The CPU plugin was developed in order to provide opportunity for high performance scoring of neural networks on CPU, using the Intel® Math Kernel Library for Deep Neural Networks (Intel® MKL-DNN).
Currently, the CPU plugin uses Intel® Threading Building Blocks (Intel® TBB) in order to parallelize calculations. Please refer to the Optimization Guide for associated performance considerations.
The set of supported layers can be expanded with the Extensibility mechanism.
OpenVINO™ toolkit is officially supported and validated on the following platforms:
| Host | OS (64-bit) |
|---|---|
| Development | Ubuntu* 18.04, CentOS* 7.5, MS Windows* 10 |
| Target | Ubuntu* 18.04, CentOS* 7.5, MS Windows* 10 |
The CPU Plugin supports inference on Intel® Xeon® with Intel® Advanced Vector Extensions 2 (Intel® AVX2), Intel® Advanced Vector Extensions 512 (Intel® AVX-512), and AVX512_BF16, Intel® Core™ Processors with Intel® AVX2, Intel Atom® Processors with Intel® Streaming SIMD Extensions (Intel® SSE).
You can use -pc the flag for samples to know which configuration is used by some layer. This flag shows execution statistics that you can use to get information about layer name, execution status, layer type, execution time, and the type of the execution primitive.
CPU plugin supports several graph optimization algorithms, such as fusing or removing layers. Refer to the sections below for details.
NOTE: For layer descriptions, see the IR Notation Reference.
CPU plugin follows default optimization approach. This approach means that inference is made with lower precision if it is possible on a given platform to reach better performance with acceptable range of accuracy.
NOTE: For details, see the Using Bfloat16 Inference.
Merge of a Convolution layer and any of the simple layers listed below:
NOTE: You can have any number and order of simple layers.
A combination of a Convolution layer and simple layers results in a single fused layer called Convolution:
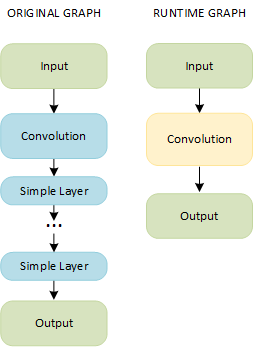
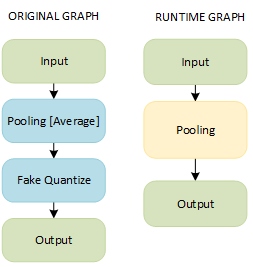
A combination of Pooling and FakeQuantize layers results in a single fused layer called Pooling:
A combination of FullyConnected and Activation layers results in a single fused layer called FullyConnected:
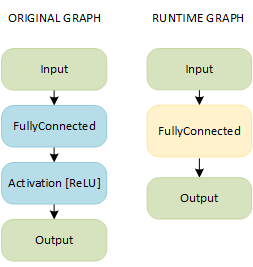
NOTE: This pattern is possible only on CPUs with support of Streaming SIMD Extensions 4.2 (SSE 4.2) and Intel AVX2 Instruction Set Architecture (ISA).
A combination of a group of a Convolution (or Binary Convolution) layer and simple layers and a group of a Depthwise Convolution layer and simple layers results in a single layer called Convolution (or Binary Convolution):
NOTE: Depthwise convolution layers should have the same values for the
group, input channels, and output channels parameters.
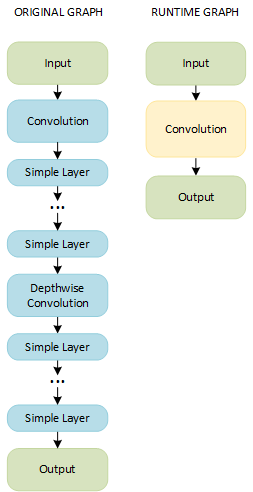
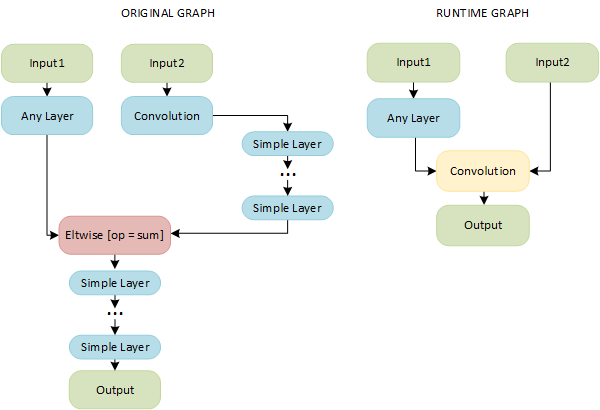
A combination of Convolution, Simple, and Eltwise layers with the sum operation results in a single layer called Convolution:
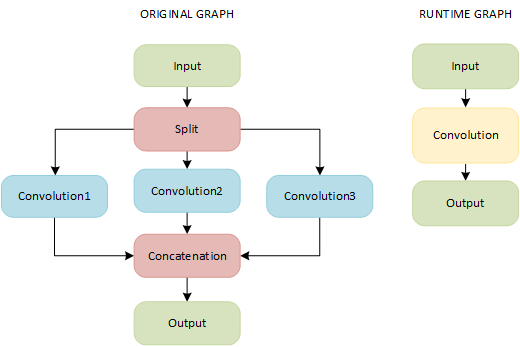
If a topology contains the following pipeline, a CPU plugin merges Split, Convolution, and Concatenation layers into a single Convolution layer with the group parameter:
NOTE: Parameters of the Convolution layers must coincide.
CPU plugin removes a Power layer from a topology if it has the following parameters:
The plugin supports the configuration parameters listed below. All parameters must be set with the InferenceEngine::Core::LoadNetwork() method. When specifying key values as raw strings (that is, when using Python API), omit the KEY_ prefix. Refer to the OpenVINO samples for usage examples: Benchmark App.
These are general options, also supported by other plugins:
| Parameter name | Parameter values | Default | Description |
|---|---|---|---|
| KEY_EXCLUSIVE_ASYNC_REQUESTS | YES/NO | NO | Forces async requests (also from different executable networks) to execute serially. This prevents potential oversubscription |
| KEY_PERF_COUNT | YES/NO | NO | Enables gathering performance counters |
CPU-specific settings:
| Parameter name | Parameter values | Default | Description |
|---|---|---|---|
| KEY_CPU_THREADS_NUM | positive integer values | 0 | Specifies the number of threads that CPU plugin should use for inference. Zero (default) means using all (logical) cores |
| KEY_CPU_BIND_THREAD | YES/NUMA/NO | YES | Binds inference threads to CPU cores. 'YES' (default) binding option maps threads to cores - this works best for static/synthetic scenarios like benchmarks. The 'NUMA' binding is more relaxed, binding inference threads only to NUMA nodes, leaving further scheduling to specific cores to the OS. This option might perform better in the real-life/contended scenarios. Note that for the latency-oriented cases (number of the streams is less or equal to the number of NUMA nodes, see below) both YES and NUMA options limit number of inference threads to the number of hardware cores (ignoring hyper-threading) on the multi-socket machines. |
| KEY_CPU_THROUGHPUT_STREAMS | KEY_CPU_THROUGHPUT_NUMA, KEY_CPU_THROUGHPUT_AUTO, or positive integer values | 1 | Specifies number of CPU "execution" streams for the throughput mode. Upper bound for the number of inference requests that can be executed simultaneously. All available CPU cores are evenly distributed between the streams. The default value is 1, which implies latency-oriented behavior for single NUMA-node machine, with all available cores processing requests one by one. On the multi-socket (multiple NUMA nodes) machine, the best latency numbers usually achieved with a number of streams matching the number of NUMA-nodes. KEY_CPU_THROUGHPUT_NUMA creates as many streams as needed to accommodate NUMA and avoid associated penalties. KEY_CPU_THROUGHPUT_AUTO creates bare minimum of streams to improve the performance; this is the most portable option if you don't know how many cores your target machine has (and what would be the optimal number of streams). Note that your application should provide enough parallel slack (for example, run many inference requests) to leverage the throughput mode. Non-negative integer value creates the requested number of streams. If a number of streams is 0, no internal streams are created and user threads are interpreted as stream master threads. |
| KEY_ENFORCE_BF16 | YES/NO | YES | The name for setting to execute in bfloat16 precision whenever it is possible. This option lets plugin know to downscale the precision where it sees performance benefits from bfloat16 execution. Such option does not guarantee accuracy of the network, you need to verify the accuracy in this mode separately, based on performance and accuracy results. It should be your decision whether to use this option or not. |
NOTE: To disable all internal threading, use the following set of configuration parameters:
KEY_CPU_THROUGHPUT_STREAMS=0,KEY_CPU_THREADS_NUM=1,KEY_CPU_BIND_THREAD=NO.
