weights = int8_model_dir / "openvino_model.bin"
int4_weights = int4_model_dir / "openvino_model.bin"
if fp16_weights.exists():
print(f"Size of FP16 model is {fp16_weights.stat().st_size / 1024 / 1024:.2f} MB")
for precision, compressed_weights in zip([8, 4], [int8_weights, int4_weights]):
if compressed_weights.exists():
print(f"Size of model with INT{precision} compressed weights is {compressed_weights.stat().st_size / 1024 / 1024:.2f} MB")
if compressed_weights.exists() and fp16_weights.exists():
print(f"Compression rate for INT{precision} model: {fp16_weights.stat().st_size / compressed_weights.stat().st_size:.3f}")
Size of model with INT4 compressed weights is 358.86 MB
Select device for inference and model variant#
Note: There may be no speedup for INT4/INT8 compressed models on dGPU.
import requests
r = requests.get(
url="https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/utils/notebook_utils.py",
)
open("notebook_utils.py", "w").write(r.text)
from notebook_utils import device_widget
device = device_widget("CPU", exclude=["NPU"])
device
# Read more about telemetry collection at https://github.com/openvinotoolkit/openvino_notebooks?tab=readme-ov-file#-telemetry
from notebook_utils import collect_telemetry
collect_telemetry("llm-chatbot.ipynb")
Dropdown(description='Device:', options=('CPU', 'AUTO'), value='CPU')
The cell below demonstrates how to instantiate model based on selected variant of model weights and inference device
available_models = []
if int4_model_dir.exists():
available_models.append("INT4")
if int8_model_dir.exists():
available_models.append("INT8")
if fp16_model_dir.exists():
available_models.append("FP16")
model_to_run = widgets.Dropdown(
options=available_models,
value=available_models[0],
description="Model to run:",
disabled=False,
)
model_to_run
Dropdown(description='Model to run:', options=('INT4',), value='INT4')
Instantiate Model using Optimum Intel#
Optimum Intel can be used to load optimized models from the Hugging
Face Hub and
create pipelines to run an inference with OpenVINO Runtime using Hugging
Face APIs. The Optimum Inference models are API compatible with Hugging
Face Transformers models. This means we just need to replace
AutoModelForXxx class with the corresponding OVModelForXxx
class.
Below is an example of the RedPajama model
-from transformers import AutoModelForCausalLM
+from optimum.intel.openvino import OVModelForCausalLM
from transformers import AutoTokenizer, pipeline
model_id = "togethercomputer/RedPajama-INCITE-Chat-3B-v1"
-model = AutoModelForCausalLM.from_pretrained(model_id)
+model = OVModelForCausalLM.from_pretrained(model_id, export=True)
Model class initialization starts with calling from_pretrained
method. When downloading and converting Transformers model, the
parameter export=True should be added (as we already converted model
before, we do not need to provide this parameter). We can save the
converted model for the next usage with the save_pretrained method.
Tokenizer class and pipelines API are compatible with Optimum models.
You can find more details about OpenVINO LLM inference using HuggingFace Optimum API in LLM inference guide.
from transformers import AutoConfig, AutoTokenizer
from optimum.intel.openvino import OVModelForCausalLM
import openvino as ov
import openvino.properties as props
import openvino.properties.hint as hints
import openvino.properties.streams as streams
if model_to_run.value == "INT4":
model_dir = int4_model_dir
elif model_to_run.value == "INT8":
model_dir = int8_model_dir
else:
model_dir = fp16_model_dir
print(f"Loading model from {model_dir}")
ov_config = {hints.performance_mode(): hints.PerformanceMode.LATENCY, streams.num(): "1", props.cache_dir(): ""}
if "GPU" in device.value and "qwen2-7b-instruct" in model_id.value:
ov_config["GPU_ENABLE_SDPA_OPTIMIZATION"] = "NO"
# On a GPU device a model is executed in FP16 precision. For red-pajama-3b-chat model there known accuracy
# issues caused by this, which we avoid by setting precision hint to "f32".
core = ov.Core()
if model_id.value == "red-pajama-3b-chat" and "GPU" in core.available_devices and device.value in ["GPU", "AUTO"]:
ov_config["INFERENCE_PRECISION_HINT"] = "f32"
model_name = model_configuration["model_id"]
tok = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
ov_model = OVModelForCausalLM.from_pretrained(
model_dir,
device=device.value,
ov_config=ov_config,
config=AutoConfig.from_pretrained(model_dir, trust_remote_code=True),
trust_remote_code=True,
)
Loading model from qwen2-0.5b-instruct/INT4_compressed_weights
Compiling the model to CPU ...
tokenizer_kwargs = model_configuration.get("tokenizer_kwargs", {})
test_string = "2 + 2 ="
input_tokens = tok(test_string, return_tensors="pt", **tokenizer_kwargs)
answer = ov_model.generate(**input_tokens, max_new_tokens=2)
print(tok.batch_decode(answer, skip_special_tokens=True)[0])
2 + 2 = 4
Run Chatbot#
Now, when model created, we can setup Chatbot interface using Gradio. The diagram below illustrates how the chatbot pipeline works
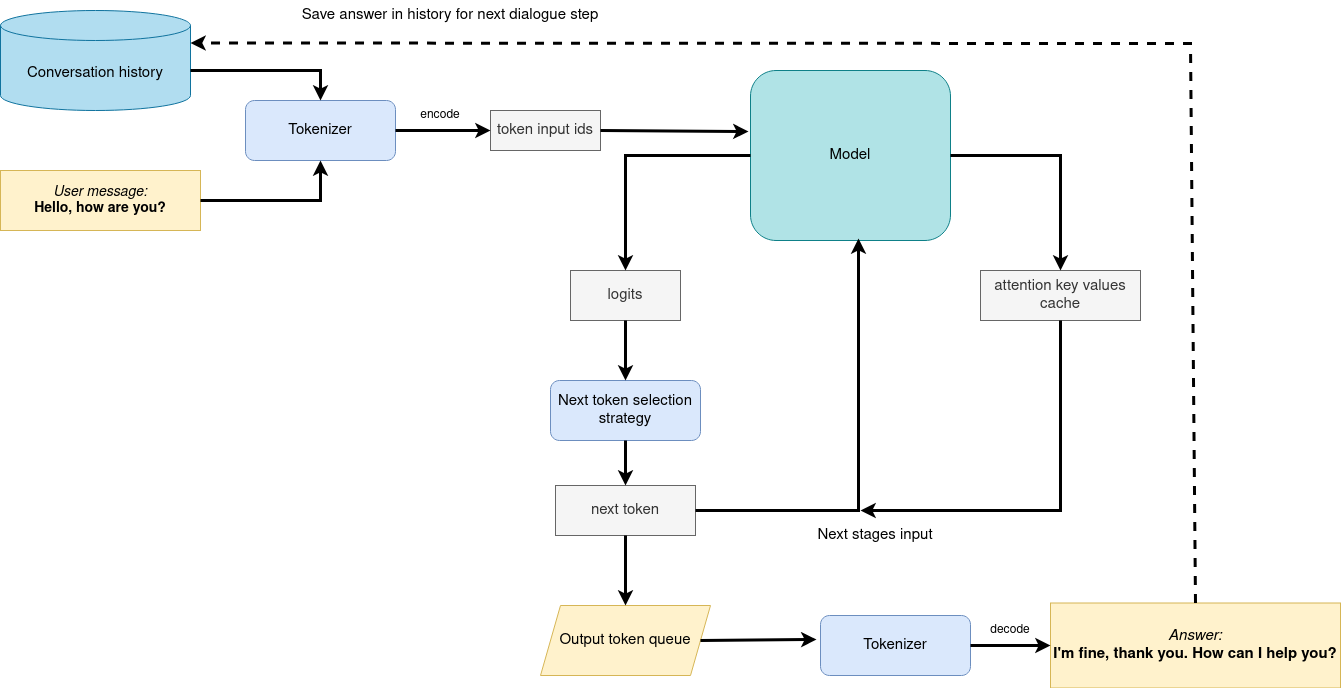
generation pipeline#
As can be seen, the pipeline very similar to instruction-following with only changes that previous conversation history additionally passed as input with next user question for getting wider input context. On the first iteration, the user provided instructions joined to conversation history (if exists) converted to token ids using a tokenizer, then prepared input provided to the model. The model generates probabilities for all tokens in logits format The way the next token will be selected over predicted probabilities is driven by the selected decoding methodology. You can find more information about the most popular decoding methods in this blog. The result generation updates conversation history for next conversation step. it makes stronger connection of next question with previously provided and allows user to make clarifications regarding previously provided answers.https://docs.openvino.ai/2024/learn-openvino/llm_inference_guide.html
Temperature is a parameter used to control the level of
creativity in AI-generated text. By adjusting the temperature, you
can influence the AI model’s probability distribution, making the text
more focused or diverse.playing: 0.5
sleeping: 0.25
eating: 0.15
driving: 0.05
flying: 0.05
- **Low temperature** (e.g., 0.2): The AI model becomes more focused and deterministic, choosing tokens with the highest probability, such as "playing."
- **Medium temperature** (e.g., 1.0): The AI model maintains a balance between creativity and focus, selecting tokens based on their probabilities without significant bias, such as "playing," "sleeping," or "eating."
- **High temperature** (e.g., 2.0): The AI model becomes more adventurous, increasing the chances of selecting less likely tokens, such as "driving" and "flying."
Top-p, also known as nucleus sampling, is a parameter used to control the range of tokens considered by the AI model based on their cumulative probability. By adjusting thetop-pvalue, you can influence the AI model’s token selection, making it more focused or diverse. Using the same example with the cat, consider the following top_p settings:Low top_p (e.g., 0.5): The AI model considers only tokens with the highest cumulative probability, such as “playing.”
Medium top_p (e.g., 0.8): The AI model considers tokens with a higher cumulative probability, such as “playing,” “sleeping,” and “eating.”
High top_p (e.g., 1.0): The AI model considers all tokens, including those with lower probabilities, such as “driving” and “flying.”
Top-kis an another popular sampling strategy. In comparison with Top-P, which chooses from the smallest possible set of words whose cumulative probability exceeds the probability P, in Top-K sampling K most likely next words are filtered and the probability mass is redistributed among only those K next words. In our example with cat, if k=3, then only “playing”, “sleeping” and “eating” will be taken into account as possible next word.Repetition PenaltyThis parameter can help penalize tokens based on how frequently they occur in the text, including the input prompt. A token that has already appeared five times is penalized more heavily than a token that has appeared only one time. A value of 1 means that there is no penalty and values larger than 1 discourage repeated tokens.https://docs.openvino.ai/2024/learn-openvino/llm_inference_guide.html
import torch
from threading import Event, Thread
from typing import List, Tuple
from transformers import (
AutoTokenizer,
StoppingCriteria,
StoppingCriteriaList,
TextIteratorStreamer,
)
model_name = model_configuration["model_id"]
start_message = model_configuration["start_message"]
history_template = model_configuration.get("history_template")
has_chat_template = model_configuration.get("has_chat_template", history_template is None)
current_message_template = model_configuration.get("current_message_template")
stop_tokens = model_configuration.get("stop_tokens")
tokenizer_kwargs = model_configuration.get("tokenizer_kwargs", {})
max_new_tokens = 256
class StopOnTokens(StoppingCriteria):
def __init__(self, token_ids):
self.token_ids = token_ids
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> bool:
for stop_id in self.token_ids:
if input_ids[0][-1] == stop_id:
return True
return False
if stop_tokens is not None:
if isinstance(stop_tokens[0], str):
stop_tokens = tok.convert_tokens_to_ids(stop_tokens)
stop_tokens = [StopOnTokens(stop_tokens)]
def default_partial_text_processor(partial_text: str, new_text: str):
"""
helper for updating partially generated answer, used by default
Params:
partial_text: text buffer for storing previosly generated text
new_text: text update for the current step
Returns:
updated text string
"""
partial_text += new_text
return partial_text
text_processor = model_configuration.get("partial_text_processor", default_partial_text_processor)
def convert_history_to_token(history: List[Tuple[str, str]]):
"""
function for conversion history stored as list pairs of user and assistant messages to tokens according to model expected conversation template
Params:
history: dialogue history
Returns:
history in token format
"""
if pt_model_name == "baichuan2":
system_tokens = tok.encode(start_message)
history_tokens = []
for old_query, response in history[:-1]:
round_tokens = []
round_tokens.append(195)
round_tokens.extend(tok.encode(old_query))
round_tokens.append(196)
round_tokens.extend(tok.encode(response))
history_tokens = round_tokens + history_tokens
input_tokens = system_tokens + history_tokens
input_tokens.append(195)
input_tokens.extend(tok.encode(history[-1][0]))
input_tokens.append(196)
input_token = torch.LongTensor([input_tokens])
elif history_template is None or has_chat_template:
messages = [{"role": "system", "content": start_message}]
for idx, (user_msg, model_msg) in enumerate(history):
if idx == len(history) - 1 and not model_msg:
messages.append({"role": "user", "content": user_msg})
break
if user_msg:
messages.append({"role": "user", "content": user_msg})
if model_msg:
messages.append({"role": "assistant", "content": model_msg})
input_token = tok.apply_chat_template(messages, add_generation_prompt=True, tokenize=True, return_tensors="pt")
else:
text = start_message + "".join(
["".join([history_template.format(num=round, user=item[0], assistant=item[1])]) for round, item in enumerate(history[:-1])]
)
text += "".join(
[
"".join(
[
current_message_template.format(
num=len(history) + 1,
user=history[-1][0],
assistant=history[-1][1],
)
]
)
]
)
input_token = tok(text, return_tensors="pt", **tokenizer_kwargs).input_ids
return input_token
def bot(history, temperature, top_p, top_k, repetition_penalty, conversation_id):
"""
callback function for running chatbot on submit button click
Params:
history: conversation history
temperature: parameter for control the level of creativity in AI-generated text.
By adjusting the `temperature`, you can influence the AI model's probability distribution, making the text more focused or diverse.
top_p: parameter for control the range of tokens considered by the AI model based on their cumulative probability.
top_k: parameter for control the range of tokens considered by the AI model based on their cumulative probability, selecting number of tokens with highest probability.
repetition_penalty: parameter for penalizing tokens based on how frequently they occur in the text.
conversation_id: unique conversation identifier.
"""
# Construct the input message string for the model by concatenating the current system message and conversation history
# Tokenize the messages string
input_ids = convert_history_to_token(history)
if input_ids.shape[1] > 2000:
history = [history[-1]]
input_ids = convert_history_to_token(history)
streamer = TextIteratorStreamer(tok, timeout=3600.0, skip_prompt=True, skip_special_tokens=True)
generate_kwargs = dict(
input_ids=input_ids,
max_new_tokens=max_new_tokens,
temperature=temperature,
do_sample=temperature > 0.0,
top_p=top_p,
top_k=top_k,
repetition_penalty=repetition_penalty,
streamer=streamer,
)
if stop_tokens is not None:
generate_kwargs["stopping_criteria"] = StoppingCriteriaList(stop_tokens)
stream_complete = Event()
def generate_and_signal_complete():
"""
genration function for single thread
"""
global start_time
ov_model.generate(**generate_kwargs)
stream_complete.set()
t1 = Thread(target=generate_and_signal_complete)
t1.start()
# Initialize an empty string to store the generated text
partial_text = ""
for new_text in streamer:
partial_text = text_processor(partial_text, new_text)
history[-1][1] = partial_text
yield history
def request_cancel():
ov_model.request.cancel()
if not Path("gradio_helper.py").exists():
r = requests.get(url="https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/notebooks/llm-chatbot/gradio_helper.py")
open("gradio_helper.py", "w").write(r.text)
from gradio_helper import make_demo
demo = make_demo(run_fn=bot, stop_fn=request_cancel, title=f"OpenVINO {model_id.value} Chatbot", language=model_language.value)
try:
demo.launch()
except Exception:
demo.launch(share=True)
# If you are launching remotely, specify server_name and server_port
# EXAMPLE: `demo.launch(server_name='your server name', server_port='server port in int')`
# To learn more please refer to the Gradio docs: https://gradio.app/docs/
# please uncomment and run this cell for stopping gradio interface
# demo.close()
Next Step#
Besides chatbot, we can use LangChain to augmenting LLM knowledge with additional data, which allow you to build AI applications that can reason about private data or data introduced after a model’s cutoff date. You can find this solution in Retrieval-augmented generation (RAG) example.