Introduction
The purpose of this document is to provide best-known methods on how to use low-precision capabilities of the OpenVINO toolkit. Currently, these capabilities are represented by several components:
- Low-precision runtime
- Post-training Optimization Toolkit (POT)
- Neural Network Compression Framework (NNCF)
The first two components are the part of OpenVINO toolkit itself while the latter one represents OpenVINO extension which is highly aligned with toolkit and called OpenVINO Training Extensions (OTE).
This document covers high level aspects of model optimization flow in OpenVINO.
General information
By low precision we imply the inference of Deep Learning models in the precision which is lower than 32 or 16 bits, such as FLOAT32 and FLOAT16. For example, the most popular bit-width for the low-precision inference is INT8 (UINT8). Such models are represented by the quantized models, i.e. the models that were trained in the floating-point precision and then transformed to integer representation with floating/fixed-point quantization operations between the layers.
Starting from the OpenVINO 2020.1 release all the quantized models are represented using so-called FakeQuantize layer which is a very expressive primitive and is able to represent such operations as Quantize, Dequantize, Requantize, and even more. For more details about this operation please refer to the following description.
In order to execute such "fake-quantized" models, OpenVINO has a low-precision runtime which consists from a generic part translating the model to real integer representation and HW-specific part implemented in the corresponding HW plug-ins.
Model optimization flow
The diagram below shows a common optimization flow for the new model with OpenVINO and relative tools.
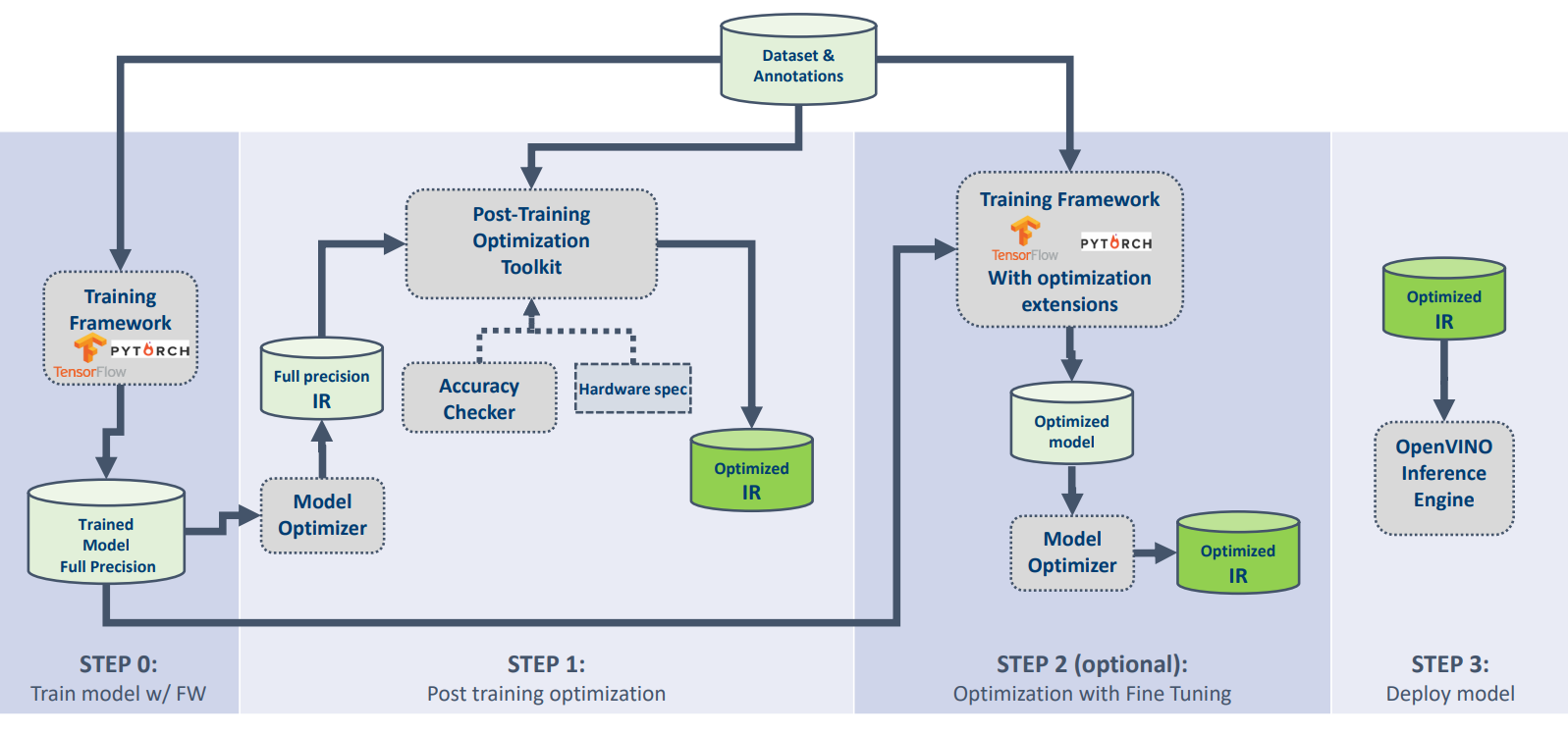
- Model enabling step: as a zero-step, we assume that the model is trained on the target dataset and can be successfully inferred with OpenVINO IE in floating-point precision.
Note: this step presumes that the model has the same accuracy as in the original training framework and enabled in the AccuracyChecker tool or through the custom validation sample. - Post-training quantization: for the first step for optimization, we suggest using INT8 quantization from POT where in most cases it is possible to get an accurate quantized model. At this step you do not need model re-training. The only thing required is a representative dataset which is usually several hundreds of images and it is used to collect statistics during the quantization process. Post-training quantization is also really fast and usually takes several minutes depending on the model size and used HW. And, generally, a regular desktop system is enough to quantize most of OpenVINO Model Zoo. For more information on best practices of post-training optimization please refer to this document.
- QAT: If the accuracy of the quantized model does not satisfy accuracy criteria, there is step two which implies Quantization-aware Training (QAT) using OpenVINO compatible training frameworks. At this step, we assume the user has an original training pipeline of the model written on TensorFlow or PyTorch. After this step, you can get an accurate optimized model that can be converted to OpenVINO Intermediate Representation (IR) using Model Optimizer component and inferred with OpenVINO Inference Engine.