Style Transfer with OpenVINO™#
This Jupyter notebook can be launched on-line, opening an interactive environment in a browser window. You can also make a local installation. Choose one of the following options:



This notebook demonstrates style transfer with OpenVINO, using the Style Transfer Models from ONNX Model Repository. Specifically, Fast Neural Style Transfer model, which is designed to mix the content of an image with the style of another image.
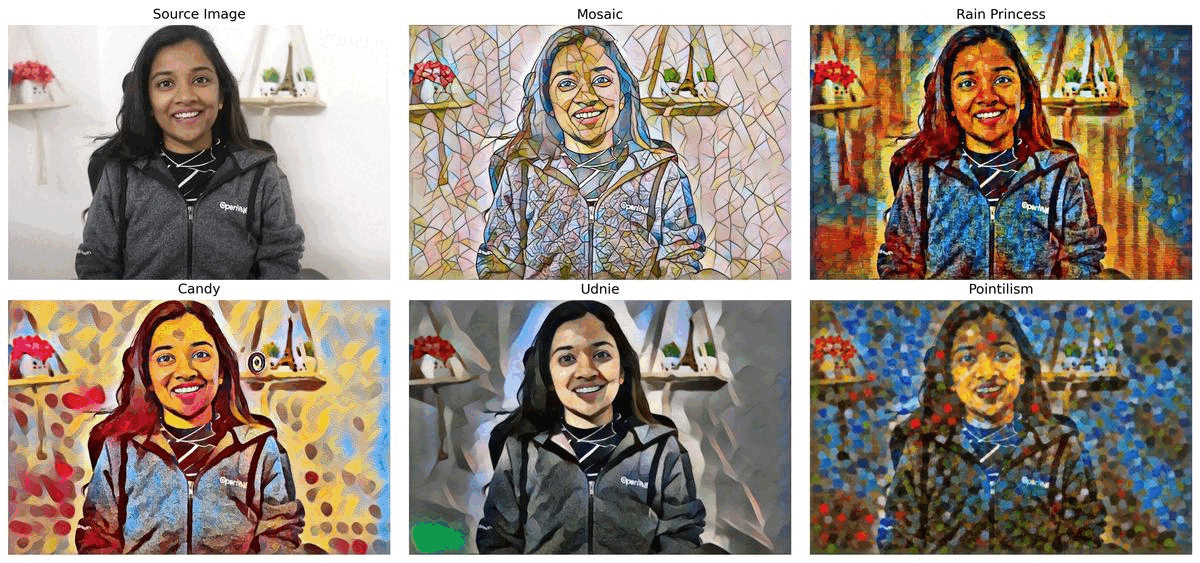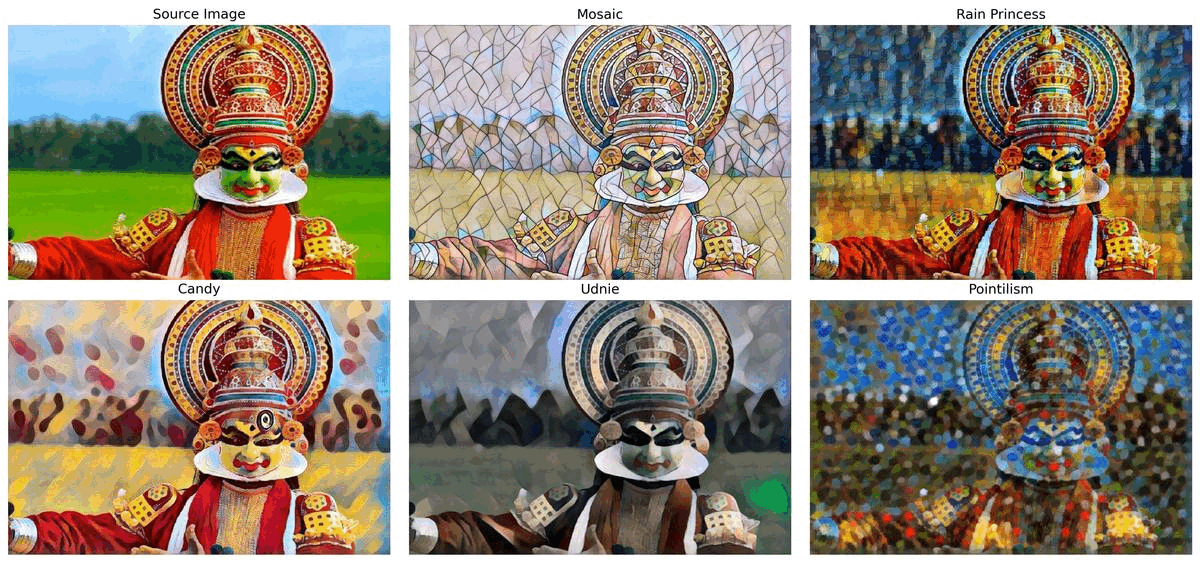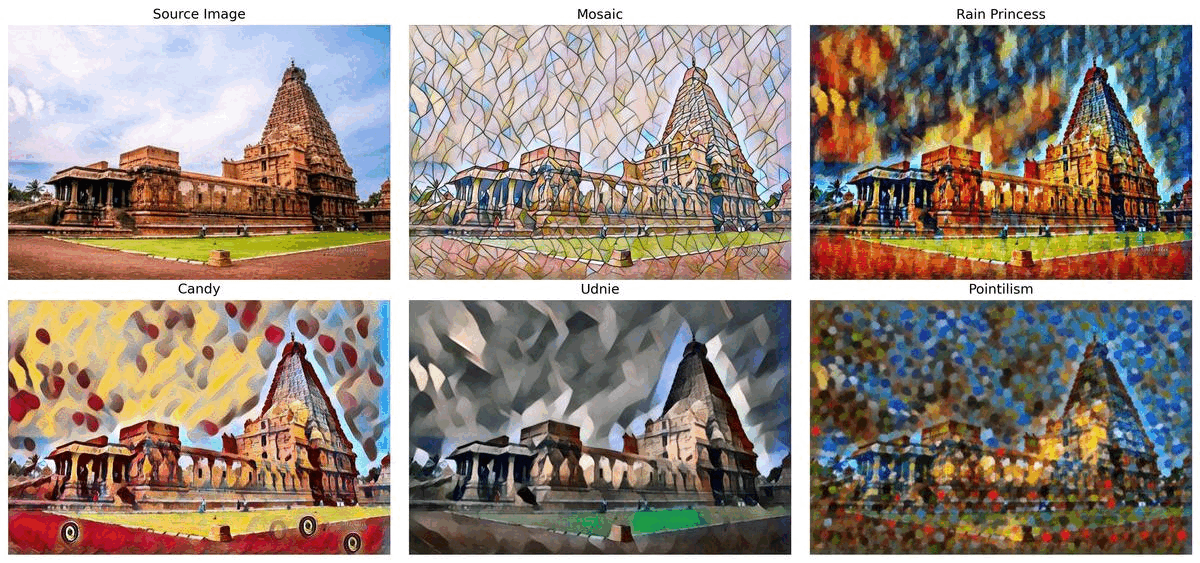
style transfer#
This notebook uses five pre-trained models, for the following styles: Mosaic, Rain Princess, Candy, Udnie and Pointilism. The models are from ONNX Model Repository and are based on the research paper Perceptual Losses for Real-Time Style Transfer and Super-Resolution along with Instance Normalization. Final part of this notebook shows live inference results from a webcam. Additionally, you can also upload a video file.
NOTE: If you have a webcam on your computer, you can see live results streaming in the notebook. If you run the notebook on a server, the webcam will not work but you can run inference, using a video file.
Table of contents:
Installation Instructions#
This is a self-contained example that relies solely on its own code.
We recommend running the notebook in a virtual environment. You only need a Jupyter server to start. For details, please refer to Installation Guide.
Preparation#
Install requirements#
%pip install -q "openvino>=2023.1.0"
%pip install -q opencv-python requests tqdm
from pathlib import Path
# Fetch `notebook_utils` module
import requests
if not Path("notebook_utils.py").exists():
r = requests.get(
url="https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/utils/notebook_utils.py",
)
open("notebook_utils.py", "w").write(r.text)
# Read more about telemetry collection at https://github.com/openvinotoolkit/openvino_notebooks?tab=readme-ov-file#-telemetry
from notebook_utils import collect_telemetry
collect_telemetry("style-transfer.ipynb")
Imports#
import collections
import time
import cv2
import numpy as np
from pathlib import Path
import ipywidgets as widgets
from IPython.display import display, clear_output, Image
import openvino as ov
import notebook_utils as utils
Select one of the styles below: Mosaic, Rain Princess, Candy, Udnie, and Pointilism to do the style transfer.
# Option to select different styles using a dropdown
style_dropdown = widgets.Dropdown(
options=["MOSAIC", "RAIN-PRINCESS", "CANDY", "UDNIE", "POINTILISM"],
value="MOSAIC", # Set the default value
description="Select Style:",
disabled=False,
style={"description_width": "initial"}, # Adjust the width as needed
)
# Function to handle changes in dropdown and print the selected style
def print_style(change):
if change["type"] == "change" and change["name"] == "value":
print(f"Selected style {change['new']}")
# Observe changes in the dropdown value
style_dropdown.observe(print_style, names="value")
# Display the dropdown
display(style_dropdown)
The Model#
Download the Model#
The style transfer model, selected in the previous step, will be
downloaded to model_path if you have not already downloaded it. The
models are provided by the ONNX Model Zoo in .onnx format, which
means it could be used with OpenVINO directly. However, this notebook
will also show how you can use the Conversion API to convert ONNX to
OpenVINO Intermediate Representation (IR) with FP16 precision.
# Directory to download the model from ONNX model zoo
base_model_dir = "model"
base_url = "https://github.com/onnx/models/raw/69d69010b7ed6ba9438c392943d2715026792d40/archive/vision/style_transfer/fast_neural_style/model"
# Selected ONNX model will be downloaded in the path
model_path = Path(f"{style_dropdown.value.lower()}-9.onnx")
ir_path = Path(f"model/{style_dropdown.value.lower()}-9.xml")
onnx_path = Path(f"model/{model_path}")
if not onnx_path.exists():
style_url = f"{base_url}/{model_path}"
utils.download_file(style_url, directory=base_model_dir)
Convert ONNX Model to OpenVINO IR Format#
In the next step, you will convert the ONNX model to OpenVINO IR format
with FP16 precision. While ONNX models are directly supported by
OpenVINO runtime, it can be useful to convert them to IR format to take
advantage of OpenVINO optimization tools and features. The
ov.convert_model Python function of model conversion API can be
used. The converted model is saved to the model directory. The function
returns instance of OpenVINO Model class, which is ready to use in
Python interface but can also be serialized to OpenVINO IR format for
future execution. If the model has been already converted, you can skip
this step.
if not ir_path.exists():
ov_model = ov.convert_model(onnx_path)
ov.save_model(ov_model, ir_path)
Load the Model#
Both the ONNX model(s) and converted IR model(s) are stored in the
model directory.
Only a few lines of code are required to run the model. First,
initialize OpenVINO Runtime. Then, read the network architecture and
model weights from the .bin and .xml files to compile for the
desired device. If you select GPU you may need to wait briefly for
it to load, as the startup time is somewhat longer than CPU.
To let OpenVINO automatically select the best device for inference just
use AUTO. In most cases, the best device to use is GPU (better
performance, but slightly longer startup time). You can select one from
available devices using dropdown list below.
OpenVINO Runtime can load ONNX models from ONNX Model Repository directly. In such cases, use ONNX path instead of IR model to load the model. It is recommended to load the OpenVINO Intermediate Representation (IR) model for the best results.
# Initialize OpenVINO Runtime.
core = ov.Core()
# Read the network and corresponding weights from ONNX Model.
# model = ie_core.read_model(model=onnx_path)
# Read the network and corresponding weights from IR Model.
model = core.read_model(model=ir_path)
device = utils.device_widget()
# Compile the model for CPU (or change to GPU, etc. for other devices)
# or let OpenVINO select the best available device with AUTO.
device
compiled_model = core.compile_model(model=model, device_name=device.value)
# Get the input and output nodes.
input_layer = compiled_model.input(0)
output_layer = compiled_model.output(0)
Input and output layers have the names of the input node and output node
respectively. For fast-neural-style-mosaic-onnx, there is 1 input and
1 output with the (1, 3, 224, 224) shape.
print(input_layer.any_name, output_layer.any_name)
print(input_layer.shape)
print(output_layer.shape)
# Get the input size.
N, C, H, W = list(input_layer.shape)
Preprocess the image#
Preprocess the input image before running the model. Prepare the dimensions and channel order for the image to match the original image with the input tensor
Preprocess a frame to convert from
unit8tofloat32.Transpose the array to match with the network input size
# Preprocess the input image.
def preprocess_images(frame, H, W):
"""
Preprocess input image to align with network size
Parameters:
:param frame: input frame
:param H: height of the frame to style transfer model
:param W: width of the frame to style transfer model
:returns: resized and transposed frame
"""
image = np.array(frame).astype("float32")
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
image = cv2.resize(src=image, dsize=(H, W), interpolation=cv2.INTER_AREA)
image = np.transpose(image, [2, 0, 1])
image = np.expand_dims(image, axis=0)
return image
Helper function to postprocess the stylized image#
The converted IR model outputs a NumPy float32 array of the (1, 3,
224,
224)
shape .
# Postprocess the result
def convert_result_to_image(frame, stylized_image) -> np.ndarray:
"""
Postprocess stylized image for visualization
Parameters:
:param frame: input frame
:param stylized_image: stylized image with specific style applied
:returns: resized stylized image for visualization
"""
h, w = frame.shape[:2]
stylized_image = stylized_image.squeeze().transpose(1, 2, 0)
stylized_image = cv2.resize(src=stylized_image, dsize=(w, h), interpolation=cv2.INTER_CUBIC)
stylized_image = np.clip(stylized_image, 0, 255).astype(np.uint8)
stylized_image = cv2.cvtColor(stylized_image, cv2.COLOR_BGR2RGB)
return stylized_image
Main Processing Function#
The style transfer function can be run in different operating modes, either using a webcam or a video file.
def run_style_transfer(source=0, flip=False, use_popup=False, skip_first_frames=0):
"""
Main function to run the style inference:
1. Create a video player to play with target fps (utils.VideoPlayer).
2. Prepare a set of frames for style transfer.
3. Run AI inference for style transfer.
4. Visualize the results.
Parameters:
source: The webcam number to feed the video stream with primary webcam set to "0", or the video path.
flip: To be used by VideoPlayer function for flipping capture image.
use_popup: False for showing encoded frames over this notebook, True for creating a popup window.
skip_first_frames: Number of frames to skip at the beginning of the video.
"""
# Create a video player to play with target fps.
player = None
try:
player = utils.VideoPlayer(source=source, flip=flip, fps=30, skip_first_frames=skip_first_frames)
# Start video capturing.
player.start()
if use_popup:
title = "Press ESC to Exit"
cv2.namedWindow(winname=title, flags=cv2.WINDOW_GUI_NORMAL | cv2.WINDOW_AUTOSIZE)
processing_times = collections.deque()
while True:
# Grab the frame.
frame = player.next()
if frame is None:
print("Source ended")
break
# If the frame is larger than full HD, reduce size to improve the performance.
scale = 720 / max(frame.shape)
if scale < 1:
frame = cv2.resize(
src=frame,
dsize=None,
fx=scale,
fy=scale,
interpolation=cv2.INTER_AREA,
)
# Preprocess the input image.
image = preprocess_images(frame, H, W)
# Measure processing time for the input image.
start_time = time.time()
# Perform the inference step.
stylized_image = compiled_model([image])[output_layer]
stop_time = time.time()
# Postprocessing for stylized image.
result_image = convert_result_to_image(frame, stylized_image)
processing_times.append(stop_time - start_time)
# Use processing times from last 200 frames.
if len(processing_times) > 200:
processing_times.popleft()
processing_time_det = np.mean(processing_times) * 1000
# Visualize the results.
f_height, f_width = frame.shape[:2]
fps = 1000 / processing_time_det
cv2.putText(
result_image,
text=f"Inference time: {processing_time_det:.1f}ms ({fps:.1f} FPS)",
org=(20, 40),
fontFace=cv2.FONT_HERSHEY_COMPLEX,
fontScale=f_width / 1000,
color=(0, 0, 255),
thickness=1,
lineType=cv2.LINE_AA,
)
# Use this workaround if there is flickering.
if use_popup:
cv2.imshow(title, result_image)
key = cv2.waitKey(1)
# escape = 27
if key == 27:
break
else:
# Encode numpy array to jpg.
_, encoded_img = cv2.imencode(".jpg", result_image, params=[cv2.IMWRITE_JPEG_QUALITY, 90])
# Create an IPython image.
i = Image(data=encoded_img)
# Display the image in this notebook.
clear_output(wait=True)
display(i)
# ctrl-c
except KeyboardInterrupt:
print("Interrupted")
# any different error
except RuntimeError as e:
print(e)
finally:
if player is not None:
# Stop capturing.
player.stop()
if use_popup:
cv2.destroyAllWindows()
Run Style Transfer#
Now, try to apply the style transfer model using video from your webcam
or video file. By default, the primary webcam is set with source=0.
If you have multiple webcams, each one will be assigned a consecutive
number starting at 0. Set flip=True when using a front-facing
camera. Some web browsers, especially Mozilla Firefox, may cause
flickering. If you experience flickering, set use_popup=True.
NOTE: To use a webcam, you must run this Jupyter notebook on a computer with a webcam. If you run it on a server, you will not be able to access the webcam. However, you can still perform inference on a video file in the final step.
If you do not have a webcam, you can still run this demo with a video file. Any format supported by OpenCV
USE_WEBCAM = False
cam_id = 0
video_file = Path("coco.mp4")
video_url = "https://storage.openvinotoolkit.org/repositories/openvino_notebooks/data/data/video/Coco%20Walking%20in%20Berkeley.mp4"
source = cam_id if USE_WEBCAM else video_file
if not USE_WEBCAM and not video_file.exists():
utils.download_file(video_url, filename="coco.mp4")
run_style_transfer(source=source, flip=isinstance(source, int), use_popup=False)