The Intel® Distribution of OpenVINO™ toolkit supports neural network model layers in multiple frameworks including TensorFlow*, Caffe*, MXNet*, Kaldi* and ONYX*. The list of known layers is different for each of the supported frameworks. To see the layers supported by your framework, refer to supported frameworks.
Custom layers are layers that are not included in the list of known layers. If your topology contains any layers that are not in the list of known layers, the Model Optimizer classifies them as custom.
This guide illustrates the workflow for running inference on topologies featuring custom layers, allowing you to plug in your own implementation for existing or completely new layers. For a step-by-step example of creating and executing a custom layer, see the Custom Layer Implementation Tutorials for Linux and Windows.
Terms used in this guide
- Layer — The abstract concept of a math function that is selected for a specific purpose (relu, sigmoid, tanh, convolutional). This is one of a sequential series of building blocks within the neural network.
- Kernel — The implementation of a layer function, in this case, the math programmed (in C++ and Python) to perform the layer operation for target hardware (CPU or GPU).
- Intermediate Representation (IR) — Neural Network used only by the Inference Engine in OpenVINO abstracting the different frameworks and describing topology, layer parameters and weights. The original format will be a supported framework such as TensorFlow, Caffe, or MXNet.
- Model Extension Generator — Generates template source code files for each of the extensions needed by the Model Optimizer and the Inference Engine.
- Inference Engine Extension — Device-specific module implementing custom layers (a set of kernels).
Custom Layer Overview
The Model Optimizer searches the list of known layers for each layer contained in the input model topology before building the model's internal representation, optimizing the model, and producing the Intermediate Representation files.
The Inference Engine loads the layers from the input model IR files into the specified device plugin, which will search a list of known layer implementations for the device. If your topology contains layers that are not in the list of known layers for the device, the Inference Engine considers the layer to be unsupported and reports an error. To see the layers that are supported by each device plugin for the Inference Engine, refer to the Supported Devices documentation.
Note: If a device doesn't support a particular layer, an alternative to creating a new custom layer is to target an additional device using the HETERO plugin. The Heterogeneous Plugin may be used to run an inference model on multiple devices allowing the unsupported layers on one device to "fallback" to run on another device (e.g., CPU) that does support those layers.
Custom Layer Implementation Workflow
When implementing a custom layer for your pre-trained model in the Intel® Distribution of OpenVINO™ toolkit, you will need to add extensions to both the Model Optimizer and the Inference Engine.
Custom Layer Extensions for the Model Optimizer
The following figure shows the basic processing steps for the Model Optimizer highlighting the two necessary custom layer extensions, the Custom Layer Extractor and the Custom Layer Operation.
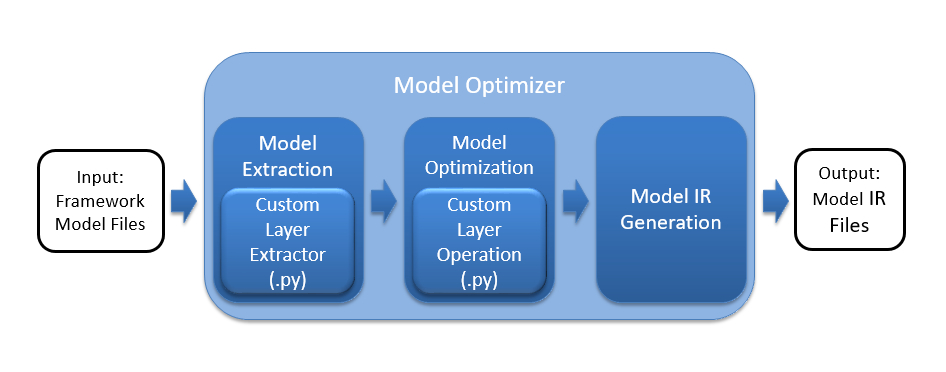
The Model Optimizer first extracts information from the input model which includes the topology of the model layers along with parameters, input and output format, etc., for each layer. The model is then optimized from the various known characteristics of the layers, interconnects, and data flow which partly comes from the layer operation providing details including the shape of the output for each layer. Finally, the optimized model is output to the model IR files needed by the Inference Engine to run the model.
The Model Optimizer starts with a library of known extractors and operations for each supported model framework which must be extended to use each unknown custom layer. The custom layer extensions needed by the Model Optimizer are:
- Custom Layer Extractor
- Responsible for identifying the custom layer operation and extracting the parameters for each instance of the custom layer. The layer parameters are stored per instance and used by the layer operation before finally appearing in the output IR. Typically the input layer parameters are unchanged, which is the case covered by this tutorial.
- Custom Layer Operation
- Responsible for specifying the attributes that are supported by the custom layer and computing the output shape for each instance of the custom layer from its parameters.
The--mo-opcommand-line argument shown in the examples below generates a custom layer operation for the Model Optimizer.
- Responsible for specifying the attributes that are supported by the custom layer and computing the output shape for each instance of the custom layer from its parameters.
Custom Layer Extensions for the Inference Engine
The following figure shows the basic flow for the Inference Engine highlighting two custom layer extensions for the CPU and GPU Plugins, the Custom Layer CPU extension and the Custom Layer GPU Extension.
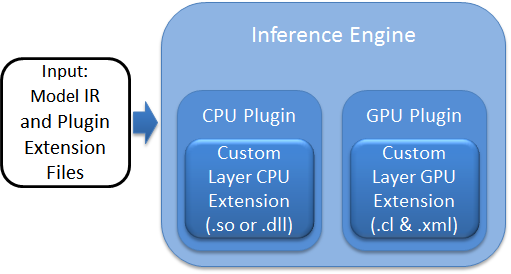
Each device plugin includes a library of optimized implementations to execute known layer operations which must be extended to execute a custom layer. The custom layer extension is implemented according to the target device:
- Custom Layer CPU Extension
- A compiled shared library (.so or .dll binary) needed by the CPU Plugin for executing the custom layer on the CPU.
- Custom Layer GPU Extension
- OpenCL source code (.cl) for the custom layer kernel that will be compiled to execute on the GPU along with a layer description file (.xml) needed by the GPU Plugin for the custom layer kernel.
Model Extension Generator
Using answers to interactive questions or a *.json* configuration file, the Model Extension Generator tool generates template source code files for each of the extensions needed by the Model Optimizer and the Inference Engine. To complete the implementation of each extension, the template functions may need to be edited to fill-in details specific to the custom layer or the actual custom layer functionality itself.
Command-line
The Model Extension Generator is included in the Intel® Distribution of OpenVINO™ toolkit installation and is run using the command (here with the "--help" option):
where the output will appear similar to:
The available command-line arguments are used to specify which extension(s) to generate templates for the Model Optimizer or Inference Engine. The generated extension files for each argument will appear starting from the top of the output directory as follows:
| Command-line Argument | Output Directory Location |
|---|---|
--mo-caffe-ext | user_mo_extensions/front/caffe |
--mo-mxnet-ext | user_mo_extensions/front/mxnet |
--mo-tf-ext | user_mo_extensions/front/tf |
--mo-op | user_mo_extensions/ops |
--ie-cpu-ext | user_ie_extensions/cpu |
--ie-gpu-ext | user_ie_extensions/gpu |
Extension Workflow
The workflow for each generated extension follows the same basic steps:
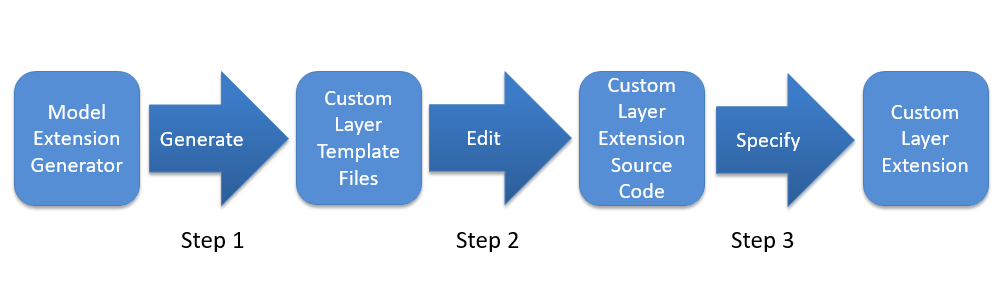
Step 1: Generate: Use the Model Extension Generator to generate the Custom Layer Template Files.
Step 2: Edit: Edit the Custom Layer Template Files as necessary to create the specialized Custom Layer Extension Source Code.
Step 3: Specify: Specify the custom layer extension locations to be used by the Model Optimizer or Inference Engine.
Caffe* Models with Custom Layers
If your Caffe* model has custom layers:
Register the custom layers as extensions to the Model Optimizer. For instructions, see Extending Model Optimizer with New Primitives. When your custom layers are registered as extensions, the Model Optimizer generates a valid and optimized Intermediate Representation. You will need a bit of Python* code that lets the Model Optimizer;
- Generate a valid Intermediate Representation according to the rules you specified.
- Be independent from the availability of Caffe on your computer.
If your model contains Custom Layers, it is important to understand the internal workflow of the Model Optimizer. Consider the following example.
Example:
The network has:
- One input layer (#1)
- One output Layer (#5)
- Three internal layers (#2, 3, 4)
The custom and standard layer types are:
- Layers #2 and #5 are implemented as Model Optimizer extensions.
- Layers #1 and #4 are supported in Model Optimizer out-of-the box.
- Layer #3 is neither in the list of supported layers nor in extensions, but is specified in CustomLayersMapping.xml.
NOTE: If any of the layers are not in one of three categories described above, the Model Optimizer fails with an appropriate message and a link to the corresponding question in Model Optimizer FAQ.
The general process is as shown:
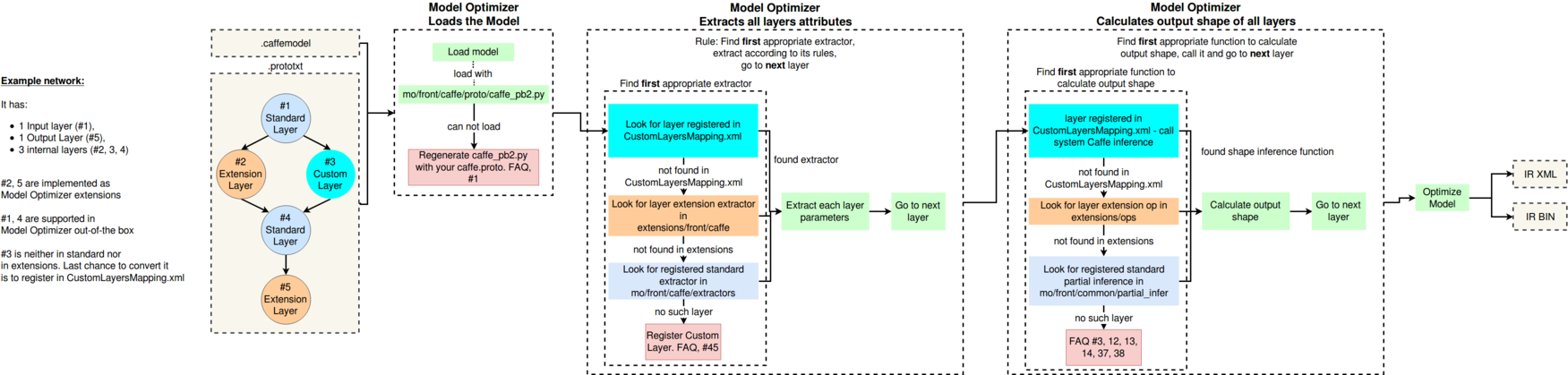
Step 1: The example model is fed to the Model Optimizer that loads the model with the special parser built on top of the caffe.proto file. In case of failure, the Model Optimizer asks you to prepare the parser that can read the model. For more information, refer to the Model Optimizer, FAQ #1.
Step 2: The Model Optimizer extracts the attributes of all layers by going through the list of layers and attempting to find the appropriate extractor. In order of priority, the Model Optimizer checks if the layer is:
- A. Registered as a Model Optimizer extension
- B. Registered as a standard Model Optimizer layer
When the Model Optimizer finds a satisfying condition from the list above, it extracts the attributes according to the following rules:
- For A. - takes only the parameters specified in the extension
- For B. - takes only the parameters specified in the standard extractor
Step 3: The Model Optimizer calculates the output shape of all layers. The logic is the same as it is for the priorities. Important: the Model Optimizer always takes the first available option.
Step 4: The Model Optimizer optimizes the original model and produces the two Intermediate Representation (IR) files in .xml and .bin.
TensorFlow* Models with Custom Layers
You have two options for TensorFlow* models with custom layers:
- Register those layers as extensions to the Model Optimizer. In this case, the Model Optimizer generates a valid and optimized Intermediate Representation.
- If you have sub-graphs that should not be expressed with the analogous sub-graph in the Intermediate Representation, but another sub-graph should appear in the model, the Model Optimizer provides such an option. This feature is helpful for many TensorFlow models. To read more, see Sub-graph Replacement in the Model Optimizer.
MXNet* Models with Custom Layers
There are two options to convert your MXNet* model that contains custom layers:
- Register the custom layers as extensions to the Model Optimizer. For instructions, see Extending MXNet Model Optimizer with New Primitives. When your custom layers are registered as extensions, the Model Optimizer generates a valid and optimized Intermediate Representation. You can create Model Optimizer extensions for both MXNet layers with op
Customand layers which are not standard MXNet layers. - If you have sub-graphs that should not be expressed with the analogous sub-graph in the Intermediate Representation, but another sub-graph should appear in the model, the Model Optimizer provides such an option. In MXNet the function is actively used for ssd models provides an opportunity to for the necessary subgraph sequences and replace them. To read more, see Sub-graph Replacement in the Model Optimizer.
Kaldi* Models with Custom Layers
For information on converting your Kaldi* model containing custom layers see Converting a Kaldi Model in the Model Optimizer Developer Guide.
ONNX* Models with Custom Layers
For information on converting your ONNX* model containing custom layers see Converting an ONNX Model in the Model Optimizer Developer Guide.
Step-by-Step Custom Layers Tutorial
For a step-by-step walk-through creating and executing a custom layer, see Custom Layer Implementation Tutorial for Linux and Windows.
Additional Resources
- Intel® Distribution of OpenVINO™ toolkit home page: https://software.intel.com/en-us/openvino-toolkit
- OpenVINO™ toolkit online documentation: https://docs.openvinotoolkit.org
- Model Optimizer Developer Guide
- Kernel Extensivility in the Inference Engine Developer Guide
- Inference Engine Samples Overview
- Overview of OpenVINO™ Toolkit Pre-Trained Models
- Inference Engine Tutorials
- For IoT Libraries and Code Samples see the Intel® IoT Developer Kit.