Once you identify the optimal configuration of inferences, batch and target for a model, you can incorporate those settings into the inference engine deployed with your application.
How Streams and Batches Impact Performance
Internally, the execution resources are split/pinned into execution streams. This feature provides much better performance for networks that are not originally scaled with a number of threads (for example, lightweight topologies). This is especially pronounced for the many-core server machines. Refer to the Throughput Mode for CPU section in the Optimization Guide for more information.
NOTE: Unlike CPUs and GPUs, VPUs do not support streams. Therefore, on a VPU you can find only optimal inference requests combination. For details, refer to the Performance Aspects of Running Multiple Requests Simultaneously section in the Optimization Guide.
During execution of a model, streams, as well as inference requests in a stream, can be distributed inefficiently among cores of hardware, which can reduce model speed. Using the DL Workbench Inference Results can help optimize performance of your model on specific hardware by providing you with the information you need to manually redistribute streams and inference requests in each stream for each core of the hardware.
NOTE: Inference requests in each stream are parallel.
The optimal configuration is the one with the highest throughput value. Latency, or execution time of an inference, is critical for real-time services. The common technique for improving performance is batching. However, real-time applications often cannot take advantage of batching, because high batch size comes with the latency penalty. With the 2018 R5 release, OpenVINO™ introduced a throughput mode which allows the Inference Engine to efficiently run multiple inference requests simultaneously, greatly improving the throughput.
Discover Optimal Combination of Streams and Batches with DL Workbench
To find an optimal combination of inference requests and batches, follow the steps described in Run Range of Inferences.
The optimal combination is the highest point on the Inference Results graph. However, you can choose to limit latency values by specifying the Latency Threshold value and select an optimal inference among the limited number of inferences:
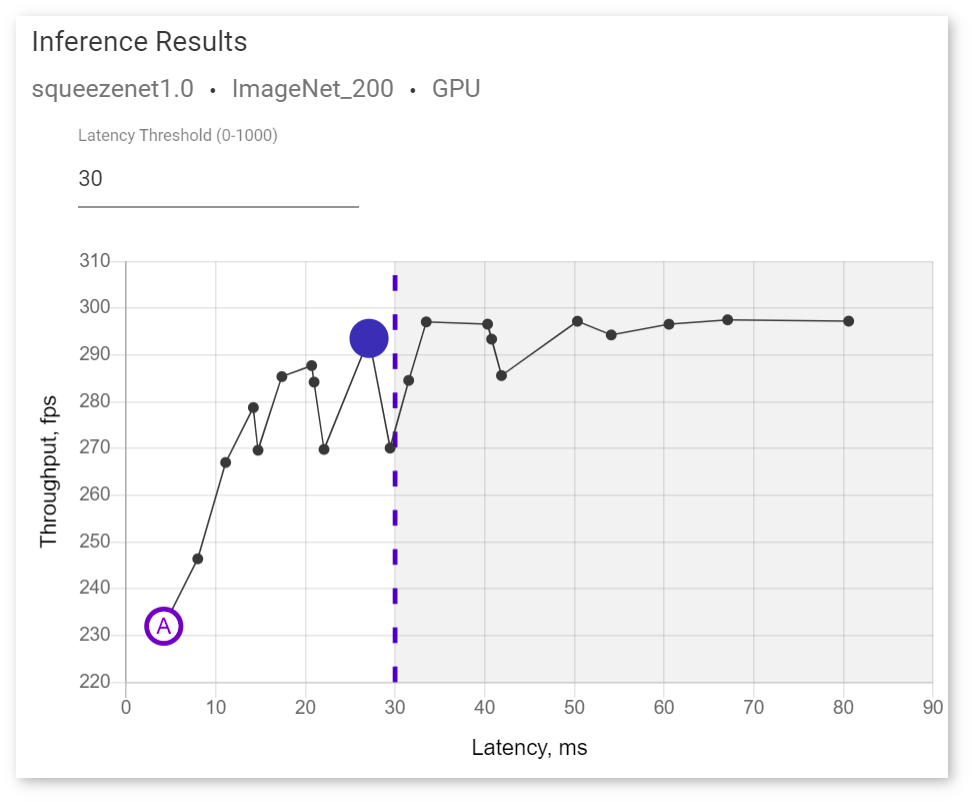
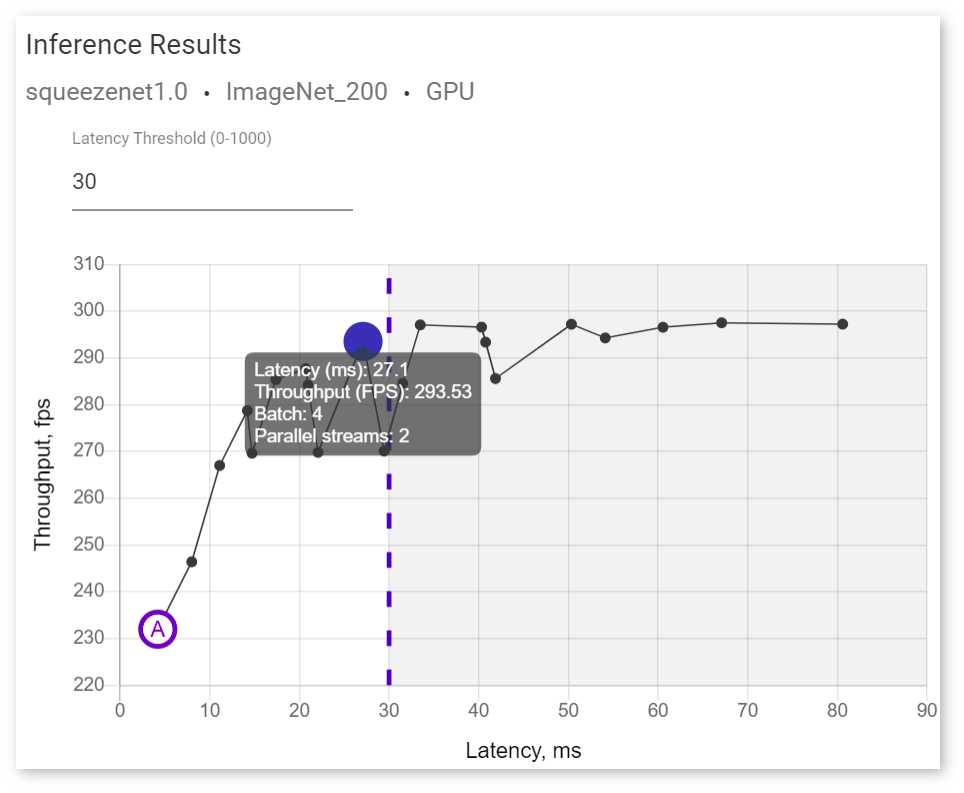
To view information about latency, throughput, batch, and parallel requests of a specific job, hover your cursor over the corresponding point on the graph:
For details, read Integrate the Inference Engine New Request API with Your Application.
Integrate Optimal Combination into Sample Application
Below is the example on how to build your own application to integrate optimal batch and stream numbers explored with the DL Workbench. Follow the simple steps:
- Download a deployment package as described in the Download Deployment Package section of Build Your Application with Deployment Package
- Create
main.cpp - Create
CMakeLists.txt - Compile the application
- Run the application with optimal performance criteria
NOTE: The machine where you use the DL Workbench to download the package and where you prepare your own application is a developer machine. The machine where you deploy the application is a target machine.
Create main.cpp
NOTE: Perform this step on your developer machine.
Create a file main.cpp and paste there the code provided below:
View
main.cpp
In the code above, the following section sets number of streams for CPU and GPU devices respectively. On a CPU device, the number of streams equals to the number of inference requests. On GPUs, this number is twice smaller for even numbers of inference requests and two times smaller plus one for odd numbers:
The batch size is set with the following line:
Inference requests are created in the section below.
Create CMakeLists.txt
NOTE: Perform this step on your developer machine.
In the same directory as main.cpp, create a file named CMakeLists.txt with the following commands to compile main.cpp into an executable file:
View
CMakeLists.txt
Compile Application
NOTE: Perform this step on your developer machine.
Open a terminal in the directory with main.cpp and CMakeLists.txt, run the following commands to build the sample:
NOTE: Replace
<INSTALL_OPENVINO_DIR>with the directory you installed the OpenVINO™ package in. By default, the package is installed to/opt/intel/openvinoor~/intel/openvino.
Once the commands are executed, find the ie_sample binary in the build folder in the directory with the source files.
Run Application
Make sure you have the following components on your developer machine:
- Deployment package
- Model (if it is not included in the package)
- Binary file with your application,
ie_samplefor example
Unarchive the deployment package. Place the binary and model inside the deployment_package folder as follows:
Then archive the deployment_package folder and copy it to the target machine.
NOTE: Perform the steps below on your target machine.
- Open a terminal in the
deployment_packagefolder on the target machine. - (Optional: for inference on Intel® GPU, Intel® Movidius™ VPU, or Intel® Vision Accelerator Design with Intel® Movidius™ VPUs targets) Install dependencies by running the
install_openvino_dependencies.shscript:sudo -E ./install_dependencies/install_openvino_dependencies.sh - Set up the environment variables by running
bin/setupvars.sh:source ./bin/setupvars.sh - Run the application specifying the path to your model, target device, number of batches, and number of streams. In our example, we identified the number of batches equal to
4and number of streams equal to2as an optimal combination for thesqueezenet1.0model on a GPU device, so we pass these values to the command:NOTE: The order of variables is important here.
NOTE: Replace
<path>and<model>with the path to your model and its name respectively.
NOTE: If you run the application on other devices, set the following flags instead of
GPU:
CPUMYRIADfor Intel® Movidius™ Neural Compute Stick 2 (NCS 2)HDDLfor Intel® Vision Accelerator Design with Intel® Movidius™ VPUs
Once you run the application, you get the following output: