Grammatical Error Correction with OpenVINO#
This Jupyter notebook can be launched after a local installation only.

AI-based auto-correction products are becoming increasingly popular due to their ease of use, editing speed, and affordability. These products improve the quality of written text in emails, blogs, and chats.
Grammatical Error Correction (GEC) is the task of correcting different types of errors in text such as spelling, punctuation, grammatical and word choice errors. GEC is typically formulated as a sentence correction task. A GEC system takes a potentially erroneous sentence as input and is expected to transform it into a more correct version. See the example given below:
Input (Erroneous) |
Output (Corrected) |
|---|---|
I like to rides my bicycle. |
I like to ride my bicycle. |
As shown in the image below, different types of errors in written language can be corrected.
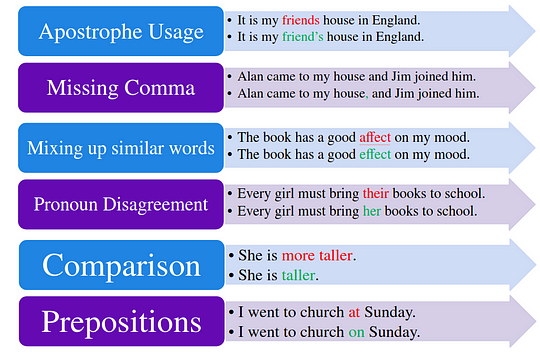
error_types#
This tutorial shows how to perform grammatical error correction using OpenVINO. We will use pre-trained models from the Hugging Face Transformers library. To simplify the user experience, the Hugging Face Optimum library is used to convert the models to OpenVINO™ IR format.
It consists of the following steps:
Install prerequisites
Download and convert models from a public source using the OpenVINO integration with Hugging Face Optimum.
Create an inference pipeline for grammatical error checking
Optimize grammar correction pipeline with NNCF quantization
Compare original and optimized pipelines from performance and accuracy standpoints
Table of contents:
Installation Instructions#
This is a self-contained example that relies solely on its own code.
We recommend running the notebook in a virtual environment. You only need a Jupyter server to start. For details, please refer to Installation Guide.
How does it work?#
A Grammatical Error Correction task can be thought of as a sequence-to-sequence task where a model is trained to take a grammatically incorrect sentence as input and return a grammatically correct sentence as output. We will use the FLAN-T5 model finetuned on an expanded version of the JFLEG dataset.
The version of FLAN-T5 released with the Scaling Instruction-Finetuned Language Models paper is an enhanced version of T5 that has been finetuned on a combination of tasks. The paper explores instruction finetuning with a particular focus on scaling the number of tasks, scaling the model size, and finetuning on chain-of-thought data. The paper discovers that overall instruction finetuning is a general method that improves the performance and usability of pre-trained language models.

flan-t5_training#
For more details about the model, please check out paper, original repository, and Hugging Face model card
Additionally, to reduce the number of sentences required to be processed, you can perform grammatical correctness checking. This task should be considered as a simple binary text classification, where the model gets input text and predicts label 1 if a text contains any grammatical errors and 0 if it does not. You will use the roberta-base-CoLA model, the RoBERTa Base model finetuned on the CoLA dataset. The RoBERTa model was proposed in RoBERTa: A Robustly Optimized BERT Pretraining Approach paper. It builds on BERT and modifies key hyperparameters, removing the next-sentence pre-training objective and training with much larger mini-batches and learning rates. Additional details about the model can be found in a blog post by Meta AI and in the Hugging Face documentation
Now that we know more about FLAN-T5 and RoBERTa, let us get started. 🚀
Prerequisites#
First, we need to install the Hugging Face Optimum library accelerated by OpenVINO integration. The Hugging Face Optimum API is a high-level API that enables us to convert and quantize models from the Hugging Face Transformers library to the OpenVINO™ IR format. For more details, refer to the Hugging Face Optimum documentation.
import platform
%pip install -q "torch>=2.1.0" "git+https://github.com/huggingface/optimum-intel.git" "openvino>=2024.0.0" "onnx<1.16.2" tqdm "gradio>=4.19" "transformers>=4.33.0" --extra-index-url https://download.pytorch.org/whl/cpu
%pip install -q "nncf>=2.9.0" datasets jiwer
if platform.system() == "Darwin":
%pip install -q "numpy<2.0.0"
Download and Convert Models#
Optimum Intel can be used to load optimized models from the Hugging
Face Hub and
create pipelines to run an inference with OpenVINO Runtime using Hugging
Face APIs. The Optimum Inference models are API compatible with Hugging
Face Transformers models. This means we just need to replace
AutoModelForXxx class with the corresponding OVModelForXxx
class.
Below is an example of the RoBERTa text classification model
-from transformers import AutoModelForSequenceClassification
+from optimum.intel.openvino import OVModelForSequenceClassification
from transformers import AutoTokenizer, pipeline
model_id = "textattack/roberta-base-CoLA"
-model = AutoModelForSequenceClassification.from_pretrained(model_id)
+model = OVModelForSequenceClassification.from_pretrained(model_id, from_transformers=True)
Model class initialization starts with calling from_pretrained
method. When downloading and converting Transformers model, the
parameter from_transformers=True should be added. We can save the
converted model for the next usage with the save_pretrained method.
Tokenizer class and pipelines API are compatible with Optimum models.
from transformers import pipeline, AutoTokenizer
from optimum.intel.openvino import OVModelForSeq2SeqLM, OVModelForSequenceClassification
import requests
from pathlib import Path
if not Path("notebook_utils.py").exists():
r = requests.get(
url="https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/utils/notebook_utils.py",
)
open("notebook_utils.py", "w").write(r.text)
# Read more about telemetry collection at https://github.com/openvinotoolkit/openvino_notebooks?tab=readme-ov-file#-telemetry
from notebook_utils import collect_telemetry
collect_telemetry("grammar-correction.ipynb")
2024-03-25 11:56:04.043628: I tensorflow/core/util/port.cc:111] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable TF_ENABLE_ONEDNN_OPTS=0. 2024-03-25 11:56:04.045940: I tensorflow/tsl/cuda/cudart_stub.cc:28] Could not find cuda drivers on your machine, GPU will not be used. 2024-03-25 11:56:04.079112: E tensorflow/compiler/xla/stream_executor/cuda/cuda_dnn.cc:9342] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered 2024-03-25 11:56:04.079147: E tensorflow/compiler/xla/stream_executor/cuda/cuda_fft.cc:609] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered 2024-03-25 11:56:04.079167: E tensorflow/compiler/xla/stream_executor/cuda/cuda_blas.cc:1518] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered 2024-03-25 11:56:04.085243: I tensorflow/tsl/cuda/cudart_stub.cc:28] Could not find cuda drivers on your machine, GPU will not be used. 2024-03-25 11:56:04.085971: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations. To enable the following instructions: AVX2 AVX512F AVX512_VNNI FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags. 2024-03-25 11:56:05.314633: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
INFO:nncf:NNCF initialized successfully. Supported frameworks detected: torch, tensorflow, onnx, openvino
Select inference device#
select device from dropdown list for running inference using OpenVINO
from notebook_utils import device_widget
device = device_widget(default="CPU", exclude=["AUTO", "GPU"])
device
Dropdown(description='Device:', index=3, options=('CPU', 'GPU.0', 'GPU.1', 'AUTO'), value='AUTO')
Grammar Checker#
grammar_checker_model_id = "textattack/roberta-base-CoLA"
grammar_checker_dir = Path("roberta-base-cola")
grammar_checker_tokenizer = AutoTokenizer.from_pretrained(grammar_checker_model_id)
if grammar_checker_dir.exists():
grammar_checker_model = OVModelForSequenceClassification.from_pretrained(grammar_checker_dir, device=device.value)
else:
grammar_checker_model = OVModelForSequenceClassification.from_pretrained(grammar_checker_model_id, export=True, device=device.value, load_in_8bit=False)
grammar_checker_model.save_pretrained(grammar_checker_dir)
Framework not specified. Using pt to export the model.
Some weights of the model checkpoint at textattack/roberta-base-CoLA were not used when initializing RobertaForSequenceClassification: ['roberta.pooler.dense.bias', 'roberta.pooler.dense.weight']
- This IS expected if you are initializing RobertaForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing RobertaForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Using the export variant default. Available variants are:
- default: The default ONNX variant.
Using framework PyTorch: 2.2.1+cpu
Overriding 1 configuration item(s)
- use_cache -> False
/home/ea/miniconda3/lib/python3.11/site-packages/transformers/modeling_utils.py:4225: FutureWarning: _is_quantized_training_enabled is going to be deprecated in transformers 4.39.0. Please use model.hf_quantizer.is_trainable instead
warnings.warn(
Compiling the model to AUTO ...
Let us check model work, using inference pipeline for
text-classification task. You can find more information about usage
Hugging Face inference pipelines in this
tutorial
import torch
input_text = "They are moved by salar energy"
grammar_checker_pipe = pipeline("text-classification", model=grammar_checker_model, tokenizer=grammar_checker_tokenizer, device=torch.device("cpu"))
result = grammar_checker_pipe(input_text)[0]
print(f"input text: {input_text}")
print(f'predicted label: {"contains_errors" if result["label"] == "LABEL_1" else "no errors"}')
print(f'predicted score: {result["score"] :.2}')
input text: They are moved by salar energy
predicted label: contains_errors
predicted score: 0.88
Great! Looks like the model can detect errors in the sample.
Grammar Corrector#
The steps for loading the Grammar Corrector model are very similar,
except for the model class that is used. Because FLAN-T5 is a
sequence-to-sequence text generation model, we should use the
OVModelForSeq2SeqLM class and the text2text-generation pipeline
to run it.
grammar_corrector_model_id = "pszemraj/flan-t5-large-grammar-synthesis"
grammar_corrector_dir = Path("flan-t5-large-grammar-synthesis")
grammar_corrector_tokenizer = AutoTokenizer.from_pretrained(grammar_corrector_model_id)
if grammar_corrector_dir.exists():
grammar_corrector_model = OVModelForSeq2SeqLM.from_pretrained(grammar_corrector_dir, device=device.value)
else:
grammar_corrector_model = OVModelForSeq2SeqLM.from_pretrained(grammar_corrector_model_id, export=True, device=device.value)
grammar_corrector_model.save_pretrained(grammar_corrector_dir)
Framework not specified. Using pt to export the model.
Using the export variant default. Available variants are:
- default: The default ONNX variant.
Some non-default generation parameters are set in the model config. These should go into a GenerationConfig file (https://huggingface.co/docs/transformers/generation_strategies#save-a-custom-decoding-strategy-with-your-model) instead. This warning will be raised to an exception in v4.41.
Non-default generation parameters: {'max_length': 512, 'min_length': 8, 'num_beams': 2, 'no_repeat_ngram_size': 4}
Using framework PyTorch: 2.2.1+cpu
Overriding 1 configuration item(s)
- use_cache -> False
/home/ea/miniconda3/lib/python3.11/site-packages/transformers/modeling_utils.py:4225: FutureWarning: _is_quantized_training_enabled is going to be deprecated in transformers 4.39.0. Please use model.hf_quantizer.is_trainable instead
warnings.warn(
Using framework PyTorch: 2.2.1+cpu
Overriding 1 configuration item(s)
- use_cache -> True
/home/ea/miniconda3/lib/python3.11/site-packages/transformers/modeling_utils.py:943: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
if causal_mask.shape[1] < attention_mask.shape[1]:
Using framework PyTorch: 2.2.1+cpu
Overriding 1 configuration item(s)
- use_cache -> True
/home/ea/miniconda3/lib/python3.11/site-packages/transformers/models/t5/modeling_t5.py:509: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
elif past_key_value.shape[2] != key_value_states.shape[1]:
Some non-default generation parameters are set in the model config. These should go into a GenerationConfig file (https://huggingface.co/docs/transformers/generation_strategies#save-a-custom-decoding-strategy-with-your-model) instead. This warning will be raised to an exception in v4.41.
Non-default generation parameters: {'max_length': 512, 'min_length': 8, 'num_beams': 2, 'no_repeat_ngram_size': 4}
Compiling the encoder to AUTO ...
Compiling the decoder to AUTO ...
Compiling the decoder to AUTO ...
Some non-default generation parameters are set in the model config. These should go into a GenerationConfig file (https://huggingface.co/docs/transformers/generation_strategies#save-a-custom-decoding-strategy-with-your-model) instead. This warning will be raised to an exception in v4.41.
Non-default generation parameters: {'max_length': 512, 'min_length': 8, 'num_beams': 2, 'no_repeat_ngram_size': 4}
grammar_corrector_pipe = pipeline("text2text-generation", model=grammar_corrector_model, tokenizer=grammar_corrector_tokenizer, device=torch.device("cpu"))
result = grammar_corrector_pipe(input_text)[0]
print(f"input text: {input_text}")
print(f'generated text: {result["generated_text"]}')
input text: They are moved by salar energy
generated text: They are powered by solar energy.
Nice! The result looks pretty good!
Prepare Demo Pipeline#
Now let us put everything together and create the pipeline for grammar correction. The pipeline accepts input text, verifies its correctness, and generates the correct version if required. It will consist of several steps:
Split text on sentences.
Check grammatical correctness for each sentence using Grammar Checker.
Generate an improved version of the sentence if required.
import re
import transformers
from tqdm.notebook import tqdm
def split_text(text: str) -> list:
"""
Split a string of text into a list of sentence batches.
Parameters:
text (str): The text to be split into sentence batches.
Returns:
list: A list of sentence batches. Each sentence batch is a list of sentences.
"""
# Split the text into sentences using regex
sentences = re.split(r"(?<=[^A-Z].[.?]) +(?=[A-Z])", text)
# Initialize a list to store the sentence batches
sentence_batches = []
# Initialize a temporary list to store the current batch of sentences
temp_batch = []
# Iterate through the sentences
for sentence in sentences:
# Add the sentence to the temporary batch
temp_batch.append(sentence)
# If the length of the temporary batch is between 2 and 3 sentences, or if it is the last batch, add it to the list of sentence batches
if len(temp_batch) >= 2 and len(temp_batch) <= 3 or sentence == sentences[-1]:
sentence_batches.append(temp_batch)
temp_batch = []
return sentence_batches
def correct_text(
text: str,
checker: transformers.pipelines.Pipeline,
corrector: transformers.pipelines.Pipeline,
separator: str = " ",
) -> str:
"""
Correct the grammar in a string of text using a text-classification and text-generation pipeline.
Parameters:
text (str): The inpur text to be corrected.
checker (transformers.pipelines.Pipeline): The text-classification pipeline to use for checking the grammar quality of the text.
corrector (transformers.pipelines.Pipeline): The text-generation pipeline to use for correcting the text.
separator (str, optional): The separator to use when joining the corrected text into a single string. Default is a space character.
Returns:
str: The corrected text.
"""
# Split the text into sentence batches
sentence_batches = split_text(text)
# Initialize a list to store the corrected text
corrected_text = []
# Iterate through the sentence batches
for batch in tqdm(sentence_batches, total=len(sentence_batches), desc="correcting text.."):
# Join the sentences in the batch into a single string
raw_text = " ".join(batch)
# Check the grammar quality of the text using the text-classification pipeline
results = checker(raw_text)
# Only correct the text if the results of the text-classification are not LABEL_1 or are LABEL_1 with a score below 0.9
if results[0]["label"] != "LABEL_1" or (results[0]["label"] == "LABEL_1" and results[0]["score"] < 0.9):
# Correct the text using the text-generation pipeline
corrected_batch = corrector(raw_text)
corrected_text.append(corrected_batch[0]["generated_text"])
else:
corrected_text.append(raw_text)
# Join the corrected text into a single string
corrected_text = separator.join(corrected_text)
return corrected_text
Let us see it in action.
default_text = (
"Most of the course is about semantic or content of language but there are also interesting"
" topics to be learned from the servicefeatures except statistics in characters in documents.At"
" this point, He introduces herself as his native English speaker and goes on to say that if"
" you contine to work on social scnce"
)
corrected_text = correct_text(default_text, grammar_checker_pipe, grammar_corrector_pipe)
correcting text..: 0%| | 0/1 [00:00<?, ?it/s]
print(f"input text: {default_text}\n")
print(f"generated text: {corrected_text}")
input text: Most of the course is about semantic or content of language but there are also interesting topics to be learned from the servicefeatures except statistics in characters in documents.At this point, He introduces herself as his native English speaker and goes on to say that if you contine to work on social scnce
generated text: Most of the course is about the semantic content of language but there are also interesting topics to be learned from the service features except statistics in characters in documents. At this point, she introduces herself as a native English speaker and goes on to say that if you continue to work on social science, you will continue to be successful.
Quantization#
NNCF enables
post-training quantization by adding quantization layers into model
graph and then using a subset of the training dataset to initialize the
parameters of these additional quantization layers. Quantized operations
are executed in INT8 instead of FP32/FP16 making model
inference faster.
Grammar checker model takes up a tiny portion of the whole text correction pipeline so we optimize only the grammar corrector model. Grammar corrector itself consists of three models: encoder, first call decoder and decoder with past. The last model’s share of inference dominates the other ones. Because of this we quantize only it.
The optimization process contains the following steps:
Create a calibration dataset for quantization.
Run
nncf.quantize()to obtain quantized models.Serialize the
INT8model usingopenvino.save_model()function.
Please select below whether you would like to run quantization to improve model inference speed.
from notebook_utils import quantization_widget
to_quantize = quantization_widget()
to_quantize
Checkbox(value=True, description='Quantization')
Run Quantization#
Below we retrieve the quantized model. Please see utils.py for
source code. Quantization is relatively time-consuming and will take
some time to complete.
from utils import get_quantized_pipeline, CALIBRATION_DATASET_SIZE
import openvino as ov
grammar_corrector_pipe_fp32 = grammar_corrector_pipe
grammar_corrector_pipe_int8 = None
if to_quantize.value:
quantized_model_path = Path("quantized_decodet") / "openvino_model.xml"
grammar_corrector_pipe_int8 = get_quantized_pipeline(
grammar_corrector_pipe_fp32,
grammar_corrector_tokenizer,
ov.Core(),
grammar_corrector_dir,
quantized_model_path,
device.value,
calibration_dataset_size=CALIBRATION_DATASET_SIZE,
)
Downloading readme: 0%| | 0.00/5.94k [00:00<?, ?B/s]
Downloading data: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 148k/148k [00:01<00:00, 79.1kB/s]
Downloading data: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 141k/141k [00:01<00:00, 131kB/s]
Generating validation split: 0%| | 0/755 [00:00<?, ? examples/s]
Generating test split: 0%| | 0/748 [00:00<?, ? examples/s]
Collecting calibration data: 0%| | 0/10 [00:00<?, ?it/s]
Output()
Output()
INFO:nncf:72 ignored nodes were found by name in the NNCFGraph
INFO:nncf:145 ignored nodes were found by name in the NNCFGraph
Output()
Compiling the encoder to AUTO ...
Compiling the decoder to AUTO ...
Compiling the decoder to AUTO ...
Compiling the decoder to AUTO ...
Let’s see correction results. The generated texts for quantized INT8 model and original FP32 model should be almost the same.
if to_quantize.value:
corrected_text_int8 = correct_text(default_text, grammar_checker_pipe, grammar_corrector_pipe_int8)
print(f"Input text: {default_text}\n")
print(f"Generated text by INT8 model: {corrected_text_int8}")
correcting text..: 0%| | 0/1 [00:00<?, ?it/s]
Input text: Most of the course is about semantic or content of language but there are also interesting topics to be learned from the servicefeatures except statistics in characters in documents.At this point, He introduces herself as his native English speaker and goes on to say that if you contine to work on social scnce
Generated text by INT8 model: Most of the course is about semantics or content of language but there are also interesting topics to be learned from the service features except statistics in characters in documents. At this point, she introduces himself as a native English speaker and goes on to say that if you continue to work on social science, you will continue to do so.
Compare model size, performance and accuracy#
First, we compare file size of FP32 and INT8 models.
from utils import calculate_compression_rate
if to_quantize.value:
model_size_fp32, model_size_int8 = calculate_compression_rate(
grammar_corrector_dir / "openvino_decoder_model.xml",
quantized_model_path,
)
Model footprint comparison:
* FP32 IR model size: 1658150.25 KB
* INT8 IR model size: 415711.39 KB
Second, we compare two grammar correction pipelines from performance and accuracy stand points.
Test split of jflegdataset is used for testing. One dataset sample consists of a text with
errors as input and several corrected versions as labels. When measuring
accuracy we use mean (1 - WER) against corrected text versions,
where WER is Word Error Rate metric.
from utils import calculate_inference_time_and_accuracy
TEST_SUBSET_SIZE = 50
if to_quantize.value:
inference_time_fp32, accuracy_fp32 = calculate_inference_time_and_accuracy(grammar_corrector_pipe_fp32, TEST_SUBSET_SIZE)
print(f"Evaluation results of FP32 grammar correction pipeline. Accuracy: {accuracy_fp32:.2f}%. Time: {inference_time_fp32:.2f} sec.")
inference_time_int8, accuracy_int8 = calculate_inference_time_and_accuracy(grammar_corrector_pipe_int8, TEST_SUBSET_SIZE)
print(f"Evaluation results of INT8 grammar correction pipeline. Accuracy: {accuracy_int8:.2f}%. Time: {inference_time_int8:.2f} sec.")
print(f"Performance speedup: {inference_time_fp32 / inference_time_int8:.3f}")
print(f"Accuracy drop :{accuracy_fp32 - accuracy_int8:.2f}%.")
print(f"Model footprint reduction: {model_size_fp32 / model_size_int8:.3f}")
Evaluation: 0%| | 0/50 [00:00<?, ?it/s]
Evaluation results of FP32 grammar correction pipeline. Accuracy: 58.04%. Time: 62.44 sec.
Evaluation: 0%| | 0/50 [00:00<?, ?it/s]
Evaluation results of INT8 grammar correction pipeline. Accuracy: 59.04%. Time: 40.32 sec.
Performance speedup: 1.549
Accuracy drop :-0.99%.
Model footprint reduction: 3.989
Interactive demo#
import gradio as gr
import time
import requests
def correct(text, quantized, progress=gr.Progress(track_tqdm=True)):
grammar_corrector = grammar_corrector_pipe_int8 if quantized else grammar_corrector_pipe
start_time = time.perf_counter()
corrected_text = correct_text(text, grammar_checker_pipe, grammar_corrector)
end_time = time.perf_counter()
return corrected_text, f"{end_time - start_time:.2f}"
if not Path("gradio_helper.py").exists():
r = requests.get(url="https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/notebooks/grammar-correction/gradio_helper.py")
open("gradio_helper.py", "w").write(r.text)
from gradio_helper import make_demo
demo = make_demo(fn=correct, quantized=grammar_corrector_pipe_int8 is not None)
try:
demo.queue().launch(debug=False)
except Exception:
demo.queue().launch(share=True, debug=False)
# if you are launching remotely, specify server_name and server_port
# demo.launch(server_name='your server name', server_port='server port in int')
# Read more in the docs: https://gradio.app/docs/