OpenVINO™ Model Server#
Model Server hosts models and makes them accessible to software components over standard network protocols: a client sends a request to the model server, which performs model inference and sends a response back to the client. Model Server offers many advantages for efficient model deployment:
Remote inference enables using lightweight clients with only the necessary functions to perform API calls to edge or cloud deployments.
Applications are independent of the model framework, hardware device, and infrastructure.
Client applications in any programming language that supports REST or gRPC calls can be used to run inference remotely on the model server.
Clients require fewer updates since client libraries change very rarely.
Model topology and weights are not exposed directly to client applications, making it easier to control access to the model.
Ideal architecture for microservices-based applications and deployments in cloud environments – including Kubernetes and OpenShift clusters.
Efficient resource utilization with horizontal and vertical inference scaling.
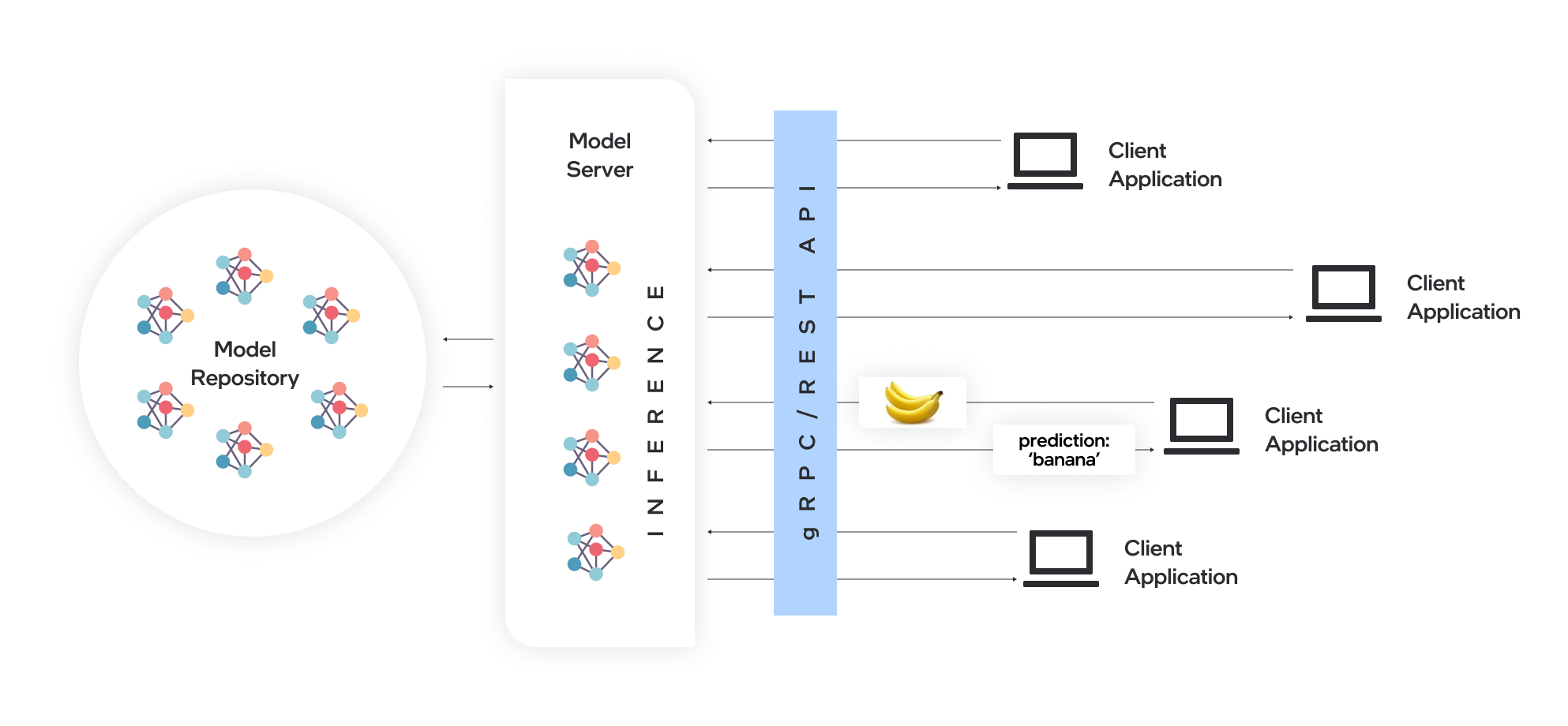
Serving with OpenVINO Model Server#
OpenVINO™ Model Server (OVMS) is a high-performance system for serving models. Implemented in C++ for scalability and optimized for deployment on Intel architectures, the model server uses the same architecture and API as TensorFlow Serving and KServe while applying OpenVINO for inference execution. Inference service is provided via gRPC or REST API, making deploying new algorithms and AI experiments easy.
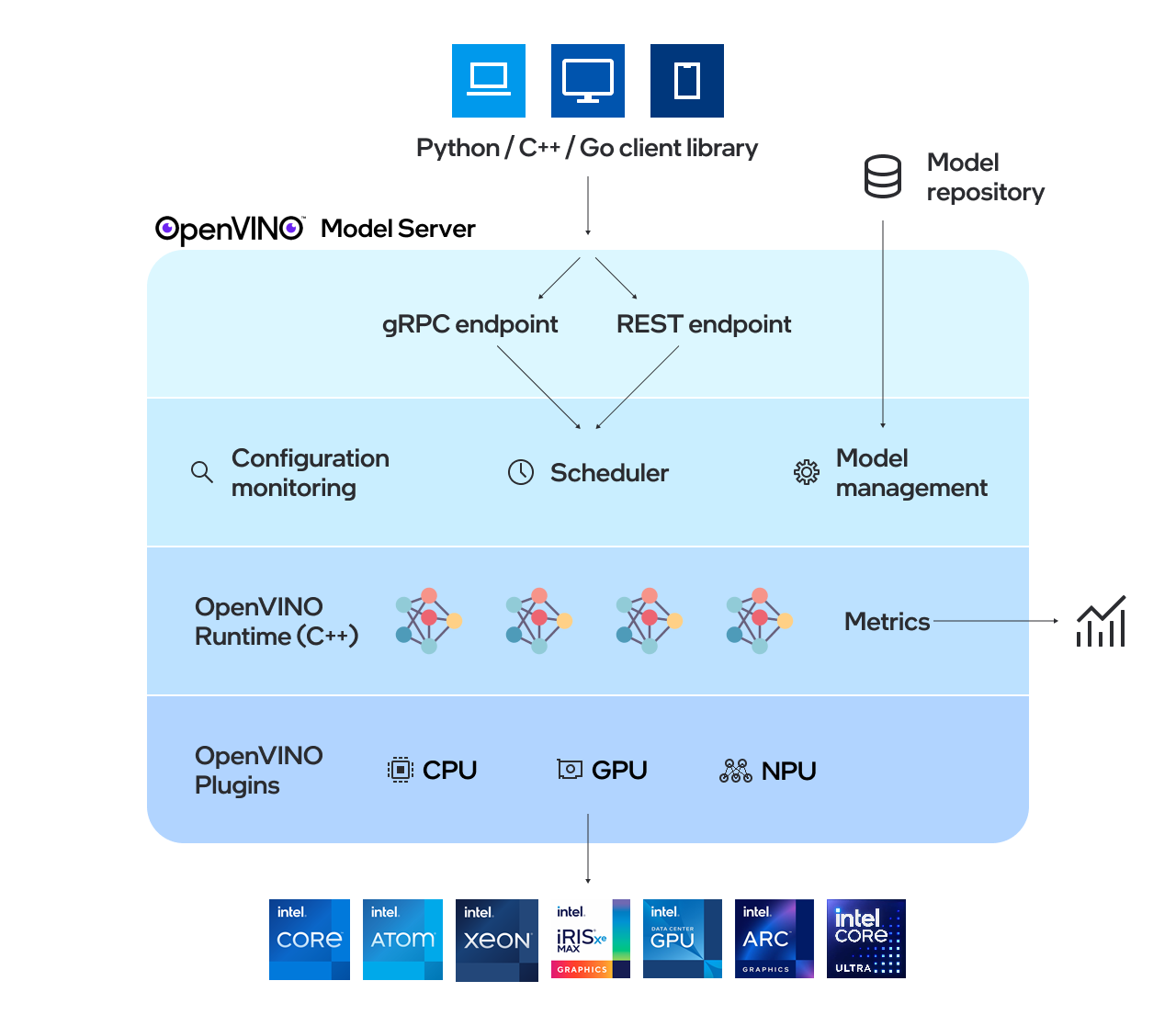
The models used by the server need to be stored locally or hosted remotely by object storage services. For more details, refer to Preparing Model Repository documentation. Model server works inside Docker containers, on Bare Metal, and in Kubernetes environment. Start using OpenVINO Model Server with a fast-forward serving example from the Quickstart guide or explore Model Server features.
Key features:#
Model management - including model versioning and model updates in runtime
Directed Acyclic Graph Scheduler along with custom nodes in DAG pipelines
Metrics - metrics compatible with Prometheus standard
Support for multiple frameworks, such as TensorFlow, PaddlePaddle and ONNX
Support for AI accelerators