Automatic Device Selection with OpenVINO™#
This Jupyter notebook can be launched on-line, opening an interactive environment in a browser window. You can also make a local installation. Choose one of the following options:



The Auto
device
(or AUTO in short) selects the most suitable device for inference by
considering the model precision, power efficiency and processing
capability of the available compute
devices.
The model precision (such as FP32, FP16, INT8, etc.) is the
first consideration to filter out the devices that cannot run the
network efficiently.
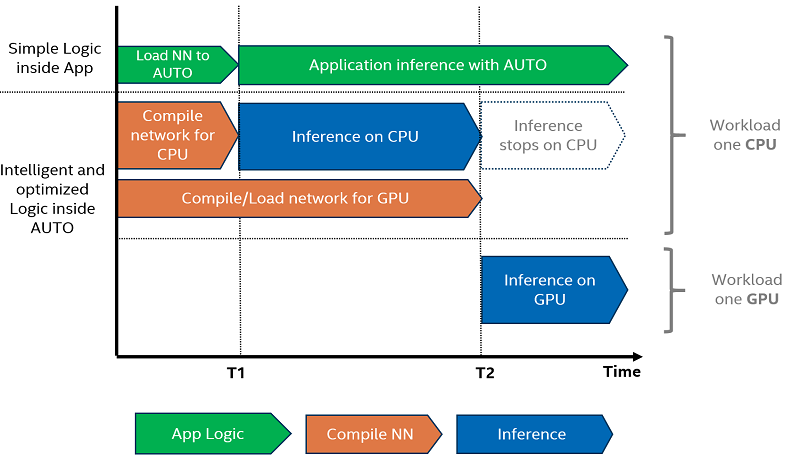
Next, if dedicated accelerators are available, these devices are preferred (for example, integrated and discrete GPU). CPU is used as the default “fallback device”. Keep in mind that AUTO makes this selection only once, during the loading of a model.
When using accelerator devices such as GPUs, loading models to these devices may take a long time. To address this challenge for applications that require fast first inference response, AUTO starts inference immediately on the CPU and then transparently shifts inference to the GPU, once it is ready. This dramatically reduces the time to execute first inference.
auto#
Table of contents:
Installation Instructions#
This is a self-contained example that relies solely on its own code.
We recommend running the notebook in a virtual environment. You only need a Jupyter server to start. For details, please refer to Installation Guide.
Import modules and create Core#
import platform
# Install required packages
%pip install -q "openvino>=2023.1.0" "matplotlib>=3.4" Pillow torch torchvision tqdm --extra-index-url https://download.pytorch.org/whl/cpu
if platform.system() == "Darwin":
%pip install -q "numpy<2.0.0"
Note: you may need to restart the kernel to use updated packages.
import time
import sys
import openvino as ov
from IPython.display import Markdown, display
core = ov.Core()
if not any("GPU" in device for device in core.available_devices):
display(
Markdown(
'<div class="alert alert-block alert-danger"><b>Warning: </b> A GPU device is not available. This notebook requires GPU device to have meaningful results. </div>'
)
)
Warning
Warning: A GPU device is not available. This notebook requires GPU device to have meaningful results.
Convert the model to OpenVINO IR format#
This tutorial uses
resnet50
model from
torchvision
library. ResNet 50 is image classification model pre-trained on ImageNet
dataset described in paper “Deep Residual Learning for Image
Recognition”. From OpenVINO
2023.0, we can directly convert a model from the PyTorch format to the
OpenVINO IR format using model conversion API. To convert model, we
should provide model object instance into ov.convert_model function,
optionally, we can specify input shape for conversion (by default models
from PyTorch converted with dynamic input shapes). ov.convert_model
returns openvino.runtime.Model object ready to be loaded on a device
with ov.compile_model or serialized for next usage with
ov.save_model.
For more information about model conversion API, see this page.
import torchvision
from pathlib import Path
base_model_dir = Path("./model")
base_model_dir.mkdir(exist_ok=True)
model_path = base_model_dir / "resnet50.xml"
if not model_path.exists():
pt_model = torchvision.models.resnet50(weights="DEFAULT")
ov_model = ov.convert_model(pt_model, input=[[1, 3, 224, 224]])
ov.save_model(ov_model, str(model_path))
print("IR model saved to {}".format(model_path))
else:
print("Read IR model from {}".format(model_path))
ov_model = core.read_model(model_path)
IR model saved to model/resnet50.xml
(1) Simplify selection logic#
Default behavior of Core::compile_model API without device_name#
By default, compile_model API will select AUTO as
device_name if no device is specified.
import openvino.properties.log as log
# Set LOG_LEVEL to LOG_INFO.
core.set_property("AUTO", {log.level(): log.Level.INFO})
# Load the model onto the target device.
compiled_model = core.compile_model(ov_model)
if isinstance(compiled_model, ov.CompiledModel):
print("Successfully compiled model without a device_name.")
[23:05:31.1930]I[plugin.cpp:421][AUTO] device:CPU, config:LOG_LEVEL=LOG_INFO
[23:05:31.1930]I[plugin.cpp:421][AUTO] device:CPU, config:PERFORMANCE_HINT=LATENCY
[23:05:31.1931]I[plugin.cpp:421][AUTO] device:CPU, config:PERFORMANCE_HINT_NUM_REQUESTS=0
[23:05:31.1931]I[plugin.cpp:421][AUTO] device:CPU, config:PERF_COUNT=NO
[23:05:31.1931]I[plugin.cpp:426][AUTO] device:CPU, priority:0
[23:05:31.1931]I[schedule.cpp:17][AUTO] scheduler starting
[23:05:31.1931]I[auto_schedule.cpp:181][AUTO] select device:CPU
[23:05:31.3235]I[auto_schedule.cpp:346][AUTO] Device: [CPU]: Compile model took 130.407415 ms
[23:05:31.3237]I[auto_schedule.cpp:112][AUTO] device:CPU compiling model finished
[23:05:31.3238]I[plugin.cpp:454][AUTO] underlying hardware does not support hardware context
Successfully compiled model without a device_name.
# Deleted model will wait until compiling on the selected device is complete.
del compiled_model
print("Deleted compiled_model")
Deleted compiled_model
[23:05:31.3290]I[schedule.cpp:308][AUTO] scheduler ending
Explicitly pass AUTO as device_name to Core::compile_model API#
It is optional, but passing AUTO explicitly as device_name may
improve readability of your code.
# Set LOG_LEVEL to LOG_NONE.
core.set_property("AUTO", {log.level(): log.Level.NO})
compiled_model = core.compile_model(model=ov_model, device_name="AUTO")
if isinstance(compiled_model, ov.CompiledModel):
print("Successfully compiled model using AUTO.")
Successfully compiled model using AUTO.
# Deleted model will wait until compiling on the selected device is complete.
del compiled_model
print("Deleted compiled_model")
Deleted compiled_model
(2) Improve the first inference latency#
One of the benefits of using AUTO device selection is reducing FIL (first inference latency). FIL is the model compilation time combined with the first inference execution time. Using the CPU device explicitly will produce the shortest first inference latency, as the OpenVINO graph representation loads quickly on CPU, using just-in-time (JIT) compilation. The challenge is with GPU devices since OpenCL graph complication to GPU-optimized kernels takes a few seconds to complete. This initialization time may be intolerable for some applications. To avoid this delay, the AUTO uses CPU transparently as the first inference device until GPU is ready.
Load an Image#
torchvision library provides model specific input transformation function, we will reuse it for preparing input data.
# Fetch `notebook_utils` module
import requests
if not Path("notebook_utils.py").exists():
r = requests.get(url="https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/utils/notebook_utils.py")
open("notebook_utils.py", "w").write(r.text)
from notebook_utils import download_file
# Read more about telemetry collection at https://github.com/openvinotoolkit/openvino_notebooks?tab=readme-ov-file#-telemetry
from notebook_utils import collect_telemetry
collect_telemetry("auto-device.ipynb")
from PIL import Image
image_filename = Path("data/coco.jpg")
if not image_filename.exists():
# Download the image from the openvino_notebooks storage
image_filename = download_file(
"https://storage.openvinotoolkit.org/repositories/openvino_notebooks/data/data/image/coco.jpg",
directory="data",
)
image = Image.open(str(image_filename))
input_transform = torchvision.models.ResNet50_Weights.DEFAULT.transforms()
input_tensor = input_transform(image)
input_tensor = input_tensor.unsqueeze(0).numpy()
image
coco.jpg: 0%| | 0.00/202k [00:00<?, ?B/s]

Load the model to GPU device and perform inference#
if not any("GPU" in device for device in core.available_devices):
print(f"A GPU device is not available. Available devices are: {core.available_devices}")
else:
# Start time.
gpu_load_start_time = time.perf_counter()
compiled_model = core.compile_model(model=ov_model, device_name="GPU") # load to GPU
# Execute the first inference.
results = compiled_model(input_tensor)[0]
# Measure time to the first inference.
gpu_fil_end_time = time.perf_counter()
gpu_fil_span = gpu_fil_end_time - gpu_load_start_time
print(f"Time to load model on GPU device and get first inference: {gpu_fil_end_time-gpu_load_start_time:.2f} seconds.")
del compiled_model
A GPU device is not available. Available devices are: ['CPU']
Load the model using AUTO device and do inference#
When GPU is the best available device, the first few inferences will be executed on CPU until GPU is ready.
# Start time.
auto_load_start_time = time.perf_counter()
compiled_model = core.compile_model(model=ov_model) # The device_name is AUTO by default.
# Execute the first inference.
results = compiled_model(input_tensor)[0]
# Measure time to the first inference.
auto_fil_end_time = time.perf_counter()
auto_fil_span = auto_fil_end_time - auto_load_start_time
print(f"Time to load model using AUTO device and get first inference: {auto_fil_end_time-auto_load_start_time:.2f} seconds.")
Time to load model using AUTO device and get first inference: 0.13 seconds.
# Deleted model will wait for compiling on the selected device to complete.
del compiled_model
(3) Achieve different performance for different targets#
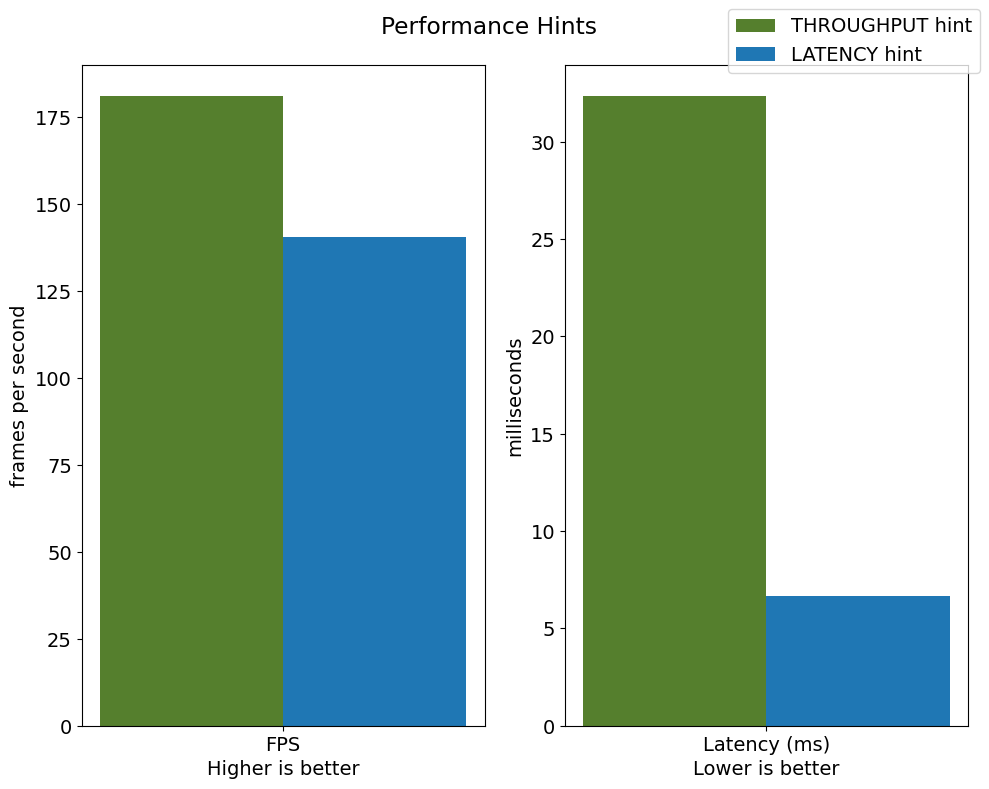
It is an advantage to define performance hints when using Automatic Device Selection. By specifying a THROUGHPUT or LATENCY hint, AUTO optimizes the performance based on the desired metric. The THROUGHPUT hint delivers higher frame per second (FPS) performance than the LATENCY hint, which delivers lower latency. The performance hints do not require any device-specific settings and they are completely portable between devices – meaning AUTO can configure the performance hint on whichever device is being used.
For more information, refer to the Performance Hints section of Automatic Device Selection article.
Class and callback definition#
class PerformanceMetrics:
"""
Record the latest performance metrics (fps and latency), update the metrics in each @interval seconds
:member: fps: Frames per second, indicates the average number of inferences executed each second during the last @interval seconds.
:member: latency: Average latency of inferences executed in the last @interval seconds.
:member: start_time: Record the start timestamp of onging @interval seconds duration.
:member: latency_list: Record the latency of each inference execution over @interval seconds duration.
:member: interval: The metrics will be updated every @interval seconds
"""
def __init__(self, interval):
"""
Create and initilize one instance of class PerformanceMetrics.
:param: interval: The metrics will be updated every @interval seconds
:returns:
Instance of PerformanceMetrics
"""
self.fps = 0
self.latency = 0
self.start_time = time.perf_counter()
self.latency_list = []
self.interval = interval
def update(self, infer_request: ov.InferRequest) -> bool:
"""
Update the metrics if current ongoing @interval seconds duration is expired. Record the latency only if it is not expired.
:param: infer_request: InferRequest returned from inference callback, which includes the result of inference request.
:returns:
True, if metrics are updated.
False, if @interval seconds duration is not expired and metrics are not updated.
"""
self.latency_list.append(infer_request.latency)
exec_time = time.perf_counter() - self.start_time
if exec_time >= self.interval:
# Update the performance metrics.
self.start_time = time.perf_counter()
self.fps = len(self.latency_list) / exec_time
self.latency = sum(self.latency_list) / len(self.latency_list)
print(f"throughput: {self.fps: .2f}fps, latency: {self.latency: .2f}ms, time interval:{exec_time: .2f}s")
sys.stdout.flush()
self.latency_list = []
return True
else:
return False
class InferContext:
"""
Inference context. Record and update peforamnce metrics via @metrics, set @feed_inference to False once @remaining_update_num <=0
:member: metrics: instance of class PerformanceMetrics
:member: remaining_update_num: the remaining times for peforamnce metrics updating.
:member: feed_inference: if feed inference request is required or not.
"""
def __init__(self, update_interval, num):
"""
Create and initilize one instance of class InferContext.
:param: update_interval: The performance metrics will be updated every @update_interval seconds. This parameter will be passed to class PerformanceMetrics directly.
:param: num: The number of times performance metrics are updated.
:returns:
Instance of InferContext.
"""
self.metrics = PerformanceMetrics(update_interval)
self.remaining_update_num = num
self.feed_inference = True
def update(self, infer_request: ov.InferRequest):
"""
Update the context. Set @feed_inference to False if the number of remaining performance metric updates (@remaining_update_num) reaches 0
:param: infer_request: InferRequest returned from inference callback, which includes the result of inference request.
:returns: None
"""
if self.remaining_update_num <= 0:
self.feed_inference = False
if self.metrics.update(infer_request):
self.remaining_update_num = self.remaining_update_num - 1
if self.remaining_update_num <= 0:
self.feed_inference = False
def completion_callback(infer_request: ov.InferRequest, context) -> None:
"""
callback for the inference request, pass the @infer_request to @context for updating
:param: infer_request: InferRequest returned for the callback, which includes the result of inference request.
:param: context: user data which is passed as the second parameter to AsyncInferQueue:start_async()
:returns: None
"""
context.update(infer_request)
# Performance metrics update interval (seconds) and number of times.
metrics_update_interval = 10
metrics_update_num = 6
Inference with THROUGHPUT hint#
Loop for inference and update the FPS/Latency every @metrics_update_interval seconds.
import openvino.properties.hint as hints
THROUGHPUT_hint_context = InferContext(metrics_update_interval, metrics_update_num)
print("Compiling Model for AUTO device with THROUGHPUT hint")
sys.stdout.flush()
compiled_model = core.compile_model(model=ov_model, config={hints.performance_mode(): hints.PerformanceMode.THROUGHPUT})
infer_queue = ov.AsyncInferQueue(compiled_model, 0) # Setting to 0 will query optimal number by default.
infer_queue.set_callback(completion_callback)
print(f"Start inference, {metrics_update_num: .0f} groups of FPS/latency will be measured over {metrics_update_interval: .0f}s intervals")
sys.stdout.flush()
while THROUGHPUT_hint_context.feed_inference:
infer_queue.start_async(input_tensor, THROUGHPUT_hint_context)
infer_queue.wait_all()
# Take the FPS and latency of the latest period.
THROUGHPUT_hint_fps = THROUGHPUT_hint_context.metrics.fps
THROUGHPUT_hint_latency = THROUGHPUT_hint_context.metrics.latency
print("Done")
del compiled_model
Compiling Model for AUTO device with THROUGHPUT hint
Start inference, 6 groups of FPS/latency will be measured over 10s intervals
throughput: 183.01fps, latency: 31.42ms, time interval: 10.01s
throughput: 181.78fps, latency: 32.22ms, time interval: 10.02s
throughput: 181.19fps, latency: 32.39ms, time interval: 10.01s
throughput: 180.90fps, latency: 32.34ms, time interval: 10.01s
throughput: 182.92fps, latency: 32.06ms, time interval: 10.01s
throughput: 183.14fps, latency: 31.93ms, time interval: 10.01s
Done
Inference with LATENCY hint#
Loop for inference and update the FPS/Latency for each @metrics_update_interval seconds
LATENCY_hint_context = InferContext(metrics_update_interval, metrics_update_num)
print("Compiling Model for AUTO Device with LATENCY hint")
sys.stdout.flush()
compiled_model = core.compile_model(model=ov_model, config={hints.performance_mode(): hints.PerformanceMode.LATENCY})
# Setting to 0 will query optimal number by default.
infer_queue = ov.AsyncInferQueue(compiled_model, 0)
infer_queue.set_callback(completion_callback)
print(f"Start inference, {metrics_update_num: .0f} groups fps/latency will be out with {metrics_update_interval: .0f}s interval")
sys.stdout.flush()
while LATENCY_hint_context.feed_inference:
infer_queue.start_async(input_tensor, LATENCY_hint_context)
infer_queue.wait_all()
# Take the FPS and latency of the latest period.
LATENCY_hint_fps = LATENCY_hint_context.metrics.fps
LATENCY_hint_latency = LATENCY_hint_context.metrics.latency
print("Done")
del compiled_model
Compiling Model for AUTO Device with LATENCY hint
Start inference, 6 groups fps/latency will be out with 10s interval
throughput: 140.07fps, latency: 6.62ms, time interval: 10.00s
throughput: 142.55fps, latency: 6.62ms, time interval: 10.00s
throughput: 138.69fps, latency: 6.83ms, time interval: 10.01s
throughput: 138.53fps, latency: 6.83ms, time interval: 10.01s
throughput: 142.77fps, latency: 6.63ms, time interval: 10.00s
throughput: 142.70fps, latency: 6.63ms, time interval: 10.01s
Done
Difference in FPS and latency#
import matplotlib.pyplot as plt
TPUT = 0
LAT = 1
labels = ["THROUGHPUT hint", "LATENCY hint"]
fig1, ax1 = plt.subplots(1, 1)
fig1.patch.set_visible(False)
ax1.axis("tight")
ax1.axis("off")
cell_text = []
cell_text.append(
[
"%.2f%s" % (THROUGHPUT_hint_fps, " FPS"),
"%.2f%s" % (THROUGHPUT_hint_latency, " ms"),
]
)
cell_text.append(["%.2f%s" % (LATENCY_hint_fps, " FPS"), "%.2f%s" % (LATENCY_hint_latency, " ms")])
table = ax1.table(
cellText=cell_text,
colLabels=["FPS (Higher is better)", "Latency (Lower is better)"],
rowLabels=labels,
rowColours=["deepskyblue"] * 2,
colColours=["deepskyblue"] * 2,
cellLoc="center",
loc="upper left",
)
table.auto_set_font_size(False)
table.set_fontsize(18)
table.auto_set_column_width(0)
table.auto_set_column_width(1)
table.scale(1, 3)
fig1.tight_layout()
plt.show()

# Output the difference.
width = 0.4
fontsize = 14
plt.rc("font", size=fontsize)
fig, ax = plt.subplots(1, 2, figsize=(10, 8))
rects1 = ax[0].bar([0], THROUGHPUT_hint_fps, width, label=labels[TPUT], color="#557f2d")
rects2 = ax[0].bar([width], LATENCY_hint_fps, width, label=labels[LAT])
ax[0].set_ylabel("frames per second")
ax[0].set_xticks([width / 2])
ax[0].set_xticklabels(["FPS"])
ax[0].set_xlabel("Higher is better")
rects1 = ax[1].bar([0], THROUGHPUT_hint_latency, width, label=labels[TPUT], color="#557f2d")
rects2 = ax[1].bar([width], LATENCY_hint_latency, width, label=labels[LAT])
ax[1].set_ylabel("milliseconds")
ax[1].set_xticks([width / 2])
ax[1].set_xticklabels(["Latency (ms)"])
ax[1].set_xlabel("Lower is better")
fig.suptitle("Performance Hints")
fig.legend(labels, fontsize=fontsize)
fig.tight_layout()
plt.show()