This document describes Python* API of the Post-Training Optimization Toolkit (POT) that allows implementing a custom optimization pipeline for a single or cascaded/composite DL model (set of joint models). By the optimization pipeline, we mean the consecutive application of optimization algorithms to the model. The input for the optimization pipeline is a full-precision model, and the result is an optimized model. The optimization pipeline is configured to sequentially apply optimization algorithms in the order they are specified. The key requirement for applying the optimization algorithm is the availability of the calibration dataset for statistics collection and validation dataset for accuracy validation which in practice can be the same. The Python* POT API provides simple interfaces for implementing custom model inference with data loading and pre-processing on an arbitrary dataset and implementing custom accuracy metrics to make it possible to use optimization algorithms from the POT.
The Python* POT API provides Pipeline class for creating and configuring the optimization pipeline and applying it to the model. The Pipeline class depends on the implementation of the following model specific interfaces which should be implemented according to the custom DL model:
Engine is responsible for model inference and provides statistical data and accuracy metrics for the model. -NOTE: The POT has the implementation of the Engine class with the class name IEEngine located in
<POT_DIR>/compression/engines/ie_engine.py, where<POT_DIR>is a directory where the Post-Training Optimization Tool is installed. It is based on the OpenVINO™ Inference Engine Python* API and can be used as a baseline engine in the customer pipeline instead of the abstract Engine class.
DataLoader is responsible for the dataset loading, including the data pre-processing.Metric is responsible for calculating the accuracy metric for the model. The pipeline with implemented model specific interfaces such asNOTE: Metric is required if you want to use accuracy-aware optimization algorithms, such as
AccuracyAwareQuantizationandINT4MixedQuantizationalgorithms.
Engine, DataLoader and Metric we will call the custom optimization pipeline (see the picture below that shows relationships between classes).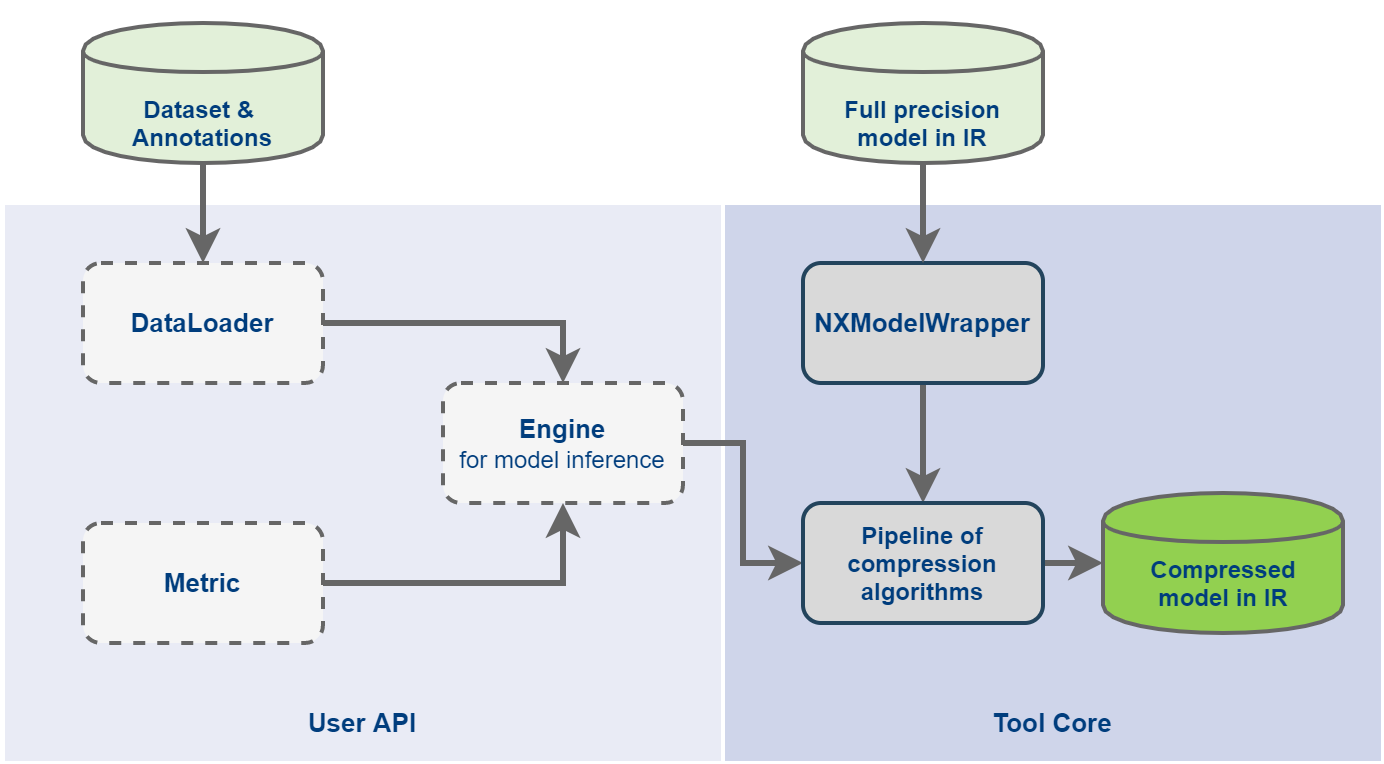
The main and easiest way to get the optimized model is to use the Post-Training Optimization Command-line Tool where you just need to prepare the configuration file. Before diving into the Python* POT API, it is highly recommended to read Best Practices document where various scenarios of using the Post-Training Optimization Command-line Tool are described.
The POT Python* API for model optimization can be used in the following cases:
Below is a detailed explanation of POT Python* APIs which should be implemented in order to create a custom optimization pipeline.
The base class for all DataLoaders.
DataLoader loads data from a dataset and applies pre-processing to them providing access to the pre-processed data by index.
All subclasses should override __len__() function, which should return the size of the dataset, and __getitem__(), which supports integer indexing in range of 0 to len(self)
An abstract class representing an accuracy metric.
All subclasses should override the following properties:
value - returns the accuracy metric value for the last model output.avg_value - returns the average accuracy metric value for all model outputs.attributes - returns a dictionary of metric attributes: direction - (higher-better or higher-worse) a string parameter defining whether metric value should be increased in accuracy-aware algorithms.type - a string representation of metric type. For example, 'accuracy' or 'mean_iou'.All subclasses should override the following methods:
update(output, annotation) - calculates and updates the accuracy metric value using last model output and annotation.reset() - resets collected accuracy metric.Base class for all Engines.
The engine provides model inference, statistics collection for activations and calculation of accuracy metrics for a dataset.
Parameters
config - engine specific config.data_loader - DataLoader instance to iterate over dataset.metric - Metric instance to calculate the accuracy metric of the model.All subclasses should override the following methods:
set_model(model) - sets/resets a model.model - NXModel instance for inference (see details below).predict(stats_layout=None, sampler=None, metric_per_sample=False, print_progress=False) - performs model inference on the specified subset of data.
Parameters
stats_layout - dictionary of statistic collection functions. An optional parameter. sampler - Sampler instance that provides a way to iterate over the dataset. (See details below).metric_per_sample - if Metric is specified and this parameter is set to True, then the metric value should be calculated for each data sample, otherwise for the whole dataset.print_progress - print inference progress.Returns
metric_per_sample is True In order to simplify implementation of optimization pipelines we provide a set of ready-to-use helpers. Here we also describe internal representation of the DL model and how to work with it.
IEEngine is a helper which implements Engine class based on OpenVINO™ Inference Engine Python* API. This class support inference in synchronous and asynchronous modes and can be reused as-is in the custom pipeline or with some modifications, e.g. in case of custom post-processing of inference results.
The following methods can be overridden in subclasses:
postprocess_output(outputs, metadata) - processes raw model output using the image metadata obtained during data loading.
Parameters
outputs - raw output of the model.metadata - information about the data used for inference.Return
IEEngine supports data returned by DataLoader in the format:
or
Metric values returned by a Metric instance are expected to be in the format:
value(): avg_value(): In order to implement a custom Engine class you may need to get familiar with the following interfaces:
The Python* POT API provides the NXModel class as one interface for working with single and cascaded DL model. It is used to load, save and access the model, in case of the cascaded model, access each model of the cascaded model.
The NXModel class provides a representation of the DL model. A single model and cascaded model can be represented as an instance of this class. The cascaded model is stored as a list of models.
Properties
models - list of models of the cascaded model.is_cascade - returns True if the loaded model is cascaded model.The Python* POT API provides the utility function to load model from the OpenVINO™ Intermediate Representation (IR):
Parameters
model_config - dictionary describing a model that includes the following attributes:
model_name - model name.model - path to the network topology (.xml).weights - path to the model weights (.bin).Example of model_config for a single model:
Example of model_config for a cascaded model:
Returns
NXModel instanceThe Python* POT API provides the utility function to save model in the OpenVINO™ Intermediate Representation (IR):
Parameters
model - NXModel instance.save_path - path to save the model.model_name - name under which the model will be saved.for_stat_collection - whether model is saved to be used for statistic collection or for normal inference (affects only cascaded models). If set to False, removes model prefixes from node names.Returns
Base class for all Samplers.
Sampler provides a way to iterate over the dataset.
All subclasses overwrite __iter__() method, providing a way to iterate over the dataset, and a __len__() method that returns the length of the returned iterators.
Parameters
data_loader - instance of DataLoader class to load data.batch_size - number of items in batch, default is 1.subset_indices - indices of samples to load. If subset_indices is set to None then the sampler will take elements from the whole dataset. Sampler provides an iterable over the dataset subset if subset_indices is specified or over the whole dataset with given batch_size. Returns a list of data items.
Pipeline class represents the optimization pipeline.
Parameters
engine - instance of Engine class for model inference.The pipeline can be applied to the DL model by calling run(model) method where model is the NXModel instance.
The POT Python* API provides the utility function to create and configure the pipeline:
Parameters
algo_config - a list defining optimization algorithms and their parameters included in the optimization pipeline. The order in which they are applied to the model in the optimization pipeline is determined by the order in the list.
Example of the algorithm configuration of the pipeline:
engine - instance of Engine class for model inference.Returns
Pipeline class.Before running the optimization tool it's highly recommended to make sure that
As was described above, DataLoader, Metric and Engine interfaces should be implemented in order to create the custom optimization pipeline for your model. There might be a case you have the Python* validation script for your model using the OpenVINO™ Inference Engine, which in practice includes loading a dataset, model inference, and calculating the accuracy metric. So you just need to wrap the existing functions of your validation script in DataLoader, Metric and Engine interfaces. In another case, you need to implement interfaces from scratch.
For facilitation of using Python* POT API, we implemented IEEngine class providing the model inference of the most models from the Vision Domain which can be reused for an arbitrary model.
After YourDataLoader, YourMetric, YourEngine interfaces are implemented, the custom optimization pipeline can be created and applied to the model as follows:
For in-depth examples of using Python* POT API, browse the samples included into the OpenVINO™ toolkit installation and available in the <INSTALL_DIR>/deployment_tools/tools/post_training_optimization_toolkit/sample directory.
