Convert a TensorFlow Object Detection Model to OpenVINO™#
This Jupyter notebook can be launched on-line, opening an interactive environment in a browser window. You can also make a local installation. Choose one of the following options:



TensorFlow, or TF for short, is an open-source framework for machine learning.
The TensorFlow Object Detection API is an open-source computer vision framework built on top of TensorFlow. It is used for building object detection and image segmentation models that can localize multiple objects in the same image. TensorFlow Object Detection API supports various architectures and models, which can be found and downloaded from the TensorFlow Hub.
This tutorial shows how to convert a TensorFlow Faster R-CNN with Resnet-50 V1 object detection model to OpenVINO Intermediate Representation (OpenVINO IR) format, using Model Converter. After creating the OpenVINO IR, load the model in OpenVINO Runtime and do inference with a sample image.
Table of contents:
Installation Instructions#
This is a self-contained example that relies solely on its own code.
We recommend running the notebook in a virtual environment. You only need a Jupyter server to start. For details, please refer to Installation Guide.
Prerequisites#
Install required packages:
%pip install -q "openvino>=2023.1.0" "numpy>=1.21.0" "opencv-python" "tqdm"
%pip install -q "matplotlib>=3.4"
%pip install -q "tensorflow-macos>=2.5; sys_platform == 'darwin' and platform_machine == 'arm64'" # macOS M1 and M2
%pip install -q "tensorflow>=2.5; sys_platform == 'darwin' and platform_machine != 'arm64'" # macOS x86
%pip install -q "tensorflow>=2.5; sys_platform != 'darwin'"
The notebook uses utility functions. The cell below will download the
notebook_utils Python module from GitHub.
# Fetch the notebook utils script from the openvino_notebooks repo
import requests
r = requests.get(
url="https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/utils/notebook_utils.py",
)
open("notebook_utils.py", "w").write(r.text)
# Read more about telemetry collection at https://github.com/openvinotoolkit/openvino_notebooks?tab=readme-ov-file#-telemetry
from notebook_utils import collect_telemetry
collect_telemetry("tensorflow-object-detection-to-openvino.ipynb")
Imports#
# Standard python modules
from pathlib import Path
# External modules and dependencies
import cv2
import matplotlib.pyplot as plt
import numpy as np
# OpenVINO import
import openvino as ov
# Notebook utils module
from notebook_utils import download_file, device_widget
Settings#
Define model related variables and create corresponding directories:
# Create directories for models files
model_dir = Path("od-model")
model_dir.mkdir(exist_ok=True)
# Create directory for TensorFlow model
tf_model_dir = model_dir / "tf"
tf_model_dir.mkdir(exist_ok=True)
# Create directory for OpenVINO IR model
ir_model_dir = model_dir / "ir"
ir_model_dir.mkdir(exist_ok=True)
model_name = "faster_rcnn_resnet50_v1_640x640"
openvino_ir_path = ir_model_dir / f"{model_name}.xml"
tf_model_url = "https://www.kaggle.com/models/tensorflow/faster-rcnn-resnet-v1/frameworks/tensorFlow2/variations/faster-rcnn-resnet50-v1-640x640/versions/1?tf-hub-format=compressed"
tf_model_archive_filename = f"{model_name}.tar.gz"
Download Model from TensorFlow Hub#
Download archive with TensorFlow Object Detection model (faster_rcnn_resnet50_v1_640x640) from TensorFlow Hub:
download_file(url=tf_model_url, filename=tf_model_archive_filename, directory=tf_model_dir)
model/tf/faster_rcnn_resnet50_v1_640x640.tar.gz: 0%| | 0.00/101M [00:00<?, ?B/s]
IOPub message rate exceeded. The Jupyter server will temporarily stop sending output to the client in order to avoid crashing it. To change this limit, set the config variable --ServerApp.iopub_msg_rate_limit. Current values: ServerApp.iopub_msg_rate_limit=1000.0 (msgs/sec) ServerApp.rate_limit_window=3.0 (secs) IOPub message rate exceeded. The Jupyter server will temporarily stop sending output to the client in order to avoid crashing it. To change this limit, set the config variable --ServerApp.iopub_msg_rate_limit. Current values: ServerApp.iopub_msg_rate_limit=1000.0 (msgs/sec) ServerApp.rate_limit_window=3.0 (secs)
Extract TensorFlow Object Detection model from the downloaded archive:
import tarfile
with tarfile.open(tf_model_dir / tf_model_archive_filename) as file:
file.extractall(path=tf_model_dir)
Convert Model to OpenVINO IR#
OpenVINO Model Conversion API can be used to convert the TensorFlow model to OpenVINO IR.
ov.convert_model function accept path to TensorFlow model and
returns OpenVINO Model class instance which represents this model. Also
we need to provide model input shape (input_shape) that is described
at model overview page on TensorFlow
Hub.
The converted model is ready to load on a device using compile_model
or saved on disk using the save_model function to reduce loading
time when the model is run in the future.
See the Model Preparation Guide for more information about model conversion and TensorFlow models support.
ov_model = ov.convert_model(tf_model_dir)
# Save converted OpenVINO IR model to the corresponding directory
ov.save_model(ov_model, openvino_ir_path)
Test Inference on the Converted Model#
Select inference device#
select device from dropdown list for running inference using OpenVINO
core = ov.Core()
device = device_widget()
device
Dropdown(description='Device:', index=2, options=('CPU', 'GPU', 'AUTO'), value='AUTO')
Load the Model#
core = ov.Core()
openvino_ir_model = core.read_model(openvino_ir_path)
compiled_model = core.compile_model(model=openvino_ir_model, device_name=device.value)
Get Model Information#
Faster R-CNN with Resnet-50 V1 object detection model has one input - a
three-channel image of variable size. The input tensor shape is
[1, height, width, 3] with values in [0, 255].
Model output dictionary contains several tensors:
num_detections- the number of detections in[N]format.detection_boxes- bounding box coordinates for allNdetections in[ymin, xmin, ymax, xmax]format.detection_classes-Ndetection class indexes size from the label file.detection_scores-Ndetection scores (confidence) for each detected class.raw_detection_boxes- decoded detection boxes without Non-Max suppression.raw_detection_scores- class score logits for raw detection boxes.detection_anchor_indices- the anchor indices of the detections after NMS.detection_multiclass_scores- class score distribution (including background) for detection boxes in the image including background class.
In this tutorial we will mostly use detection_boxes,
detection_classes, detection_scores tensors. It is important to
mention, that values of these tensors correspond to each other and are
ordered by the highest detection score: the first detection box
corresponds to the first detection class and to the first (and highest)
detection score.
See the model overview page on TensorFlow Hub for more information about model inputs, outputs and their formats.
model_inputs = compiled_model.inputs
model_input = compiled_model.input(0)
model_outputs = compiled_model.outputs
print("Model inputs count:", len(model_inputs))
print("Model input:", model_input)
print("Model outputs count:", len(model_outputs))
print("Model outputs:")
for output in model_outputs:
print(" ", output)
Model inputs count: 1
Model input: <ConstOutput: names[input_tensor] shape[1,?,?,3] type: u8>
Model outputs count: 8
Model outputs:
<ConstOutput: names[detection_anchor_indices] shape[1,?] type: f32>
<ConstOutput: names[detection_boxes] shape[1,?,..8] type: f32>
<ConstOutput: names[detection_classes] shape[1,?] type: f32>
<ConstOutput: names[detection_multiclass_scores] shape[1,?,..182] type: f32>
<ConstOutput: names[detection_scores] shape[1,?] type: f32>
<ConstOutput: names[num_detections] shape[1] type: f32>
<ConstOutput: names[raw_detection_boxes] shape[1,300,4] type: f32>
<ConstOutput: names[raw_detection_scores] shape[1,300,91] type: f32>
Get an Image for Test Inference#
Load and save an image:
image_path = Path("./data/coco_bike.jpg")
download_file(
url="https://storage.openvinotoolkit.org/repositories/openvino_notebooks/data/data/image/coco_bike.jpg",
filename=image_path.name,
directory=image_path.parent,
)
'data/coco_bike.jpg' already exists.
PosixPath('/home/ea/work/openvino_notebooks/notebooks/tensorflow-object-detection-to-openvino/data/coco_bike.jpg')
Read the image, resize and convert it to the input shape of the network:
# Read the image
image = cv2.imread(filename=str(image_path))
# The network expects images in RGB format
image = cv2.cvtColor(image, code=cv2.COLOR_BGR2RGB)
# Resize the image to the network input shape
resized_image = cv2.resize(src=image, dsize=(255, 255))
# Transpose the image to the network input shape
network_input_image = np.expand_dims(resized_image, 0)
# Show the image
plt.imshow(image)
<matplotlib.image.AxesImage at 0x7f6d48243cd0>

Perform Inference#
inference_result = compiled_model(network_input_image)
After model inference on the test image, object detection data can be
extracted from the result. For further model result visualization
detection_boxes, detection_classes and detection_scores
outputs will be used.
(
_,
detection_boxes,
detection_classes,
_,
detection_scores,
num_detections,
_,
_,
) = model_outputs
image_detection_boxes = inference_result[detection_boxes]
print("image_detection_boxes:", image_detection_boxes)
image_detection_classes = inference_result[detection_classes]
print("image_detection_classes:", image_detection_classes)
image_detection_scores = inference_result[detection_scores]
print("image_detection_scores:", image_detection_scores)
image_num_detections = inference_result[num_detections]
print("image_detections_num:", image_num_detections)
# Alternatively, inference result data can be extracted by model output name with `.get()` method
assert (inference_result[detection_boxes] == inference_result.get("detection_boxes")).all(), "extracted inference result data should be equal"
image_detection_boxes: [[[0.1645457 0.54601336 0.8953864 0.85500604]
[0.67189544 0.01240015 0.9843237 0.53085935]
[0.49188587 0.0117609 0.98050654 0.8866383 ]
...
[0.43604603 0.59332204 0.4692565 0.6341099 ]
[0.46022677 0.59246916 0.48732638 0.61871874]
[0.47092935 0.4351712 0.5583364 0.5072162 ]]]
image_detection_classes: [[18. 2. 2. 3. 2. 8. 2. 2. 3. 2. 4. 4. 2. 4. 16. 1. 1. 2.
27. 8. 62. 2. 2. 4. 4. 2. 18. 41. 4. 4. 2. 18. 2. 2. 4. 2.
27. 2. 27. 2. 1. 2. 16. 1. 16. 2. 2. 2. 2. 16. 2. 2. 4. 2.
1. 33. 4. 15. 3. 2. 2. 1. 2. 1. 4. 2. 3. 11. 4. 35. 4. 1.
40. 2. 62. 2. 4. 4. 36. 1. 36. 36. 31. 77. 2. 1. 51. 1. 34. 3.
2. 3. 90. 2. 1. 2. 1. 2. 1. 1. 2. 4. 18. 2. 3. 2. 31. 1.
1. 2. 2. 33. 41. 41. 31. 3. 1. 36. 3. 15. 27. 27. 4. 4. 2. 37.
3. 15. 1. 35. 27. 4. 36. 4. 88. 3. 2. 15. 2. 4. 2. 1. 3. 4.
27. 4. 3. 16. 44. 1. 1. 23. 4. 1. 4. 3. 4. 15. 62. 36. 77. 3.
1. 28. 27. 35. 2. 36. 75. 28. 27. 8. 3. 36. 4. 44. 2. 35. 4. 1.
3. 1. 1. 35. 87. 1. 1. 1. 15. 84. 1. 1. 1. 3. 1. 35. 1. 1.
1. 62. 15. 1. 15. 44. 1. 41. 1. 62. 4. 4. 3. 43. 16. 35. 15. 2.
4. 34. 14. 3. 62. 33. 4. 41. 2. 35. 18. 3. 15. 1. 27. 4. 87. 2.
19. 21. 1. 1. 27. 1. 3. 3. 2. 15. 38. 1. 1. 15. 27. 4. 4. 3.
84. 38. 1. 15. 3. 20. 62. 58. 41. 20. 2. 4. 88. 62. 15. 31. 1. 31.
14. 19. 4. 1. 2. 8. 18. 15. 4. 2. 2. 2. 31. 84. 15. 3. 28. 2.
27. 18. 15. 1. 31. 28. 1. 41. 8. 1. 3. 20.]]
image_detection_scores: [[0.9810079 0.9406672 0.9318088 0.877368 0.8406416 0.590001
0.55449295 0.53957206 0.49390146 0.48142543 0.46272704 0.44070077
0.40116653 0.34708446 0.31795666 0.27489546 0.24746332 0.23632598
0.23248206 0.22401379 0.21871354 0.20231584 0.19377239 0.14768413
0.1455532 0.14337878 0.12709719 0.12582931 0.11867398 0.11002147
0.10564942 0.09225623 0.08963215 0.08887199 0.08704525 0.08072542
0.08002211 0.07911447 0.0666113 0.06338121 0.06100726 0.06005874
0.05798694 0.05364129 0.0520498 0.05011013 0.04850959 0.04709018
0.04469205 0.04128502 0.04075819 0.03989548 0.03523409 0.03272378
0.03108071 0.02970156 0.028723 0.02845931 0.02585638 0.02348842
0.0233041 0.02148155 0.02133748 0.02086138 0.02035652 0.01959795
0.01931953 0.01926655 0.01872199 0.0185623 0.01853302 0.01838779
0.01818969 0.01780701 0.01727104 0.0166365 0.01586579 0.01579063
0.01573381 0.01528252 0.01502847 0.01451413 0.01439992 0.01428944
0.01419329 0.01380476 0.01360496 0.0129911 0.01249144 0.01198867
0.01148862 0.01145841 0.01144459 0.01139607 0.01113943 0.01108592
0.01089338 0.01082358 0.01051232 0.01027328 0.01006837 0.00979451
0.0097324 0.00960593 0.00957182 0.00953105 0.00949826 0.00942655
0.00942555 0.00931226 0.00907306 0.00887798 0.00884452 0.00881256
0.00864548 0.00854316 0.00849879 0.00849662 0.00846909 0.00820138
0.00816586 0.00791354 0.00790157 0.0076993 0.00768906 0.00766408
0.00766065 0.00764457 0.0074557 0.00721993 0.00706666 0.00700596
0.0067884 0.00648049 0.00646963 0.0063817 0.00635814 0.00625102
0.0062297 0.00599666 0.00591931 0.00585055 0.00578007 0.00576511
0.00572359 0.00560452 0.00558355 0.00556507 0.00553867 0.00548295
0.00547356 0.00543471 0.00543378 0.00540831 0.0053792 0.00535764
0.00523385 0.00518935 0.00505314 0.00505005 0.00492085 0.0048256
0.00471783 0.00470318 0.00464703 0.00461124 0.004583 0.00457273
0.00455803 0.00454314 0.00454088 0.00441311 0.00437612 0.00426319
0.00420744 0.00415996 0.00409997 0.00409557 0.00407971 0.00405195
0.00404085 0.00399853 0.00399512 0.00393439 0.00390283 0.00387302
0.0038489 0.00382758 0.00380028 0.00379529 0.00376791 0.00374193
0.00371191 0.0036963 0.00366445 0.00358808 0.00351783 0.00350439
0.00344527 0.00343266 0.00342918 0.0033823 0.00332239 0.00330844
0.00329753 0.00327267 0.00315135 0.0031098 0.00308979 0.00308362
0.00305496 0.00304868 0.00304044 0.00303659 0.00302582 0.00301237
0.00298851 0.00291267 0.00290264 0.00289242 0.00287722 0.00286563
0.0028257 0.00282502 0.00275258 0.00274531 0.0027204 0.00268617
0.00261917 0.00260795 0.00256594 0.00254094 0.00252856 0.00250768
0.00249793 0.00249551 0.00248255 0.00247911 0.00246619 0.00241695
0.00240165 0.00236032 0.00235902 0.00234437 0.00234337 0.0023379
0.00233535 0.00230773 0.00230558 0.00229113 0.00228888 0.0022631
0.00225214 0.00224186 0.00222553 0.00219966 0.00219677 0.00217865
0.00217775 0.00215921 0.0021541 0.00214997 0.00212954 0.00211928
0.0021005 0.00205066 0.0020487 0.00203887 0.00203537 0.00203026
0.00201357 0.00199936 0.00199386 0.00197951 0.00197287 0.00195502
0.00194848 0.00192128 0.00189951 0.00187285 0.0018519 0.0018299
0.00179158 0.00177908 0.00176328 0.00176319 0.00175034 0.00173788
0.00172983 0.00172819 0.00168272 0.0016768 0.00167543 0.00167397
0.0016395 0.00163637 0.00163319 0.00162886 0.00162824 0.00162028]]
image_detections_num: [300.]
Inference Result Visualization#
Define utility functions to visualize the inference results
from typing import Optional
def add_detection_box(box: np.ndarray, image: np.ndarray, label: Optional[str] = None) -> np.ndarray:
"""
Helper function for adding single bounding box to the image
Parameters
----------
box : np.ndarray
Bounding box coordinates in format [ymin, xmin, ymax, xmax]
image : np.ndarray
The image to which detection box is added
label : str, optional
Detection box label string, if not provided will not be added to result image (default is None)
Returns
-------
np.ndarray
NumPy array including both image and detection box
"""
ymin, xmin, ymax, xmax = box
point1, point2 = (int(xmin), int(ymin)), (int(xmax), int(ymax))
box_color = [np.random.randint(0, 255) for _ in range(3)]
line_thickness = round(0.002 * (image.shape[0] + image.shape[1]) / 2) + 1
cv2.rectangle(
img=image,
pt1=point1,
pt2=point2,
color=box_color,
thickness=line_thickness,
lineType=cv2.LINE_AA,
)
if label:
font_thickness = max(line_thickness - 1, 1)
font_face = 0
font_scale = line_thickness / 3
font_color = (255, 255, 255)
text_size = cv2.getTextSize(
text=label,
fontFace=font_face,
fontScale=font_scale,
thickness=font_thickness,
)[0]
# Calculate rectangle coordinates
rectangle_point1 = point1
rectangle_point2 = (point1[0] + text_size[0], point1[1] - text_size[1] - 3)
# Add filled rectangle
cv2.rectangle(
img=image,
pt1=rectangle_point1,
pt2=rectangle_point2,
color=box_color,
thickness=-1,
lineType=cv2.LINE_AA,
)
# Calculate text position
text_position = point1[0], point1[1] - 3
# Add text with label to filled rectangle
cv2.putText(
img=image,
text=label,
org=text_position,
fontFace=font_face,
fontScale=font_scale,
color=font_color,
thickness=font_thickness,
lineType=cv2.LINE_AA,
)
return image
from typing import Dict
from openvino.runtime.utils.data_helpers import OVDict
def visualize_inference_result(
inference_result: OVDict,
image: np.ndarray,
labels_map: Dict,
detections_limit: Optional[int] = None,
):
"""
Helper function for visualizing inference result on the image
Parameters
----------
inference_result : OVDict
Result of the compiled model inference on the test image
image : np.ndarray
Original image to use for visualization
labels_map : Dict
Dictionary with mappings of detection classes numbers and its names
detections_limit : int, optional
Number of detections to show on the image, if not provided all detections will be shown (default is None)
"""
detection_boxes: np.ndarray = inference_result.get("detection_boxes")
detection_classes: np.ndarray = inference_result.get("detection_classes")
detection_scores: np.ndarray = inference_result.get("detection_scores")
num_detections: np.ndarray = inference_result.get("num_detections")
detections_limit = int(min(detections_limit, num_detections[0]) if detections_limit is not None else num_detections[0])
# Normalize detection boxes coordinates to original image size
original_image_height, original_image_width, _ = image.shape
normalized_detection_boxex = detection_boxes[::] * [
original_image_height,
original_image_width,
original_image_height,
original_image_width,
]
image_with_detection_boxex = np.copy(image)
for i in range(detections_limit):
detected_class_name = labels_map[int(detection_classes[0, i])]
score = detection_scores[0, i]
label = f"{detected_class_name} {score:.2f}"
add_detection_box(
box=normalized_detection_boxex[0, i],
image=image_with_detection_boxex,
label=label,
)
plt.imshow(image_with_detection_boxex)
TensorFlow Object Detection model (faster_rcnn_resnet50_v1_640x640) used in this notebook was trained on COCO 2017 dataset with 91 classes. For better visualization experience we can use COCO dataset labels with human readable class names instead of class numbers or indexes.
We can download COCO dataset classes labels from Open Model Zoo:
coco_labels_file_path = Path("./data/coco_91cl.txt")
download_file(
url="https://raw.githubusercontent.com/openvinotoolkit/open_model_zoo/master/data/dataset_classes/coco_91cl.txt",
filename=coco_labels_file_path.name,
directory=coco_labels_file_path.parent,
)
data/coco_91cl.txt: 0%| | 0.00/421 [00:00<?, ?B/s]
PosixPath('/home/ea/work/openvino_notebooks/notebooks/tensorflow-object-detection-to-openvino/data/coco_91cl.txt')
Then we need to create dictionary coco_labels_map with mappings
between detection classes numbers and its names from the downloaded
file:
with open(coco_labels_file_path, "r") as file:
coco_labels = file.read().strip().split("\n")
coco_labels_map = dict(enumerate(coco_labels, 1))
print(coco_labels_map)
{1: 'person', 2: 'bicycle', 3: 'car', 4: 'motorcycle', 5: 'airplan', 6: 'bus', 7: 'train', 8: 'truck', 9: 'boat', 10: 'traffic light', 11: 'fire hydrant', 12: 'street sign', 13: 'stop sign', 14: 'parking meter', 15: 'bench', 16: 'bird', 17: 'cat', 18: 'dog', 19: 'horse', 20: 'sheep', 21: 'cow', 22: 'elephant', 23: 'bear', 24: 'zebra', 25: 'giraffe', 26: 'hat', 27: 'backpack', 28: 'umbrella', 29: 'shoe', 30: 'eye glasses', 31: 'handbag', 32: 'tie', 33: 'suitcase', 34: 'frisbee', 35: 'skis', 36: 'snowboard', 37: 'sports ball', 38: 'kite', 39: 'baseball bat', 40: 'baseball glove', 41: 'skateboard', 42: 'surfboard', 43: 'tennis racket', 44: 'bottle', 45: 'plate', 46: 'wine glass', 47: 'cup', 48: 'fork', 49: 'knife', 50: 'spoon', 51: 'bowl', 52: 'banana', 53: 'apple', 54: 'sandwich', 55: 'orange', 56: 'broccoli', 57: 'carrot', 58: 'hot dog', 59: 'pizza', 60: 'donut', 61: 'cake', 62: 'chair', 63: 'couch', 64: 'potted plant', 65: 'bed', 66: 'mirror', 67: 'dining table', 68: 'window', 69: 'desk', 70: 'toilet', 71: 'door', 72: 'tv', 73: 'laptop', 74: 'mouse', 75: 'remote', 76: 'keyboard', 77: 'cell phone', 78: 'microwave', 79: 'oven', 80: 'toaster', 81: 'sink', 82: 'refrigerator', 83: 'blender', 84: 'book', 85: 'clock', 86: 'vase', 87: 'scissors', 88: 'teddy bear', 89: 'hair drier', 90: 'toothbrush', 91: 'hair brush'}
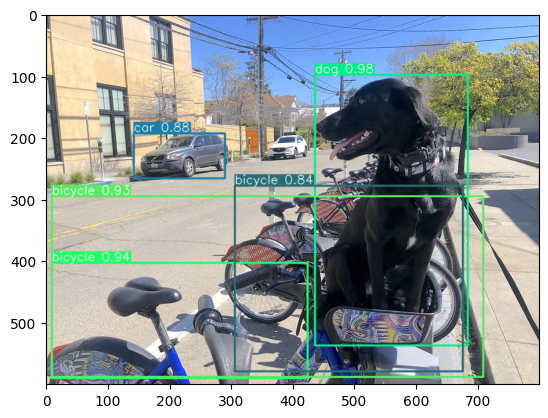
Finally, we are ready to visualize model inference results on the original test image:
visualize_inference_result(
inference_result=inference_result,
image=image,
labels_map=coco_labels_map,
detections_limit=5,
)
Next Steps#
This section contains suggestions on how to additionally improve the performance of your application using OpenVINO.
Async inference pipeline#
The key advantage of the Async API is that when a device is busy with inference, the application can perform other tasks in parallel (for example, populating inputs or scheduling other requests) rather than wait for the current inference to complete first. To understand how to perform async inference using openvino, refer to the Async API tutorial.
Integration preprocessing to model#
Preprocessing API enables making preprocessing a part of the model reducing application code and dependency on additional image processing libraries. The main advantage of Preprocessing API is that preprocessing steps will be integrated into the execution graph and will be performed on a selected device (CPU/GPU etc.) rather than always being executed on CPU as part of an application. This will improve selected device utilization.
For more information, refer to the Optimize Preprocessing tutorial and to the overview of Preprocessing API.