The GPU plugin uses the Intel® Compute Library for Deep Neural Networks (clDNN) to infer deep neural networks. clDNN is an open source performance library for Deep Learning (DL) applications intended for acceleration of Deep Learning Inference on Intel® Processor Graphics including Intel® HD Graphics, Intel® Iris® Graphics, Intel® Iris® Xe Graphics, and Intel® Iris® Xe MAX graphics. For an in-depth description of clDNN, see Inference Engine source files and Accelerate Deep Learning Inference with Intel® Processor Graphics.
X={0, 1, 2,...}. Only Intel® GPU devices are considered.For demonstration purposes, see the Hello Query Device C++ Sample that can print out the list of available devices with associated indices. Below is an example output (truncated to the device names only):
The plugin supports algorithms that fuse several operations into one optimized operation. Refer to the sections below for details.
NOTE: For operation descriptions, see the IR Notation Reference.
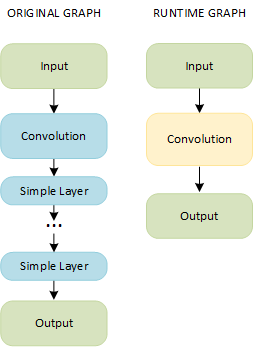
Merge of a Convolution layer and any of the simple layers listed below:
NOTE: You can have any number and order of simple layers.
A combination of a Convolution layer and simple layers results in a single fused layer called Convolution:
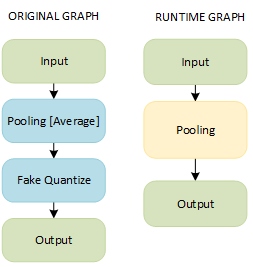
A combination of Pooling and FakeQuantize layers results in a single fused layer called Pooling:
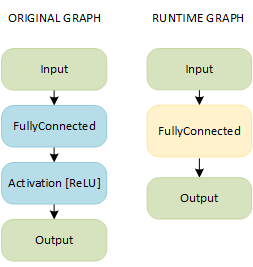
Given the linear pattern, an Activation layer can be fused into other layers:
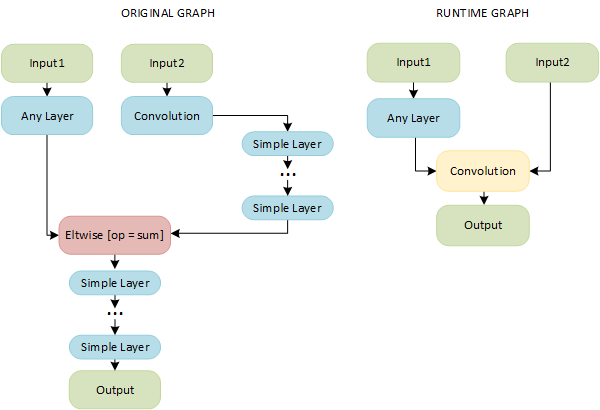
A combination of Convolution, Simple, and Eltwise layers with the sum operation results in a single layer called Convolution:
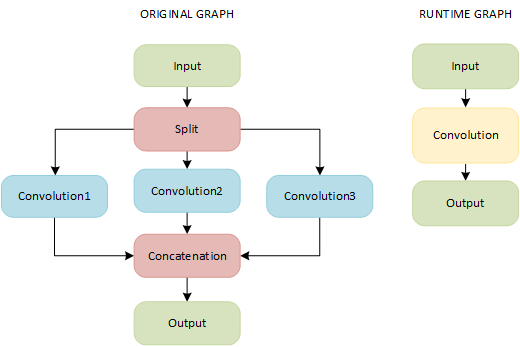
If a topology contains the following pipeline, a GPU plugin merges Split, Convolution, and Concatenation layers into a single Convolution layer with the group parameter:
NOTE: Parameters of the Convolution layers must coincide.
The following layers are optimized out under certain conditions:
Some layers are executed during the load time, not during the inference. One of such layers is PriorBox.
The following layers are not accelerated on the GPU and executed on the host CPU instead:
The plugin supports the configuration parameters listed below. All parameters must be set before calling InferenceEngine::Core::LoadNetwork() in order to take effect. When specifying key values as raw strings (that is, when using Python API), omit the KEY_ prefix.
| Parameter Name | Parameter Values | Default | Description |
|---|---|---|---|
KEY_PERF_COUNT | YES / NO | NO | Collect performance counters during inference |
KEY_CONFIG_FILE | "<file1> [<file2> ...]" | "" | Load custom layer configuration files |
KEY_DUMP_KERNELS | YES / NO | NO | Dump the final kernels used for custom layers |
KEY_TUNING_MODE | TUNING_DISABLED TUNING_CREATE TUNING_USE_EXISTING | TUNING_DISABLED | Disable inference kernel tuning Create tuning file (expect much longer runtime) Use an existing tuning file |
KEY_TUNING_FILE | "<filename>" | "" | Tuning file to create / use |
KEY_CLDNN_PLUGIN_PRIORITY | <0-3> | 0 | OpenCL queue priority (before usage, make sure your OpenCL driver supports appropriate extension) Higher value means higher priority for clDNN OpenCL queue. 0 disables the setting. |
KEY_CLDNN_PLUGIN_THROTTLE | <0-3> | 0 | OpenCL queue throttling (before usage, make sure your OpenCL driver supports appropriate extension) Lower value means lower driver thread priority and longer sleep time for it. 0 disables the setting. |
KEY_CLDNN_GRAPH_DUMPS_DIR | "<dump_dir>" | "" | clDNN graph optimizer stages dump output directory (in GraphViz format) |
KEY_CLDNN_SOURCES_DUMPS_DIR | "<dump_dir>" | "" | Final optimized clDNN OpenCL sources dump output directory |
KEY_GPU_THROUGHPUT_STREAMS | KEY_GPU_THROUGHPUT_AUTO, or positive integer | 1 | Specifies a number of GPU "execution" streams for the throughput mode (upper bound for a number of inference requests that can be executed simultaneously). This option is can be used to decrease GPU stall time by providing more effective load from several streams. Increasing the number of streams usually is more effective for smaller topologies or smaller input sizes. Note that your application should provide enough parallel slack (e.g. running many inference requests) to leverage full GPU bandwidth. Additional streams consume several times more GPU memory, so make sure the system has enough memory available to suit parallel stream execution. Multiple streams might also put additional load on CPU. If CPU load increases, it can be regulated by setting an appropriate KEY_CLDNN_PLUGIN_THROTTLE option value (see above). If your target system has relatively weak CPU, keep throttling low. The default value is 1, which implies latency-oriented behavior. KEY_GPU_THROUGHPUT_AUTO creates bare minimum of streams to improve the performance; this is the most portable option if you are not sure how many resources your target machine has (and what would be the optimal number of streams). A positive integer value creates the requested number of streams. |
KEY_EXCLUSIVE_ASYNC_REQUESTS | YES / NO | NO | Forces async requests (also from different executable networks) to execute serially. |
Inference Engine GPU plugin provides possibility to dump the user custom OpenCL™ kernels to a file to allow you to properly debug compilation issues in your custom kernels.
The application can use the SetConfig() function with the key PluginConfigParams::KEY_DUMP_KERNELS and value: PluginConfigParams::YES. Then during network loading, all custom layers will print their OpenCL kernels with the JIT instrumentation added by the plugin. The kernels will be stored in the working directory under files named the following way: clDNN_program0.cl, clDNN_program1.cl.
This option is disabled by default. Additionally, the application can call the SetConfig() function with the key PluginConfigParams::KEY_DUMP_KERNELS and value: PluginConfigParams::NO before network loading.
How to verify that this option is disabled:
clDNN_program*.cl files from the current directoryclDNN_program0.cl)See RemoteBlob API of GPU Plugin
