Wav2Lip: Accurately Lip-syncing Videos and OpenVINO#
This Jupyter notebook can be launched after a local installation only.

Lip sync technologies are widely used for digital human use cases, which enhance the user experience in dialog scenarios.
Wav2Lip is an approach to generate accurate 2D lip-synced videos in the wild with only one video and an audio clip. Wav2Lip leverages an accurate lip-sync “expert” model and consecutive face frames for accurate, natural lip motion generation.
teaser#
In this notebook, we introduce how to enable and optimize Wav2Lippipeline with OpenVINO. This is adaptation of the blog article Enable 2D Lip Sync Wav2Lip Pipeline with OpenVINO Runtime.
Here is Wav2Lip pipeline overview:
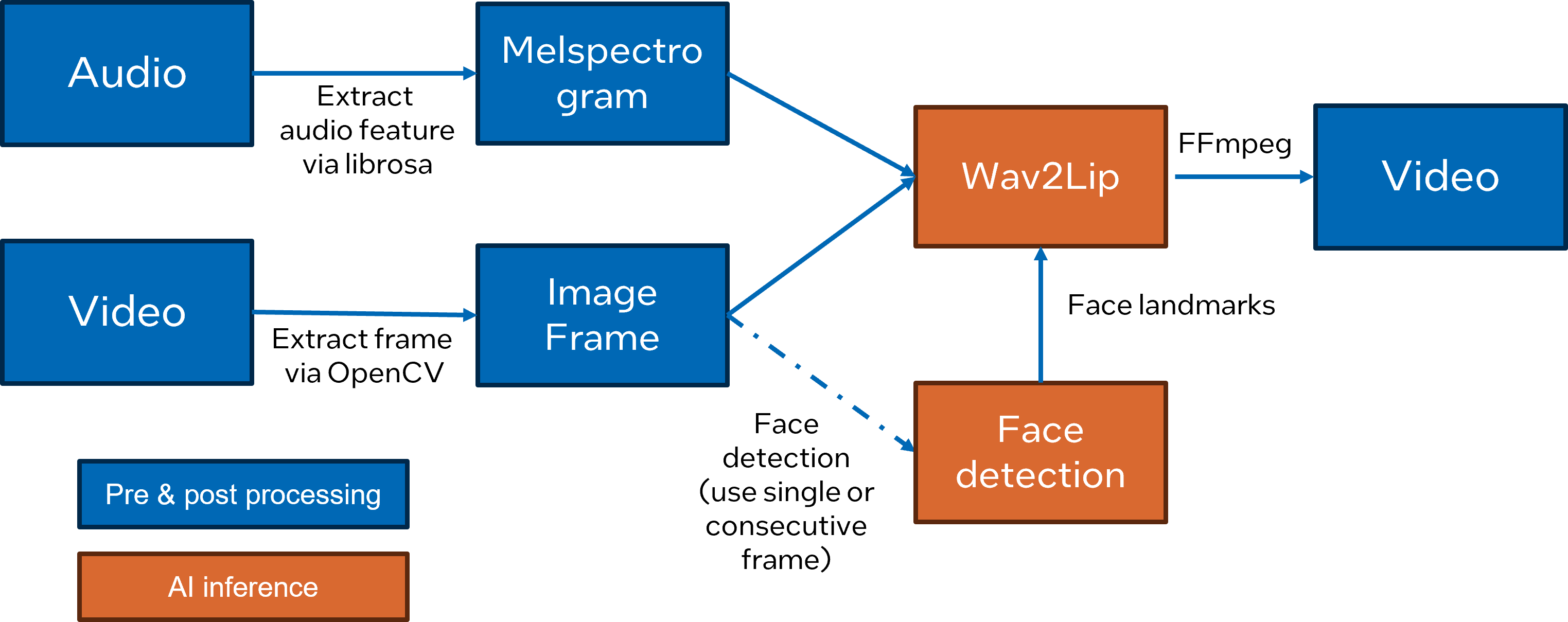
wav2lip_pipeline#
Table of contents:
Installation Instructions#
This is a self-contained example that relies solely on its own code.
We recommend running the notebook in a virtual environment. You only need a Jupyter server to start. For details, please refer to Installation Guide.
Prerequisites#
import requests
from pathlib import Path
if not Path("notebook_utils.py").exists():
r = requests.get(
url="https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/utils/notebook_utils.py",
)
open("notebook_utils.py", "w").write(r.text)
if not Path("pip_helper.py").exists():
r = requests.get(
url="https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/utils/pip_helper.py",
)
open("pip_helper.py", "w").write(r.text)
if not Path("cmd_helper.py").exists():
r = requests.get(
url="https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/utils/cmd_helper.py",
)
open("cmd_helper.py", "w").write(r.text)
from pip_helper import pip_install
pip_install("-q", "openvino>=2024.4.0")
pip_install(
"-q",
"huggingface_hub",
"torch>=2.1",
"gradio>=4.19",
"librosa==0.9.2",
"opencv-contrib-python",
"opencv-python",
"tqdm",
"numba",
"numpy<2",
"--extra-index-url",
"https://download.pytorch.org/whl/cpu",
)
helpers = ["gradio_helper.py", "ov_inference.py", "ov_wav2lip_helper.py"]
for helper_file in helpers:
if not Path(helper_file).exists():
r = requests.get(url=f"https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/notebooks/wav2lip/{helper_file}")
open(helper_file, "w").write(r.text)
# Read more about telemetry collection at https://github.com/openvinotoolkit/openvino_notebooks?tab=readme-ov-file#-telemetry
from notebook_utils import collect_telemetry
collect_telemetry("wav2lip.ipynb")
from cmd_helper import clone_repo
clone_repo("https://github.com/Rudrabha/Wav2Lip.git")
Download example files.
from notebook_utils import download_file
download_file("https://github.com/sammysun0711/openvino_aigc_samples/blob/main/Wav2Lip/data_audio_sun_5s.wav?raw=true")
download_file("https://github.com/sammysun0711/openvino_aigc_samples/blob/main/Wav2Lip/data_video_sun_5s.mp4?raw=true")
Convert the model to OpenVINO IR#
You don’t need to download checkpoints and load models, just call the
helper function download_and_convert_models. It takes care about it
and will convert both model in OpenVINO format.
from ov_wav2lip_helper import download_and_convert_models
OV_FACE_DETECTION_MODEL_PATH = Path("models/face_detection.xml")
OV_WAV2LIP_MODEL_PATH = Path("models/wav2lip.xml")
download_and_convert_models(OV_FACE_DETECTION_MODEL_PATH, OV_WAV2LIP_MODEL_PATH)
Compiling models and prepare pipeline#
Select device from dropdown list for running inference using OpenVINO.
from notebook_utils import device_widget
device = device_widget()
device
Dropdown(description='Device:', index=1, options=('CPU', 'AUTO'), value='AUTO')
ov_inference.py is an adaptation of original pipeline that has only
cli-interface. ov_inference allows running the inference using
python API and converted OpenVINO models.
import os
from ov_inference import ov_inference
if not os.path.exists("results"):
os.mkdir("results")
ov_inference(
"data_video_sun_5s.mp4",
"data_audio_sun_5s.wav",
face_detection_path=OV_FACE_DETECTION_MODEL_PATH,
wav2lip_path=OV_WAV2LIP_MODEL_PATH,
inference_device=device.value,
outfile="results/result_voice.mp4",
)
Here is an example to compare the original video and the generated video after the Wav2Lip pipeline:
from IPython.display import Video, Audio
Video("data_video_sun_5s.mp4", embed=True)
Audio("data_audio_sun_5s.wav")
The generated video:
Video("results/result_voice.mp4", embed=True)
Interactive inference#
from gradio_helper import make_demo
demo = make_demo(fn=ov_inference)
try:
demo.queue().launch(debug=True)
except Exception:
demo.queue().launch(debug=True, share=True)
# if you are launching remotely, specify server_name and server_port
# demo.launch(server_name='your server name', server_port='server port in int')
# Read more in the docs: https://gradio.app/docs/"