Below is the list of dataset types available to use in the DL Workbench:
Your dataset does not need to contain images from official databases providing these types, like ImageNet or Pascal VOC, but it needs to adhere to the supported dataset formats.
ImageNet is a dataset for classification models. DL Workbench supports only the format of the ImageNet validation dataset published in 2012.
To download images from ImageNet, you need to have an account and agree to the Terms of Access. Follow the steps below:



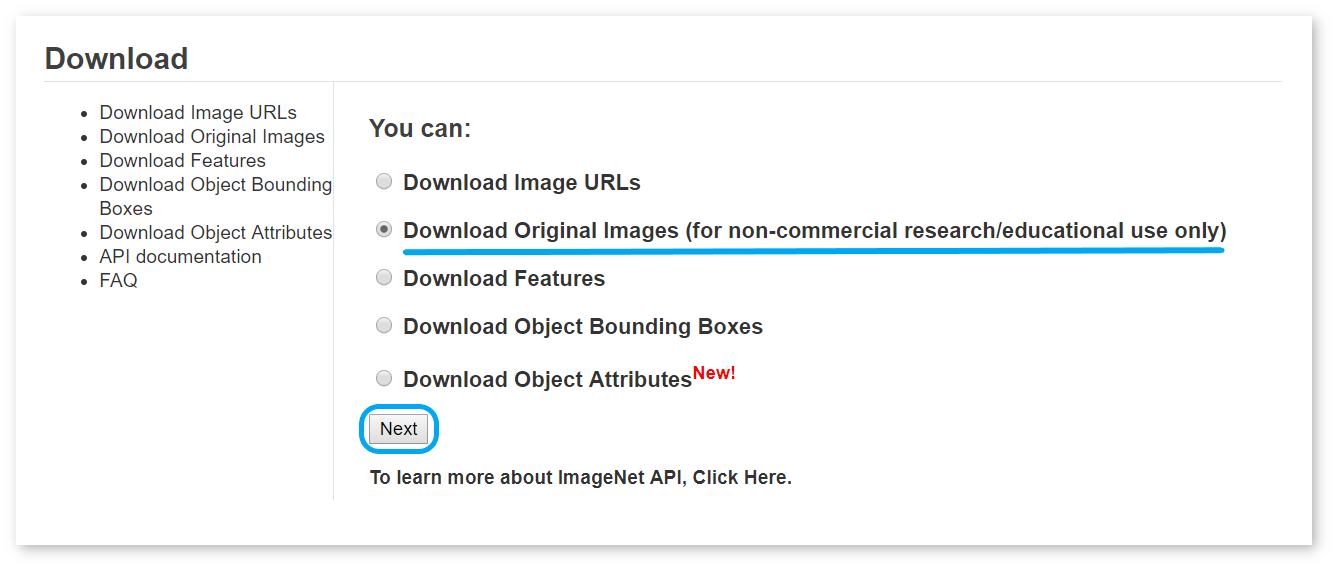


/home/<user>/Work/imagenet.zip for Linux*, macOS* or C:\Work\imagenet.zip for Windows*.imagenet.zip and caffe_ilsvrc12.tar.gz. Place the val.txt file from caffe_ilsvrc12 inside the imagenet folder.imagenet folder.The final imagenet.zip archive must follow the structure below:
The annotation file is organized as follows:
NOTE: The dataset is considerably big in size. If you want to save your time when loading it into the DL Workbench, follow the instructions to cut the dataset.
Pascal VOC dataset is used to train classification, object-detection and semantic-segmentation models. DL Workbench supports validation on Pascal VOC datasets for object detection, semantic segmentation, image inpainting and style transfer. DL Workbench supports only the format of the VOC validation datasets published in 207, 2010, and 2021.
To download test data from Pascal VOC, you need to have an account. Follow the steps below:


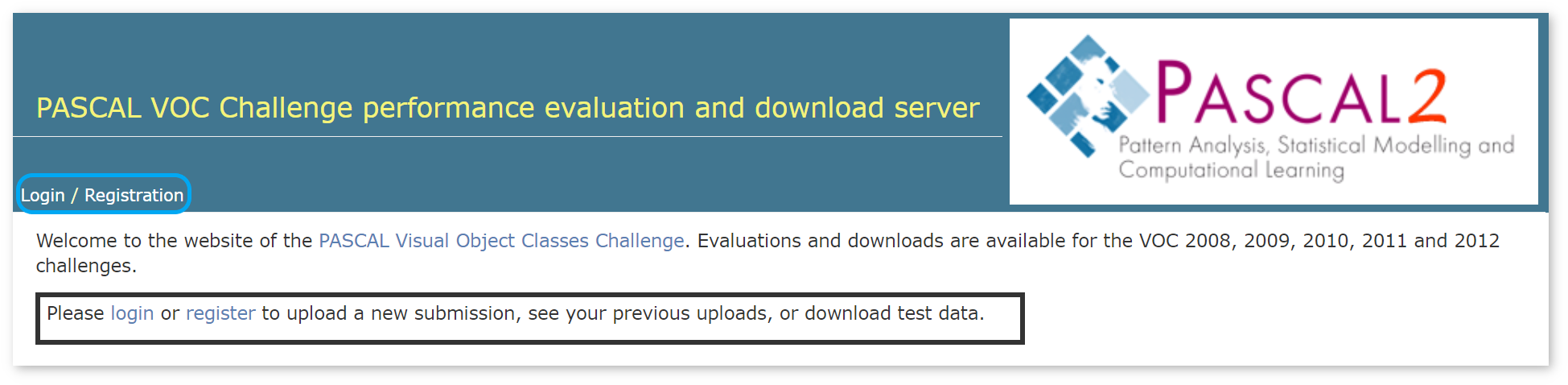
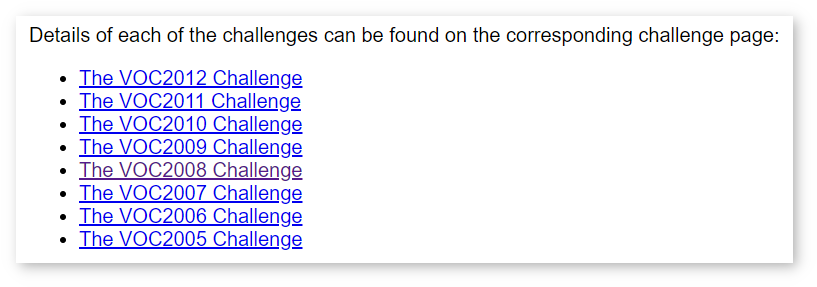

NOTE: The dataset is considerably big in size. If you want to save your time when loading it into the DL Workbench, follow the instructions to cut the dataset.
Pascal VOC datasets consist of several folders containing annotation files and image indices. Each image file must have the corresponding annotation file.
A Pascal VOC dataset archive is organized as follows:
COCO dataset is used for object detection, instance segmentation, person keypoints detection, stuff segmentation, and caption generation. DL Workbench supports validation on COCO datasets for object detection, instance segmentation, image inpainting, and style transfer. DL Workbench supports only the format of the COCO validation datasets published in 2014 and 2017.
To use a dataset from the COCO website, download annotations and images archives separately. Choose one of the options:
NOTE: The dataset is considerably big in size. If you want to save your time when loading it into the DL Workbench, follow the instructions to cut the dataset.
COCO dataset is organized as follows:
The JSON file with annotations is organized as follows:
CSS is an OpenVINO™ dataset type aimed to simplify the structure provided by Pascal VOC. DL Workbench supports validation on CSS datasets for semantic segmentation, image inpainting, and style transfer.
A CSS dataset archive consists of folders with images and masks, and a JSON file with meta information:
The JSON meta information file is organized as follows:
CSR is an OpenVINO™ dataset type for super-resolution, image-inpainting, and style-transfer models.
The archive consists of three separate folders for high-resolution images, low-resolution images, and upsampled low-resolution images:
LFW is used for face recognition. DL Workbench supports only LFW validation datasets.
LFW folder with two subdirectories: Images and Annotations.lfw.tgz archive with images. Unarchive it and place it in the Images folder. pairs.txt annotation file. Place the file in the Annotations folder.LFW folder.An LFW dataset archive consists of folders with images and annotations. The Images folder contains separate folders with photographs of a particular person. The Annotations folder contains two files: pairs.txt and landmarks.txt. The pairs.txt file is required, while landmarks.txt is optional.
The pairs.txt file follows the structure represented below. The file is split into sets of randomly selected persons to provide randomization for accuracy measurements.
Blocks of lines with correct and incorrect pairs alternate to represent different sets. Below is an example of an annotation beginning. The numbers of sets and images in them come first, followed by the lines for the first set.
Then the lines for the second set begin:
The landmarks.txt file contains coordinates of five facial landmarks found in an image:
Each line consists of the relative path to an image and two coordinates in pixels of each landmark in the same order as in the list above:
NOTE: There is no requirements for image and folder names. However, the names that you use for images and folders must match the names that you put in annotations.
VGGFace2 is used for facial landmark detection.
VGGFace2 is currently not available for download. Consider creating your own dataset with the same structure and annotations as described below.
A VGGFace2 dataset archive consists of folders with images and annotations. The Images folder contains separate folders with images of a particular person. The Annotations folder contains two files: loose_bb_test.csv and loose_landmark_test.csv.
loose_bb_test.csv contains the coordinates in pixels of a bounding box in an image: The loose_landmarks_test.csv file contains coordinates of five facial landmarks found in an image:
Each line consists of the relative path to an image and two coordinates in pixels of each landmark in the same order as in the list above:
NOTE: When you download an original dataset, it includes
loose_bb_train.csvandloose_landmarks_train.csvfiles. Remove these files before importing the dataset into the DL Workbench.
NOTE: There is no requirements for image and folder names. However, the names that you use for images and folders must match the names that you put in annotations.
Not annotated datasets are sets of images and do not contain annotations. Models in projects that use not annotated datasets can be calibrated only with the Default Calibration method and cannot be used for accuracy measurements.
Download the Landscape Pictures dataset without annotations.
The archive is organized as follows:
