Text-to-speech (TTS) with Parler-TTS and OpenVINO#
This Jupyter notebook can be launched after a local installation only.

Parler-TTS is a lightweight text-to-speech (TTS) model that can generate high-quality, natural sounding speech in the style of a given speaker (gender, pitch, speaking style, etc). It is a reproduction of work from the paper Natural language guidance of high-fidelity text-to-speech with synthetic annotations by Dan Lyth and Simon King, from Stability AI and Edinburgh University respectively.
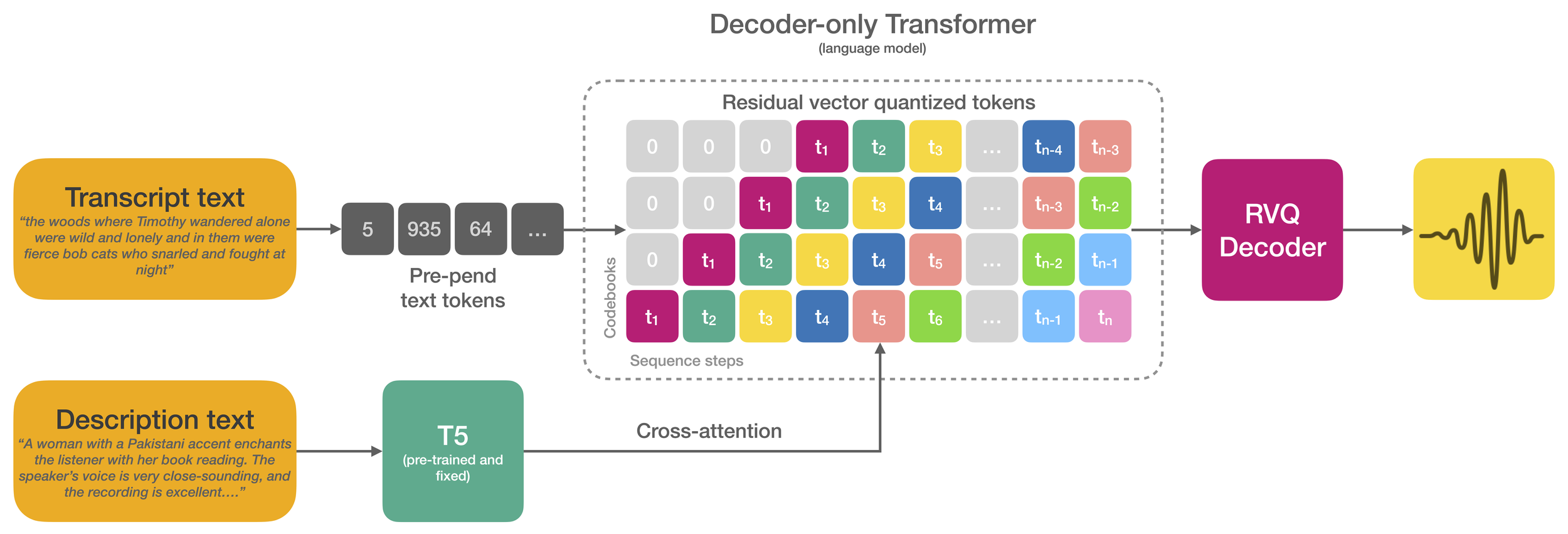
Text-to-speech models trained on large-scale datasets have demonstrated impressive in-context learning capabilities and naturalness. However, control of speaker identity and style in these models typically requires conditioning on reference speech recordings, limiting creative applications. Alternatively, natural language prompting of speaker identity and style has demonstrated promising results and provides an intuitive method of control. However, reliance on human-labeled descriptions prevents scaling to large datasets.
This work bridges the gap between these two approaches. The authors propose a scalable method for labeling various aspects of speaker identity, style, and recording conditions. This method then is applied to a 45k hour dataset, which is used to train a speech language model. Furthermore, the authors propose simple methods for increasing audio fidelity, significantly outperforming recent work despite relying entirely on found data.
Table of contents:
This is a self-contained example that relies solely on its own code.
We recommend running the notebook in a virtual environment. You only need a Jupyter server to start. For details, please refer to Installation Guide.
Prerequisites#
import os
os.environ["GIT_CLONE_PROTECTION_ACTIVE"] = "false"
%pip uninstall -q -y torch torchvision torchaudio
%pip install -q "openvino>=2024.2.0"
%pip install -q git+https://github.com/huggingface/parler-tts.git "gradio>=4.19" transformers "torch>=2.2" "torchaudio" --extra-index-url https://download.pytorch.org/whl/cpu
Load the original model and inference#
import torch
from parler_tts import ParlerTTSForConditionalGeneration
from transformers import AutoTokenizer
import soundfile as sf
device = "cpu"
repo_id = "parler-tts/parler_tts_mini_v0.1"
model = ParlerTTSForConditionalGeneration.from_pretrained(repo_id).to(device)
tokenizer = AutoTokenizer.from_pretrained(repo_id)
prompt = "Hey, how are you doing today?"
description = "A female speaker with a slightly low-pitched voice delivers her words quite expressively, in a very confined sounding environment with clear audio quality. She speaks very fast."
input_ids = tokenizer(description, return_tensors="pt").input_ids.to(device)
prompt_input_ids = tokenizer(prompt, return_tensors="pt").input_ids.to(device)
generation = model.generate(input_ids=input_ids, prompt_input_ids=prompt_input_ids)
audio_arr = generation.cpu().numpy().squeeze()
sf.write("parler_tts_out.wav", audio_arr, model.config.sampling_rate)
import IPython.display as ipd
ipd.Audio("parler_tts_out.wav")
Convert the model to OpenVINO IR#
Let’s define the conversion function for PyTorch modules. We use
ov.convert_model function to obtain OpenVINO Intermediate
Representation object and ov.save_model function to save it as XML
file.
import openvino as ov
from pathlib import Path
def convert(model: torch.nn.Module, xml_path: str, example_input):
xml_path = Path(xml_path)
if not xml_path.exists():
xml_path.parent.mkdir(parents=True, exist_ok=True)
with torch.no_grad():
converted_model = ov.convert_model(model, example_input=example_input)
ov.save_model(converted_model, xml_path)
# cleanup memory
torch._C._jit_clear_class_registry()
torch.jit._recursive.concrete_type_store = torch.jit._recursive.ConcreteTypeStore()
torch.jit._state._clear_class_state()
In the pipeline two models are used: Text Encoder (T5EncoderModel)
and Decoder (ParlerTTSDecoder). Lets convert them one by one.
TEXT_ENCODER_OV_PATH = Path("models/text_encoder_ir.xml")
example_input = {
"input_ids": torch.ones((1, 39), dtype=torch.int64),
}
text_encoder_ov_model = convert(model.text_encoder, TEXT_ENCODER_OV_PATH, example_input)
The Decoder Model performs in generation pipeline and we can separate it
into two stage. In the first stage the model generates
past_key_values into output for the second stage. In the second
stage the model produces tokens during several runs.
DECODER_STAGE_1_OV_PATH = Path("models/decoder_stage_1_ir.xml")
class DecoderStage1Wrapper(torch.nn.Module):
def __init__(self, decoder):
super().__init__()
self.decoder = decoder
def forward(self, input_ids=None, encoder_hidden_states=None, encoder_attention_mask=None, prompt_hidden_states=None):
return self.decoder(
input_ids=input_ids,
return_dict=False,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
prompt_hidden_states=prompt_hidden_states,
)
example_input = {
"input_ids": torch.ones((9, 1), dtype=torch.int64),
"encoder_hidden_states": torch.ones((1, 39, 1024), dtype=torch.float32),
"encoder_attention_mask": torch.ones((1, 39), dtype=torch.int64),
"prompt_hidden_states": torch.ones((1, 9, 1024), dtype=torch.float32),
}
decoder_1_ov_model = convert(DecoderStage1Wrapper(model.decoder.model.decoder), DECODER_STAGE_1_OV_PATH, example_input)
DECODER_STAGE_2_OV_PATH = Path("models/decoder_stage_2_ir.xml")
class DecoderStage2Wrapper(torch.nn.Module):
def __init__(self, decoder):
super().__init__()
self.decoder = decoder
def forward(self, input_ids=None, encoder_hidden_states=None, encoder_attention_mask=None, past_key_values=None):
past_key_values = tuple(tuple(past_key_values[i : i + 4]) for i in range(0, len(past_key_values), 4))
return self.decoder(
input_ids=input_ids,
return_dict=False,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
past_key_values=past_key_values,
)
example_input = {
"input_ids": torch.ones((9, 1), dtype=torch.int64),
"encoder_hidden_states": torch.ones((1, 39, 1024), dtype=torch.float32),
"encoder_attention_mask": torch.ones((1, 39), dtype=torch.int64),
"past_key_values": (
(
torch.ones(1, 16, 10, 64, dtype=torch.float32),
torch.ones(1, 16, 10, 64, dtype=torch.float32),
torch.ones(1, 16, 39, 64, dtype=torch.float32),
torch.ones(1, 16, 39, 64, dtype=torch.float32),
)
* 24
),
}
decoder_2_ov_model = convert(DecoderStage2Wrapper(model.decoder.model.decoder), DECODER_STAGE_2_OV_PATH, example_input)
Compiling models and inference#
Select device from dropdown list for running inference using OpenVINO.
import requests
if not Path("notebook_utils.py").exists():
r = requests.get(
url="https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/utils/notebook_utils.py",
)
open("notebook_utils.py", "w").write(r.text)
from notebook_utils import device_widget
device = device_widget()
device
# Read more about telemetry collection at https://github.com/openvinotoolkit/openvino_notebooks?tab=readme-ov-file#-telemetry
from notebook_utils import collect_telemetry
collect_telemetry("parler-tts-text-to-speech.ipynb")
Dropdown(description='Device:', index=4, options=('CPU', 'GPU.0', 'GPU.1', 'GPU.2', 'AUTO'), value='AUTO')
Let’s create callable wrapper classes for compiled models to allow
interaction with original pipeline. Note that all of wrapper classes
return torch.Tensors instead of np.arrays. In the
DecoderWrapper we separates the pipeline into two stages.
from collections import namedtuple
import torch.nn as nn
EncoderOutput = namedtuple("EncoderOutput", "last_hidden_state")
DecoderOutput = namedtuple("DecoderOutput", ("last_hidden_state", "past_key_values", "hidden_states", "attentions", "cross_attentions"))
core = ov.Core()
class TextEncoderModelWrapper(torch.nn.Module):
def __init__(self, encoder_ir_path, config):
ov_config = {}
if "GPU" in device.value:
ov_config = {"INFERENCE_PRECISION_HINT": "f32"}
self.encoder = core.compile_model(encoder_ir_path, device.value, ov_config)
self.config = config
self.dtype = self.config.torch_dtype
def __call__(self, input_ids, **_):
last_hidden_state = self.encoder(input_ids)[0]
return EncoderOutput(torch.from_numpy(last_hidden_state))
class DecoderWrapper(torch.nn.Module):
def __init__(self, decoder_stage_1_ir_path, decoder_stage_2_ir_path, config):
super().__init__()
self.decoder_stage_1 = core.compile_model(decoder_stage_1_ir_path, device.value)
self.decoder_stage_2 = core.compile_model(decoder_stage_2_ir_path, device.value)
self.config = config
self.embed_tokens = None
embed_dim = config.vocab_size + 1 # + 1 for pad token id
self.embed_tokens = nn.ModuleList([nn.Embedding(embed_dim, config.hidden_size) for _ in range(config.num_codebooks)])
def __call__(self, input_ids=None, encoder_hidden_states=None, encoder_attention_mask=None, past_key_values=None, prompt_hidden_states=None, **kwargs):
inputs = {}
if input_ids is not None:
inputs["input_ids"] = input_ids
if encoder_hidden_states is not None:
inputs["encoder_hidden_states"] = encoder_hidden_states
if encoder_attention_mask is not None:
inputs["encoder_attention_mask"] = encoder_attention_mask
if prompt_hidden_states is not None:
inputs["prompt_hidden_states"] = prompt_hidden_states
if past_key_values is not None:
past_key_values = tuple(past_key_value for pkv_per_layer in past_key_values for past_key_value in pkv_per_layer)
inputs["past_key_values"] = past_key_values
arguments = (
input_ids,
encoder_hidden_states,
encoder_attention_mask,
*past_key_values,
)
outs = self.decoder_stage_2(arguments)
else:
outs = self.decoder_stage_1(inputs)
outs = [torch.from_numpy(out) for out in outs.values()]
past_key_values = list(list(outs[i : i + 4]) for i in range(1, len(outs), 4))
return DecoderOutput(outs[0], past_key_values, None, None, None)
Now we can replace the original models by our wrapped OpenVINO models and run inference.
model.text_encoder = TextEncoderModelWrapper(TEXT_ENCODER_OV_PATH, model.text_encoder.config)
model.decoder.model.decoder = DecoderWrapper(DECODER_STAGE_1_OV_PATH, DECODER_STAGE_2_OV_PATH, model.decoder.model.decoder.config)
model._supports_cache_class = False
model._supports_static_cache = False
generation = model.generate(input_ids=input_ids, prompt_input_ids=prompt_input_ids)
audio_arr = generation.cpu().numpy().squeeze()
sf.write("parler_tts_out.wav", audio_arr, model.config.sampling_rate)
import IPython.display as ipd
ipd.Audio("parler_tts_out.wav")
Interactive inference#
from transformers import AutoFeatureExtractor, set_seed
feature_extractor = AutoFeatureExtractor.from_pretrained(repo_id)
SAMPLE_RATE = feature_extractor.sampling_rate
def infer(prompt, description, seed):
set_seed(seed)
input_ids = tokenizer(description, return_tensors="pt").input_ids.to("cpu")
prompt_input_ids = tokenizer(prompt, return_tensors="pt").input_ids.to("cpu")
generation = model.generate(input_ids=input_ids, prompt_input_ids=prompt_input_ids)
audio_arr = generation.cpu().numpy().squeeze()
sr = SAMPLE_RATE
return sr, audio_arr
if not Path("gradio_helper.py").exists():
r = requests.get(url="https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/notebooks/parler-tts-text-to-speech/gradio_helper.py")
open("gradio_helper.py", "w").write(r.text)
from gradio_helper import make_demo
demo = make_demo(fn=infer)
try:
demo.queue().launch(debug=True)
except Exception:
demo.queue().launch(share=True, debug=True)
# if you are launching remotely, specify server_name and server_port
# demo.launch(server_name='your server name', server_port='server port in int')
# Read more in the docs: https://gradio.app/docs/
# please uncomment and run this cell for stopping gradio interface
# demo.close()