DeepSpeech project provides an engine to train speech-to-text models.
Download the Pre-Trained DeepSpeech Model
Pre-trained English speech-to-text model is publicly available. To download the model, please follow the instruction below:
- For UNIX*-like systems, run the following command: wget -O - https://github.com/mozilla/DeepSpeech/releases/download/v0.3.0/deepspeech-0.3.0-models.tar.gz | tar xvfz -
- For Windows* systems:
- Download the archive from the DeepSpeech project repository: https://github.com/mozilla/DeepSpeech/releases/download/v0.3.0/deepspeech-0.3.0-models.tar.gz.
- Unpack it with a file archiver application.
After you unpack the archive with the pre-trained model, you will have the new models directory with the following files:
Pre-trained frozen model file is output_graph.pb.
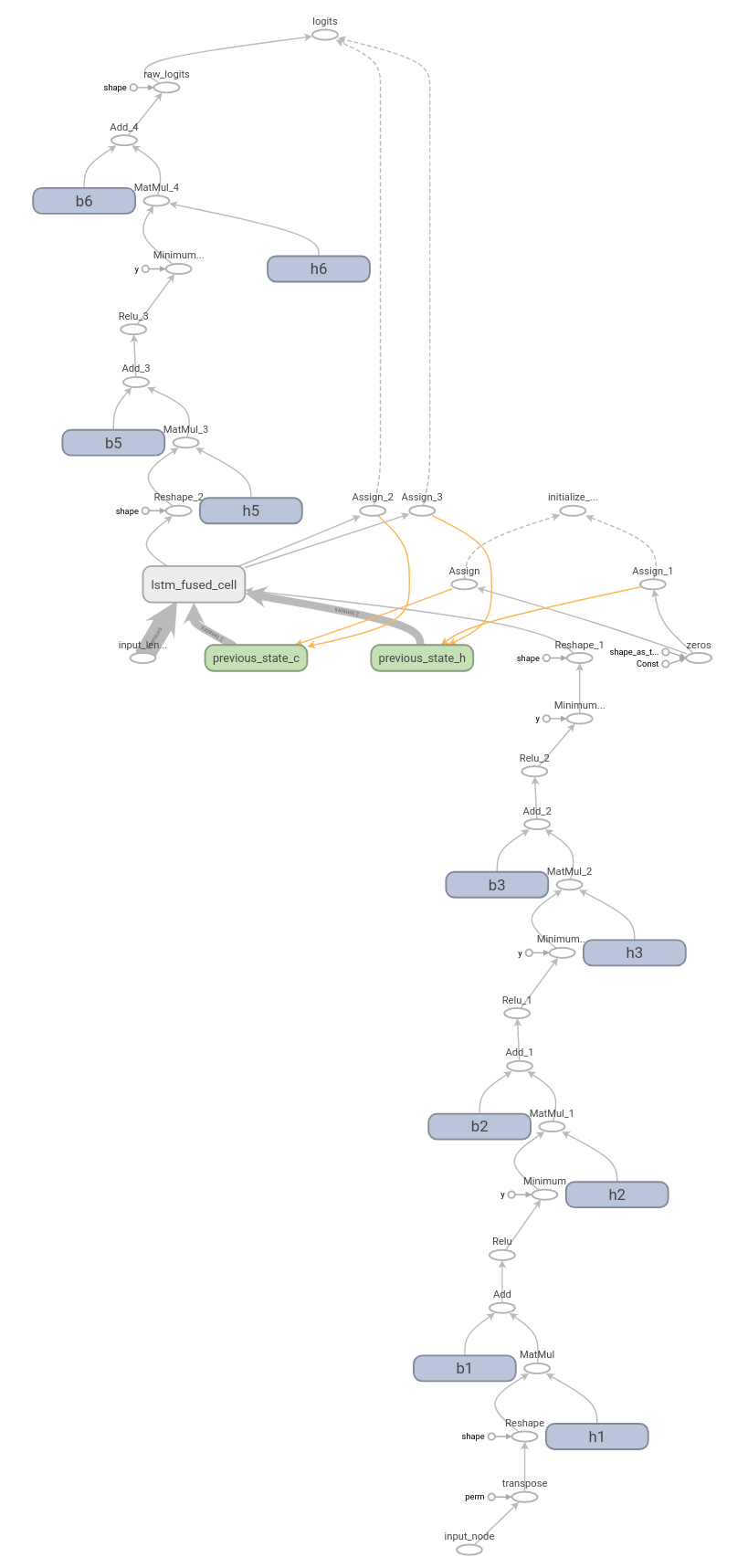
As you can see, the frozen model still has two variables: previous_state_c and previous_state_h. It means that the model keeps training those variables at each inference.
At the first inference of this graph, the variables are initialized by zero tensors. After executing the lstm_fused_cell nodes, cell state and hidden state, which are the results of the BlockLSTM execution, are assigned to these two variables.
With each inference of the DeepSpeech graph, initial cell state and hidden state data for BlockLSTM is taken from previous inference from variables. Outputs (cell state and hidden state) of BlockLSTM are reassigned to the same variables.
It helps the model to remember the context of the words that it takes as input.
Convert the TensorFlow* DeepSpeech Model to IR
The Model Optimizer assumes that the output model is for inference only. That is why you should cut those variables off and resolve keeping cell and hidden states on the application level.
There are certain limitations for the model conversion:
- Time length (
time_len) and sequence length (seq_len) are equal. - Original model cannot be reshaped, so you should keep original shapes.
To generate the DeepSpeech Intermediate Representation (IR), provide the TensorFlow DeepSpeech model to the Model Optimizer with the following parameters:
Where:
--freeze_placeholder_with_value input_lengths->[16]freezes sequence length--input input_node,previous_state_h/read,previous_state_c/readand--input_shape [1,16,19,26],[1,2048],[1,2048]replace the variables with a placeholder--output raw_logits,lstm_fused_cell/GatherNd,lstm_fused_cell/GatherNd_1gets data for the next model execution.