formula-recognition-medium-scan-0001 (composite)¶
Use Case and High-Level Description¶
This is an im2latex composite model that recognizes latex formulas.
The model uses vocabulary file vocab.json to predict sequence of latex tokens.
The model is built on the ResNeXt-50 backbone with additional attention-based text recognition head.
Vocabulary file is downloaded tp corresponding model directory, <models_dir>/models/intel/formula-recognition-medium-scan-0001/formula-recognition-medium-scan-0001-im2latex-decoder/vocab.json. Model can predict big and small letters, numbers, some greek letters, trigonometric functions (e.g. cos, sin, coth), logarithmic function, sqrt and superscript.
Example of the input data¶
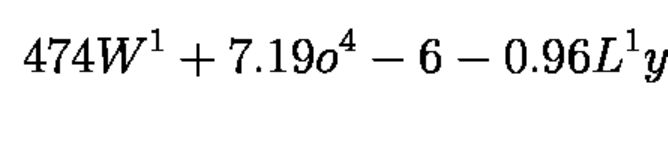
Example of the output¶
4 7 4 W ^ { 1 } + 7 . 1 9 o ^ { 4 } - 6 - 0 . 9 6 L ^ { 1 } y
Composite model specification¶
Metric |
Value |
|---|---|
im2latex_medium_photographed dataset, im2latex-match-images metric |
81.5% |
im2latex_medium_rendered dataset, im2latex-match-images metric |
95.7% |
Source framework |
PyTorch* |
Im2latex-match-images metric is calculated by <omz_dir>/tools/accuracy_checker/openvino/tools/accuracy_checker/metrics/im2latex_images_match.py
Encoder model specification¶
The formula-recognition-medium-scan-0001-encoder model is a ResNeXt-50 like backbone with some initialization layers for decoder
Metric |
Value |
|---|---|
GFlops |
16.56 |
MParams |
1.69 |
Inputs¶
Image, name: imgs, shape: 1, 3, 160, 1400 in the 1, C, H, W format, where:
C- number of channelsH- image heightW- image width
The expected channel order is BGR.
Outputs¶
Name:
hidden, shape:1, 512. Initial context state of the LSTM cell.Name:
context, shape:1, 512. Initial hidden state of the LSTM cell.Name:
init_0, shape:1, 256. Initial state of the decoder.Name:
row_enc_out, shape:1, 20, 75, 512. Features from encoder that are fed to a decoder.
Decoder model specification¶
The formula-recognition-medium-scan-0001-decoder model is an LSTM based decoder with attention module.
Metric |
Value |
|---|---|
GFlops |
1.86 |
MParams |
2.56 |
Inputs¶
Name:
dec_st_c, shape:1, 512. Current context state of the LSTM cell.Name:
dec_st_h, shape:1, 512. Current hidden state of the LSTM cell.Name:
output_prev, shape:1, 256. Current state of the decoder.Name:
row_enc_out, shape:1, 20, 175, 512. Encoded features.Name:
tgt, shape:1, 1. Index of the previous symbol.
Outputs¶
Name:
dec_st_c, shape:1, 512. Current context state of the LSTM cell.Name:
dec_st_h, shape:1, 512. Current hidden state of the LSTM cell.Name:
output, shape:1, 256. Current state of the decoder.Name:
logit, shape:1, Vocab_Size. Classification confidence scores in the [0, 1] range for every token.
Demo usage¶
The model can be used in the following demos provided by the Open Model Zoo to show its capabilities:
Legal Information¶
[*] Other names and brands may be claimed as the property of others.