Cross-lingual Books Alignment with Transformers and OpenVINO™#
This Jupyter notebook can be launched on-line, opening an interactive environment in a browser window. You can also make a local installation. Choose one of the following options:



Cross-lingual text alignment is the task of matching sentences in a pair of texts that are translations of each other. In this notebook, you’ll learn how to use a deep learning model to create a parallel book in English and German
This method helps you learn languages but also provides parallel texts that can be used to train machine translation models. This is particularly useful if one of the languages is low-resource or you don’t have enough data to train a full-fledged translation model.
The notebook shows how to accelerate the most computationally expensive part of the pipeline - getting vectors from sentences - using the OpenVINO™ framework.
Pipeline#
The notebook guides you through the entire process of creating a parallel book: from obtaining raw texts to building a visualization of aligned sentences. Here is the pipeline diagram:

Visualizing the result allows you to identify areas for improvement in the pipeline steps, as indicated in the diagram.
Prerequisites#
requests- for getting bookspysbd- for splitting sentencestransformers[torch]andopenvino- for getting sentence embeddingsseaborn- for alignment matrix visualizationipywidgets- for displaying HTML and JS output in the notebook
Table of contents:
Installation Instructions#
This is a self-contained example that relies solely on its own code.
We recommend running the notebook in a virtual environment. You only need a Jupyter server to start. For details, please refer to Installation Guide.
%pip install -q --extra-index-url https://download.pytorch.org/whl/cpu requests pysbd transformers "torch>=2.1" "openvino>=2023.1.0" seaborn ipywidgets "matplotlib>=3.4"
Get Books#
The first step is to get the books that we will be working with. For this notebook, we will use English and German versions of Anna Karenina by Leo Tolstoy. The texts can be obtained from the Project Gutenberg site. Since copyright laws are complex and differ from country to country, check the book’s legal availability in your country. Refer to the Project Gutenberg Permissions, Licensing and other Common Requests page for more information.
Find the books on Project Gutenberg search page and get the ID of each book. To get the texts, we will pass the IDs to the Gutendex API.
import requests
r = requests.get(
url="https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/utils/notebook_utils.py",
)
open("notebook_utils.py", "w").write(r.text)
def get_book_by_id(book_id: int, gutendex_url: str = "https://gutendex.com/") -> str:
book_metadata_url = gutendex_url + "/books/" + str(book_id)
request = requests.get(book_metadata_url, timeout=30)
request.raise_for_status()
book_metadata = request.json()
text_format_key = "text/plain"
text_plain = [k for k in book_metadata["formats"] if k.startswith(text_format_key)]
book_url = book_metadata["formats"][text_plain[0]]
return requests.get(book_url).text
en_book_id = 1399
de_book_id = 44956
anna_karenina_en = get_book_by_id(en_book_id)
anna_karenina_de = get_book_by_id(de_book_id)
Let’s check that we got the right books by showing a part of the texts:
print(anna_karenina_en[:1500])
The Project Gutenberg eBook of Anna Karenina
This ebook is for the use of anyone anywhere in the United States and
most other parts of the world at no cost and with almost no restrictions
whatsoever. You may copy it, give it away or re-use it under the terms
of the Project Gutenberg License included with this ebook or online
at www.gutenberg.org. If you are not located in the United States,
you will have to check the laws of the country where you are located
before using this eBook.
Title: Anna Karenina
Author: graf Leo Tolstoy
Translator: Constance Garnett
Release date: July 1, 1998 [eBook #1399]
Most recently updated: April 9, 2023
Language: English
* START OF THE PROJECT GUTENBERG EBOOK ANNA KARENINA *
[Illustration]
ANNA KARENINA
by Leo Tolstoy
Translated by Constance Garnett
Contents
PART ONE
PART TWO
PART THREE
PART FOUR
PART FIVE
PART SIX
PART SEVEN
PART EIGHT
PART ONE
Chapter 1
Happy families are all alike; every unhappy family is unhappy in its
own way.
Everything was in confusion in the Oblonskys’ house. The wife had
discovered that the husband was carrying on an intrigue with a French
girl, who had been a governess in their family, and she had announced
to her husband that she could not go on living in the same house with
him. This position of affairs had now lasted three days, and not only
the husband and wife themselves, but all the me
which in a raw format looks like this:
anna_karenina_en[:1500]
'ufeffThe Project Gutenberg eBook of Anna Kareninarn rnThis ebook is for the use of anyone anywhere in the United States andrnmost other parts of the world at no cost and with almost no restrictionsrnwhatsoever. You may copy it, give it away or re-use it under the termsrnof the Project Gutenberg License included with this ebook or onlinernat www.gutenberg.org. If you are not located in the United States,rnyou will have to check the laws of the country where you are locatedrnbefore using this eBook.rnrnTitle: Anna KareninarnrnrnAuthor: graf Leo TolstoyrnrnTranslator: Constance GarnettrnrnRelease date: July 1, 1998 [eBook #1399]rn Most recently updated: April 9, 2023rnrnLanguage: Englishrnrnrnrn*** START OF THE PROJECT GUTENBERG EBOOK ANNA KARENINA ***rn[Illustration]rnrnrnrnrn ANNA KARENINA rnrn by Leo Tolstoy rnrn Translated by Constance Garnett rnrnContentsrnrnrn PART ONErn PART TWOrn PART THREErn PART FOURrn PART FIVErn PART SIXrn PART SEVENrn PART EIGHTrnrnrnrnrnPART ONErnrnChapter 1rnrnrnHappy families are all alike; every unhappy family is unhappy in itsrnown way.rnrnEverything was in confusion in the Oblonskys’ house. The wife hadrndiscovered that the husband was carrying on an intrigue with a Frenchrngirl, who had been a governess in their family, and she had announcedrnto her husband that she could not go on living in the same house withrnhim. This position of affairs had now lasted three days, and not onlyrnthe husband and wife themselves, but all the me'
anna_karenina_de[:1500]
'The Project Gutenberg EBook of Anna Karenina, 1. Band, by Leo N. TolstoirnrnThis eBook is for the use of anyone anywhere at no cost and withrnalmost no restrictions whatsoever. You may copy it, give it away orrnre-use it under the terms of the Project Gutenberg License includedrnwith this eBook or online at www.gutenberg.orgrnrnrnTitle: Anna Karenina, 1. BandrnrnAuthor: Leo N. TolstoirnrnRelease Date: February 18, 2014 [EBook #44956]rnrnLanguage: GermanrnrnCharacter set encoding: ISO-8859-1rnrn*** START OF THIS PROJECT GUTENBERG EBOOK ANNA KARENINA, 1. BAND ***rnrnrnrnrnProduced by Norbert H. Langkau, Jens Nordmann and thernOnline Distributed Proofreading Team at http://www.pgdp.netrnrnrnrnrnrnrnrnrnrn Anna Karenina.rnrnrn Roman aus dem Russischenrnrn desrnrn Grafen Leo N. Tolstoi.rnrnrnrn Nach der siebenten Auflage übersetztrnrn vonrnrn Hans Moser.rnrnrn Erster Band.rnrnrnrn Leipzigrnrn Druck und Verlag von Philipp Reclam jun.rnrn * * * * *rnrnrnrnrn Erster Teil.rnrn »Die Rache ist mein, ich will vergelten.«rnrn 1.rnrnrnAlle glücklichen Familien sind einander ähnlich; jede unglücklich'
Clean Text#
The downloaded books may contain service information before and after the main text. The text might have different formatting styles and markup, for example, phrases from a different language enclosed in underscores for potential emphasis or italicization:
Yes, Alabin was giving a dinner on glass tables, and the tables sang, Il mio tesoro—not Il mio tesoro though, but something better, and there were some sort of little decanters on the table, and they were women, too,” he remembered.
The next stages of the pipeline will be difficult to complete without
cleaning and normalizing the text. Since formatting may differ, manual
work is required at this stage. For example, the main content in the
German version is enclosed in * * * * *, so
it is safe to remove everything before the first occurrence and after
the last occurrence of these asterisks.
Hint: There are text-cleaning libraries that clean up common flaws. If the source of the text is known, you can look for a library designed for that source, for example gutenberg_cleaner. These libraries can reduce manual work and even automate the process.process.
import re
from contextlib import contextmanager
from tqdm.auto import tqdm
start_pattern_en = r"\nPART ONE"
anna_karenina_en = re.split(start_pattern_en, anna_karenina_en)[1].strip()
end_pattern_en = "*** END OF THE PROJECT GUTENBERG EBOOK ANNA KARENINA ***"
anna_karenina_en = anna_karenina_en.split(end_pattern_en)[0].strip()
start_pattern_de = "* * * * *"
anna_karenina_de = anna_karenina_de.split(start_pattern_de, maxsplit=1)[1].strip()
anna_karenina_de = anna_karenina_de.rsplit(start_pattern_de, maxsplit=1)[0].strip()
anna_karenina_en = anna_karenina_en.replace("\r\n", "\n")
anna_karenina_de = anna_karenina_de.replace("\r\n", "\n")
For this notebook, we will work only with the first chapter.
chapter_pattern_en = r"Chapter \d?\d"
chapter_1_en = re.split(chapter_pattern_en, anna_karenina_en)[1].strip()
chapter_pattern_de = r"\d?\d.\n\n"
chapter_1_de = re.split(chapter_pattern_de, anna_karenina_de)[1].strip()
Let’s cut it out and define some cleaning functions.
def remove_single_newline(text: str) -> str:
return re.sub(r"\n(?!\n)", " ", text)
def unify_quotes(text: str) -> str:
return re.sub(r"['\"»«“”]", '"', text)
def remove_markup(text: str) -> str:
text = text.replace(">=", "").replace("=<", "")
return re.sub(r"_\w|\w_", "", text)
Combine the cleaning functions into a single pipeline. The tqdm
library is used to track the execution progress. Define a context
manager to optionally disable the progress indicators if they are not
needed.
disable_tqdm = False
@contextmanager
def disable_tqdm_context():
global disable_tqdm
disable_tqdm = True
yield
disable_tqdm = False
def clean_text(text: str) -> str:
text_cleaning_pipeline = [
remove_single_newline,
unify_quotes,
remove_markup,
]
progress_bar = tqdm(text_cleaning_pipeline, disable=disable_tqdm)
for clean_func in progress_bar:
progress_bar.set_postfix_str(clean_func.__name__)
text = clean_func(text)
return text
chapter_1_en = clean_text(chapter_1_en)
chapter_1_de = clean_text(chapter_1_de)
0%| | 0/3 [00:00<?, ?it/s]
0%| | 0/3 [00:00<?, ?it/s]
Split Text#
Dividing text into sentences is a challenging task in text processing.
The problem is called sentence boundary
disambiguation,
which can be solved using heuristics or machine learning models. This
notebook uses a Segmenter from the pysbd library, which is
initialized with an ISO language
code, as the
rules for splitting text into sentences may vary for different
languages.
Hint: The
book_metadataobtained from the Gutendex contains the language code as well, enabling automation of this part of the pipeline.
import pysbd
splitter_en = pysbd.Segmenter(language="en", clean=True)
splitter_de = pysbd.Segmenter(language="de", clean=True)
sentences_en = splitter_en.segment(chapter_1_en)
sentences_de = splitter_de.segment(chapter_1_de)
len(sentences_en), len(sentences_de)
(32, 34)
Get Sentence Embeddings#
The next step is to transform sentences into vector representations. Transformer encoder models, like BERT, provide high-quality embeddings but can be slow. Additionally, the model should support both chosen languages. Training separate models for each language pair can be expensive, so there are many models pre-trained on multiple languages simultaneously, for example:
LaBSE stands for Language-agnostic BERT Sentence Embedding and supports 109+ languages. It has the same architecture as the BERT model but has been trained on a different task: to produce identical embeddings for translation pairs.
This makes LaBSE a great choice for our task and it can be reused for different language pairs still producing good results.
from typing import List, Union, Dict
from transformers import AutoTokenizer, AutoModel, BertModel
import numpy as np
import torch
from openvino.runtime import CompiledModel as OVModel
import openvino as ov
model_id = "rasa/LaBSE"
pt_model = AutoModel.from_pretrained(model_id)
tokenizer = AutoTokenizer.from_pretrained(model_id)
The model has two outputs: last_hidden_state and pooler_output.
For generating embeddings, you can use either the first vector from the
last_hidden_state, which corresponds to the special [CLS] token,
or the entire vector from the second input. Usually, the second option
is used, but we will be using the first option as it also works well for
our task. Fill free to experiment with different outputs to find the
best fit.
def get_embeddings(
sentences: List[str],
embedding_model: Union[BertModel, OVModel],
) -> np.ndarray:
if isinstance(embedding_model, OVModel):
embeddings = [embedding_model(tokenizer(sent, return_tensors="np").data)["last_hidden_state"][0][0] for sent in tqdm(sentences, disable=disable_tqdm)]
return np.vstack(embeddings)
else:
embeddings = [embedding_model(**tokenizer(sent, return_tensors="pt"))["last_hidden_state"][0][0] for sent in tqdm(sentences, disable=disable_tqdm)]
return torch.vstack(embeddings)
embeddings_en_pt = get_embeddings(sentences_en, pt_model)
embeddings_de_pt = get_embeddings(sentences_de, pt_model)
0%| | 0/32 [00:00<?, ?it/s]
0%| | 0/34 [00:00<?, ?it/s]
Optimize the Model with OpenVINO#
The LaBSE model is quite large and can be slow to infer on some
hardware, so let’s optimize it with OpenVINO. Model Conversion
API
accepts the PyTorch/Transformers model object and additional information
about model inputs. An example_input is needed to trace the model
execution graph, as PyTorch constructs it dynamically during inference.
The converted model must be compiled for the target device using the
Core object before it can be used.
For starting work, we should select device for inference first:
from notebook_utils import device_widget
core = ov.Core()
device = device_widget()
device
# 3 inputs with dynamic axis [batch_size, sequence_length] and type int64
inputs_info = [([-1, -1], ov.Type.i64)] * 3
ov_model = ov.convert_model(
pt_model,
example_input=tokenizer("test", return_tensors="pt").data,
input=inputs_info,
)
core = ov.Core()
compiled_model = core.compile_model(ov_model, device.value)
embeddings_en = get_embeddings(sentences_en, compiled_model)
embeddings_de = get_embeddings(sentences_de, compiled_model)
0%| | 0/32 [00:00<?, ?it/s]
0%| | 0/34 [00:00<?, ?it/s]
On an Intel Core i9-10980XE CPU, the PyTorch model processed 40-43 sentences per second. After optimization with OpenVINO, the processing speed increased to 56-60 sentences per second. This is about 40% performance boost with just a few lines of code. Let’s check if the model predictions remain within an acceptable tolerance:
np.all(np.isclose(embeddings_en, embeddings_en_pt.detach().numpy(), atol=1e-3))
True
Calculate Sentence Alignment#
With the embedding matrices from the previous step, we can calculate the
alignment: 1. Calculate sentence similarity between each pair of
sentences. 1. Transform the values in the similarity matrix rows and
columns to a specified range, for example [-1, 1]. 1. Compare the
values with a threshold to get boolean matrices with 0 and 1. 1.
Sentence pairs that have 1 in both matrices should be aligned according
to the model.
We visualize the resulting matrix and also make sure that the result of the converted model is the same as the original one.
import seaborn as sns
import matplotlib.pyplot as plt
sns.set_style("whitegrid")
def transform(x):
x = x - np.mean(x)
return x / np.var(x)
def calculate_alignment_matrix(first: np.ndarray, second: np.ndarray, threshold: float = 1e-3) -> np.ndarray:
similarity = first @ second.T # 1
similarity_en_to_de = np.apply_along_axis(transform, -1, similarity) # 2
similarity_de_to_en = np.apply_along_axis(transform, -2, similarity) # 2
both_one = (similarity_en_to_de > threshold) * (similarity_de_to_en > threshold) # 3 and 4
return both_one
threshold = 0.028
alignment_matrix = calculate_alignment_matrix(embeddings_en, embeddings_de, threshold)
alignment_matrix_pt = calculate_alignment_matrix(
embeddings_en_pt.detach().numpy(),
embeddings_de_pt.detach().numpy(),
threshold,
)
graph, axis = plt.subplots(1, 2, figsize=(10, 5), sharey=True)
for matrix, ax, title in zip((alignment_matrix, alignment_matrix_pt), axis, ("OpenVINO", "PyTorch")):
plot = sns.heatmap(matrix, cbar=False, square=True, ax=ax)
plot.set_title(f"Sentence Alignment Matrix {title}")
plot.set_xlabel("German")
if title == "OpenVINO":
plot.set_ylabel("English")
graph.tight_layout()
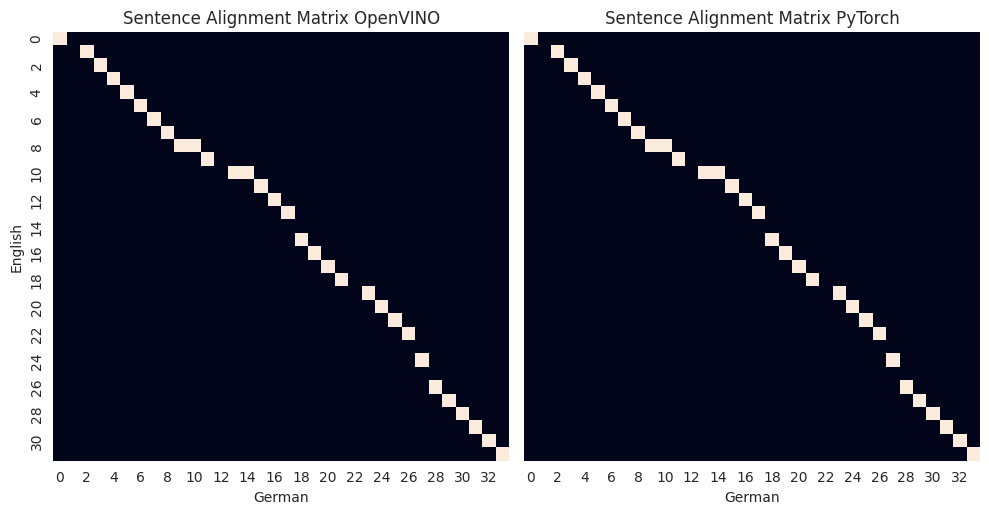
After visualizing and comparing the alignment matrices, let’s transform them into a dictionary to make it more convenient to work with alignment in Python. Dictionary keys will be English sentence numbers and values will be lists of German sentence numbers.
def make_alignment(alignment_matrix: np.ndarray) -> Dict[int, List[int]]:
aligned = {idx: [] for idx, sent in enumerate(sentences_en)}
for en_idx, de_idx in zip(*np.nonzero(alignment_matrix)):
aligned[en_idx].append(de_idx)
return aligned
aligned = make_alignment(alignment_matrix)
aligned
{0: [0],
1: [2],
2: [3],
3: [4],
4: [5],
5: [6],
6: [7],
7: [8],
8: [9, 10],
9: [11],
10: [13, 14],
11: [15],
12: [16],
13: [17],
14: [],
15: [18],
16: [19],
17: [20],
18: [21],
19: [23],
20: [24],
21: [25],
22: [26],
23: [],
24: [27],
25: [],
26: [28],
27: [29],
28: [30],
29: [31],
30: [32],
31: [33]}
Postprocess Sentence Alignment#
There are several gaps in the resulting alignment, such as English sentence #14 not mapping to any German sentence. Here are some possible reasons for this:
There are no equivalent sentences in the other book, and in such cases, the model is working correctly.
The sentence has an equivalent sentence in another language, but the model failed to identify it. The
thresholdmight be too high, or the model is not sensitive enough. To address this, lower thethresholdvalue or try a different model.The sentence has an equivalent text part in another language, meaning that either the sentence splitters are too fine or too coarse. Try tuning the text cleaning and splitting steps to fix this issue.
Combination of 2 and 3, where both the model’s sensitivity and text preparation steps need adjustments.
Another solution to address this issue is by applying heuristics. As you can see, English sentence 13 corresponds to German 17, and 15 to 18. Most likely, English sentence 14 is part of either German sentence 17 or 18. By comparing the similarity using the model, you can choose the most suitable alignment.
Visualize Sentence Alignment#
To evaluate the final alignment and choose the best way to improve the results of the pipeline, we will create an interactive table with HTML and JS.
from IPython.display import display, HTML
from itertools import zip_longest
from io import StringIO
def create_interactive_table(list1: List[str], list2: List[str], mapping: Dict[int, List[int]]) -> str:
def inverse_mapping(mapping):
inverse_map = {idx: [] for idx in range(len(list2))}
for key, values in mapping.items():
for value in values:
inverse_map[value].append(key)
return inverse_map
inversed_mapping = inverse_mapping(mapping)
table_html = StringIO()
table_html.write('<table id="mappings-table"><tr><th>Sentences EN</th><th>Sentences DE</th></tr>')
for i, (first, second) in enumerate(zip_longest(list1, list2)):
table_html.write("<tr>")
if i < len(list1):
table_html.write(f'<td id="list1-{i}">{first}</td>')
else:
table_html.write("<td></td>")
if i < len(list2):
table_html.write(f'<td id="list2-{i}">{second}</td>')
else:
table_html.write("<td></td>")
table_html.write("</tr>")
table_html.write("</table>")
hover_script = (
"""
<script type="module">
const highlightColor = '#0054AE';
const textColor = 'white'
const mappings = {
'list1': """
+ str(mapping)
+ """,
'list2': """
+ str(inversed_mapping)
+ """
};
const table = document.getElementById('mappings-table');
let highlightedIds = [];
table.addEventListener('mouseover', ({ target }) => {
if (target.tagName !== 'TD' || !target.id) {
return;
}
const [listName, listId] = target.id.split('-');
const mappedIds = mappings[listName]?.[listId]?.map((id) => `${listName === 'list1' ? 'list2' : 'list1'}-${id}`) || [];
const idsToHighlight = [target.id, ...mappedIds];
setBackgroud(idsToHighlight, highlightColor, textColor);
highlightedIds = idsToHighlight;
});
table.addEventListener('mouseout', () => setBackgroud(highlightedIds, ''));
function setBackgroud(ids, color, text_color="unset") {
ids.forEach((id) => {
document.getElementById(id).style.backgroundColor = color;
document.getElementById(id).style.color = text_color
});
}
</script>
"""
)
table_html.write(hover_script)
return table_html.getvalue()
html_code = create_interactive_table(sentences_en, sentences_de, aligned)
display(HTML(html_code))
| Sentences EN | Sentences DE |
|---|---|
| Happy families are all alike; every unhappy family is unhappy in its own way. | Alle glücklichen Familien sind einander ähnlich; jede unglückliche Familie ist auf hr Weise unglücklich. |
| Everything was in confusion in the Oblonskys’ house. | -- |
| The wife had discovered that the husband was carrying on an intrigue with a French girl, who had been a governess in their family, and she had announced to her husband that she could not go on living in the same house with him. | Im Hause der Oblonskiy herrschte allgemeine Verwirrung. |
| This position of affairs had now lasted three days, and not only the husband and wife themselves, but all the members of their family and household, were painfully conscious of it. | Die Dame des Hauses hatte in Erfahrung gebracht, daß ihr Gatte mit der im Hause gewesenen französischen Gouvernante ein Verhältnis unterhalten, und ihm erklärt, sie könne fürderhin nicht mehr mit ihm unter einem Dache bleiben. |
| Every person in the house felt that there was no sense in their living together, and that the stray people brought together by chance in any inn had more in common with one another than they, the members of the family and household of the Oblonskys. | Diese Situation währte bereits seit drei Tagen und sie wurde nicht allein von den beiden Ehegatten selbst, nein auch von allen Familienmitgliedern und dem Personal aufs Peinlichste empfunden. |
| The wife did not leave her own room, the husband had not been at home for three days. | Sie alle fühlten, daß in ihrem Zusammenleben kein höherer Gedanke mehr liege, daß die Leute, welche auf jeder Poststation sich zufällig träfen, noch enger zu einander gehörten, als sie, die Glieder der Familie selbst, und das im Hause geborene und aufgewachsene Gesinde der Oblonskiy. |
| The children ran wild all over the house; the English governess quarreled with the housekeeper, and wrote to a friend asking her to look out for a new situation for her; the man-cook had walked off the day before just at dinner time; the kitchen-maid, and the coachman had given warning. | Die Herrin des Hauses verließ ihre Gemächer nicht, der Gebieter war schon seit drei Tagen abwesend. |
| Three days after the quarrel, Prince Stepan Arkadyevitch Oblonsky—Stiva, as he was called in the fashionable world—woke up at his usual hour, that is, at eight o’clock in the morning, not in his wife’s bedroom, but on the leather-covered sofa in his study. | Die Kinder liefen wie verwaist im ganzen Hause umher, die Engländerin schalt auf die Wirtschafterin und schrieb an eine Freundin, diese möchte ihr eine neue Stellung verschaffen, der Koch hatte bereits seit gestern um die Mittagszeit das Haus verlassen und die Köchin, sowie der Kutscher hatten ihre Rechnungen eingereicht. |
| He turned over his stout, well-cared-for person on the springy sofa, as though he would sink into a long sleep again; he vigorously embraced the pillow on the other side and buried his face in it; but all at once he jumped up, sat up on the sofa, and opened his eyes. | Am dritten Tage nach der Scene erwachte der Fürst Stefan Arkadjewitsch Oblonskiy -- Stiwa hieß er in der Welt -- um die gewöhnliche Stunde, das heißt um acht Uhr morgens, aber nicht im Schlafzimmer seiner Gattin, sondern in seinem Kabinett auf dem Saffiandiwan. |
| "Yes, yes, how was it now?" he thought, going over his dream. | Er wandte seinen vollen verweichlichten Leib auf den Sprungfedern des Diwans, als wünsche er noch weiter zu schlafen, während er von der andern Seite innig ein Kissen umfaßte und an die Wange drückte. |
| "Now, how was it? To be sure! Alabin was giving a dinner at Darmstadt; no, not Darmstadt, but something American. Yes, but then, Darmstadt was in America. Yes, Alabin was giving a dinner on glass tables, and the tables sang, l mio tesor—not l mio tesor though, but something better, and there were some sort of little decanters on the table, and they were women, too," he remembered. | Plötzlich aber sprang er empor, setzte sich aufrecht und öffnete die Augen. |
| Stepan Arkadyevitch’s eyes twinkled gaily, and he pondered with a smile. | "Ja, ja, wie war doch das?" sann er, über seinem Traum grübelnd. |
| "Yes, it was nice, very nice. There was a great deal more that was delightful, only there’s no putting it into words, or even expressing it in one’s thoughts awake." | "Wie war doch das? |
| And noticing a gleam of light peeping in beside one of the serge curtains, he cheerfully dropped his feet over the edge of the sofa, and felt about with them for his slippers, a present on his last birthday, worked for him by his wife on gold-colored morocco. | Richtig; Alabin gab ein Diner in Darmstadt; nein, nicht in Darmstadt, es war so etwas Amerikanisches dabei. |
| And, as he had done every day for the last nine years, he stretched out his hand, without getting up, towards the place where his dressing-gown always hung in his bedroom. | Dieses Darmstadt war aber in Amerika, ja, und Alabin gab das Essen auf gläsernen Tischen, ja, und die Tische sangen: Il mio tesoro -- oder nicht so, es war etwas Besseres, und gewisse kleine Karaffen, wie Frauenzimmer aussehend," -- fiel ihm ein. |
| And thereupon he suddenly remembered that he was not sleeping in his wife’s room, but in his study, and why: the smile vanished from his face, he knitted his brows. | Die Augen Stefan Arkadjewitschs blitzten heiter, er sann und lächelte. |
| "Ah, ah, ah! Oo!..." he muttered, recalling everything that had happened. | "Ja, es war hübsch, sehr hübsch. Es gab viel Ausgezeichnetes dabei, was man mit Worten nicht schildern könnte und in Gedanken nicht ausdrücken." |
| And again every detail of his quarrel with his wife was present to his imagination, all the hopelessness of his position, and worst of all, his own fault. | Er bemerkte einen Lichtstreif, der sich von der Seite durch die baumwollenen Stores gestohlen hatte und schnellte lustig mit den Füßen vom Sofa, um mit ihnen die von seiner Gattin ihm im vorigen Jahr zum Geburtstag verehrten gold- und saffiangestickten Pantoffeln zu suchen; während er, einer alten neunjährigen Gewohnheit folgend, ohne aufzustehen mit der Hand nach der Stelle fuhr, wo in dem Schlafzimmer sonst sein Morgenrock zu hängen pflegte. |
| "Yes, she won’t forgive me, and she can’t forgive me. And the most awful thing about it is that it’s all my fault—all my fault, though I’m not to blame. That’s the point of the whole situation," he reflected. | Hierbei erst kam er zur Besinnung; er entsann sich jäh wie es kam, daß er nicht im Schlafgemach seiner Gattin, sondern in dem Kabinett schlief; das Lächeln verschwand von seinen Zügen und er runzelte die Stirn. |
| "Oh, oh, oh!" he kept repeating in despair, as he remembered the acutely painful sensations caused him by this quarrel. | "O, o, o, ach," brach er jammernd aus, indem ihm alles wieder einfiel, was vorgefallen war. |
| Most unpleasant of all was the first minute when, on coming, happy and good-humored, from the theater, with a huge pear in his hand for his wife, he had not found his wife in the drawing-room, to his surprise had not found her in the study either, and saw her at last in her bedroom with the unlucky letter that revealed everything in her hand. | Vor seinem Innern erstanden von neuem alle die Einzelheiten des Auftritts mit seiner Frau, erstand die ganze Mißlichkeit seiner Lage und -- was ihm am peinlichsten war -- seine eigene Schuld. |
| She, his Dolly, forever fussing and worrying over household details, and limited in her ideas, as he considered, was sitting perfectly still with the letter in her hand, looking at him with an expression of horror, despair, and indignation. | "Ja wohl, sie wird nicht verzeihen, sie kann nicht verzeihen, und am Schrecklichsten ist, daß die Schuld an allem nur ich selbst trage -- ich bin schuld -- aber nicht schuldig! |
| "What’s this? this?" she asked, pointing to the letter. | Und hierin liegt das ganze Drama," dachte er, "o weh, o weh!" |
| And at this recollection, Stepan Arkadyevitch, as is so often the case, was not so much annoyed at the fact itself as at the way in which he had met his wife’s words. | Er sprach voller Verzweiflung, indem er sich alle die tiefen Eindrücke vergegenwärtigte, die er in jener Scene erhalten. |
| There happened to him at that instant what does happen to people when they are unexpectedly caught in something very disgraceful. | Am unerquicklichsten war ihm jene erste Minute gewesen, da er, heiter und zufrieden aus dem Theater heimkehrend, eine ungeheure Birne für seine Frau in der Hand, diese weder im Salon noch im Kabinett fand, und sie endlich im Schlafzimmer antraf, jenen unglückseligen Brief, der alles entdeckte, in den Händen. |
| He did not succeed in adapting his face to the position in which he was placed towards his wife by the discovery of his fault. | Sie, die er für die ewig sorgende, ewig sich mühende, allgegenwärtige Dolly gehalten, sie saß jetzt regungslos, den Brief in der Hand, mit dem Ausdruck des Entsetzens, der Verzweiflung und der Wut ihm entgegenblickend. |
| Instead of being hurt, denying, defending himself, begging forgiveness, instead of remaining indifferent even—anything would have been better than what he did do—his face utterly involuntarily (reflex spinal action, reflected Stepan Arkadyevitch, who was fond of physiology)—utterly involuntarily assumed its habitual, good-humored, and therefore idiotic smile. | "Was ist das?" frug sie ihn, auf das Schreiben weisend, und in der Erinnerung hieran quälte ihn, wie das oft zu geschehen pflegt, nicht sowohl der Vorfall selbst, als die Art, wie er ihr auf diese Worte geantwortet hatte. |
| This idiotic smile he could not forgive himself. | Es ging ihm in diesem Augenblick, wie den meisten Menschen, wenn sie unerwartet eines zu schmählichen Vergehens überführt werden. |
| Catching sight of that smile, Dolly shuddered as though at physical pain, broke out with her characteristic heat into a flood of cruel words, and rushed out of the room. | Er verstand nicht, sein Gesicht der Situation anzupassen, in welche er nach der Entdeckung seiner Schuld geraten war, und anstatt den Gekränkten zu spielen, sich zu verteidigen, sich zu rechtfertigen und um Verzeihung zu bitten oder wenigstens gleichmütig zu bleiben -- alles dies wäre noch besser gewesen als das, was er wirklich that -- verzogen sich seine Mienen ("Gehirnreflexe" dachte Stefan Arkadjewitsch, als Liebhaber von Physiologie) unwillkürlich und plötzlich zu seinem gewohnten, gutmütigen und daher ziemlich einfältigen Lächeln. |
| Since then she had refused to see her husband. | Dieses dumme Lächeln konnte er sich selbst nicht vergeben. |
| "It’s that idiotic smile that’s to blame for it all," thought Stepan Arkadyevitch. | Als Dolly es gewahrt hatte, erbebte sie, wie von einem physischen Schmerz, und erging sich dann mit der ihr eigenen Leidenschaftlichkeit in einem Strom bitterer Worte, worauf sie das Gemach verließ. |
| "But what’s to be done? What’s to be done?" he said to himself in despair, and found no answer. | Von dieser Zeit an wollte sie ihren Gatten nicht mehr sehen. |
| "An allem ist das dumme Lächeln schuld," dachte Stefan Arkadjewitsch. | |
| "Aber was soll ich thun, was soll ich thun?" frug er voll Verzweiflung sich selbst, ohne eine Antwort zu finden. |
You can see that the pipeline does not fully clean up the German text,
resulting in issues like the second sentence consisting of only --.
On a positive note, the split sentences in the German translation line
up correctly with the single English sentence. Overall, the pipeline
already works well, but there is still room for improvement.
Save the OpenVINO model to disk for future use:
from pathlib import Path
ov_model_path = Path("ov_model/model.xml")
ov.save_model(ov_model, ov_model_path)
To read the model from disk, use the read_model method of the
Core object:
ov_model = core.read_model(ov_model_path)
Speed up Embeddings Computation#
Let’s see how we can speed up the most computationally complex part of the pipeline - getting embeddings. You might wonder why, when using OpenVINO, you need to compile the model after reading it. There are two main reasons for this: 1. Compatibility with different devices. The model can be compiled to run on a specific device, like CPU, GPU or GNA. Each device may work with different data types, support different features, and gain performance by changing the neural network for a specific computing model. With OpenVINO, you do not need to store multiple copies of the network with optimized for different hardware. A universal OpenVINO model representation is enough. 1. Optimization for different scenarios. For example, one scenario prioritizes minimizing the time between starting and finishing model inference (latency-oriented optimization). In our case, it is more important how many texts per second the model can process (throughput-oriented optimization).
To get a throughput-optimized model, pass a performance hint as a configuration during compilation. Then OpenVINO selects the optimal parameters for execution on the available hardware.
from typing import Any
import openvino.properties.hint as hints
compiled_throughput_hint = core.compile_model(
ov_model,
device_name=device.value,
config={hints.performance_mode(): hints.PerformanceMode.THROUGHPUT},
)
To further optimize hardware utilization, let’s change the inference mode from synchronous (Sync) to asynchronous (Async). While the synchronous API may be easier to start with, it is recommended to use the asynchronous (callbacks-based) API in production code. It is the most general and scalable way to implement flow control for any number of requests.
To work in asynchronous mode, you need to define two things:
Instantiate an
AsyncInferQueue, which can then be populated with inference requests.Define a
callbackfunction that will be called after the output request has been executed and its results have been processed.
In addition to the model input, any data required for post-processing can be passed to the queue. We can create a zero embedding matrix in advance and fill it in as the inference requests are executed.
def get_embeddings_async(sentences: List[str], embedding_model: OVModel) -> np.ndarray:
def callback(infer_request: ov.InferRequest, user_data: List[Any]) -> None:
embeddings, idx, pbar = user_data
embedding = infer_request.get_output_tensor(0).data[0, 0]
embeddings[idx] = embedding
pbar.update()
infer_queue = ov.AsyncInferQueue(embedding_model)
infer_queue.set_callback(callback)
embedding_dim = embedding_model.output(0).get_partial_shape().get_dimension(2).get_length()
embeddings = np.zeros((len(sentences), embedding_dim))
with tqdm(total=len(sentences), disable=disable_tqdm) as pbar:
for idx, sent in enumerate(sentences):
tokenized = tokenizer(sent, return_tensors="np").data
infer_queue.start_async(tokenized, [embeddings, idx, pbar])
infer_queue.wait_all()
return embeddings
Let’s compare the models and plot the results.
Note: To get a more accurate benchmark, use the Benchmark Python Tool
number_of_chars = 15_000
more_sentences_en = splitter_en.segment(clean_text(anna_karenina_en[:number_of_chars]))
len(more_sentences_en)
0%| | 0/3 [00:00<?, ?it/s]
112
import pandas as pd
from time import perf_counter
benchmarks = [
(pt_model, get_embeddings, "PyTorch"),
(compiled_model, get_embeddings, "OpenVINO\nSync"),
(
compiled_throughput_hint,
get_embeddings_async,
"OpenVINO\nThroughput Hint\nAsync",
),
]
number_of_sentences = 100
benchmark_data = more_sentences_en[: min(number_of_sentences, len(more_sentences_en))]
benchmark_results = {name: [] for *_, name in benchmarks}
benchmarks_iterator = tqdm(benchmarks, leave=False, disable=disable_tqdm)
for model, func, name in benchmarks_iterator:
printable_name = name.replace("\n", " ")
benchmarks_iterator.set_description(f"Run benchmark for {printable_name} model")
for run in tqdm(range(10 + 1), leave=False, desc="Benchmark Runs: ", disable=disable_tqdm):
with disable_tqdm_context():
start = perf_counter()
func(benchmark_data, model)
end = perf_counter()
benchmark_results[name].append(len(benchmark_data) / (end - start))
benchmark_dataframe = pd.DataFrame(benchmark_results)[1:]
0%| | 0/3 [00:00<?, ?it/s]
Benchmark Runs: 0%| | 0/11 [00:00<?, ?it/s]
Benchmark Runs: 0%| | 0/11 [00:00<?, ?it/s]
Benchmark Runs: 0%| | 0/11 [00:00<?, ?it/s]
import openvino.properties as props
cpu_name = core.get_property("CPU", props.device.full_name)
plot = sns.barplot(benchmark_dataframe, errorbar="sd")
plot.set(ylabel="Sentences Per Second", title=f"Sentence Embeddings Benchmark\n{cpu_name}")
perf_ratio = benchmark_dataframe.mean() / benchmark_dataframe.mean()[0]
plot.spines["right"].set_visible(False)
plot.spines["top"].set_visible(False)
plot.spines["left"].set_visible(False)
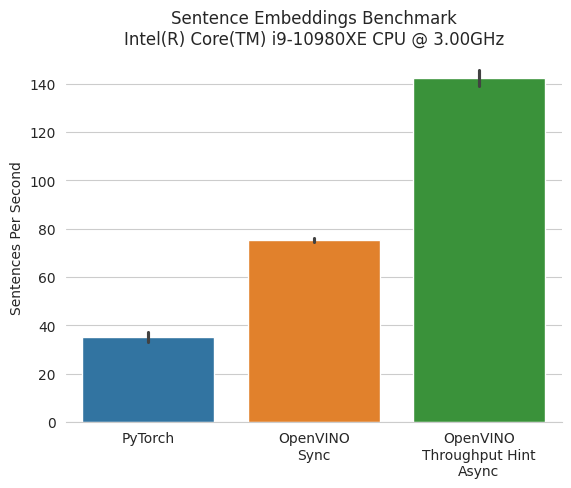
On an Intel Core i9-10980XE CPU, the OpenVINO model processed 45% more sentences per second compared with the original PyTorch model. Using Async mode with throughput hint, we get ×3.21 (or 221%) performance boost.
Here are useful links with information about the techniques used in this notebook: - OpenVINO performance hints - OpenVINO Async API - Throughput Optimizations