Intel® distributions of OpenVINO™ toolkit for Linux* OS and Windows* OS provide a set of libraries and demos to demonstrate end-to-end speech recognition, as well as new acoustic and language models that can work with these demos. The libraries are designed for preprocessing (feature extraction) to get a feature vector from a speech signal, as well as postprocessing (decoding) to produce text from scores. Together with OpenVINO™-based neural-network speech recognition, these libraries provide an end-to-end pipeline converting speech to text. This pipeline is demonstrated by the end-to-end demos:
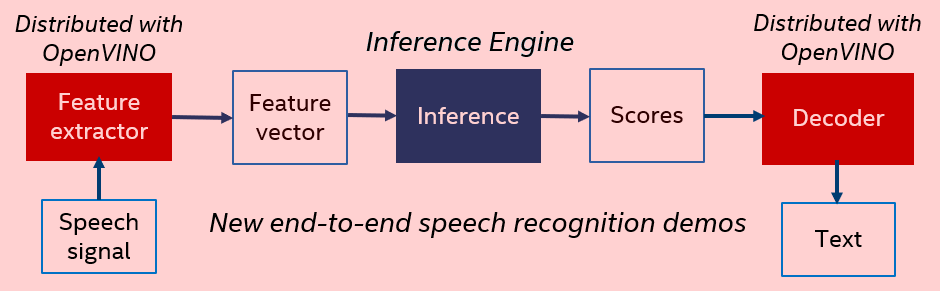
Note that the OpenVINO™ package also includes an automatic speech recognition sample demonstrating acoustic model inference based on Kaldi* neural networks. The sample works with Kaldi ARK files only, so it does not cover an end-to-end speech recognition scenario (speech to text),requiring additional preprocessing (feature extraction) to get a feature vector from a speech signal, as well as postprocessing (decoding) to produce text from scores:
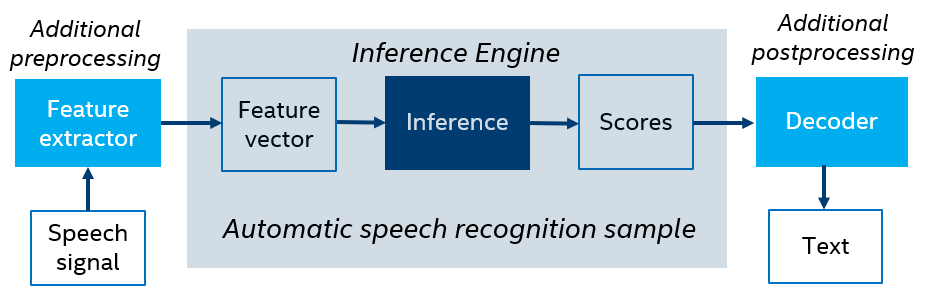
The main purpose of the sample is to demonstrate a variety of features and options provided by OpenVINO™ for speech recognition neural networks.
Find new libraries, demos, and models at <INSTALL_DIR>/data_processing/audio/speech_recognition.
NOTE: These components are installed only if you select the Inference Engine Runtime for Intel® Gaussian & Neural Accelerator component during installation. However, the Speech Library and speech recognition demos do not require the GNA accelerator. See Hardware support for details.
The package contains the following components:
Additionally, new acoustic and language models to be used by new demos are located at download.01.org.
To download pretrained models and build all dependencies:
<INSTALL_DIR>/deployment_tools/demo/demo_speech_recognition.sh<INSTALL_DIR>\deployment_tools\demo\demo_speech_recognition.batThe script follows the steps below:
If you are behind a proxy, set the following environment variables in a console session before running the script:
The provided acoustic models have been tested on a CPU, graphics processing unit (GPU), and Intel® Gaussian & Neural Accelerator (Intel® GNA), and you can switch between these targets in offline and live speech recognition demos.
NOTE: Intel® GNA is a specific low-power coprocessor, which offloads some workloads, thus saving power and CPU resources. If you use a processor supporting the GNA, such as Intel® Core™ i3-8121U and Intel® Core™ i7-1065G7, you can notice that CPU load is much lower when GNA is selected. If you selected GNA as a device for inference, and your processor does not support GNA, then execution is performed in the emulation mode (on CPU) because
GNA_AUTOconfiguration option is used.
See the GNA plugin documentation for more information.
Speech Library provides a highly optimized implementation of preprocessing and postprocessing (feature extraction and decoding) on CPU only.
Before running demonstration applications with custom models, follow the steps below:
demo_speech_recognition.sh/.bat file mentioned in Run Speech Recognition Demos with Pretrained Models{OpenVINO build folder}/data_processing/audio/speech_recognition/models/{LANG}. The demo models are trained for US English, so use en-us for the {LANG} folder name.Then you can use new models in the live speech recognition demo. To perform speech recognition using a new model and the command-line application, provide the path to the new configuration file as an input argument of the application.
In order to convert acoustic models, the following Kaldi files are required:
final.nnet – RAW neural network without topology informationpdf.counts (if used)final.feature_transform (if used)For conversion steps, follow Converting a Kaldi* Model.
NOTE: Set the path to the XML file with the converted model in the configuration file.
In order to convert language models, the following Kaldi files are required:
final.mdlHCLG.wfstwords.txt.All these files are required to create resources for demo applications.
Model conversion from Kaldi requires the following steps:
phones.txt and final.mdl: NOTE: Put the paths to
cl.fstandlabels.binfiles in the configuration file to use them with the Live Speech Recognition Demo Application.
See the offline speech recognition demo documentation to learn about the configuration file format.
See Kaldi* Statistical Language Model Conversion Tool for more information on the conversion tool.
