Inference Engine with the bfloat16 inference implemented on CPU must support the native avx512_bf16 instruction and therefore the bfloat16 data format. It is possible to use bfloat16 inference in simulation mode on platforms with Intel® Advanced Vector Extensions 512 (Intel® AVX-512), but it leads to significant performance degradation in comparison with FP32 or native avx512_bf16 instruction usage.
Bfloat16 computations (referred to as BF16) is the Brain Floating-Point format with 16 bits. This is a truncated 16-bit version of the 32-bit IEEE 754 single-precision floating-point format FP32. BF16 preserves 8 exponent bits as FP32 but reduces precision of the sign and mantissa from 24 bits to 8 bits.
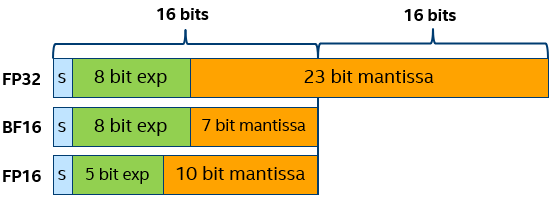
Preserving the exponent bits keeps BF16 to the same range as the FP32 (~1e-38 to ~3e38). This simplifies conversion between two data types: you just need to skip or flush to zero 16 low bits. Truncated mantissa leads to occasionally less precision, but according to investigations, neural networks are more sensitive to the size of the exponent than the mantissa size. Also, in lots of models, precision is needed close to zero but not so much at the maximum range. Another useful feature of BF16 is possibility to encode INT8 in BF16 without loss of accuracy, because INT8 range completely fits in BF16 mantissa field. It reduces data flow in conversion from INT8 input image data to BF16 directly without intermediate representation in FP32, or in combination of INT8 inference and BF16 layers.
See the Intel's site for more bfloat16 format details.
There are two ways to check if CPU device can support bfloat16 computations for models:
lscpu | grep avx512_bf16 or cat /proc/cpuinfo | grep avx512_bf16.METRIC_KEY(OPTIMIZATION_CAPABILITIES), which should return BF16 in the list of CPU optimization options:Current Inference Engine solution for bfloat16 inference uses Intel® Math Kernel Library for Deep Neural Networks (Intel® MKL-DNN) and supports inference of the significant number of layers in BF16 computation mode.
Lowering precision to increase performance is widely used for optimization of inference. The bfloat16 data type usage on CPU for the first time opens the possibility of default optimization approach. The embodiment of this approach is to use the optimization capabilities of the current platform to achieve maximum performance while maintaining the accuracy of calculations within the acceptable range.
Bfloat16 data usage provides the following benefits that increase performance:
For default optimization on CPU, source model is converted from FP32 or FP16 to BF16 and executed internally on platforms with native BF16 support. In this case, KEY_ENFORCE_BF16 is set to YES. The code below demonstrates how to check if the key is set:
To disable BF16 internal transformations, set the KEY_ENFORCE_BF16 to NO. In this case, the model infers as is without modifications with precisions that were set on each layer edge.
To disable BF16 in C API:
An exception with message Platform doesn't support BF16 format is formed in case of setting KEY_ENFORCE_BF16 to YES on CPU without native BF16 support or BF16 simulation mode.
Low-Precision 8-bit integer models cannot be converted to BF16, even if bfloat16 optimization is set by default.
Bfloat16 simulation mode is available on CPU and Intel® AVX-512 platforms that do not support the native avx512_bf16 instruction. The simulator does not guarantee an adequate performance. To enable Bfloat16 simulator:
-enforcebf16=true optionKEY_ENFORCE_BF16 to YESInformation about layer precision is stored in the performance counters that are available from the Inference Engine API. The layers have the following marks:
BF16 for layers that had bfloat16 data type input and were computed in BF16 precisionFP32 for layers computed in 32-bit precisionFor example, the performance counters table for the Inception model can look as follows:
The execType column of the table includes inference primitives with specific suffixes.
