Agentic AI with OpenVINO Model Server#
OpenVINO Model Server can be used to serve language models for AI Agents. It supports the usage of tools in the context of content generation. It can be integrated with MCP servers and AI agent frameworks. You can learn more about tools calling based on OpenAI API
Here are presented required steps to deploy language models trained for tools support. The diagram depicting the demo setup is below:
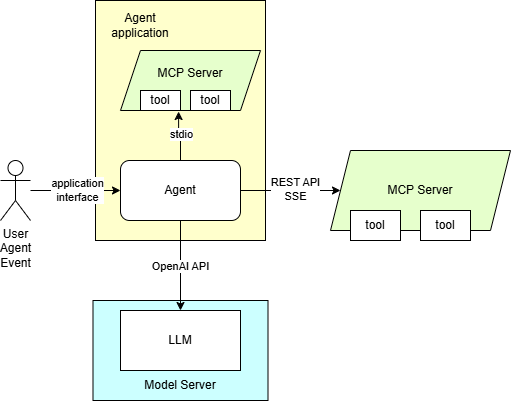
The application employing OpenAI agent SDK is using MCP server. It is equipped with a set of tools to providing context for the content generation. The tools can also be used for automation purposes based on input in text format.
Start MCP server with SSE interface#
Linux#
git clone https://github.com/isdaniel/mcp_weather_server
cd mcp_weather_server && git checkout v0.5.0
docker build -t mcp-weather-server:sse .
docker run -d -p 8080:8080 -e PORT=8080 mcp-weather-server:sse uv run python -m mcp_weather_server --mode sse
Windows#
On Windows the MCP server will be demonstrated as an instance with stdio interface inside the agent application. File system MCP server requires NodeJS and npx, visit https://nodejs.org/en/download. The weather MCP should be installed as python package:
pip install python-dateutil mcp_weather_server
Prepare the agent#
Install the application requirements
curl https://raw.githubusercontent.com/openvinotoolkit/model_server/main/demos/continuous_batching/agentic_ai/openai_agent.py -O -L
pip install openai-agents openai
Start OVMS#
This deployment procedure assumes the model was pulled or exported using the procedure above. The exception are models from OpenVINO organization if they support tools correctly with the default template like “OpenVINO/Qwen3-4B-int4-ov” - they can be deployed in a single command pulling and starting the server.
Deploying on Windows with GPU#
Assuming you have unpacked model server package with python enabled version, make sure to run setupvars script
as mentioned in deployment guide, in every new shell that will start OpenVINO Model Server.
Pull and start OVMS:
ovms.exe --rest_port 8000 --source_model OpenVINO/Qwen3-VL-8B-Instruct-int4-ov --model_repository_path c:\models --tool_parser hermes3 --target_device GPU --task text_generation --pipeline_type VLM_CB --cache_dir .cache --allowed_media_domains raw.githubusercontent.com
Use MCP server, with additional image of Gdańsk old town. VLM model deduces location and calls get_weather tool to summarize the weather conditions in the city.

Note: Image source: Link
python openai_agent.py --query "What is the current weather in location depicted in the image?" --image https://raw.githubusercontent.com/openvinotoolkit/model_server/refs/heads/releases/2026/1/demos/continuous_batching/agentic_ai/photo.jpeg --model OpenVINO/Qwen3-VL-8B-Instruct-int4-ov --base-url http://localhost:8000/v3 --mcp-server-url http://localhost:8080/sse --mcp-server weather
Exemplary output:
The current weather in Gdańsk is overcast with a temperature of 8.8°C (feels like 4.2°C). The relative humidity is 52%, and the wind is blowing from the SSW at 17.0 km/h with gusts up to 36.7 km/h. The atmospheric pressure is 1010.7 hPa with 84% cloud cover. The UV index is moderate at 3.5, and visibility is 40.9 km.
Pull and start OVMS:
ovms.exe --rest_port 8000 --source_model OpenVINO/Qwen3-4B-int4-ov --model_repository_path c:\models --tool_parser hermes3 --target_device GPU --task text_generation --cache_dir .cache
Use MCP server:
python openai_agent.py --query "What is the current weather in Tokyo?" --model OpenVINO/Qwen3-4B-int4-ov --base-url http://localhost:8000/v3 --mcp-server-url http://localhost:8080/sse --mcp-server weather
Exemplary output:
The current weather in Tokyo is overcast with a temperature of 9.4°C (feels like 6.4°C). The relative humidity is at 42%, and the dew point is at -2.9°C. Wind is blowing from the NE at 3.6 km/h with gusts up to 24.8 km/h. The atmospheric pressure is 1018.9 hPa with 84% cloud cover. Visibility is 24.1 km.
Pull and start OVMS:
ovms.exe --rest_port 8000 --source_model OpenVINO/Phi-4-mini-instruct-int4-ov --model_repository_path c:\models --tool_parser phi4 --target_device GPU --task text_generation --enable_tool_guided_generation true --cache_dir .cache --max_num_batched_tokens 99999
Use MCP server:
python openai_agent.py --query "What is the current weather in Tokyo?" --model OpenVINO/Phi-4-mini-instruct-int4-ov --base-url http://localhost:8000/v3 --mcp-server-url http://localhost:8080/sse --mcp-server weather --tool-choice required
Exemplary output:
The current weather in Tokyo is Overcast with a temperature of 9.4°C (feels like 6.4°C), relative humidity at 42%, and dew point at -2.9°C. Wind is blowing from the NE at 3.6 km/h with gusts up to 24.8 km/h. Atmospheric pressure is 1018.9 hPa with 84% cloud cover. Visibility is 24.1 km.
Pull and start OVMS:
ovms.exe --rest_port 8000 --source_model OpenVINO/Qwen3-30B-A3B-Instruct-2507-int4-ov --model_repository_path c:\models --tool_parser hermes3 --target_device GPU --task text_generation --cache_dir .cache
Use MCP server:
python openai_agent.py --query "What is the current weather in Tokyo?" --model OpenVINO/Qwen3-30B-A3B-Instruct-2507-int4-ov --base-url http://localhost:8000/v3 --mcp-server-url http://localhost:8080/sse --mcp-server weather
Exemplary output:
The current weather in Tokyo is Overcast with a temperature of 9.4°C (feels like 6.4°C), relative humidity at 42%, and dew point at -2.9°C. The wind is blowing from the northeast at 3.6 km/h with gusts up to 24.8 km/h. The atmospheric pressure is 1018.9 hPa with 84% cloud cover. Visibility is 24.1 km.
Vision Language MoE model (35B total / 3B active parameters). Requires OpenVINO 2026.2 or newer and a GPU with sufficient memory to fit the INT4 weights. Tested on PantherLake iGPU with 32GB RAM with iGPU allocation increase and B70 dGPU.
Pull and start OVMS:
ovms.exe --rest_port 8000 --source_model OpenVINO/Qwen3.6-35B-A3B-int4-ov --model_repository_path c:\models --reasoning_parser qwen3 --tool_parser qwen3coder --target_device GPU --task text_generation --cache_dir .cache --allowed_media_domains raw.githubusercontent.com
Use MCP server, with additional image of Gdańsk old town. VLM model deduces location and calls get_weather tool to summarize the weather conditions in the city.
Note: Image source: Link
python openai_agent.py --query "What is the current weather in location depicted in the image?" --image https://raw.githubusercontent.com/openvinotoolkit/model_server/refs/heads/releases/2026/1/demos/continuous_batching/agentic_ai/photo.jpeg --model OpenVINO/Qwen3.6-35B-A3B-int4-ov --base-url http://localhost:8000/v3 --mcp-server-url http://localhost:8080/sse --mcp-server weather
Pull and start OVMS:
ovms.exe --rest_port 8000 --source_model OpenVINO/gpt-oss-20b-int4-ov --model_repository_path c:\models --tool_parser gptoss --reasoning_parser gptoss --task text_generation --target_device GPU
Note: Continuous batching and paged attention are supported for GPT‑OSS. However, when deployed on GPU, the model may experience reduced accuracy under high‑concurrency workloads. This issue will be resolved in version 2026.1 and in the upcoming weekly release. CPU execution is not affected.
Use MCP server:
python openai_agent.py --query "What is the current weather in Tokyo?" --model OpenVINO/gpt-oss-20b-int4-ov --base-url http://localhost:8000/v3 --mcp-server-url http://localhost:8080/sse --mcp-server weather
Exemplary output:
**Tokyo Current Weather**
- **Condition:** Overcast
- **Temperature:** 9.4°C (feels like 6.4°C)
- **Humidity:** 42%
- **Dew Point:** 2.9°C
- **Wind:** 3.6km/h from the NE, gusts up to 24.8km/h
- **Pressure:** 1018.9hPa
- **Cloud Cover:** 84%
- **Visibility:** 24.1km
Let me know if you'd like forecast details or anything else!
Deploying on Windows with NPU#
Pull and start OVMS:
ovms.exe --rest_port 8000 --source_model OpenVINO/Qwen3-8B-int4-cw-ov --model_repository_path c:\models --tool_parser hermes3 --target_device NPU --task text_generation --cache_dir .cache --max_prompt_len 8000
Use MCP server:
python openai_agent.py --query "What is the current weather in Tokyo?" --model OpenVINO/Qwen3-8B-int4-cw-ov --base-url http://localhost:8000/v3 --mcp-server-url http://localhost:8080/sse --mcp-server weather
Exemplary output:
The current weather in Tokyo is overcast with a temperature of 9.4°C (feels like 6.4°C). The relative humidity is at 42%, and the dew point is at -2.9°C. The wind is blowing from the NE at 3.6 km/h, with gusts up to 24.8 km/h. The atmospheric pressure is 1018.9 hPa, and there is 84% cloud cover. Visibility is 24.1 km.
Pull and start OVMS:
ovms.exe --rest_port 8000 --source_model FluidInference/qwen3-4b-int4-ov-npu --model_repository_path c:\models --tool_parser hermes3 --target_device NPU --task text_generation --cache_dir .cache --max_prompt_len 8000
Use MCP server:
python openai_agent.py --query "What is the current weather in Tokyo?" --model OpenVINO/Qwen3-8B-int4-cw-ov --base-url http://localhost:8000/v3 --mcp-server-url http://localhost:8080/sse --mcp-server weather
Exemplary output:
The current weather in Tokyo is overcast with a temperature of 9.4°C (feels like 6.4°C). The relative humidity is at 42%, and the dew point is at -2.9°C. The wind is blowing from the NE at 3.6 km/h, with gusts up to 24.8 km/h. The atmospheric pressure is 1018.9 hPa, and there is 84% cloud cover. Visibility is 24.1 km.
Note: Setting the
--max_prompt_lenparameter too high may lead to performance degradation. It is recommended to use the smallest value that meets your requirements.
Deploying in a docker container on CPU#
Pull and start OVMS:
mkdir -p ${HOME}/models
docker run -d --user $(id -u):$(id -g) --rm -p 8000:8000 -v ${HOME}/models:/models openvino/model_server:weekly \
--rest_port 8000 --model_repository_path /models --source_model OpenVINO/Qwen3-VL-8B-Instruct-int4-ov --tool_parser hermes3 --task text_generation --pipeline_type VLM_CB --allowed_media_domains raw.githubusercontent.com
Use MCP server, with additional image of Gdańsk old town. VLM model deduces location and calls get_weather tool to summarize the weather conditions in the city.
Note: Image source: Link
python openai_agent.py --query "What is the current weather in location depicted in the image?" --image https://raw.githubusercontent.com/openvinotoolkit/model_server/refs/heads/releases/2026/1/demos/continuous_batching/agentic_ai/photo.jpeg --model OpenVINO/Qwen3-VL-8B-Instruct-int4-ov --base-url http://localhost:8000/v3 --mcp-server-url http://localhost:8080/sse --mcp-server weather
Exemplary output:
The current weather in Gdańsk is overcast with a temperature of 8.8°C (feels like 4.2°C). The relative humidity is 52%, and the wind is blowing from the SSW at 17.0 km/h with gusts up to 36.7 km/h. The atmospheric pressure is 1010.7 hPa with 84% cloud cover. The UV index is moderate at 3.5, and visibility is 40.9 km.
Pull and start OVMS:
mkdir -p ${HOME}/models
docker run -d --user $(id -u):$(id -g) --rm -p 8000:8000 -v ${HOME}/models:/models openvino/model_server:weekly \
--rest_port 8000 --model_repository_path /models --source_model OpenVINO/Qwen3-4B-int4-ov --tool_parser hermes3 --task text_generation
Use MCP server:
python openai_agent.py --query "What is the current weather in Tokyo?" --model OpenVINO/Qwen3-4B-int4-ov --base-url http://localhost:8000/v3 --mcp-server-url http://localhost:8080/sse --mcp-server weather
Exemplary output:
The current weather in Tokyo is overcast with a temperature of 9.4°C (feels like 6.4°C). The relative humidity is at 42%, and the dew point is at -2.9°C. Wind is blowing from the NE at 3.6 km/h with gusts up to 24.8 km/h. The atmospheric pressure is 1018.9 hPa with 84% cloud cover. Visibility is 24.1 km.
Pull and start OVMS:
mkdir -p ${HOME}/models
docker run -d --user $(id -u):$(id -g) --rm -p 8000:8000 -v ${HOME}/models:/models openvino/model_server:weekly \
--rest_port 8000 --model_repository_path /models --source_model OpenVINO/Phi-4-mini-instruct-int4-ov --tool_parser phi4 --task text_generation --max_num_batched_tokens 99999
Use MCP server:
python openai_agent.py --query "What is the current weather in Tokyo?" --model OpenVINO/Phi-4-mini-instruct-int4-ov --base-url http://localhost:8000/v3 --mcp-server-url http://localhost:8080/sse --mcp-server weather --tool-choice required
Exemplary output:
The current weather in Tokyo is as follows: The sky is mostly covered with clouds, and the temperature is 9.4°C, which feels like 6.4°C due to the humidity. The air is relatively dry with a humidity level of 42%, and the dew point is -2.9°C, indicating that the air is not very moist. The wind is coming from the northeast at a gentle pace of 3.6 km/h, but it can get quite gusty, reaching speeds of up to 24.8 km/h. The atmospheric pressure is 1018.9 hPa, which is slightly lower than average, and the sky is mostly cloudy with 84% cloud cover. Visibility is good at 24.1 km, so you can see quite a distance.
Pull and start OVMS:
mkdir -p ${HOME}/models
docker run -d --user $(id -u):$(id -g) --rm -p 8000:8000 -v ${HOME}/models:/models openvino/model_server:weekly \
--rest_port 8000 --source_model OpenVINO/Qwen3-30B-A3B-Instruct-2507-int4-ov --model_repository_path /models --tool_parser hermes3 --task text_generation
Use MCP server:
python openai_agent.py --query "What is the current weather in Tokyo?" --model OpenVINO/Qwen3-30B-A3B-Instruct-2507-int4-ov --base-url http://localhost:8000/v3 --mcp-server-url http://localhost:8080/sse --mcp-server weather
Exemplary output:
The current weather in Tokyo is overcast with a temperature of 9.4°C (feels like 6.4°C). The relative humidity is 42%, and the dew point is -2.9°C. Wind is blowing from the northeast at 3.6 km/h, with gusts up to 24.8 km/h. The atmospheric pressure is 1018.9 hPa, and there is 84% cloud cover. Visibility is 24.1 km.
Vision Language MoE model (35B total / 3B active parameters). Requires OpenVINO 2026.2 or newer and enough host memory to fit the INT4 weights. Tested on PantherLake iGPU with 32GB RAM with iGPU allocation increase and B70 dGPU.
Pull and start OVMS:
mkdir -p ${HOME}/models
docker run -d --user $(id -u):$(id -g) --rm -p 8000:8000 -v ${HOME}/models:/models openvino/model_server:weekly \
--rest_port 8000 --source_model OpenVINO/Qwen3.6-35B-A3B-int4-ov --model_repository_path /models --reasoning_parser qwen3 --tool_parser qwen3coder --task text_generation --allowed_media_domains raw.githubusercontent.com
Use MCP server, with additional image of Gdańsk old town. VLM model deduces location and calls get_weather tool to summarize the weather conditions in the city.
Note: Image source: Link
python openai_agent.py --query "What is the current weather in location depicted in the image?" --image https://raw.githubusercontent.com/openvinotoolkit/model_server/refs/heads/releases/2026/1/demos/continuous_batching/agentic_ai/photo.jpeg --model OpenVINO/Qwen3.6-35B-A3B-int4-ov --base-url http://localhost:8000/v3 --mcp-server-url http://localhost:8080/sse --mcp-server weather
Pull and start OVMS:
mkdir -p ${HOME}/models
docker run -d --user $(id -u):$(id -g) --rm -p 8000:8000 -v ${HOME}/models:/models openvino/model_server:weekly \
--rest_port 8000 --source_model OpenVINO/gpt-oss-20b-int4-ov --model_repository_path /models \
--tool_parser gptoss --reasoning_parser gptoss --task text_generation
Use MCP server:
python openai_agent.py --query "What is the current weather in Tokyo?" --model OpenVINO/gpt-oss-20b-int4-ov --base-url http://localhost:8000/v3 --mcp-server-url http://localhost:8080/sse --mcp-server weather
Exemplary output:
**Tokyo Current Weather**
- **Condition:** Overcast
- **Temperature:** 9.4°C (feels like 6.4°C)
- **Humidity:** 42%
- **Dew Point:** 2.9°C
- **Wind:** 3.6km/h from the NE, gusts up to 24.8km/h
- **Pressure:** 1018.9hPa
- **Cloud Cover:** 84%
- **Visibility:** 24.1km
Let me know if you’d like more details (e.g., forecast, precipitation chance, or air‑quality info).
Deploying in a docker container on GPU#
In case you want to use GPU device to run the generation, add extra docker parameters --device /dev/dri --group-add=$(stat -c "%g" /dev/dri/render* | head -n 1)
to docker run command, use the image with GPU support. Export the models with precision matching the GPU capacity and adjust pipeline configuration.
It can be applied using the commands below:
Pull and start OVMS:
mkdir -p ${HOME}/models
docker run -d --user $(id -u):$(id -g) --rm -p 8000:8000 -v ${HOME}/models:/models --device /dev/dri --group-add=$(stat -c "%g" /dev/dri/render* | head -n 1) openvino/model_server:weekly \
--rest_port 8000 --model_repository_path /models --source_model OpenVINO/Qwen3-VL-8B-Instruct-int4-ov --tool_parser hermes3 --target_device GPU --task text_generation --pipeline_type VLM_CB --allowed_media_domains raw.githubusercontent.com
Use MCP server, with additional image of Gdańsk old town. VLM model deduces location and calls get_weather tool to summarize the weather conditions in the city.
Note: Image source: Link
python openai_agent.py --query "What is the current weather in location depicted in the image?" --image https://raw.githubusercontent.com/openvinotoolkit/model_server/refs/heads/releases/2026/1/demos/continuous_batching/agentic_ai/photo.jpeg --model OpenVINO/Qwen3-VL-8B-Instruct-int4-ov --base-url http://localhost:8000/v3 --mcp-server-url http://localhost:8080/sse --mcp-server weather
Exemplary output:
The current weather in Gdańsk is overcast with a temperature of 8.8°C (feels like 4.2°C). The relative humidity is 52%, and the wind is blowing from the SSW at 17.0 km/h with gusts up to 36.7 km/h. The atmospheric pressure is 1010.7 hPa with 84% cloud cover. The UV index is moderate at 3.5, and visibility is 40.9 km.
Pull and start OVMS:
mkdir -p ${HOME}/models
docker run -d --user $(id -u):$(id -g) --rm -p 8000:8000 -v ${HOME}/models:/models --device /dev/dri --group-add=$(stat -c "%g" /dev/dri/render* | head -n 1) openvino/model_server:weekly \
--rest_port 8000 --model_repository_path /models --source_model OpenVINO/Qwen3-4B-int4-ov --tool_parser hermes3 --target_device GPU --task text_generation
Use MCP server:
python openai_agent.py --query "What is the current weather in Tokyo?" --model OpenVINO/Qwen3-4B-int4-ov --base-url http://localhost:8000/v3 --mcp-server-url http://localhost:8080/sse --mcp-server weather
Exemplary output:
The current weather in Tokyo is overcast with a temperature of 9.4°C (feels like 6.4°C). The relative humidity is at 42%, and the dew point is at -2.9°C. Wind is blowing from the NE at 3.6 km/h with gusts up to 24.8 km/h. The atmospheric pressure is 1018.9 hPa with 84% cloud cover. Visibility is 24.1 km.
Pull and start OVMS:
mkdir -p ${HOME}/models
docker run -d --user $(id -u):$(id -g) --rm -p 8000:8000 -v ${HOME}/models:/models --device /dev/dri --group-add=$(stat -c "%g" /dev/dri/render* | head -n 1) openvino/model_server:weekly \
--rest_port 8000 --model_repository_path /models --source_model OpenVINO/Phi-4-mini-instruct-int4-ov --tool_parser phi4 --task text_generation --target_device GPU --max_num_batched_tokens 99999
Use MCP server:
python openai_agent.py --query "What is the current weather in Tokyo?" --model OpenVINO/Phi-4-mini-instruct-int4-ov --base-url http://localhost:8000/v3 --mcp-server-url http://localhost:8080/sse --mcp-server weather --tool-choice required
Exemplary output:
The current weather in Tokyo is overcast with a temperature of 9.4°C (feels like 6.4°C). The relative humidity is 42%, and the dew point is -2.9°C. Wind is blowing from the northeast at 3.6 km/h, with gusts up to 24.8 km/h. The atmospheric pressure is 1018.9 hPa, and there is 84% cloud cover. Visibility is 24.1 km.
Pull and start OVMS:
mkdir -p ${HOME}/models
docker run -d --user $(id -u):$(id -g) --rm -p 8000:8000 -v ${HOME}/models:/models --device /dev/dri --group-add=$(stat -c "%g" /dev/dri/render* | head -n 1) openvino/model_server:weekly \
--rest_port 8000 --source_model OpenVINO/Qwen3-30B-A3B-Instruct-2507-int4-ov --model_repository_path /models --tool_parser hermes3 --target_device GPU --task text_generation --enable_tool_guided_generation true
Use MCP server:
python openai_agent.py --query "What is the current weather in Tokyo?" --model OpenVINO/Qwen3-30B-A3B-Instruct-2507-int4-ov --base-url http://localhost:8000/v3 --mcp-server-url http://localhost:8080/sse --mcp-server weather
Exemplary output:
The current weather in Tokyo is overcast with a temperature of 9.4°C (feels like 6.4°C). The relative humidity is 42%, and the dew point is -2.9°C. Wind is blowing from the northeast at 3.6 km/h, with gusts up to 24.8 km/h. The atmospheric pressure is 1018.9 hPa, and there is 84% cloud cover. Visibility is 24.1 km.
Vision Language MoE model (35B total / 3B active parameters). Requires OpenVINO 2026.2 or newer and a GPU with sufficient memory to fit the INT4 weights. Tested on PantherLake iGPU with 32GB RAM with iGPU allocation increase and B70 dGPU.
Pull and start OVMS:
mkdir -p ${HOME}/models
docker run -d --user $(id -u):$(id -g) --rm -p 8000:8000 -v ${HOME}/models:/models --device /dev/dri --group-add=$(stat -c "%g" /dev/dri/render* | head -n 1) openvino/model_server:weekly \
--rest_port 8000 --source_model OpenVINO/Qwen3.6-35B-A3B-int4-ov --model_repository_path /models --reasoning_parser qwen3 --tool_parser qwen3coder --target_device GPU --task text_generation --allowed_media_domains raw.githubusercontent.com
Use MCP server, with additional image of Gdańsk old town. VLM model deduces location and calls get_weather tool to summarize the weather conditions in the city.
Note: Image source: Link
python openai_agent.py --query "What is the current weather in location depicted in the image?" --image https://raw.githubusercontent.com/openvinotoolkit/model_server/refs/heads/releases/2026/1/demos/continuous_batching/agentic_ai/photo.jpeg --model OpenVINO/Qwen3.6-35B-A3B-int4-ov --base-url http://localhost:8000/v3 --mcp-server-url http://localhost:8080/sse --mcp-server weather
Pull and start OVMS:
mkdir -p ${HOME}/models
docker run -d --user $(id -u):$(id -g) --rm -p 8000:8000 -v ${HOME}/models:/models --device /dev/dri --group-add=$(stat -c "%g" /dev/dri/render* | head -n 1) openvino/model_server:weekly \
--rest_port 8000 --source_model OpenVINO/gpt-oss-20b-int4-ov --model_repository_path /models \
--tool_parser gptoss --reasoning_parser gptoss --target_device GPU --task text_generation
Note: Continuous batching and paged attention are supported for GPT‑OSS. However, when deployed on GPU, the model may experience reduced accuracy under high‑concurrency workloads. This issue will be resolved in version 2026.1 and in the upcoming weekly release. CPU execution is not affected.
Use MCP server:
python openai_agent.py --query "What is the current weather in Tokyo?" --model OpenVINO/gpt-oss-20b-int4-ov --base-url http://localhost:8000/v3 --mcp-server-url http://localhost:8080/sse --mcp-server weather
Exemplary output:
**Tokyo Current Weather**
- **Condition:** Overcast
- **Temperature:** 9.4°C (feels like 6.4°C)
- **Humidity:** 42%
- **Dew Point:** 2.9°C
- **Wind:** 3.6km/h from the NE, gusts up to 24.8km/h
- **Pressure:** 1018.9hPa
- **Cloud Cover:** 84%
- **Visibility:** 24.1km
Let me know if you'd like forecast details or anything else!
Deploying in a docker container on NPU#
The case of NPU is similar to GPU, but --device should be set to /dev/accel, --group-add parameter should be the same.
Running docker run command, use the image with GPU support. Export the models with precision matching the NPU capacity and adjust pipeline configuration.
It can be applied using the commands below:
Pull and start OVMS:
mkdir -p ${HOME}/models
docker run -d --user $(id -u):$(id -g) --rm -p 8000:8000 -v ${HOME}/models:/models --device /dev/accel --group-add=$(stat -c "%g" /dev/dri/render* | head -1) openvino/model_server:weekly \
--rest_port 8000 --model_repository_path /models --source_model OpenVINO/Qwen3-8B-int4-cw-ov --tool_parser hermes3 --target_device NPU --task text_generation --max_prompt_len 8000
Use MCP server:
python openai_agent.py --query "What is the current weather in Tokyo?" --model OpenVINO/Qwen3-8B-int4-cw-ov --base-url http://localhost:8000/v3 --mcp-server-url http://localhost:8080/sse --mcp-server weather
Exemplary output:
The current weather in Tokyo is overcast with a temperature of 9.4°C (feels like 6.4°C). The relative humidity is at 42%, and the dew point is at -2.9°C. The wind is blowing from the NE at 3.6 km/h with gusts up to 24.8 km/h. The atmospheric pressure is 1018.9 hPa with 84% cloud cover, and the visibility is 24.1 km.
Pull and start OVMS:
mkdir -p ${HOME}/models
docker run -d --user $(id -u):$(id -g) --rm -p 8000:8000 -v ${HOME}/models:/models --device /dev/accel --group-add=$(stat -c "%g" /dev/dri/render* | head -n 1) openvino/model_server:weekly \
--rest_port 8000 --model_repository_path /models --source_model FluidInference/qwen3-4b-int4-ov-npu --tool_parser hermes3 --target_device NPU --task text_generation --max_prompt_len 8000
Use MCP server:
python openai_agent.py --query "What is the current weather in Tokyo?" --model FluidInference/qwen3-4b-int4-ov-npu --base-url http://localhost:8000/v3 --mcp-server-url http://localhost:8080/sse --mcp-server weather --stream
Exemplary output:
The current weather in Tokyo is overcast with a temperature of 9.4°C (feels like 6.4°C). The relative humidity is at 42%, and the dew point is at -2.9°C. The wind is blowing from the NE at 3.6 km/h with gusts up to 24.8 km/h. The atmospheric pressure is 1018.9 hPa with 84% cloud cover, and the visibility is 24.1 km.
Note: The tool checking the weather forecast in the demo is making a remote call to a REST API server. Make sure you have internet connection and proxy configured while running the agent.
Note: For more interactive mode you can run the application with streaming enabled by providing
--streamparameter to the script.
Using Llama index agentic framework#
Pull and start OVMS:
mkdir -p ${HOME}/models
docker run -d --user $(id -u):$(id -g) --rm -p 8000:8000 -v ${HOME}/models:/models openvino/model_server:weekly \
--rest_port 8000 --model_repository_path /models --source_model OpenVINO/Qwen3-8B-int4-ov --tool_parser hermes3 --task text_generation
You can try also similar implementation based on llama_index library working the same way like openai-agent:
pip install llama-index-llms-openai-like==0.5.3 llama-index-core==0.14.5 llama-index-tools-mcp==0.4.2
curl https://raw.githubusercontent.com/openvinotoolkit/model_server/main/demos/continuous_batching/agentic_ai/llama_index_agent.py -o llama_index_agent.py
python llama_index_agent.py --query "What is the current weather in Tokyo?" --model OpenVINO/Qwen3-8B-int4-ov --base-url http://localhost:8000/v3 --mcp-server-url http://localhost:8080/sse --mcp-server weather --stream --enable-thinking
Testing accuracy#
Testing model accuracy is critical for a successful adoption in AI application. The recommended methodology is to use BFCL tool like describe in the testing guide. Here is example of the response from the OpenVINO/Qwen3-8B-int4-ov model:
--test-category simple_python
{"accuracy": 0.9525, "correct_count": 381, "total_count": 400}
--test-category multiple
{"accuracy": 0.89, "correct_count": 178, "total_count": 200}
--test-category parallel
{"accuracy": 0.89, "correct_count": 178, "total_count": 200}
--test-category irrelevance
{"accuracy": 0.825, "correct_count": 198, "total_count": 240}
Models can be also compared using the leaderboard reports.
Export and quantize model#
Use those steps to convert the model from HuggingFace Hub to OpenVINO format and export it to a local storage.
# Download export script, install its dependencies and create directory for the models
curl https://raw.githubusercontent.com/openvinotoolkit/model_server/refs/heads/main/demos/common/export_models/export_model.py -o export_model.py
pip3 install -r https://raw.githubusercontent.com/openvinotoolkit/model_server/refs/heads/main/demos/common/export_models/requirements.txt
mkdir models
Run export_model.py script to download and quantize the model:
Note: The users in China need to set environment variable HF_ENDPOINT=”https://hf-mirror.com” or “https://www.modelscope.cn/models” before running the export script to connect to the HF Hub.
python export_model.py text_generation --source_model meta-llama/Llama-3.2-3B-Instruct --weight-format int4 --config_file_path models/config.json --model_repository_path models --tool_parser llama3
curl -L -o models/meta-llama/Llama-3.2-3B-Instruct/chat_template.jinja https://raw.githubusercontent.com/vllm-project/vllm/refs/tags/v0.9.0/examples/tool_chat_template_llama3.2_json.jinja
Note: To use these models on NPU, set
--weight-formatto either int4 or nf4. When specifying--extra_quantization_params, ensure thatratiois set to 1.0 andgroup_sizeis set to -1 or 128. For example:
python export_model.py text_generation --source_model meta-llama/Llama-3.2-3B-Instruct --weight-format nf4 --config_file_path models/config.json --model_repository_path models --tool_parser llama3 --extra_quantization_params "--library transformers --sym group_size -1"
For more details, see OpenVINO GenAI on NPU.