Model Optimizer is a cross-platform command-line tool that facilitates the transition between the training and deployment environment, performs static model analysis, and adjusts deep learning models for optimal execution on end-point target devices.
Model Optimizer process assumes you have a network model trained using a supported deep learning framework. The scheme below illustrates the typical workflow for deploying a trained deep learning model:
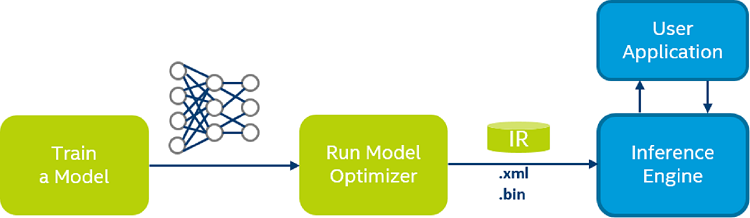
Model Optimizer produces an Intermediate Representation (IR) of the network, which can be read, loaded, and inferred with the Inference Engine. The Inference Engine API offers a unified API across a number of supported Intel® platforms. The Intermediate Representation is a pair of files describing the model:
.xml- Describes the network topology.bin- Contains the weights and biases binary data.
What's New in the Model Optimizer in this Release?
- Common changes:
- Implemented generation of a compressed OpenVINO IR suitable for INT8 inference, which takes up to 4 times less disk space than an expanded one. Use the
--disable_weights_compressionModel Optimizer command-line parameter to get an expanded version. - Implemented an optimization transformation to replace a sub-graph with the
Erfoperation into theGeLUoperation. - Implemented an optimization transformation to replace an upsamping pattern that is represnted as a sequence of
SplitandConcatoperations to a singleInterpolateoperation. - Fixed a number of Model Optimizer bugs to generate reshape-able IRs of many models with the command line parameter
--keep_shape_ops. - Fixed a number of Model Optimizer transformations to set operations name in an IR equal to the original framework model operation name.
- The following operations are no longer generated with
version="opset1":MVN,ROIPooling,ReorgYolo. They became a part of newopset2operation set and generated withversion="opset2". Before this fix, the operations were generated withversion="opset1"by mistake, they were not a part ofopset1nGraph namespace;opset1specification was fixed accordingly.
- Implemented generation of a compressed OpenVINO IR suitable for INT8 inference, which takes up to 4 times less disk space than an expanded one. Use the
- ONNX*:
- Added support for the following operations:
MeanVarianceNormalizationif normalization is performed over spatial dimensions.
- Added support for the following operations:
- TensorFlow*:
- Added support for the TensorFlow Object Detection models version 1.15.X.
- Added support for the following operations:
BatchToSpaceND,SpaceToBatchND,Floor.
- MXNet*:
- Added support for the following operations:
Reshapewith input shape values equal to -2, -3, and -4.
- Added support for the following operations:
NOTE: Intel® System Studio is an all-in-one, cross-platform tool suite, purpose-built to simplify system bring-up and improve system and IoT device application performance on Intel® platforms. If you are using the Intel® Distribution of OpenVINO™ with Intel® System Studio, go to Get Started with Intel® System Studio.
Table of Content
- Introduction to Intel® Deep Learning Deployment Toolkit
- Preparing and Optimizing your Trained Model with Model Optimizer
- Configuring Model Optimizer
- Converting a Model to Intermediate Representation (IR)
- Converting a Model Using General Conversion Parameters
- Converting Your Caffe* Model
- Converting Your TensorFlow* Model
- Converting BERT from TensorFlow
- Converting GNMT from TensorFlow
- Converting YOLO from DarkNet to Tensorflow and then to IR
- Converting Wide and Deep Models from TensorFlow
- Converting FaceNet from TensorFlow
- Converting DeepSpeech from TensorFlow
- Converting Language Model on One Billion Word Benchmark from TensorFlow
- Converting Neural Collaborative Filtering Model from TensorFlow*
- Converting TensorFlow* Object Detection API Models
- Converting TensorFlow*-Slim Image Classification Model Library Models
- Converting CRNN Model from TensorFlow*
- Converting Your MXNet* Model
- Converting Your Kaldi* Model
- Converting Your ONNX* Model
- Model Optimizations Techniques
- Cutting parts of the model
- Sub-graph Replacement in Model Optimizer
- Supported Framework Layers
- Intermediate Representation and Operation Sets
- Operations Specification
- Intermediate Representation suitable for INT8 inference
- Custom Layers in Model Optimizer
- Model Optimizer Frequently Asked Questions
- Known Issues
Typical Next Step: Introduction to Intel® Deep Learning Deployment Toolkit