Scaling on a dual CPU socket server#
Note: This demo uses Docker and has been tested only on Linux hosts
Text generation in OpenVINO Model Server with continuous batching is most efficient on a single CPU socket. OpenVINO ensures the load to be constrained to a single NUMA node. That ensure fast memory access from the node and avoids intra socket communication.
The example below demonstrate how serving can be scaled on dual socket servers to double the throughout. It deploys two instances of the model server allocated to difference CPU sockets. The client calls are distributed used an Nginx proxy server with a load balancer.
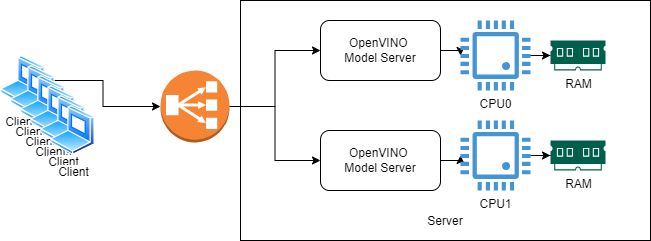
Start the Model Server instances#
Let’s assume we have two CPU sockets server with two NUMA nodes.
lscpu | grep NUMA
NUMA node(s): 2
NUMA node0 CPU(s): 0-31,64-95
NUMA node1 CPU(s): 32-63,96-127
Following the prework from demo start the instances like below:
docker run --cpuset-cpus $(lscpu | grep node0 | cut -d: -f2) -d --rm -p 8003:8003 -v $(pwd)/models:/workspace:ro openvino/model_server:latest --rest_port 8003 --config_path /workspace/config.json
docker run --cpuset-cpus $(lscpu | grep node1 | cut -d: -f2) -d --rm -p 8004:8004 -v $(pwd)/models:/workspace:ro openvino/model_server:latest --rest_port 8004 --config_path /workspace/config.json
Confirm in logs if the containers loaded the models successfully.
Start Nginx load balancer#
The configuration below is a basic example distributing the clients between two started instances.
stream {
upstream ovms-cluster {
least_conn;
server localhost:8003;
server localhost:8004;
}
server {
listen 80;
proxy_pass ovms-cluster;
}
}
Start the Nginx container with:
docker run -v $(pwd)/nginx.conf:/etc/nginx/nginx.conf:ro -d --net=host -p 80:80 nginx
Testing the scalability#
Start benchmarking script like in demo, pointing to the load balancer port and host.
python benchmark_serving.py --host localhost --port 80 --endpoint /v3/chat/completions --backend openai-chat --model meta-llama/Meta-Llama-3-8B-Instruct --dataset-path ShareGPT_V3_unfiltered_cleaned_split.json --num-prompts 2000 --request-rate inf --save-result --seed 10
Initial test run completed. Starting main benchmark run...
Traffic request rate: inf
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2000/2000 [08:08<00:00, 4.09it/s]
============ Serving Benchmark Result ============
Successful requests: 2000
Benchmark duration (s): 488.53
Total input tokens: 443650
Total generated tokens: 367462
Request throughput (req/s): 4.09
Output token throughput (tok/s): 752.18
Total Token throughput (tok/s): 1660.32
---------------Time to First Token----------------
Mean TTFT (ms): 188339.52
Median TTFT (ms): 186645.04
P99 TTFT (ms): 404661.83
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 253.62
Median TPOT (ms): 252.55
P99 TPOT (ms): 319.91
---------------Inter-token Latency----------------
Mean ITL (ms): 355.27
Median ITL (ms): 268.23
P99 ITL (ms): 1301.87
==================================================
Scaling in Kubernetes#
TBD