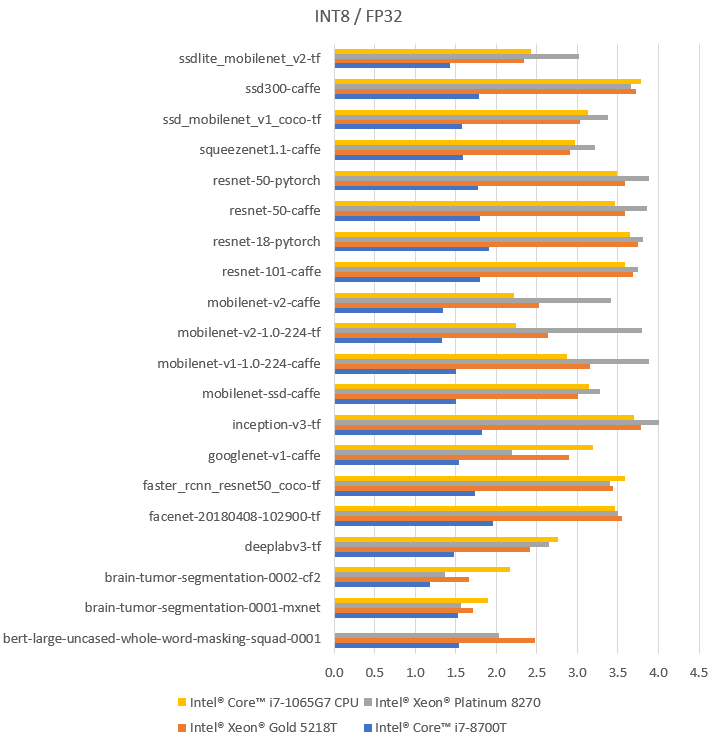
The table below illustrates the speed-up factor for the performance gain by switching from an FP32 representation of an OpenVINO™ supported model to its INT8 representation.
| Intel® Core™ i7-8700T | Intel® Xeon® Gold 5218T | Intel® Xeon® Platinum 8270 | Intel® Core™ i7-1065G7 | ||
|---|---|---|---|---|---|
| OpenVINO benchmark model name | Dataset | Throughput speed-up FP16-INT8 vs FP32 | |||
| bert-large- uncased-whole-word- masking-squad-0001 | SQuAD | 1.5 | 2.5 | 2.0 | N/A |
| brain-tumor- segmentation- 0001-mxnet | BraTS | 1.5 | 1.7 | 1.6 | 1.9 |
| brain-tumor- segmentation- 0002-cf2 | BraTS 2017 | 1.2 | 1.7 | 1.4 | 2.2 |
| deeplabv3-tf | VOC 2012 Segmentation | 1.5 | 2.4 | 2.6 | 2.8 |
| facenet- 20180408- 102900-tf | LFW | 2.0 | 3.5 | 3.5 | 3.5 |
| faster_rcnn_ resnet50_coco-tf | MS COCO | 1.7 | 3.4 | 3.4 | 3.6 |
| googlenet-v1-caffe | ImageNet | 1.5 | 2.9 | 2.2 | 3.2 |
| inception-v3-tf | ImageNet | 1.8 | 3.8 | 4.0 | 3.7 |
| mobilenet- ssd-caffe | VOC2012 | 1.5 | 3.0 | 3.3 | 3.1 |
| mobilenet-v1-1.0- 224-caffe | ImageNet | 1.5 | 3.2 | 3.9 | 2.9 |
| mobilenet-v2-1.0- 224-tf | ImageNet | 1.3 | 2.6 | 3.8 | 2.2 |
| mobilenet-v2- caffe | ImageNet | 1.3 | 2.5 | 3.4 | 2.2 |
| resnet-101- caffe | ImageNet | 1.8 | 3.7 | 3.7 | 3.6 |
| resnet-18- pytorch | ImageNet | 1.9 | 3.7 | 3.8 | 3.6 |
| resnet-50- caffe | ImageNet | 1.8 | 3.6 | 3.9 | 3.5 |
| resnet-50- pytorch | ImageNet | 1.8 | 3.6 | 3.9 | 3.5 |
| squeezenet1.1- caffe | ImageNet | 1.6 | 2.9 | 3.2 | 3.0 |
| ssd_mobilenet_ v1_coco-tf | MS COCO | 1.6 | 3.0 | 3.4 | 3.1 |
| ssd300-caffe | MS COCO | 1.8 | 3.7 | 3.7 | 3.8 |
| ssdlite_ mobilenet_ v2-tf | MS COCO | 1.4 | 2.3 | 3.0 | 2.4 |
The following table shows the absolute accuracy drop that is calculated as the difference in accuracy between the FP32 representation of a model and its INT8 representation.
| Intel® Core™ i9-10920X CPU @ 3.50GHZ (VNNI) | Intel® Core™ i9-9820X CPU @ 3.30GHz (AVX512) | Intel® Core™ i7-8700 CPU @ 3.20GHz (AVX2) | |||
|---|---|---|---|---|---|
| OpenVINO Benchmark Model Name | Dataset | Metric Name | Absolute Accuracy Drop, % | ||
| bert-large- uncased-whole-word- masking-squad-0001 | SQuAD | F1 | 0.46 | 0.70 | 0.64 |
| brain-tumor- segmentation- 0001-mxnet | BraTS | Dice-index@ Mean@ Overall Tumor | 0.08 | 0.08 | 0.14 |
| brain-tumor- segmentation- 0002-cf2 | BraTS 2017 | Dice-index@ Mean@ Overall Tumor | 0.16 | 0.14 | 0.13 |
| deeplabv3-tf | VOC 2012 Segmentation | mean_iou | 0.28 | 0.71 | 0.71 |
| facenet- 20180408- 102900-tf | LFW | pairwise_ accuracy _subsets | 0.02 | 0.05 | 0.05 |
| faster_rcnn_ resnet50_coco-tf | MS COCO | coco_ precision | 0.21 | 0.20 | 0.20 |
| googlenet-v1-caffe | ImageNet | acc-1 | 0.24 | 0.19 | 0.20 |
| inception-v3-tf | ImageNet | acc-1 | 0.03 | 0.01 | 0.01 |
| mobilenet- ssd-caffe | VOC2012 | mAP | 0.35 | 0.34 | 0.34 |
| mobilenet-v1-1.0- 224-caffe | ImageNet | acc-1 | 0.19 | 0.18 | 0.18 |
| mobilenet-v2-1.0- 224-tf | ImageNet | acc-1 | 0.45 | 0.94 | 0.94 |
| mobilenet-v2- caffe | ImageNet | acc-1 | 0.24 | 1.45 | 1.45 |
| resnet-101- caffe | ImageNet | acc-1 | 0.00 | 0.02 | 0.02 |
| resnet-18- pytorch | ImageNet | acc-1 | 0.26 | 0.25 | 0.25 |
| resnet-50- caffe | ImageNet | acc-1 | 0.16 | 0.12 | 0.12 |
| resnet-50- pytorch | ImageNet | acc-1 | 0.20 | 0.17 | 0.17 |
| squeezenet1.1- caffe | ImageNet | acc-1 | 0.66 | 0.64 | 0.64 |
| ssd_mobilenet_ v1_coco-tf | MS COCO | COCO mAp | 0.24 | 3.07 | 3.07 |
| ssd300-caffe | MS COCO | COCO mAp | 0.06 | 0.05 | 0.05 |
| ssdlite_ mobilenet_ v2-tf | MS COCO | COCO mAp | 0.14 | 0.47 | 0.47 |
INT8 vs FP32 Comparison
For more complete information about performance and benchmark results, visit: www.intel.com/benchmarks and Optimization Notice. Legal Information.