This specification document describes opset1 operation set supported in OpenVINO. Support for each particular operation from the list below depends on the capabilities available in a inference plugin and may vary among different hardware platforms and devices. Examples of operation instances are expressed as IR V10 xml snippets. Such IR is generated by the Model Optimizer. The semantics match corresponding nGraph operation classes declared in namespace opset1.
Table of Contents
- Abs
- Acos
- Acosh
- Add
- Asin
- Asinh
- Atan
- Atanh
- AvgPool
- BatchNormInference
- BinaryConvolution
- Broadcast
- CTCGreadyDecoder
- Ceiling
- Clamp
- Concat
- Constant
- Convert
- ConvertLike
- Convolution
- ConvolutionBackpropData
- Cos
- Cosh
- DeformableConvolution
- DeformablePSROIPooling
- DepthToSpace
- DetectionOutput
- Divide
- Elu
- Erf
- Equal
- Exp
- FakeQuantize
- Floor
- FloorMod
- Gather
- GatherTree
- Greater
- GreaterEqual
- GroupConvolution
- GRN
- GroupConvolutionBackpropData
- HardSigmoid
- Interpolate
- Less
- LessEqual
- Log
- LogicalAnd
- LogicalNot
- LogicalOr
- LogicalXor
- LRN
- LSTMCell
- LSTMSequence
- MatMul
- MaxPool
- Maximum
- Minimum
- Mod
- Multiply
- MVN
- Negative
- NonMaxSuppression
- NormalizeL2
- NotEqual
- OneHot
- PReLU
- PSROIPooling
- Pad
- Parameter
- Power
- PriorBox
- PriorBoxClustered
- Proposal
- Range
- ReLU
- ReduceLogicalAnd
- ReduceLogicalOr
- ReduceMax
- ReduceMean
- ReduceMin
- ReduceProd
- ReduceSum
- RegionYolo
- ReorgYolo
- Reshape
- Result
- Reverse
- ReverseSequence
- RNNCell
- ROIPooling
- Select
- ShapeOf
- ShuffleChannels
- Sign
- Sigmoid
- Sin
- Sinh
- Softmax
- Sqrt
- SpaceToDepth
- Split
- SquaredDifference
- Squeeze
- StridedSlice
- Subtract
- Tan
- Tanh
- TensorIterator
- Tile
- TopK
- Transpose
- Unsqueeze
- VariadicSplit
Sigmoid
Category: Activation function
Short description: Sigmoid element-wise activation function.
Attributes: operations has no attributes.
Inputs:
- 1: Input tensor x of any floating point type. Required.
Outputs:
- 1: Result of Sigmoid function applied to the input tensor x. Floating point tensor with shape and type matching the input tensor. Required.
Mathematical Formulation
For each element from the input tensor calculates corresponding element in the output tensor with the following formula:
![\[ sigmoid( x ) = \frac{1}{1+e^{-x}} \]](form_25.png)
Tanh
Category: Activation function
Short description: Tanh element-wise activation function.
Attributes: has no attributes
Inputs:
- 1: Input tensor x of any floating point type. Required.
Outputs:
- 1: Result of Tanh function applied to the input tensor x. Floating point tensor with shape and type matching the input tensor. Required.
Detailed description
For each element from the input tensor calculates corresponding element in the output tensor with the following formula:
![\[ tanh ( x ) = \frac{2}{1+e^{-2x}} - 1 = 2sigmoid(2x) - 1 \]](form_26.png)
Elu
Category: Activation function
Short description: Exponential linear unit element-wise activation function.
Detailed Description
For each element from the input tensor calculates corresponding element in the output tensor with the following formula:
![\[ elu(x) = \left\{\begin{array}{ll} alpha(e^{x} - 1) \quad \mbox{if } x < 0 \\ x \quad \mbox{if } x \geq 0 \end{array}\right. \]](form_27.png)
Attributes
- alpha
- Description: scale for the negative factor
- Range of values: arbitrary floating point number
- Type: float
- Default value: none
- Required: yes
Inputs:
- 1: Input tensor x of any floating point type. Required.
Outputs:
- 1: Result of Elu function applied to the input tensor x. Floating point tensor with shape and type matching the input tensor. Required.
Erf
Category: Arithmetic unary operation
Short description: Erf calculates the Gauss error function element-wise with given tensor.
Detailed Description
For each element from the input tensor calculates corresponding element in the output tensor with the following formula:
![\[ erf(x) = \pi^{-1} \int_{-x}^{x} e^{-t^2} dt \]](form_28.png)
Attributes:
No attributes available.
Inputs
- 1: A tensor of type T. Required.
Outputs
- 1: The result of element-wise operation. A tensor of type T.
Types
- T: any supported floating point type.
Examples
Example 1
Selu
Category: Arithmetic unary operation
Short description: Selu calculates the SELU activation function (https://arxiv.org/abs/1706.02515) element-wise with given tensor.
Detailed Description
For each element from the input tensor calculates corresponding element in the output tensor with the following formula:
![\[ selu(x) = \lambda \left\{\begin{array}{ll} \alpha(e^{x} - 1) \quad \mbox{if } x \le 0 \\ x \quad \mbox{if } x > 0 \end{array}\right. \]](form_29.png)
Attributes:
No attributes available.
Inputs
- 1: An tensor of type T. Required.
- 2:
alpha1D tensor with one element of type T. Required. - 3:
lambda1D tensor with one element of type T. Required.
Outputs
- 1: The result of element-wise operation. A tensor of type T.
Types
- T: any supported floating point type.
Examples
Example 1
FloorMod
Category: Arithmetic binary operation
Short description: FloorMod returns an element-wise division reminder with two given tensors applying multi-directional broadcast rules. The result here is consistent with a flooring divide (like in Python programming language): floor(x / y) * y + mod(x, y) = x. The sign of the result is equal to a sign of the divisor.
Attributes:
- auto_broadcast
- Description: specifies rules used for auto-broadcasting of input tensors.
- Range of values:
- none - no auto-broadcasting is allowed, all input shapes should match
- numpy - numpy broadcasting rules, aligned with ONNX Broadcasting. Description is available in ONNX docs.
- Type: string
- Default value: "numpy"
- Required: no
Inputs
- 1: A tensor of type T. Required.
- 2: A tensor of type T. Required.
Outputs
- 1: The element-wise division reminder. A tensor of type T.
Types
- T: any numeric type.
Examples
Example 1
Example 2: broadcast
Mod
Category: Arithmetic binary operation
Short description: Mod returns an element-wise division reminder with two given tensors applying multi-directional broadcast rules. The result here is consistent with a truncated divide (like in C programming language): truncated(x / y) * y + truncated_mod(x, y) = x. The sign of the result is equal to a sign of a dividend.
Attributes:
- auto_broadcast
- Description: specifies rules used for auto-broadcasting of input tensors.
- Range of values:
- none - no auto-broadcasting is allowed, all input shapes should match
- numpy - numpy broadcasting rules, aligned with ONNX Broadcasting. Description is available in ONNX docs.
- Type: string
- Default value: "numpy"
- Required: no
Inputs
- 1: A tensor of type T. Required.
- 2: A tensor of type T. Required.
Outputs
- 1: The element-wise division reminder. A tensor of type T.
Types
- T: any numeric type.
Examples
Example 1
Example 2: broadcast
HardSigmoid
Category: Activation function
Short description: HardSigmoid calculates the hard sigmoid function y(x) = max(0, min(1, alpha * x + beta)) element-wise with given tensor.
Attributes:
No attributes available.
Inputs
- 1: An tensor of type T. Required.
- 2:
alpha0D tensor (scalar) of type T. Required. - 3:
beta0D tensor (scalar) of type T. Required.
Outputs
- 1: The result of the hard sigmoid operation. A tensor of type T.
Types
- T: any floating point type.
Examples
ShuffleChannels
Name: ShuffleChannels
Category: Layer
Short description: ShuffleChannels permutes data in the channel dimension of the input tensor.
Attributes:
- axis
- Description: axis specifies the index of a channel dimension.
- Range of values: an integer number in the range [-4, 3]
- Type:
int - Default value: 1
- Required: No
- group
- Description: group specifies the number of groups to split the channel dimension into. This number must evenly divide the channel dimension size.
- Range of values: a positive integer
- Type:
int - Default value: 1
- Required: No
Inputs:
- 1: 4D input tensor of any supported data type. Required.
Outputs:
- 1: 4D input tensor with shape and element type as for the input tensor.
Mathematical Formulation
The operation is the equivalent with the following transformation of the input tensor x of shape [N, C, H, W]:
where group is the layer parameter described above and the axis = 1.
Example
NonMaxSuppression
Short description: NonMaxSuppression performs non maximum suppression of the boxes with predicted scores.
Detailed description: NonMaxSuppression layer performs non maximum suppression algorithm as described below:
- Take the box with highest score. If the score is less than
score_thresholdthen stop. Otherwise add the box to the output and continue to the next step. - For each input box, calculate the IOU (intersection over union) with the box added during the previous step. If the value is greater than the
iou_thresholdthreshold then remove the input box from further consideration. - Return to step 1.
This algorithm is applied independently to each class of each batch element. The total number of output boxes for each class must not exceed max_output_boxes_per_class.
Attributes:
- box_encoding
- Description: box_encoding specifies the format of boxes data encoding.
- Range of values: "corner" or "center"
- corner - the box data is supplied as
[y1, x1, y2, x2]where(y1, x1)and(y2, x2)are the coordinates of any diagonal pair of box corners. - center - the box data is supplied as
[x_center, y_center, width, height].
- corner - the box data is supplied as
- Type: string
- Default value: "corner"
- Required: no
- sort_result_descending
- Description: sort_result_descending is a flag that specifies whenever it is necessary to sort selected boxes across batches or not.
- Range of values: True of False
- True - sort selected boxes across batches.
- False - do not sort selected boxes across batches (boxes are sorted per class).
- Type: boolean
- Default value: True
- Required: no
Inputs:
- 1:
boxes- floating point tensor of shape[num_batches, num_boxes, 4]with box coordinates. Required. - 2:
scores- floating point tensor of shape[num_batches, num_classes, num_boxes]with box scores. Required. - 3:
max_output_boxes_per_class- integer scalar tensor specifying maximum number of boxes to be selected per class. Optional with default value 0 meaning select no boxes. - 4:
iou_threshold- floating point scalar tensor specifying intersection over union threshold. Optional with default value 0 meaning keep all boxes. - 5:
score_threshold- floating point scalar tensor specifying minimum score to consider box for the processing. Optional with default value 0.
Outputs:
- 1:
selected_indices- integer tensor of shape[min(num_boxes, max_output_boxes_per_class * num_classes), 3]containing information about selected boxes as triplets[batch_index, class_index, box_index]. The output tensor is filled with 0s for output tensor elements if the total number of selected boxes is less than the output tensor size.
Example
Equal
Category: Comparison binary operation
Short description: Equal performs element-wise comparison operation with two given tensors applying multi-directional broadcast rules.
Attributes:
- auto_broadcast
- Description: specifies rules used for auto-broadcasting of input tensors.
- Range of values:
- none - no auto-broadcasting is allowed, all input shapes should match
- numpy - numpy broadcasting rules, aligned with ONNX Broadcasting. Description is available in ONNX docs.
- Type: string
- Default value: "numpy"
- Required: no
Inputs
- 1: A tensor of type T. Required.
- 2: A tensor of type T. Required.
Outputs
- 1: The result of element-wise comparison operation. A tensor of type boolean.
Types
- T: arbitrary supported type.
Detailed description Before performing arithmetic operation, input tensors a and b are broadcasted if their shapes are different and auto_broadcast attributes is not none. Broadcasting is performed according to auto_broadcast value.
After broadcasting Equal does the following with the input tensors a and b:
![\[ o_{i} = a_{i} == b_{i} \]](form_30.png)
Examples
Example 1
Example 2: broadcast
Clamp
Category: Activation function
Short description: Clamp operation represents clipping activation function.
Attributes:
- min
- Description: min is the lower bound of values in the output. Any value in the input that is smaller than the bound, is replaced with the min value. For example, min equal 10 means that any value in the input that is smaller than the bound, is replaced by 10.
- Range of values: non-negative positive floating point number
- Type: float
- Default value: None
- Required: yes
- max
- Description: max is the upper bound of values in the output. Any value in the input that is greater than the bound, is replaced with the max value. For example, max equals 50 means that any value in the input that is greater than the bound, is replaced by 50.
- Range of values: positive floating point number
- Type: float
- Default value: None
- Required: yes
Inputs:
- 1: Multidimensional input tensor. Required.
Outputs:
- 1: Multidimensional output tensor with shape and type matching the input tensor. Required.
Detailed description:
Clamp does the following with the input tensor element-wise:
![\[ clamp( x )=\left\{\begin{array}{ll} max\_value \quad \mbox{if } \quad input( x )>max\_value \\ min\_value \quad \mbox{if } \quad input( x ) \end{array}\right. \]](form_31.png)
Example
Constant
Category: Infrastructure
Short description: Constant operation produces a tensor with content read from binary file by offset and size.
Attributes
- offset
- Description: specifies position in binary file with weights where the content of the constant begins; value in bytes
- Range of values: non-negative integer value
- Type: int
- Default value: none
- Required: yes
- size
- Description: size of constant content in binary files; value in bytes
- Range of values: positive integer bigger than zero
- Type: int
- Default value: none
- Required: yes
- element_type
- Description: the type of element of output tensor
- Range of values: u1, u8, u16, u32, u64, i8, i16, i32, i64, f16, f32, boolean, bf16
- Type: string
- Default value: None
- Required: Yes
- shape
- Description: the shape of the output tensor
- Range of values: list of non-negative integers, empty list is allowed, which means 0D or scalar tensor
- Type: int[]
- Default value: None
- Required: Yes
Example
Concat
Category: data movement operation.
Short description: Concatenates arbitrary number of input tensors to a single output tensor along one axis.
Attributes:
- axis
- Description: axis specifies dimension to concatenate along
- Range of values: integer number greater or equal to 0
- Type: int
- Default value: None
- Required: yes
Inputs:
- 1..N: Arbitrary number of input tensors of any type. Types of all tensors should match. Rank of all tensors should match. The rank is positive, so scalars as inputs are not allowed. Shapes for all inputs should match at every position except
axisposition. At least one input is required.
Outputs:
- 1: Tensor of the same type as input tensor and shape
[d1, d2, ..., d_axis, ...], whered_axisis a sum of sizes of input tensors alongaxisdimension.
Example
Convolution
Category: Convolution
Short description: Reference
Detailed description: Reference
- For the convolutional layer, the number of output features in each dimension is calculated using the formula:
![\[ n_{out} = \left ( \frac{n_{in} + 2p - k}{s} \right ) + 1 \]](form_32.png)
- The receptive field in each layer is calculated using the formulas:
- Jump in the output feature map:
![\[ j_{out} = j_{in} * s \]](form_33.png)
- Size of the receptive field of output feature:
![\[ r_{out} = r_{in} + ( k - 1 ) * j_{in} \]](form_34.png)
- Center position of the receptive field of the first output feature:
![\[ start_{out} = start_{in} + ( \frac{k - 1}{2} - p ) * j_{in} \]](form_35.png)
- Output is calculated using the following formula:
![\[ out = \sum_{i = 0}^{n}w_{i}x_{i} + b \]](form_36.png)
- Jump in the output feature map:
Attributes
- strides
- Description: strides is a distance (in pixels) to slide the filter on the feature map over the (z, y, x) axes for 3D convolutions and (y, x) axes for 2D convolutions. For example, strides equal 4,2,1 means sliding the filter 4 pixel at a time over depth dimension, 2 over height dimension and 1 over width dimension.
- Range of values: integer values starting from 0
- Type: int[]
- Default value: None
- Required: yes
- pads_begin
- Description: pads_begin is a number of pixels to add to the beginning along each axis. For example, pads_begin equal 1,2 means adding 1 pixel to the top of the input and 2 to the left of the input.
- Range of values: integer values starting from 0
- Type: int[]
- Default value: None
- Required: yes
- pads_end
- Description: pads_end is a number of pixels to add to the ending along each axis. For example, pads_end equal 1,2 means adding 1 pixel to the bottom of the input and 2 to the right of the input.
- Range of values: integer values starting from 0
- Type: int[]
- Default value: None
- Required: yes
- dilations
- Description: dilations denotes the distance in width and height between elements (weights) in the filter. For example, dilation equal 1,1 means that all the elements in the filter are neighbors, so it is the same as for the usual convolution. dilation equal 2,2 means that all the elements in the filter are matched not to adjacent elements in the input matrix, but to those that are adjacent with distance 1.
- Range of values: integer value starting from 0
- Type: int[]
- Default value: None
- Required: yes
- auto_pad
- Description: auto_pad how the padding is calculated. Possible values:
- Not specified: use explicit padding values.
- same_upper (same_lower) the input is padded to match the output size. In case of odd padding value an extra padding is added at the end (at the beginning).
- valid - do not use padding.
- Type: string
- Default value: None
- Required: no
- Description: auto_pad how the padding is calculated. Possible values:
Inputs:
- 1: Input tensor of rank 3 or greater. Required.
- 2: Convolution kernel tensor. Weights layout is OIYX (OIZYX for 3D convolution), which means that X is changing the fastest, then Y, then Input, then Output. The size of the kernel is derived from the shape of this input and not specified by any attribute. Required.
Example
ConvolutionBackpropData
Category: Convolution
Short description: Computes the gradients of a Convolution operation with respect to the input. Also known as a Deconvolution or a Transposed Convolution.
Detailed description:
ConvolutionBackpropData takes the input tensor, weights tensor and output shape and computes the output tensor of a given shape. The shape of the output can be specified as an input 1D integer tensor explicitly or determined by other attributes implicitly. If output shape is specified as an explicit input, shape of the output exactly matches the specified size and required amount of padding is computed.
ConvolutionBackpropData accepts the same set of attributes as a regular Convolution operation, but they are interpreted in a "backward way", so they are applied to the output of ConvolutionBackpropData, but not to the input. Refer to a regular Convolution operation for detailed description of each attribute.
Output shape when specified as an input output_shape, specifies only spatial dimensions. No batch or channel dimension should be passed along with H, W or other spatial dimensions. If output_shape is omitted, then pads_begin, pads_end or auto_pad are used to determine output spatial shape [Y_1, Y_2, ..., Y_D] by input spatial shape [X_1, X_2, ..., X_D] in the following way:
where K_i filter kernel dimension along spatial axis i.
If output_shape is specified, neither pads_begin nor pads_end should be specified, but auto_pad defines how to distribute padding amount around the tensor. In this case pads are determined based on the next formulas to correctly align input and output tensors (similar to ONNX definition at https://github.com/onnx/onnx/blob/master/docs/Operators.md#convtranspose):
Attributes
- strides
- Description: strides has the same definition as strides for a regular Convolution but applied in the backward way, for the output tensor.
- Range of values: positive integers
- Type: int[]
- Default value: None
- Required: yes
- pads_begin
- Description: pads_begin has the same definition as pads_begin for a regular Convolution but applied in the backward way, for the output tensor. May be omitted specified, in which case pads are calculated automatically.
- Range of values: non-negative integers
- Type: int[]
- Default value: None
- Required: yes
- pads_end
- Description: pads_end has the same definition as pads_end for a regular Convolution but applied in the backward way, for the output tensor. May be omitted, in which case pads are calculated automatically.
- Range of values: non-negative integers
- Type: int[]
- Default value: None
- Required: yes
- dilations
- Description: dilations has the same definition as dilations for a regular Convolution but applied in the backward way, for the output tensor.
- Range of values: positive integers
- Type: int[]
- Default value: None
- Required: yes
- auto_pad
- Description: auto_pad has the same definition as auto_pad for a regular Convolution but applied in the backward way, for the output tensor.
- None (not specified): use explicit padding values from
pads_beginandpads_end. - same_upper (same_lower) the input is padded to match the output size. In case of odd padding value an extra padding is added at the end (at the beginning).
- valid - do not use padding.
- None (not specified): use explicit padding values from
- Type: string
- Default value: None
- Required: no
- Description: auto_pad has the same definition as auto_pad for a regular Convolution but applied in the backward way, for the output tensor.
- output_padding
- Description: output_padding adds additional amount of paddings per each spatial axis in the
outputtensor. It unlocks more elements in the output allowing them to be computed. Elements are added at the higher coordinate indices for the spatial dimensions. Number of elements in output_padding list matches the number of spatial dimensions indataandoutputtensors. - Range of values: non-negative integer values
- Type: int[]
- Default value: all zeros
- Required: no
- Description: output_padding adds additional amount of paddings per each spatial axis in the
Inputs:
- 1:
data– input tensor of rank 3 or greater. Layout is[N, C_INPUT, X1, ..., XD]. Required. - 2:
filter– convolution kernel tensor. Weights have shape[C_INPUT, C_OUTPUT, K_D, ..., K_1].C_INPUTis the number of channels in inputdatatensor shape, andC_OUTPUTis the number of channels in theoutputtensor. Spatial size of the kernel[K_D, ..., K_1]is derived from the shape of this input and aren't specified by any attribute. Required. - 3:
output_shapeis 1D integer tensor that specifies spatial shape of the output. Optional. If specified, padding amount is deduced from relation of input and output spatial shapes according to formulas in the description. If not specified, output shape is calculated based on thepads_beginandpads_endor completely according toauto_pad.
Outputs:
- 1:
output– output tensor of the same rank as inputdatatensor and shape[N, C_OUTPUT, Y1, ..., YD].
Example
GRN
Category: Normalization
Short description: GRN is the Global Response Normalization with L2 norm (across channels only).
Detailed description:
GRN computes the L2 norm by channels for input tensor with shape [N, C, ...]. GRN does the following with the input tensor:
output[i0, i1, ..., iN] = x[i0, i1, ..., iN] / sqrt(sum[j = 0..C-1](x[i0, j, ..., iN]**2) + bias)
Attributes:
- bias
- Description: bias is added to the variance.
- Range of values: a non-negative floating point value
- Type:
float - Default value: None
- Required: yes
Inputs
- 1: Input tensor with element of any floating point type and
2 <= rank <=4. Required.
Outputs
- 1: Output tensor of the same type and shape as the input tensor.
Example
GroupConvolution
Category: Convolution
Short description: Reference
Detailed description: Reference
Attributes
- strides
- Description: strides is a distance (in pixels) to slide the filter on the feature map over the (z, y, x) axes for 3D convolutions and (y, x) axes for 2D convolutions. For example, strides equal 4,2,1 means sliding the filter 4 pixel at a time over depth dimension, 2 over height dimension and 1 over width dimension.
- Range of values: positive integer numbers
- Type: int[]
- Default value: None
- Required: yes
- pads_begin
- Description: pads_begin is a number of pixels to add to the beginning along each axis. For example, pads_begin equal 1,2 means adding 1 pixel to the top of the input and 2 to the left of the input.
- Range of values: positive integer numbers
- Type: int[]
- Default value: None
- Required: yes
- pads_end
- Description: pads_end is a number of pixels to add to the ending along each axis. For example, pads_end equal 1,2 means adding 1 pixel to the bottom of the input and 2 to the right of the input.
- Range of values: positive integer numbers
- Type: int[]
- Default value: None
- Required: yes
- dilations
- Description: dilations denotes the distance in width and height between elements (weights) in the filter. For example, dilation equal 1,1 means that all the elements in the filter are neighbors, so it is the same as for the usual convolution. dilation equal 2,2 means that all the elements in the filter are matched not to adjacent elements in the input matrix, but to those that are adjacent with distance 1.
- Range of values: positive integer numbers
- Type: int[]
- Default value: None
- Required: yes
- auto_pad
- Description: auto_pad how the padding is calculated. Possible values:
- Not specified: use explicit padding values.
- same_upper (same_lower) the input is padded to match the output size. In case of odd padding value an extra padding is added at the end (at the beginning).
- valid - do not use padding.
- Type: string
- Default value: None
- Required: yes
- Description: auto_pad how the padding is calculated. Possible values:
Inputs:
- 1: 4D or 5D input tensor. Required.
- 2: Convolution kernel tensor. Weights layout is GOIYX (GOIZYX for 3D convolution), which means that X is changing the fastest, then Y, then Input, Output and Group. The size of kernel and number of groups are derived from the shape of this input and aren't specified by any attribute. Required.
Mathematical Formulation
- For the convolutional layer, the number of output features in each dimension is calculated using the formula:
- The receptive field in each layer is calculated using the formulas:
- Jump in the output feature map:
- Size of the receptive field of output feature:
- Center position of the receptive field of the first output feature:
- Output is calculated using the following formula:
- Jump in the output feature map:
Example
GroupConvolutionBackpropData
Category: Convolution
Short description: Computes the gradients of a GroupConvolution operation with respect to the input. Also known as Deconvolution or Transposed Convolution.
Detailed description:
GroupConvolutionBackpropData is similar to ConvolutionBackpropData but also specifies the group processing in a way similar to how GroupConvolution extends behavior of a regular Convolution operation.
GroupConvolutionBackpropData takes input tensor, weights tensor and output shape and computes output tensor of a given shape. The shape of the output can be specified as an input 1D integer tensor explicitly or determined according to other attributes implicitly. If the output shape is specified as an explicit input, shape of the output exactly matches the specified size and required amount of padding is computed.
GroupConvolutionBackpropData accepts the same set of attributes as a regular GroupConvolution operation, but they are interpreted in a "backward way", so they are applied to the output of GroupConvolutionBackpropData, but not to the input. Refer to a regular GroupConvolution operation for detailed description of each attribute.
Output shape when specified as an input output_shape, specifies only spatial dimensions. No batch or channel dimension should be passed along with H, W or other spatial dimensions. If output_shape is omitted, then pads_begin, pads_end or auto_pad are used to determine output spatial shape [Y_1, Y_2, ..., Y_D] by input spatial shape [X_1, X_2, ..., X_D] in the following way:
where K_i filter kernel dimension along spatial axis i.
If output_shape is specified, neither pads_begin nor pads_end should be specified, but auto_pad defines how to distribute padding amount around the tensor. In this case pads are determined based on the next formulas to correctly align input and output tensors (similar to ONNX definition at https://github.com/onnx/onnx/blob/master/docs/Operators.md#convtranspose):
Attributes
- strides
- Description: strides has the same definition as strides for a regular Convolution but applied in the backward way, for the output tensor.
- Range of values: positive integers
- Type: int[]
- Default value: None
- Required: yes
- pads_begin
- Description: pads_begin has the same definition as pads_begin for a regular Convolution but applied in the backward way, for the output tensor. May be omitted, in which case pads are calculated automatically.
- Range of values: non-negative integers
- Type: int[]
- Default value: None
- Required: yes
- pads_end
- Description: pads_end has the same definition as pads_end for a regular Convolution but applied in the backward way, for the output tensor. May be omitted, in which case pads are calculated automatically.
- Range of values: non-negative integers
- Type: int[]
- Default value: None
- Required: yes
- dilations
- Description: dilations has the same definition as dilations for a regular Convolution but applied in the backward way, for the output tensor.
- Range of values: positive integers
- Type: int[]
- Default value: None
- Required: yes
- auto_pad
- Description: auto_pad has the same definition as auto_pad for a regular Convolution but applied in the backward way, for the output tensor.
- None (not specified): use explicit padding values from
pads_beginandpads_end. - same_upper (same_lower) the input is padded to match the output size. In case of odd padding value an extra padding is added at the end (at the beginning).
- valid - do not use padding.
- None (not specified): use explicit padding values from
- Type: string
- Default value: None
- Required: no
- Description: auto_pad has the same definition as auto_pad for a regular Convolution but applied in the backward way, for the output tensor.
- output_padding
- Description: output_padding adds additional amount of paddings per each spatial axis in the
outputtensor. It unlocks more elements in the output allowing them to be computed. Elements are added at the higher coordinate indices for the spatial dimensions. Number of elements in output_padding list matches the number of spatial dimensions indataandoutputtensors. - Range of values: non-negative integer values
- Type: int[]
- Default value: all zeros
- Required: no
- Description: output_padding adds additional amount of paddings per each spatial axis in the
Inputs:
- 1:
data– input tensor of rank 3 or greater. Layout is[N, C_INPUT * GROUPS, X1, ..., XD], whereGROUPSis the number of groups that is specified as a dedicated dimension infilterinput. Required. - 2:
filter– convolution kernel tensor. Weights have shape[GROUPS, C_INPUT, C_OUTPUT, K_D, ..., K_1].C_INPUTis the number of channels in inputdatatensor shape, andC_OUTPUTis the number of channels in theoutputtensor.GROUPSis the number of groups in input/output channel dimension. Spatial size of the kernel[K_D, ..., K_1]is derived from the shape of this input and not specified by any attribute. Required. - 3:
output_shapeis 1D integer tensor that specifies spatial shape of the output. Optional. If specified, padding amount is deduced from relation of input and output spatial shapes according to formulas in the description. If not specified, output shape is calculated based on thepads_beginandpads_endor completely according toauto_pad.
Outputs:
- 1:
output– output tensor of the same rank as inputdatatensor and shape[N, GROUPS * C_OUTPUT, Y1, ..., YD], whereGROUPSis the number of groups that is specified as a dedicated dimension infilterinput.
Example
MatMul
Category: Matrix multiplication
Short description: Generalized matrix multiplication
Detailed description
MatMul operation takes two tensors and performs usual matrix-matrix multiplication, matrix-vector multiplication or vector-matrix multiplication depending on argument shapes. Input tensors can have any rank >= 1. Two right-most axes in each tensor are interpreted as matrix rows and columns dimensions while all left-most axes (if present) are interpreted as multi-dimensional batch: [BATCH_DIM_1, BATCH_DIM_2,..., BATCH_DIM_K, ROW_INDEX_DIM, COL_INDEX_DIM]. The operation supports usual broadcast semantics for batch dimensions. It enables multiplication of batch of pairs of matrices in a single shot.
Before matrix multiplication, there is an implicit shape alignment for input arguments. It consists of the following steps:
- If rank of an input less than 2 it is unsqueezed to 2D tensor by adding axes with size 1 to the left of the shape. For example, if input has shape
[S]it will be reshaped to[1, S]. It is applied for each input independently. - Applied transpositions specified by optional
transpose_aandtranspose_battributes. - If ranks of input arguments are different after steps 1 and 2, each is unsqueezed from the left side of the shape by necessary number of axes to make both shapes of the same rank.
- Usual rules of the broadcasting are applied for batch dimensions.
Two attributes, transpose_a and transpose_b specifies embedded transposition for two right-most dimension for the first and the second input tensors correspondingly. It implies swapping of ROW_INDEX_DIM and COL_INDEX_DIM in the corresponding input tensor. Batch dimensions are not affected by these attributes.
Attributes
- transpose_a
- Description: transposes dimensions ROW_INDEX_DIM and COL_INDEX_DIM of the 1st input; 0 means no transpose, 1 means transpose
- Range of values: False or True
- Type: boolean
- Default value: False
- Required: no
- transpose_b
- Description: transposes dimensions ROW_INDEX_DIM and COL_INDEX_DIM of the 2nd input; 0 means no transpose, 1 means transpose
- Range of values: False or True
- Type: boolean
- Default value: False
- Required: no
Inputs:
- 1: Input batch of matrices A. Rank >= 1. Required.
- 2: Input batch of matrices B. Rank >= 1. Required.
Example
Vector-matric multiplication
Matrix-matrix multiplication (like FullyConnected with batch size 1)
Matrix-vector multiplication with embedded transposition of the second matrix
Matrix-matrix multiplication (like FullyConnected with batch size 10)
Multiplication of batch of 5 matrices by a one matrix with broadcasting
DetectionOutput
Category: Object detection
Short description: DetectionOutput performs non-maximum suppression to generate the detection output using information on location and confidence predictions.
Detailed description: Reference. The layer has 3 mandatory inputs: tensor with box logits, tensor with confidence predictions and tensor with box coordinates (proposals). It can have 2 additional inputs with additional confidence predictions and box coordinates described in the article. The 5-input version of the layer is supported with Myriad plugin only. The output tensor contains information about filtered detections described with 7 element tuples: [batch_id, class_id, confidence, x_1, y_1, x_2, y_2]. The first tuple with batch_id equal to *-1* means end of output.
At each feature map cell, DetectionOutput predicts the offsets relative to the default box shapes in the cell, as well as the per-class scores that indicate the presence of a class instance in each of those boxes. Specifically, for each box out of k at a given location, DetectionOutput computes class scores and the four offsets relative to the original default box shape. This results in a total of 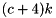 filters that are applied around each location in the feature map, yielding
filters that are applied around each location in the feature map, yielding 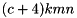 outputs for a m * n feature map.
outputs for a m * n feature map.
Attributes:
- num_classes
- Description: number of classes to be predicted
- Range of values: positive integer number
- Type: int
- Default value: None
- Required: yes
- background_label_id
- Description: background label id. If there is no background class, set it to -1.
- Range of values: integer values
- Type: int
- Default value: 0
- Required: no
- top_k
- Description: maximum number of results to be kept per batch after NMS step. -1 means keeping all bounding boxes.
- Range of values: integer values
- Type: int
- Default value: -1
- Required: no
- variance_encoded_in_target
- Description: variance_encoded_in_target is a flag that denotes if variance is encoded in target. If flag is false then it is necessary to adjust the predicted offset accordingly.
- Range of values: False or True
- Type: boolean
- Default value: False
- Required: no
- keep_top_k
- Description: maximum number of bounding boxes per batch to be kept after NMS step. -1 means keeping all bounding boxes after NMS step.
- Range of values: integer values
- Type: int[]
- Default value: None
- Required: yes
- code_type
- Description: type of coding method for bounding boxes
- Range of values: "caffe.PriorBoxParameter.CENTER_SIZE", "caffe.PriorBoxParameter.CORNER"
- Type: string
- Default value: "caffe.PriorBoxParameter.CORNER"
- Required: no
- share_location
- Description: share_location is a flag that denotes if bounding boxes are shared among different classes.
- Range of values: 0 or 1
- Type: int
- Default value: 1
- Required: no
- nms_threshold
- Description: threshold to be used in the NMS stage
- Range of values: floating point values
- Type: float
- Default value: None
- Required: yes
- confidence_threshold
- Description: only consider detections whose confidences are larger than a threshold. If not provided, consider all boxes.
- Range of values: floating point values
- Type: float
- Default value: 0
- Required: no
- clip_after_nms
- Description: clip_after_nms flag that denotes whether to perform clip bounding boxes after non-maximum suppression or not.
- Range of values: 0 or 1
- Type: int
- Default value: 0
- Required: no
- clip_before_nms
- Description: clip_before_nms flag that denotes whether to perform clip bounding boxes before non-maximum suppression or not.
- Range of values: 0 or 1
- Type: int
- Default value: 0
- Required: no
- decrease_label_id
- Description: decrease_label_id flag that denotes how to perform NMS.
- Range of values:
- 0 - perform NMS like in Caffe*.
- 1 - perform NMS like in MxNet*.
- Type: int
- Default value: 0
- Required: no
- normalized
- Description: normalized flag that denotes whether input tensors with boxes are normalized. If tensors are not normalized then input_height and input_width attributes are used to normalize box coordinates.
- Range of values: 0 or 1
- Type: int
- Default value: 0
- Required: no
- input_height (input_width)
- Description: input image height (width). If the normalized is 1 then these attributes are not used.
- Range of values: positive integer number
- Type: int
- Default value: 1
- Required: no
- objectness_score
- Description: threshold to sort out confidence predictions. Used only when the DetectionOutput layer has 5 inputs.
- Range of values: non-negative float number
- Type: float
- Default value: 0
- Required: no
Inputs
- 1: 2D input tensor with box logits. Required.
- 2: 2D input tensor with class predictions. Required.
- 3: 3D input tensor with proposals. Required.
- 4: 2D input tensor with additional class predictions information described in the article. Optional.
- 5: 2D input tensor with additional box predictions information described in the article. Optional.
Example
LRN
Category: Normalization
Short description: Local response normalization.
Attributes:
- alpha
- Description: alpha represents the scaling attribute for the normalizing sum. For example, alpha equal 0.0001 means that the normalizing sum is multiplied by 0.0001.
- Range of values: no restrictions
- Type: float
- Default value: None
- Required: yes
- beta
- Description: beta represents the exponent for the normalizing sum. For example, beta equal 0.75 means that the normalizing sum is raised to the power of 0.75.
- Range of values: positive number
- Type: float
- Default value: None
- Required: yes
- bias
- Description: beta represents the offset. Usually positive number to avoid dividing by zero.
- Range of values: no restrictions
- Type: float
- Default value: None
- Required: yes
- size
- Description: size represents the side length of the region to be used for the normalization sum. The region can have one or more dimensions depending on the second input axes indices.
- Range of values: positive integer
- Type: int
- Default value: None
- Required: yes
Inputs
- 1:
data- input tensor of any floating point type and arbitrary shape. Required. - 2:
axes- specifies indices of dimensions indatathat define normalization slices. Required.
Outputs
- 1: Output tensor of the same shape and type as the
datainput tensor.
Detailed description: Reference
Here is an example for 4D data input tensor and axes = [1]:
sqr_sum[a, b, c, d] =
sum(input[a, b - local_size : b + local_size + 1, c, d] ** 2)
output = input / (bias + alpha * sqr_sum) ** beta
Example
MaxPool
Category: Pooling
Short description: Reference
Detailed description: Reference
Attributes: Pooling attributes are specified in the data node, which is a child of the layer node.
- strides
- Description: strides is a distance (in pixels) to slide the window on the feature map over the (z, y, x) axes for 3D poolings and (y, x) axes for 2D poolings. For example, strides equal "4,2,1" means sliding the window 4 pixel at a time over depth dimension, 2 over height dimension and 1 over width dimension.
- Range of values: integer values starting from 0
- Type: int[]
- Default value: None
- Required: yes
- pads_begin
- Description: pads_begin is a number of pixels to add to the beginning along each axis. For example, pads_begin equal "1,2" means adding 1 pixel to the top of the input and 2 to the left of the input.
- Range of values: integer values starting from 0
- Type: int[]
- Default value: None
- Required: yes
- pads_end
- Description: pads_end is a number of pixels to add to the ending along each axis. For example, pads_end equal "1,2" means adding 1 pixel to the bottom of the input and 2 to the right of the input.
- Range of values: integer values starting from 0
- Type: int[]
- Default value: None
- Required: yes
- kernel
- Description: kernel is a size of each filter. For example, kernel equal (2, 3) means that each filter has height equal to 2 and width equal to 3.
- Range of values: integer values starting from 1
- Type: int[]
- Default value: None
- Required: yes
- rounding_type
- Description: rounding_type is a type of rounding to be applied.
- Range of values:
- ceil
- floor
- Type: string
- Default value: floor
- auto_pad
- Description: auto_pad how the padding is calculated. Possible values:
- Not specified: use explicit padding values.
- same_upper (same_lower) the input is padded to match the output size. In case of odd padding value an extra padding is added at the end (at the beginning).
- valid - do not use padding.
- Type: string
- Default value: None
- Required: no
- Description: auto_pad how the padding is calculated. Possible values:
Inputs:
- 1: 4D or 5D input tensor. Required.
Mathematical Formulation
![\[ output_{j} = MAX\{ x_{0}, ... x_{i}\} \]](form_39.png)
Example
AvgPool
Category: Pooling
Short description: Reference
Detailed description: Reference
Attributes: Pooling attributes are specified in the data node, which is a child of the layer node.
- strides
- Description: strides is a distance (in pixels) to slide the window on the feature map over the (z, y, x) axes for 3D poolings and (y, x) axes for 2D poolings. For example, strides equal "4,2,1" means sliding the window 4 pixel at a time over depth dimension, 2 over height dimension and 1 over width dimension.
- Range of values: integer values starting from 0
- Type: int[]
- Default value: None
- Required: yes
- pads_begin
- Description: pads_begin is a number of pixels to add to the beginning along each axis. For example, pads_begin equal "1,2" means adding 1 pixel to the top of the input and 2 to the left of the input.
- Range of values: integer values starting from 0
- Type: int[]
- Default value: None
- Required: yes
- pads_end
- Description: pads_end is a number of pixels to add to the ending along each axis. For example, pads_end equal "1,2" means adding 1 pixel to the bottom of the input and 2 to the right of the input.
- Range of values: integer values starting from 0
- Type: int[]
- Default value: None
- Required: yes
- kernel
- Description: kernel is a size of each filter. For example, kernel equal (2, 3) means that each filter has height equal to 2 and width equal to 3.
- Range of values: integer values starting from 1
- Type: int[]
- Default value: None
- Required: yes
- exclude_pad
- Description: exclude_pad is a type of pooling strategy for values in the padding area. For example, if exclude_pad is "true", zero-values in the padding are not used.
- Range of values: True or False
- Type: boolean
- Default value: None
- Required: yes
- rounding_type
- Description: rounding_type is a type of rounding to be applied.
- Range of values:
- ceil
- floor
- Type: string
- Default value: floor
- auto_pad
- Description: auto_pad how the padding is calculated. Possible values:
- Not specified: use explicit padding values.
- same_upper (same_lower) the input is padded to match the output size. In case of odd padding value an extra padding is added at the end (at the beginning).
- valid - do not use padding.
- Type: string
- Default value: None
- Required: no
- Description: auto_pad how the padding is calculated. Possible values:
Inputs:
- 1: 4D or 5D input tensor. Required.
Mathematical Formulation
![\[ output_{j} = \frac{\sum_{i = 0}^{n}x_{i}}{n} \]](form_40.png)
Example
PriorBox
Category: Object detection
Short description: PriorBox operation generates prior boxes of specified sizes and aspect ratios across all dimensions.
Attributes:
- min_size (max_size)
- Description: min_size (max_size) is the minimum (maximum) box size (in pixels). For example, min_size (max_size) equal 15 means that the minimum (maximum) box size is 15.
- Range of values: positive floating point numbers
- Type: float[]
- Default value: []
- Required: no
- aspect_ratio
- Description: aspect_ratio is a variance of aspect ratios. Duplicate values are ignored. For example, aspect_ratio equal "2.0,3.0" means that for the first box aspect_ratio is equal to 2.0 and for the second box is 3.0.
- Range of values: set of positive integer numbers
- Type: float[]
- Default value: []
- Required: no
- flip
- Description: flip is a flag that denotes that each aspect_ratio is duplicated and flipped. For example, flip equals 1 and aspect_ratio equals to "4.0,2.0" mean that aspect_ratio is equal to "4.0,2.0,0.25,0.5".
- Range of values:
- False - each aspect_ratio is flipped
- True - each aspect_ratio is not flipped
- Type: boolean
- Default value: False
- Required: no
- clip
- Description: clip is a flag that denotes if each value in the output tensor should be clipped to [0,1] interval.
- Range of values:
- False - clipping is not performed
- True - each value in the output tensor is clipped to [0,1] interval.
- Type: boolean
- Default value: False
- Required: no
- step
- Description: step is a distance between box centers. For example, step equal 85 means that the distance between neighborhood prior boxes centers is 85.
- Range of values: floating point non-negative number
- Type: float
- Default value: 0
- Required: no
- offset
- Description: offset is a shift of box respectively to top left corner. For example, offset equal 85 means that the shift of neighborhood prior boxes centers is 85.
- Range of values: floating point non-negative number
- Type: float
- Default value: None
- Required: yes
- variance
- Description: variance denotes a variance of adjusting bounding boxes. The attribute could contain 0, 1 or 4 elements.
- Range of values: floating point positive numbers
- Type: float[]
- Default value: []
- Required: no
- scale_all_sizes
- Description: scale_all_sizes is a flag that denotes type of inference. For example, scale_all_sizes equals 0 means that the PriorBox layer is inferred in MXNet-like manner. In particular, max_size attribute is ignored.
- Range of values:
- False - max_size is ignored
- True - max_size is used
- Type: boolean
- Default value: True
- Required: no
- fixed_ratio
- Description: fixed_ratio is an aspect ratio of a box. For example, fixed_ratio equal to 2.000000 means that the aspect ratio for the first box aspect ratio is 2.
- Range of values: a list of positive floating-point numbers
- Type:
float[] - Default value: None
- Required: no
- fixed_size
- Description: fixed_size is an initial box size (in pixels). For example, fixed_size equal to 15 means that the initial box size is 15.
- Range of values: a list of positive floating-point numbers
- Type:
float[] - Default value: None
- Required: no
- density
- Description: density is the square root of the number of boxes of each type. For example, density equal to 2 means that the first box generates four boxes of the same size and with the same shifted centers.
- Range of values: a list of positive floating-point numbers
- Type:
float[] - Default value: None
- Required: no
Inputs:
- 1:
output_size- 1D tensor with two integer elements[height, width]. Specifies the spatial size of generated grid with boxes. Required. - 2:
image_size- 1D tensor with two integer elements[image_height, image_width]that specifies shape of the image for which boxes are generated. Required.
Outputs:
- 1: 2D tensor of shape
[2, 4 * height * width * priors_per_point]with box coordinates. Thepriors_per_pointis the number of boxes generated per each grid element. The number depends on layer attribute values.
Detailed description:
PriorBox computes coordinates of prior boxes by following:
- First calculates center_x and center_y of prior box:
![\[ W \equiv Width \quad Of \quad Image \]](form_41.png)
![\[ H \equiv Height \quad Of \quad Image \]](form_42.png)
- If step equals 0:
![\[ center_x=(w+0.5) \]](form_43.png)
![\[ center_y=(h+0.5) \]](form_44.png)
- else:
![\[ center_x=(w+offset)*step \]](form_45.png)
![\[ center_y=(h+offset)*step \]](form_46.png)
![\[ w \subset \left( 0, W \right ) \]](form_47.png)
![\[ h \subset \left( 0, H \right ) \]](form_48.png)
- If step equals 0:
- Then, for each
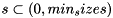 calculates coordinates of prior boxes:
calculates coordinates of prior boxes: ![\[ xmin = \frac{\frac{center_x - s}{2}}{W} \]](form_50.png)
![\[ ymin = \frac{\frac{center_y - s}{2}}{H} \]](form_51.png)
![\[ xmax = \frac{\frac{center_x + s}{2}}{W} \]](form_52.png)
![\[ ymin = \frac{\frac{center_y + s}{2}}{H} \]](form_53.png)
Example
PriorBoxClustered
Category: Object detection
Short description: PriorBoxClustered operation generates prior boxes of specified sizes normalized to the input image size.
Attributes
- width (height)
- Description: width (height) specifies desired boxes widths (heights) in pixels.
- Range of values: floating point positive numbers
- Type: float[]
- Default value: 1.0
- Required: no
- clip
- Description: clip is a flag that denotes if each value in the output tensor should be clipped within [0,1].
- Range of values:
- False - clipping is not performed
- True - each value in the output tensor is within [0,1]
- Type: boolean
- Default value: True
- Required: no
- step (step_w, step_h)
- Description: step (step_w, step_h) is a distance between box centers. For example, step equal 85 means that the distance between neighborhood prior boxes centers is 85. If both step_h and step_w are 0 then they are updated with value of step. If after that they are still 0 then they are calculated as input image width(height) divided with first input width(height).
- Range of values: floating point positive number
- Type: float
- Default value: 0.0
- Required: no
- offset
- Description: offset is a shift of box respectively to top left corner. For example, offset equal 85 means that the shift of neighborhood prior boxes centers is 85.
- Range of values: floating point positive number
- Type: float
- Default value: None
- Required: yes
- variance
- Description: variance denotes a variance of adjusting bounding boxes.
- Range of values: floating point positive numbers
- Type: float[]
- Default value: []
- Required: no
- img_h (img_w)
- Description: img_h (img_w) specifies height (width) of input image. These attributes are taken from the second input
image_sizeheight(width) unless provided explicitly as the value for this attributes. - Range of values: floating point positive number
- Type: float
- Default value: 0
- Required: no
- Description: img_h (img_w) specifies height (width) of input image. These attributes are taken from the second input
Inputs:
- 1:
output_size- 1D tensor with two integer elements[height, width]. Specifies the spatial size of generated grid with boxes. Required. - 2:
image_size- 1D tensor with two integer elements[image_height, image_width]that specifies shape of the image for which boxes are generated. Optional.
Outputs:
- 1: 2D tensor of shape
[2, 4 * height * width * priors_per_point]with box coordinates. Thepriors_per_pointis the number of boxes generated per each grid element. The number depends on layer attribute values.
Detailed description
PriorBoxClustered computes coordinates of prior boxes by following:
- Calculates the center_x and center_y of prior box:
- For each
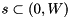 calculates the prior boxes coordinates:
calculates the prior boxes coordinates: ![\[ xmin = \frac{center_x - \frac{width_s}{2}}{W} \]](form_55.png)
![\[ ymin = \frac{center_y - \frac{height_s}{2}}{H} \]](form_56.png)
![\[ xmax = \frac{center_x - \frac{width_s}{2}}{W} \]](form_57.png)
If clip is defined, the coordinates of prior boxes are recalculated with the formula:![\[ ymax = \frac{center_y - \frac{height_s}{2}}{H} \]](form_58.png)
Example
ReLU
Category: Activation
Short description: Reference
Detailed description: Reference
Attributes: ReLU operation has no attributes.
Mathematical Formulation
![\[ Y_{i}^{( l )} = max(0, Y_{i}^{( l - 1 )}) \]](form_60.png)
Inputs:
- 1: Multidimensional input tensor. Required.
Example
Reshape
Category: Shape manipulation operations
Short description: Reshape operation changes dimensions of the input tensor according to the specified order. Input tensor volume is equal to output tensor volume, where volume is the product of dimensions.
Detailed description:
Reshape layer takes two input tensors: the tensor to be resized and the output tensor shape. The values in the second tensor could be -1, 0 and any positive integer number. The two special values -1 and 0:
0means "copy the respective dimension of the input tensor" ifspecial_zerois set totrue; otherwise it is a normal dimension and is applicable to empty tensors.-1means that this dimension is calculated to keep the overall elements count the same as in the input tensor. Not more than one-1can be used in a reshape operation.
Attributes:
- special_zero
- Description: special_zero controls how zero values in
shapeare interpreted. If special_zero isfalse, then 0 is interpreted as-is which means that output shape will contain a zero dimension at the specified location. Input and output tensors are empty in this case. If special_zero istrue, then all zeros inshapeimplies the copying of corresponding dimensions fromdata.shapeinto the output shape. - Range of values:
falseortrue - Type: boolean
- Default value: None
- Required: yes
- Description: special_zero controls how zero values in
Inputs:
- 1:
data– multidimensional input tensor. Required. - 2:
shape– 1D tensor describing output shape. Required.
Outputs:
- 1: Output tensor with the same content as a tensor at input
databut with shape defined by inputshape.
Examples
Parameter
Category: Infrastructure
Short description: Parameter layer specifies input to the model.
Attributes:
- element_type
- Description: the type of element of output tensor
- Range of values: u8, u16, u32, u64, i8, i16, i32, i64, f16, f32, boolean, bf16
- Type: string
- Default value: None
- Required: Yes
- shape
- Description: the shape of the output tensor
- Range of values: list of non-negative integers, emty list is allowed that means 0D or scalar tensor
- Type: int[]
- Default value: None
- Required: Yes
Example
Add
Category: Arithmetic binary operation
Short description: Add performs element-wise addition operation with two given tensors applying multi-directional broadcast rules.
Attributes:
- auto_broadcast
- Description: specifies rules used for auto-broadcasting of input tensors.
- Range of values:
- none - no auto-broadcasting is allowed, all input shapes should match
- numpy - numpy broadcasting rules, aligned with ONNX Broadcasting. Description is available in ONNX docs.
- Type: string
- Default value: "numpy"
- Required: no
Inputs
- 1: A tensor of type T. Required.
- 2: A tensor of type T. Required.
Outputs
- 1: The result of element-wise addition operation. A tensor of type T.
Types
- T: any numeric type.
Detailed description Before performing arithmetic operation, input tensors a and b are broadcasted if their shapes are different and auto_broadcast attributes is not none. Broadcasting is performed according to auto_broadcast value.
After broadcasting Add does the following with the input tensors a and b:
![\[ o_{i} = a_{i} + b_{i} \]](form_61.png)
Examples
Example 1
Example 2: broadcast
Multiply
Category: Arithmetic binary operation
Short description: Multiply performs element-wise multiplication operation with two given tensors applying multi-directional broadcast rules.
Attributes:
- auto_broadcast
- Description: specifies rules used for auto-broadcasting of input tensors.
- Range of values:
- none - no auto-broadcasting is allowed, all input shapes should match
- numpy - numpy broadcasting rules, aligned with ONNX Broadcasting. Description is available in ONNX docs.
- Type: string
- Default value: "numpy"
- Required: no
Inputs
- 1: A tensor of type T. Required.
- 2: A tensor of type T. Required.
Outputs
- 1: The result of element-wise multiplication operation. A tensor of type T.
Types
- T: any numeric type.
Detailed description Before performing arithmetic operation, input tensors a and b are broadcasted if their shapes are different and auto_broadcast attributes is not none. Broadcasting is performed according to auto_broadcast value.
After broadcasting Multiply does the following with the input tensors a and b:
![\[ o_{i} = a_{i} * b_{i} \]](form_62.png)
Examples
Example 1
Example 2: broadcast
MVN
Category: Normalization
Short description: Reference
Detailed description
MVN subtracts mean value from the input blob:
![\[ o_{i} = i_{i} - \frac{\sum{i_{k}}}{C * H * W} \]](form_63.png)
If normalize_variance is set to 1, the output blob is divided by variance:
![\[ o_{i}=\frac{o_{i}}{\sum \sqrt {o_{k}^2}+\epsilon} \]](form_64.png)
Attributes
- across_channels
- Description: across_channels is a flag that specifies whether mean values are shared across channels. For example, across_channels equal to
falsemeans that mean values are not shared across channels. - Range of values:
false- do not share mean values across channelstrue- share mean values across channels
- Type:
boolean - Default value:
false - Required: no
- Description: across_channels is a flag that specifies whether mean values are shared across channels. For example, across_channels equal to
- normalize_variance
- Description: normalize_variance is a flag that specifies whether to perform variance normalization.
- Range of values:
false– do not normalize variancetrue– normalize variance
- Type:
boolean - Default value:
false - Required: no
- eps
- Description: eps is the number to be added to the variance to avoid division by zero when normalizing the value. For example, epsilon equal to 0.001 means that 0.001 is added to the variance.
- Range of values: a positive floating-point number
- Type:
float - Default value: None
- Required: yes
Inputs
- 1: 4D or 5D input tensor of any floating point type. Required.
Outputs
- 1: normalized tensor of the same type and shape as input tensor.
Example
Power
Category: Arithmetic binary operation
Short description: Power performs element-wise power operation with two given tensors applying multi-directional broadcast rules.
Attributes:
- auto_broadcast
- Description: specifies rules used for auto-broadcasting of input tensors.
- Range of values:
- none - no auto-broadcasting is allowed, all input shapes should match
- numpy - numpy broadcasting rules, aligned with ONNX Broadcasting. Description is available in ONNX docs.
- Type: string
- Default value: "numpy"
- Required: no
Inputs
- 1: A tensor of type T. Required.
- 2: A tensor of type T. Required.
Outputs
- 1: The result of element-wise power operation. A tensor of type T.
Types
- T: any numeric type.
Detailed description Before performing arithmetic operation, input tensors a and b are broadcasted if their shapes are different and auto_broadcast attributes is not none. Broadcasting is performed according to auto_broadcast value.
After broadcasting Power does the following with the input tensors a and b:
![\[ o_{i} = {a_{i} ^ b}_{i} \]](form_65.png)
Examples
Example 1
Example 2: broadcast
Exp
Category: Activation function
Short description: Exponential element-wise activation function.
Attributes: has no attributes
Inputs:
- 1: Input tensor x of any floating point type. Required.
Outputs:
- 1: Result of Exp function applied to the input tensor x. Floating point tensor with shape and type matching the input tensor. Required.
ShapeOf
Category: Shape manipulation operations
Short description: ShapeOf produces 1D tensor with the input tensor shape.
Attributes: has no attributes.
Inputs:
- 1: Arbitrary input tensor. Required.
Outputs:
- 1: 1D tensor that is equal to input tensor shape. Number of elements is equal to input tensor rank. Can be empty 1D tensor if input tensor is a scalar, that mean 0-dimensional tensor.
Example
SoftMax
Category: Activation
Short description: Reference
Detailed description: Reference
Attributes
- axis
- Description: axis represents the axis of which the SoftMax is calculated. axis equal 1 is a default value.
- Range of values: positive integer value
- Type: int
- Default value: 1
- Required: no
Inputs:
- 1: Input tensor with enough number of dimension to be compatible with axis attribute. Required.
Outputs:
- 1: The resulting tensor of the same shape and type as input tensor.
Detailed description
![\[ y_{c} = \frac{e^{Z_{c}}}{\sum_{d=1}^{C}e^{Z_{d}}} \]](form_66.png)
where  is a size of tensor along axis dimension.
is a size of tensor along axis dimension.
Example
PReLU
Category: Activation function
Short description: PReLU performs element-wise parametric ReLU operation with negative slope defined by the second input.
Attributes: operation has no attributes.
Inputs
- 1:
X- Input tensor of any supported floating point type T1. Required. - 2:
slope- Tensor with negative slope values of type T2. The shape of the tensor should be broadcastable to input 1. Required.
Outputs
- 1: The result of element-wise PReLU operation applied for tensor from input 1 with slope values from input 2. A tensor of type T1 and shape matching shape of input x tensor.
Types
- T1: arbitrary supported floating point type.
- T2: arbitrary supported floating point type.
Detailed description Before performing addition operation, input tensor 2 with slope values is broadcasted to input 1. The broadcasting rules are aligned with ONNX Broadcasting. Description is available in ONNX docs.
After broadcasting PReLU does the following for each input 1 element x:
f(x) = slope * x for x < 0; x for x >= 0
Interpolate
Category: Image processing
Short description: Interpolate layer performs interpolation of independent slices in input tensor by specified dimensions and attributes.
Attributes
- axes
- Description:
axesspecify spatial dimension indices where interpolation is applied. Other dimensions are treated as batch dimensions. The order of elements inaxesattribute matters and mapped directly to elements with the same indices in the 2nd inputtarget_spatial_shape. - Range of values: list of non-negative integer numbers
- Type:
int[] - Default value: None
- Required: yes
- Description:
- mode
- Description: specifies type of interpolation
- Range of values: one of
nearest,linear,cubic,area - Type: string
- Default value: none
- Required: yes
- align_corners
- Description: align_corners is a flag that specifies whether to align corners or not. 1 means the alignment is applied, 0 means the alignment isn't applied.
- Range of values: True or False
- Type:
boolean - Default value: True
- Required: no
- antialias
- Description: antialias is a flag that specifies whether to perform anti-aliasing.
- Range of values:
- False - do not perform anti-aliasing
- True - perform anti-aliasing
- Type: boolean
- Default value: False
- Required: no
- pads_begin
- Description: pads_beg specify the number of pixels to add to the beginning of the image being interpolated. This is a scalar that specifies padding for each spatial dimension.
- Range of values: list of non-negative integer numbers
- Type:
int - Default value: 0
- Required: no
- pads_end
- Description: pads_end specify the number of pixels to add to the beginning of the image being interpolated. This is a scalar that specifies padding for each spatial dimension.
- Range of values: list of non-negative integer numbers
- Type:
int - Default value: 0
- Required: no
Inputs
- 1:
data- Input tensor with data for interpolation. Type of elements is any supported floating point type. Required. - 2:
target_spatial_shape- 1D tensor describing output shape for spatial axes. Number of elements matches the number of indices in axes attribute, the order matches as well. Required.
Outputs
- 1: Resulting interpolated tensor with elements of the same type as input
datatensor. The shape of the output matches inputdatashape except spatial dimensions mentioned inaxesattribute. For other dimensions shape matches sizes fromtarget_spaticl_shapein order specified inaxes.
Example
Less
Category: Comparison binary operation
Short description: Less performs element-wise comparison operation with two given tensors applying multi-directional broadcast rules.
Attributes:
- auto_broadcast
- Description: specifies rules used for auto-broadcasting of input tensors.
- Range of values:
- none - no auto-broadcasting is allowed, all input shapes should match
- numpy - numpy broadcasting rules, aligned with ONNX Broadcasting. Description is available in ONNX docs.
- Type: string
- Default value: "numpy"
- Required: no
Inputs
- 1: A tensor of type T. Required.
- 2: A tensor of type T. Required.
Outputs
- 1: The result of element-wise comparison operation. A tensor of type boolean.
Types
- T: arbitrary supported type.
Detailed description Before performing arithmetic operation, input tensors a and b are broadcasted if their shapes are different and auto_broadcast attributes is not none. Broadcasting is performed according to auto_broadcast value.
After broadcasting Less does the following with the input tensors a and b:
![\[ o_{i} = a_{i} < b_{i} \]](form_67.png)
Examples
Example 1
Example 2: broadcast
LessEqual
Category: Comparison binary operation
Short description: LessEqual performs element-wise comparison operation with two given tensors applying multi-directional broadcast rules.
Attributes:
- auto_broadcast
- Description: specifies rules used for auto-broadcasting of input tensors.
- Range of values:
- none - no auto-broadcasting is allowed, all input shapes should match
- numpy - numpy broadcasting rules, aligned with ONNX Broadcasting. Description is available in ONNX docs.
- Type: string
- Default value: "numpy"
- Required: no
Inputs
- 1: A tensor of type T. Required.
- 2: A tensor of type T. Required.
Outputs
- 1: The result of element-wise comparison operation. A tensor of type boolean.
Types
- T: arbitrary supported type.
Detailed description Before performing arithmetic operation, input tensors a and b are broadcasted if their shapes are different and auto_broadcast attributes is not none. Broadcasting is performed according to auto_broadcast value.
After broadcasting LessEqual does the following with the input tensors a and b:
![\[ o_{i} = a_{i} <= b_{i} \]](form_68.png)
Examples
Example 1
Example 2: broadcast
PSROIPooling
Category: Object detection
Short description: PSROIPooling computes position-sensitive pooling on regions of interest specified by input.
Detailed description: Reference.
PSROIPooling operation takes two input blobs: with feature maps and with regions of interests (box coordinates). The latter is specified as five element tuples: [batch_id, x_1, y_1, x_2, y_2]. ROIs coordinates are specified in absolute values for the average mode and in normalized values (to [0,1] interval) for bilinear interpolation.
Attributes
- output_dim
- Description: output_dim is a pooled output channel number.
- Range of values: a positive integer
- Type:
int - Default value: None
- Required: yes
- group_size
- Description: group_size is the number of groups to encode position-sensitive score maps. Use for average mode only.
- Range of values: a positive integer
- Type:
int - Default value: 1
- Required: no
- spatial_scale
- Description: spatial_scale is a multiplicative spatial scale factor to translate ROI coordinates from their input scale to the scale used when pooling.
- Range of values: a positive floating-point number
- Type:
float - Default value: None
- Required: yes
- mode
- Description: mode specifies mode for pooling.
- Range of values:
- average - perform average pooling
- bilinear - perform pooling with bilinear interpolation
- Type: string
- Default value: average
- Required: no
- spatial_bins_x
- Description: spatial_bins_x specifies numbers of bins to divide the input feature maps over width. Used for "bilinear" mode only.
- Range of values: a positive integer
- Type:
int - Default value: 1
- Required: no
- spatial_bins_y
- Description: spatial_bins_y specifies numbers of bins to divide the input feature maps over height. Used for "bilinear" mode only.
- Range of values: a positive integer
- Type:
int - Default value: 1
- Required: no
Inputs:
- 1: 4D input blob with feature maps. Required.
- 2: 2D input blob describing box consisting of five element tuples:
[batch_id, x_1, y_1, x_2, y_2]. Required.
Outputs:
- 1: 4D output tensor with areas copied and interpolated from the 1st input tensor by coordinates of boxes from the 2nd input.
Example
Select
Category: Conditions
Short description: Select returns a tensor filled with the elements from the second or the third inputs, depending on the condition (the first input) value.
Detailed description
Select takes elements from then input tensor or the else input tensor based on a condition mask provided in the first input cond. Before performing selection, input tensors then and else are broadcasted to each other if their shapes are different and auto_broadcast attributes is not none. Then the cond tensor is one-way broadcasted to the resulting shape of broadcasted then and else. Broadcasting is performed according to auto_broadcast value.
Attributes
- auto_broadcast
- Description: specifies rules used for auto-broadcasting of input tensors.
- Range of values:
- none - no auto-broadcasting is allowed, all input shapes should match
- numpy - numpy broadcasting rules, aligned with ONNX Broadcasting. Description is available in ONNX docs.
- Type: string
- Default value: "numpy"
- Required: no
Inputs:
- 1:
condtensor with selection mask of typeboolean. The tensor can be 0D. - 2:
thenthe tensor with elements to take where the corresponding element incondis true. Arbitrary type that should match type ofelseinput tensor. - 3:
elsethe tensor with elements to take where the corresponding element incondis false. Arbitrary type that should match type oftheninput tensor.
Outputs:
- 1: blended output tensor that is tailored from values of inputs tensors
thenandelsebased oncondand broadcasting rules. It has the same type of elements asthenandelse.
Example
DeformableConvolution
Category: DeformableConvolution
Detailed description: Reference
Attributes
- strides
- Description: strides is a distance (in pixels) to slide the filter on the feature map over the (z, y, x) axes for 3D convolutions and (y, x) axes for 2D convolutions. For example, strides equal 4,2,1 means sliding the filter 4 pixel at a time over depth dimension, 2 over height dimension and 1 over width dimension.
- Range of values: integer values starting from 0
- Type: int[]
- Default value: None
- Required: yes
- pads_begin
- Description: pads_begin is a number of pixels to add to the beginning along each axis. For example, pads_begin equal 1,2 means adding 1 pixel to the top of the input and 2 to the left of the input.
- Range of values: integer values starting from 0
- Type: int[]
- Default value: None
- Required: yes
- pads_end
- Description: pads_end is a number of pixels to add to the ending along each axis. For example, pads_end equal 1,2 means adding 1 pixel to the bottom of the input and 2 to the right of the input.
- Range of values: integer values starting from 0
- Type: int[]
- Default value: None
- Required: yes
- dilations
- Description: dilations denotes the distance in width and height between elements (weights) in the filter. For example, dilation equal 1,1 means that all the elements in the filter are neighbors, so it is the same as for the usual convolution. dilation equal 2,2 means that all the elements in the filter are matched not to adjacent elements in the input matrix, but to those that are adjacent with distance 1.
- Range of values: integer value starting from 0
- Type: int[]
- Default value: None
- Required: yes
- auto_pad
- Description: auto_pad how the padding is calculated. Possible values:
- Not specified: use explicit padding values.
- same_upper (same_lower) the input is padded to match the output size. In case of odd padding value an extra padding is added at the end (at the beginning).
- valid - do not use padding.
- Type: string
- Default value: None
- Required: yes
- Description: auto_pad how the padding is calculated. Possible values:
- group
- Description: group is the number of groups which output and input should be split into. For example, group equal to 1 means that all filters are applied to the whole input (usual convolution), group equal to 2 means that both input and output channels are separated into two groups and the i-th output group is connected to the i-th input group channel. group equal to a number of output feature maps implies depth-wise separable convolution.
- Range of values: integer value starting from 1
- Type: int
- Default value: 1
- Required: no
- deformable_group
- Description: deformable_group is the number of groups which deformable values and output should be split into along the channel axis. Apply the deformable convolution using the i-th part of the offset part on the i-th out.
- Range of values: integer value starting from 1
- Type: int
- Default value: 1
- Required: no
Inputs:
- 1: Input tensor of rank 3 or greater. Required.
- 2: Deformable values tensor of rank 3 or higher. Required.
- 3: Convolution kernel tensor. Weights layout is OIYX (OIZYX for 3D convolution), which means that X is changing the fastest, then Y, then Input then Output. The size of kernel is derived from the shape of this input and not specified by any attribute. Required.
Example
DeformablePSROIPooling
Category: Object detection
Short description: DeformablePSROIPooling computes position-sensitive pooling on regions of interest specified by input.
Detailed description: Reference.
DeformablePSROIPooling operation takes two or three input tensors: with feature maps, with regions of interests (box coordinates) and an optional tensor with transformation values. The box coordinates are specified as five element tuples: [batch_id, x_1, y_1, x_2, y_2] in absolute values.
Attributes
- output_dim
- Description: output_dim is a pooled output channel number.
- Range of values: a positive integer
- Type:
int - Default value: None
- Required: yes
- group_size
- Description: group_size is the number of groups to encode position-sensitive score maps.
- Range of values: a positive integer
- Type:
int - Default value: 1
- Required: no
- spatial_scale
- Description: spatial_scale is a multiplicative spatial scale factor to translate ROI coordinates from their input scale to the scale used when pooling.
- Range of values: a positive floating-point number
- Type:
float - Default value: None
- Required: yes
- mode
- Description: mode specifies mode for pooling.
- Range of values:
- bilinear_deformable - perform pooling with bilinear interpolation and deformable transformation
- Type: string
- Default value: bilinear_deformable
- Required: no
- spatial_bins_x
- Description: spatial_bins_x specifies numbers of bins to divide the input feature maps over width.
- Range of values: a positive integer
- Type:
int - Default value: 1
- Required: no
- spatial_bins_y
- Description: spatial_bins_y specifies numbers of bins to divide the input feature maps over height.
- Range of values: a positive integer
- Type:
int - Default value: 1
- Required: no
- trans_std
- Description: trans_std is the value that all transformation (offset) values are multiplied with.
- Range of values: floating point number
- Type:
float - Default value: 1
- Required: no
- part_size
- Description: part_size is the number of parts the output tensor spatial dimensions are divided into. Basically it is the height and width of the third input with transformation values.
- Range of values: positive integer number
- Type:
int - Default value: 1
- Required: no
Inputs:
- 1: 4D input tensor with feature maps. Required.
- 2: 2D input tensor describing box consisting of five element tuples:
[batch_id, x_1, y_1, x_2, y_2]. Required. - 3: 4D input blob with transformation values (offsets). Optional.
Outputs:
- 1: 4D output tensor with areas copied and interpolated from the 1st input tensor by coordinates of boxes from the 2nd input and transformed according to values from the 3rd input.
Example
FakeQuantize
Category: Quantization
Short description: FakeQuantize is element-wise linear quantization of floating-point input values into a discrete set of floating-point values.
Detailed description: Input and output ranges as well as the number of levels of quantization are specified by dedicated inputs and attributes. There can be different limits for each element or groups of elements (channels) of the input tensors. Otherwise, one limit applies to all elements. It depends on shape of inputs that specify limits and regular broadcasting rules applied for input tensors. The output of the operator is a floating-point number of the same type as the input tensor. In general, there are four values that specify quantization for each element: input_low, input_high, output_low, output_high. input_low and input_high attributes specify the input range of quantization. All input values that are outside this range are clipped to the range before actual quantization. output_low and output_high specify minimum and maximum quantized values at the output.
Fake in FakeQuantize means the output tensor is of the same floating point type as an input tensor, not integer type.
Each element of the output is defined as the result of the following expression:
Attributes
- levels
- Description: levels is the number of quantization levels (e.g. 2 is for binarization, 255/256 is for int8 quantization)
- Range of values: an integer greater than or equal to 2
- Type:
int - Default value: None
- Required: yes
Inputs:
- 1:
X- multidimensional input tensor of floating type to be quantized. Required. - 2:
input_low- minimum limit for input value. The shape must be broadcastable to the shape of X. Required. - 3:
input_high- maximum limit for input value. Can be the same asinput_lowfor binarization. The shape must be broadcastable to the shape of X. Required. - 4:
output_low- minimum quantized value. The shape must be broadcastable to the shape of X. Required. - 5:
output_high- maximum quantized value. The shape must be broadcastable to the of X. Required.
Inputs:
- 1:
Y- resulting tensor with shape and type matching the 1st input tensor X.
Example
BinaryConvolution
Category: Convolution
Short description: BinaryConvolution convolution with binary weights, binary input and integer output
Attributes:
The operation has the same attributes as a regular Convolution layer and several unique attributes that are listed below:
- mode
- Description: mode defines how input tensor 0/1 values and weights 0/1 are interpreted as real numbers and how the result is computed.
- Range of values:
- xnor-popcount
- Type:
string - Default value: None
- Required: yes
- pad_value
- Description: pad_value is a floating-point value used to fill pad area.
- Range of values: a floating-point number
- Type:
float - Default value: None
- Required: yes
Inputs:
- 1: ND tensor with N >= 3, containing integer, float or binary values; filled with 0/1 values of any appropriate type. 0 means -1, 1 means 1 for
mode="xnor-popcount". Required. - 2: ND tensor with N >= 3 that represents convolutional kernel filled by integer, float or binary values; filled with 0/1 values. 0 means -1, 1 means 1 for
mode="xnor-popcount". Required.
Outputs:
- 1: output tensor containing float values. Required.
ReverseSequence
Category: data movement operation
Short description: ReverseSequence reverses variable length slices of data.
Detailed description: ReverseSequence slices input along the dimension specified in the batch_axis, and for each slice i, reverses the first lengths[i] (the second input) elements along the dimension specified in the seq_axis.
Attributes
- batch_axis
- Description: batch_axis is the index of the batch dimension.
- Range of values: an integer. Can be negative.
- Type:
int - Default value: 0
- Required: no
- seq_axis
- Description: seq_axis is the index of the sequence dimension.
- Range of values: an integer. Can be negative.
- Type:
int - Default value: 1
- Required: no
Inputs:
- 1: tensor with input data to reverse. Required.
- 2: 1D tensor populated with integers with sequence lengths in the 1st input tensor. Required.
Example
Reverse
Category: data movement operation
Short description: Reverse operations reverse specified axis in an input tensor.
Detailed description: Reverse produces a tensor with the same shape as the first input tensor and with elements reversed along dimensions specified in the second input tensor. The axes can be represented either by dimension indices or as a mask. The interpretation of the second input is determined by mode attribute. If index mode is used, the second tensor should contain indices of axes that should be reversed. The length of the second tensor should be in a range from 0 to rank of the 1st input tensor.
In case if mask mode is used, then the second input tensor length should be equal to the rank of the 1st input. And each value has boolean value True or False. True means the corresponding axes should be reverted, False means it should be untouched.
If no axis specified, that means either the second input is empty if index mode is used or second input has only False elements if mask mode is used, then Reverse just passes the source tensor through output not doing any data movements.
Attributes
- mode
- Description: specifies how the second input tensor should be interpreted: as a set of indices or a mask
- Range of values:
index,mask - Type:
string - Default value: None
- Required: yes Inputs:
- 1: tensor with input data to reverse. Required.
- 2: 1D tensor populated with indices of reversed axes or boolean values that specify mask for reversed axes.
Example
RNNCell
Category: Sequence processing
Short description: RNNCell represents a single RNN cell that computes the output using the formula described in the article.
Attributes
- hidden_size
- Description: hidden_size specifies hidden state size.
- Range of values: a positive integer
- Type:
int - Default value: None
- Required: yes
- activations
- Description: activation functions for gates
- Range of values: any combination of relu, sigmoid, tanh
- Type: a list of strings
- Default value: sigmoid,tanh
- Required: no
- activations_alpha, activations_beta
- Description: activations_alpha, activations_beta functions attributes
- Range of values: a list of floating-point numbers
- Type:
float[] - Default value: None
- Required: no
- clip
- Description: clip specifies value for tensor clipping to be in [-C, C] before activations
- Range of values: a positive floating-point number
- Type:
float - Default value: None
- Required: no
Inputs
- 1:
X- 2D ([batch_size, input_size]) input data. Required. - 2:
initial_hidden_state- 2D ([batch_size, hidden_size]) input hidden state data. Required.
Outputs
- 1:
Ho- 2D ([batch_size, hidden_size]) output hidden state.
ROIPooling
Category: Object detection
Short description: ROIPooling is a pooling layer used over feature maps of non-uniform input sizes and outputs a feature map of a fixed size.
Detailed description: deepsense.io reference
Attributes
- pooled_h
- Description: pooled_h is the height of the ROI output feature map. For example, pooled_h equal to 6 means that the height of the output of ROIPooling is 6.
- Range of values: a non-negative integer
- Type:
int - Default value: None
- Required: yes
- pooled_w
- Description: pooled_w is the width of the ROI output feature map. For example, pooled_w equal to 6 means that the width of the output of ROIPooling is 6.
- Range of values: a non-negative integer
- Type:
int - Default value: None
- Required: yes
- spatial_scale
- Description: spatial_scale is the ratio of the input feature map over the input image size.
- Range of values: a positive floating-point number
- Type:
float - Default value: None
- Required: yes
- method
- Description: method specifies a method to perform pooling. If the method is bilinear, the input box coordinates are normalized to the
[0, 1]interval. - Range of values: max or bilinear
- Type: string
- Default value: max
- Required: no
- Description: method specifies a method to perform pooling. If the method is bilinear, the input box coordinates are normalized to the
Inputs:
- 1: 4D input tensor of shape
[1, C, H, W]with feature maps. Required. - 2: 2D input tensor of shape
[NUM_ROIS, 5]describing box consisting of 5 element tuples:[batch_id, x_1, y_1, x_2, y_2]. Required.
Outputs:
- 1: 4D output tensor of shape
[NUM_ROIS, C, pooled_h, pooled_w]with feature maps. Required.
Example
Proposal
Category: Object detection
Short description: Proposal operation filters bounding boxes and outputs only those with the highest prediction confidence.
Detailed description
Proposal has three inputs: a tensor with probabilities whether particular bounding box corresponds to background and foreground, a tensor with logits for each of the bounding boxes, a tensor with input image size in the [image_height, image_width, scale_height_and_width] or [image_height, image_width, scale_height, scale_width] format. The produced tensor has two dimensions [batch_size * post_nms_topn, 5]. Proposal layer does the following with the input tensor:
- Generates initial anchor boxes. Left top corner of all boxes is at (0, 0). Width and height of boxes are calculated from base_size with scale and ratio attributes.
- For each point in the first input tensor:
- pins anchor boxes to the image according to the second input tensor that contains four deltas for each box: for x and y of center, for width and for height
- finds out score in the first input tensor
- Filters out boxes with size less than min_size
- Sorts all proposals (box, score) by score from highest to lowest
- Takes top pre_nms_topn proposals
- Calculates intersections for boxes and filter out all boxes with
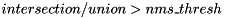
- Takes top post_nms_topn proposals
- Returns top proposals
- base_size
- Description: base_size is the size of the anchor to which scale and ratio attributes are applied.
- Range of values: a positive integer number
- Type:
int - Default value: None
- Required: yes
- pre_nms_topn
- Description: pre_nms_topn is the number of bounding boxes before the NMS operation. For example, pre_nms_topn equal to 15 means that the minimum box size is 15.
- Range of values: a positive integer number
- Type:
int - Default value: None
- Required: yes
- post_nms_topn
- Description: post_nms_topn is the number of bounding boxes after the NMS operation. For example, post_nms_topn equal to 15 means that the maximum box size is 15.
- Range of values: a positive integer number
- Type:
int - Default value: None
- Required: yes
- nms_thresh
- Description: nms_thresh is the minimum value of the proposal to be taken into consideration. For example, nms_thresh equal to 0.5 means that all boxes with prediction probability less than 0.5 are filtered out.
- Range of values: a positive floating-point number
- Type:
float - Default value: None
- Required: yes
- feat_stride
- Description: feat_stride is the step size to slide over boxes (in pixels). For example, feat_stride equal to 16 means that all boxes are analyzed with the slide 16.
- Range of values: a positive integer
- Type:
int - Default value: None
- Required: yes
- min_size
- Description: min_size is the minimum size of box to be taken into consideration. For example, min_size equal 35 means that all boxes with box size less than 35 are filtered out.
- Range of values: a positive integer number
- Type:
int - Default value: None
- Required: yes
- ratio
- Description: ratio is the ratios for anchor generation.
- Range of values: a list of floating-point numbers
- Type:
float[] - Default value: None
- Required: yes
- scale
- Description: scale is the scales for anchor generation.
- Range of values: a list of floating-point numbers
- Type:
float[] - Default value: None
- Required: yes
- clip_before_nms
- Description: clip_before_nms flag that specifies whether to perform clip bounding boxes before non-maximum suppression or not.
- Range of values: True or False
- Type:
boolean - Default value: True
- Required: no
- clip_after_nms
- Description: clip_after_nms is a flag that specifies whether to perform clip bounding boxes after non-maximum suppression or not.
- Range of values: True or False
- Type:
boolean - Default value: False
- Required: no
- normalize
- Description: normalize is a flag that specifies whether to perform normalization of output boxes to [0,1] interval or not.
- Range of values: True or False
- Type:
boolean - Default value: False
- Required: no
- box_size_scale
- Description: box_size_scale specifies the scale factor applied to logits of box sizes before decoding.
- Range of values: a positive floating-point number
- Type:
float - Default value: 1.0
- Required: no
- box_coordinate_scale
- Description: box_coordinate_scale specifies the scale factor applied to logits of box coordinates before decoding.
- Range of values: a positive floating-point number
- Type:
float - Default value: 1.0
- Required: no
- framework
- Description: framework specifies how the box coordinates are calculated.
- Range of values:
- "" (empty string) - calculate box coordinates like in Caffe*
- tensorflow - calculate box coordinates like in the TensorFlow* Object Detection API models
- Type: string
- Default value: "" (empty string)
- Required: no
Inputs:
- 1: 4D input floating point tensor with class prediction scores. Required.
- 2: 4D input floating point tensor with box logits. Required.
- 3: 1D input floating tensor 3 or 4 elements: [
image_height,image_width,scale_height_and_width] or [image_height,image_width,scale_height,scale_width]. Required.
Outputs:
- 1: Floating point tensor of shape
[batch_size * post_nms_topn, 5].
Example
Broadcast
Category: Data movement
Short description: Broadcast replicates data on the first input to fit a given shape on the second input.
Detailed description:
Broadcast takes the first tensor data and, following broadcasting rules that are specified by mode attribute and the 3rd input axes_mapping, builds a new tensor with shape matching the 2nd input tensor target_shape. target_shape input is a 1D integer tensor that represents required shape of the output.
Attribute mode and the 3rd input axes_mapping are relevant for cases when rank of the input data tensor doesn't match the size of the target_shape input. They both define how axes from data shape are mapped to the output axes. If mode is set to numpy, it means that the standard one-directional numpy broadcasting rules are applied. They are similar to rules that applied in all binary element-wise operations in case when auto_broadcasting attribute is set to numpy, and are similar to rules described at here, when only one-directional broadcasting is applied: input tensor data is broadcasted to target_shape but not vice-versa.
In case if mode is set to explicit, then 3rd input axes_mapping comes to play. It contains a list of axis indices, each index maps an axis from the 1st input tensor data to axis in the output. The size of axis_mapping should match the rank of input data tensor, so all axes from data tensor should be mapped to axes of the output.
For example, axes_mapping = [1] enables broadcasting of a tensor with shape [C] to shape [N,C,H,W] by replication of initial tensor along dimensions 0, 2 and 3. Another example is broadcasting of tensor with shape [H,W] to shape [N,H,W,C] with axes_mapping = [1, 2]. Both examples requires mode set to explicit and providing mentioned axes_mapping input, because such operations cannot be expressed with axes_mapping set to numpy.
Attributes:
- mode
- Description: specifies rules used for mapping of
inputtensor axes to output shape axes. - Range of values:
- numpy - numpy broadcasting rules, aligned with ONNX Broadcasting. Description is available in ONNX docs.; only one-directional broadcasting is applied from
datatotarget_shape. If this attribute value is used, then the 3rd input for the operation shouldn't be provided. - explicit - mapping of the input
datashape axes to output shape is provided as an explicit 3rd input.
- numpy - numpy broadcasting rules, aligned with ONNX Broadcasting. Description is available in ONNX docs.; only one-directional broadcasting is applied from
- Type: string
- Default value: "numpy"
- Required: no
- Description: specifies rules used for mapping of
Inputs:
- 1:
data- source tensor of any type and shape that is being broadcasted. Required. - 2:
taget_shape- 1D integer tensor describing output shape. Required. - 3:
axes_mapping- 1D integer tensor describing a list of axis indices, each index maps an axis from the 1st input tensordatato axis in the output. The index values in this tensor should be sorted, that disables on-the-fly transpositions of inputdatatensor while the broadcasting.axes_mappinginput is optional depending onmodevalue.
Outputs:
- 1: Output tensor with replicated content from the 1st tensor
dataand with shape matchedtarget_shape.
Example
CTCGreedyDecoder
Category: Sequence processing
Short description: CTCGreedyDecoder performs greedy decoding on the logits given in input (best path).
Detailed description:
This operation is similar Reference
Given an input sequence 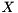 of length
of length 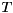 , CTCGreedyDecoder assumes the probability of a length character sequence is given by
, CTCGreedyDecoder assumes the probability of a length character sequence is given by
![\[ p(C|X) = \prod_{t=1}^{T} p(c_{t}|X) \]](form_72.png)
Sequences in the batch can have different length. The lengths of sequences are coded as values 1 and 0 in the second input tensor sequence_mask. Value sequence_mask[j, i] specifies whether there is a sequence symbol at index i in the sequence i in the batch of sequences. If there is no symbol at j-th position sequence_mask[j, i] = 0, and sequence_mask[j, i] = 1 otherwise. Starting from j = 0, sequence_mass[j, i] are equal to 1 up to the particular index j = last_sequence_symbol, which is defined independently for each sequence i. For j > last_sequence_symbol, values in sequence_mask[j, i] are all zeros.
Attributes
- merge_repeated
- Description: merge_repeated is a flag for merging repeated labels during the CTC calculation.
- Range of values: True or False
- Type:
boolean - Default value: True
- Required: no
Inputs
- 1:
data- Input tensor with a batch of sequences. Type of elements is any supported floating point type. Shape of the tensor is[T, N, C], whereTis the maximum sequence length,Nis the batch size andCis the number of classes. Required. - 2:
sequence_mask- 2D input floating point tensor with sequence masks for each sequence in the batch. Populated with values 0 and 1. Shape of this input is[T, N]. Required.
Output
- 1: Output tensor with shape
[N, T, 1, 1]and integer elements containing final sequence class indices. A final sequence can be shorter that the sizeTof the tensor, all elements that do not code sequence classes are filled with -1. Type of elements is floating point, but all values are integers.
Example
Divide
Category: Arithmetic binary operation
Short description: Divide performs element-wise division operation with two given tensors applying multi-directional broadcast rules.
Attributes:
- auto_broadcast
- Description: specifies rules used for auto-broadcasting of input tensors.
- Range of values:
- none - no auto-broadcasting is allowed, all input shapes should match
- numpy - numpy broadcasting rules, aligned with ONNX Broadcasting. Description is available in ONNX docs.
- Type: string
- Default value: "numpy"
- Required: no
Inputs
- 1: A tensor of type T. Required.
- 2: A tensor of type T. Required.
Outputs
- 1: The result of element-wise division operation. A tensor of type T.
Types
- T: any numeric type.
Detailed description Before performing arithmetic operation, input tensors a and b are broadcasted if their shapes are different and auto_broadcast attributes is not none. Broadcasting is performed according to auto_broadcast value.
After broadcasting Divide does the following with the input tensors a and b:
![\[ o_{i} = a_{i} / b_{i} \]](form_73.png)
Examples
Example 1
Example 2: broadcast
Gather
Category: Data movement operations
Short description: Gather operation takes slices of data in the 1st input tensor according to the indexes specified in the 2nd input tensor and axis from the 3rd input
Detailed description
output[:, ... ,:, i, ... , j,:, ... ,:] = input1[:, ... ,:, input2[i, ... ,j],:, ... ,:]
Where i is value from the 3rd input.
Attributes: Gather has no attributes
Inputs
- 1: Tensor with arbitrary data. Required.
- 2: Tensor with indexes to gather. The values for indexes are in the range
[0, input1[axis] - 1]. Required. - 3: Scalar or 1D tensor axis is a dimension index to gather data from. For example, axis equal to 1 means that gathering is performed over the first dimension. Negative value means reverse indexing. Allowed values are from
[-len(input1.shape), len(input1.shape) - 1]. Required.
Outputs
- 1: The resulting tensor that consists of elements from 2nd input tensor gathered by indices from 1st input tensor. Shape of the tensor is
input1.shape[:axis] + input2.shape + input1.shape[axis + 1:]
Example
GatherTree
Category: Beam search post-processing
Short description: Generates the complete beams from the ids per each step and the parent beam ids.
Detailed description
GatherTree operation implements the same algorithm as GatherTree operation in TensorFlow. Please see complete documentation here.
Pseudo code:
Element data types for all input tensors should match each other.
Attributes: GatherTree has no attributes
Inputs
- 1:
step_ids– a tensor of shape[MAX_TIME, BATCH_SIZE, BEAM_WIDTH]of typeTwith indices from per each step. Required. - 2:
parent_idx– a tensor of shape[MAX_TIME, BATCH_SIZE, BEAM_WIDTH]of typeTwith parent beam indices. Required. - 3:
max_seq_len– a tensor of shape[BATCH_SIZE]of typeTwith maximum lengths for each sequence in the batch. Required. - 4:
end_token– a scalar tensor of typeTwith value of the end marker in a sequence. Required.
Outputs
- 1:
final_idx– a tensor of shape[MAX_TIME, BATCH_SIZE, BEAM_WIDTH]of typeT.
Types
- T:
float32orint32;float32should have integer values only.
Example
Greater
Category: Comparison binary operation
Short description: Greater performs element-wise comparison operation with two given tensors applying multi-directional broadcast rules.
Attributes:
- auto_broadcast
- Description: specifies rules used for auto-broadcasting of input tensors.
- Range of values:
- none - no auto-broadcasting is allowed, all input shapes should match
- numpy - numpy broadcasting rules, aligned with ONNX Broadcasting. Description is available in ONNX docs.
- Type: string
- Default value: "numpy"
- Required: no
Inputs
- 1: A tensor of type T. Required.
- 2: A tensor of type T. Required.
Outputs
- 1: The result of element-wise comparison operation. A tensor of type boolean.
Types
- T: arbitrary supported type.
Detailed description Before performing arithmetic operation, input tensors a and b are broadcasted if their shapes are different and auto_broadcast attributes is not none. Broadcasting is performed according to auto_broadcast value.
After broadcasting Greater does the following with the input tensors a and b:
![\[ o_{i} = a_{i} > b_{i} \]](form_74.png)
Examples
Example 1
Example 2: broadcast
GreaterEqual
Category: Comparison binary operation
Short description: GreaterEqual performs element-wise comparison operation with two given tensors applying multi-directional broadcast rules.
Attributes:
- auto_broadcast
- Description: specifies rules used for auto-broadcasting of input tensors.
- Range of values:
- none - no auto-broadcasting is allowed, all input shapes should match
- numpy - numpy broadcasting rules, aligned with ONNX Broadcasting. Description is available in ONNX docs.
- Type: string
- Default value: "numpy"
- Required: no
Inputs
- 1: A tensor of type T. Required.
- 2: A tensor of type T. Required.
Outputs
- 1: The result of element-wise comparison operation. A tensor of type boolean.
Types
- T: arbitrary supported type.
Detailed description Before performing arithmetic operation, input tensors a and b are broadcasted if their shapes are different and auto_broadcast attributes is not none. Broadcasting is performed according to auto_broadcast value.
After broadcasting GreaterEqual does the following with the input tensors a and b:
![\[ o_{i} = a_{i} >= b_{i} \]](form_75.png)
Examples
Example 1
Example 2: broadcast
LSTMCell
Category: Sequence processing
Short description: LSTMCell operation represents a single LSTM cell. It computes the output using the formula described in the original paper Long Short-Term Memory.
Detailed description
Attributes
- hidden_size
- Description: hidden_size specifies hidden state size.
- Range of values: a positive integer
- Type:
int - Default value: None
- Required: yes
- activations
- Description: activations specifies activation functions for gates, there are three gates, so three activation functions should be specified as a value for this attributes
- Range of values: any combination of relu, sigmoid, tanh
- Type: a list of strings
- Default value: sigmoid,tanh,tanh
- Required: no
- activations_alpha, activations_beta
- Description: activations_alpha, activations_beta attributes of functions; applicability and meaning of these attributes depends on chosen activation functions
- Range of values: a list of floating-point numbers
- Type:
float[] - Default value: None
- Required: no
- clip
- Description: clip specifies bound values [-C, C] for tensor clipping. Clipping is performed before activations.
- Range of values: a positive floating-point number
- Type:
float - Default value: infinity that means that the clipping is not applied
- Required: no
Inputs
- 1:
X- 2D ([batch_size, input_size]) input data. Required. - 2:
initial_hidden_state- 2D ([batch_size, hidden_size]) input hidden state data. Required. - 3:
initial_cell_state- 2D ([batch_size, hidden_size]) input cell state data. Required. - 4:
W- 2D tensor with weights for matrix multiplication operation, shape is[4 * hidden_size, input_size], gate order: fico - 5:
R- 2D tensor with weights for matrix multiplication operation, shape is[4 * hidden_size, hidden_size], gate order: fico - 6:
BTensor with biases, shape is[4 * hidden_size]
Outputs
- 1:
Ho- 2D ([batch_size, hidden_size]) output hidden state. - 2:
Co- 2D ([batch_size, hidden_size]) output cell state.
Example
Maximum
Category: Arithmetic binary operation
Short description: Maximum performs element-wise maximum operation with two given tensors applying multi-directional broadcast rules.
Attributes:
- auto_broadcast
- Description: specifies rules used for auto-broadcasting of input tensors.
- Range of values:
- none - no auto-broadcasting is allowed, all input shapes should match
- numpy - numpy broadcasting rules, aligned with ONNX Broadcasting. Description is available in ONNX docs.
- Type: string
- Default value: "numpy"
- Required: no
Inputs
- 1: First input tensor of type T. Required.
- 2: Second input tensor of type T. Required.
Outputs
- 1: The result of element-wise maximum operation. A tensor of type T.
Types
- T: arbitrary type, which supports less/greater comparison.
Detailed description Before performing arithmetic operation, input tensors a and b are broadcasted if their shapes are different and auto_broadcast attributes is not none. Broadcasting is performed according to auto_broadcast value.
After broadcasting Maximum does the following with the input tensors a and b:
![\[ o_{i} = max(a_{i}, b_{i}) \]](form_76.png)
Examples
Example 1
Example 2: broadcast
Minimum
Category: Arithmetic binary operation
Short description: Minimum performs element-wise minimum operation with two given tensors applying multi-directional broadcast rules.
Attributes:
- auto_broadcast
- Description: specifies rules used for auto-broadcasting of input tensors.
- Range of values:
- none - no auto-broadcasting is allowed, all input shapes should match
- numpy - numpy broadcasting rules, aligned with ONNX Broadcasting. Description is available in ONNX docs.
- Type: string
- Default value: "numpy"
- Required: no
Inputs
- 1: First input tensor of type T. Required.
- 2: Second input tensor of type T. Required.
Outputs
- 1: The result of element-wise minimum operation. A tensor of type T.
Types
- T: arbitrary type, which supports less/greater comparison.
Detailed description Before performing arithmetic operation, input tensors a and b are broadcasted if their shapes are different and auto_broadcast attributes is not none. Broadcasting is performed according to auto_broadcast value.
After broadcasting Minimum does the following with the input tensors a and b:
![\[ o_{i} = min(a_{i}, b_{i}) \]](form_77.png)
Examples
Example 1
Example 2: broadcast
NormalizeL2
Category: Normalization
Short description: NormalizeL2 operation performs L2 normalization of the 1st input tensor in slices specified by the 2nd input.
Attributes
- eps
- Description: eps is the number to be added/maximized to/with the variance to avoid division by zero when normalizing the value. For example, eps equal to 0.001 means that 0.001 is used if all the values in normalization are equal to zero.
- Range of values: a positive floating-point number
- Type:
float - Default value: None
- Required: yes
- eps_mode
- Description: Specifies how eps is combined with L2 value calculated before division.
- Range of values:
add,max - Type:
string - Default value: None
- Required: yes
Inputs
- 1:
data- input tensor to be normalized. Type of elements is any floating point type. Required. - 2:
axes- scalar or 1D tensor with axis indices for thedatainput along which L2 reduction is calculated. Required.
Outputs
- 1: Tensor of the same shape and type as the
datainput and normalized slices defined byaxesinput.
Detailed Description
Each element in the output is the result of division of corresponding element from the data input tensor by the result of L2 reduction along dimensions specified by the axes input:
output[i0, i1, ..., iN] = x[i0, i1, ..., iN] / sqrt(eps_mode(sum[j0,..., jN](x[j0, ..., jN]**2), eps))
Where indices i0, ..., iN run through all valid indices for the 1st input and summation sum[j0, ..., jN] have jk = ik for those dimensions k that are not in the set of indices specified by the axes input of the operation. One of the corner cases is when axes is an empty list, then we divide each input element by itself resulting value 1 for all non-zero elements. Another corner case is where axes input contains all dimensions from data tensor, which means that a single L2 reduction value is calculated for entire input tensor and each input element is divided by that value.
eps_mode selects how the reduction value and eps are combined. It can be max or add depending on eps_mode attribute value.
Example
NotEqual
Category: Comparison binary operation
Short description: NotEqual performs element-wise comparison operation with two given tensors applying multi-directional broadcast rules.
Attributes:
- auto_broadcast
- Description: specifies rules used for auto-broadcasting of input tensors.
- Range of values:
- none - no auto-broadcasting is allowed, all input shapes should match
- numpy - numpy broadcasting rules, aligned with ONNX Broadcasting. Description is available in ONNX docs.
- Type: string
- Default value: "numpy"
- Required: no
Inputs
- 1: A tensor of type T. Required.
- 2: A tensor of type T. Required.
Outputs
- 1: The result of element-wise comparison operation. A tensor of type boolean.
Types
- T: arbitrary supported type.
Detailed description Before performing arithmetic operation, input tensors a and b are broadcasted if their shapes are different and auto_broadcast attributes is not none. Broadcasting is performed according to auto_broadcast value.
After broadcasting NotEqual does the following with the input tensors a and b:
![\[ o_{i} = a_{i} != b_{i} \]](form_78.png)
Examples
Example 1
Example 2: broadcast
Pad
Category: Data movement operations
Short description: Pad operation extends an input tensor on edges. The amount and value of padded elements are defined by inputs and attributes.
Attributes
- pad_mode
- Description: pad_mode specifies the method used to generate new element values.
- Range of values: Name of the method in string format:
constant- padded values are equal to the value of the pad_value operation attribute.edge- padded values are copied from the respective edge of the inputdatatensor.reflect- padded values are a reflection of the inputdatatensor; values on the edges are not duplicated.pads_begin[D]andpads_end[D]must be not greater thandata.shape[D] – 1for any validD.symmetric- padded values are symmetrically added from the inputdatatensor. This method is similar to thereflect, but values on edges are duplicated. Refer to the examples below for more details.pads_begin[D]andpads_end[D]must be not greater thandata.shape[D]for any validD.
- Type: string
- Default value: None
- Required: yes
Inputs
- 1:
data- input tensor to be padded. Required. - 2:
pads_begin- specifies the number of padding elements at the beginning of each axis. A list of non-negative integers. The length of the list must be equal to the number of dimensions in the input tensor. Required. - 3:
pads_end- specifies the number of padding elements at the beginning of each axis. A list of non-negative integers. The length of the list must be equal to the number of dimensions in the input tensor. Required. - 4:
pad_value- scalar tensor of type matching type of elements indatatensor to be replicated in padded area. Used with thepad_mode = "constant"only. All new elements are populated with this value. Optional forpad_mode = "constant". If not provided, 0 of appropriate type is used. Shouldn't be set for otherpad_modevalues.
Outputs
- 1: Output padded tensor with dimensions
pads_begin[D] + data.shape[D] + pads_end[D]for eachDfrom0tolen(data.shape) - 1.
Detailed Description
The attributes specify a number of elements to add along each axis and a rule by which new element values are generated: for example, whether they are filled with a given constant or generated based on the input tensor content.
The following examples illustrate how output tensor is generated for the Pad layer for a given input tensor:
with the following attributes:
depending on the pad_mode.
pad_mode = "constant":OUTPUT =[[ 0 1 2 3 4 0 0 0 ][ 0 5 6 7 8 0 0 0 ][ 0 9 10 11 12 0 0 0 ][ 0 0 0 0 0 0 0 0 ][ 0 0 0 0 0 0 0 0 ]]pad_mode = "edge":OUTPUT =[[ 1 1 2 3 4 4 4 4 ][ 5 5 6 7 8 8 8 8 ][ 9 9 10 11 12 12 12 12 ][ 9 9 10 11 12 12 12 12 ][ 9 9 10 11 12 12 12 12 ]]pad_mode = "reflect":OUTPUT =[[ 2 1 2 3 4 3 2 1 ][ 6 5 6 7 8 7 6 5 ][ 10 9 10 11 12 11 10 9 ][ 6 5 6 7 8 7 6 5 ][ 2 1 2 3 4 3 2 1 ]]pad_mode = "symmetric":OUTPUT =[[ 1 1 2 3 4 4 3 2 ][ 5 5 6 7 8 8 7 6 ][ 9 9 10 11 12 12 11 10 ][ 9 9 10 11 12 12 11 10 ][ 5 5 6 7 8 8 7 6 ]]
Example
ReduceSum
Category: Reduction
Short description: ReduceSum operation performs reduction with addition of the 1st input tensor in slices specified by the 2nd input.
Attributes
- keep_dims
- Description: If set to
Trueit holds axes that are used for reduction. For each such axis, output dimension is equal to 1. - Range of values: True or False
- Type:
boolean - Default value: False
- Required: no
- Description: If set to
Inputs
- 1: Input tensor x of any data type that has defined addition operation. Required.
- 2: Scalar or 1D tensor with axis indices for the 1st input along which reduction is performed. Required.
Outputs
- 1: Tensor of the same type as the 1st input tensor and
shape[i] = shapeOf(input1)[i]for allithat is not in the list of axes from the 2nd input. For dimensions from the 2nd input tensor,shape[i] == 1ifkeep_dims == True, ori-th dimension is removed from the output otherwise.
Detailed Description
Each element in the output is the result of reduction with addition operation along dimensions specified by the 2nd input:
output[i0, i1, ..., iN] = sum[j0,..., jN](x[j0, ..., jN]**2))
Where indices i0, ..., iN run through all valid indices for the 1st input and summation sum[j0, ..., jN] have jk = ik for those dimensions k that are not in the set of indices specified by the 2nd input of the operation. Corner cases:
- When the 2nd input is an empty list, then this operation does nothing, it is an identity.
- When the 2nd input contains all dimensions of the 1st input, this means that a single reduction value is calculated for entire input tensor.
Example
ReduceProd
Category: Reduction
Short description: ReduceProd operation performs reduction with multiplication of the 1st input tensor in slices specified by the 2nd input.
Attributes
- keep_dims
- Description: If set to
Trueit holds axes that are used for reduction. For each such axis, output dimension is equal to 1. - Range of values: True or False
- Type:
boolean - Default value: False
- Required: no
- Description: If set to
Inputs
- 1: Input tensor x of any data type that has defined multiplication operation. Required.
- 2: Scalar or 1D tensor with axis indices for the 1st input along which reduction is performed. Required.
Outputs
- 1: Tensor of the same type as the 1st input tensor and
shape[i] = shapeOf(input1)[i]for allithat is not in the list of axes from the 2nd input. For dimensions from the 2nd input tensor,shape[i] == 1ifkeep_dims == True, ori-th dimension is removed from the output otherwise.
Detailed Description
Each element in the output is the result of reduction with multiplication operation along dimensions specified by the 2nd input:
output[i0, i1, ..., iN] = prod[j0,..., jN](x[j0, ..., jN]**2))
Where indices i0, ..., iN run through all valid indices for the 1st input and multiplication prod[j0, ..., jN] have jk = ik for those dimensions k that are not in the set of indices specified by the 2nd input of the operation. Corner cases:
- When the 2nd input is an empty list, then this operation does nothing, it is an identity.
- When the 2nd input contains all dimensions of the 1st input, this means that a single reduction value is calculated for entire input tensor.
Example
TopK
Category: Sorting and maximization
Short description: TopK computes indices and values of the k maximum/minimum values for each slice along specified axis.
Attributes
- axis
- Description: Specifies the axis along which
- Range of values: An integer. Negative value means counting dimension from the end.
- Type:
int - Default value: None
- Required: yes
- mode
- Description: Specifies which operation is used to select the biggest element of two.
- Range of values:
min,max - Type:
string - Default value: None
- Required: yes
- sort
- Description: Specifies order of output elements and/or indices.
- Range of values:
value,index,none - Type:
string - Default value: None
- Required: yes
Inputs:
- 1: Arbitrary tensor. Required.
- 2: k – scalar specifies how many maximum/minimum elements should be computed
Outputs:
- 1: Output tensor with top k values from the input tensor along specified dimension axis. The shape of the tensor is
[input1.shape[0], ..., input1.shape[axis-1], k, input1.shape[axis+1], ...]. - 2: Output tensor with top k indices for each slice along axis dimension. It is 1D tensor of shape
[k]. The shape of the tensor is the same as for the 1st output, that is[input1.shape[0], ..., input1.shape[axis-1], k, input1.shape[axis+1], ...]
Detailed Description
Output tensor is populated by values computes in the following way:
output[i1, ..., i(axis-1), j, i(axis+1) ..., iN] = top_k(input[i1, ...., i(axis-1), :, i(axis+1), ..., iN]), k, sort, mode)
So for each slice input[i1, ...., i(axis-1), :, i(axis+1), ..., iN] which represents 1D array, top_k value is computed individually. Sorting and minimum/maximum are controlled by sort and mode attributes.
Example
LSTMSequence
Category: Sequence processing
Short description: LSTMSequence operation represents a series of LSTM cells. Each cell is implemented as LSTMCell operation.
Detailed description
A single cell in the sequence is implemented in the same way as in LSTMCell operation. LSTMSequence represents a sequence of LSTM cells. The sequence can be connected differently depending on direction attribute that specifies the direction of traversing of input data along sequence dimension or specifies whether it should be a bidirectional sequence. The most of the attributes are in sync with the specification of ONNX LSTM operator defined LSTMCell.
Attributes
- hidden_size
- Description: hidden_size specifies hidden state size.
- Range of values: a positive integer
- Type:
int - Default value: None
- Required: yes
- activations
- Description: activations specifies activation functions for gates, there are three gates, so three activation functions should be specified as a value for this attributes
- Range of values: any combination of relu, sigmoid, tanh
- Type: a list of strings
- Default value: sigmoid,tanh,tanh
- Required: no
- activations_alpha, activations_beta
- Description: activations_alpha, activations_beta attributes of functions; applicability and meaning of these attributes depends on choosen activation functions
- Range of values: a list of floating-point numbers
- Type:
float[] - Default value: None
- Required: no
- clip
- Description: clip specifies bound values [-C, C] for tensor clipping. Clipping is performed before activations.
- Range of values: a positive floating-point number
- Type:
float - Default value: infinity that means that the clipping is not applied
- Required: no
- direction
- Description: Specify if the RNN is forward, reverse, or bidirectional. If it is one of forward or reverse then
num_directions = 1, if it is bidirectional, thennum_directions = 2. Thisnum_directionsvalue specifies input/output shape requirements. - Range of values: forward, reverse, bidirectional
- Type:
string - Default value: None
- Required: Yes
- Description: Specify if the RNN is forward, reverse, or bidirectional. If it is one of forward or reverse then
Inputs
- 1:
X- 3D ([batch_size, seq_length, input_size]) input data. It differs from LSTMCell 1st input only by additional axis with sizeseq_length. Floating point type. Required. - 2:
initial_hidden_state- 3D ([batch_size, num_directions, hidden_size]) input hidden state data. Floating point type. Required. - 3:
initial_cell_state- 3D ([batch_size, num_directions, hidden_size]) input cell state data. Floating point type. Required. - 4:
sequence_lengths- 1D ([batch_size]) specifies real sequence lengths for each batch element. Integer type. Required. - 5:
W- 3D tensor with weights for matrix multiplication operation with input portion of data, shape is[num_directions, 4 * hidden_size, input_size], output gate order: fico. Floating point type. Required. - 6:
R- 3D tensor with weights for matrix multiplication operation with hidden state, shape is[num_directions, 4 * hidden_size, hidden_size], output gate order: fico. Floating point type. Required. - 7:
B- 2D tensor with biases, shape is[num_directions, 4 * hidden_size]. Floating point type. Required.
Outputs
- 1:
Y– 3D output, shape [batch_size, num_directions, seq_len, hidden_size] - 2:
Ho- 3D ([batch_size, num_directions, hidden_size]) output hidden state. - 3:
Co- 3D ([batch_size, num_directions, hidden_size]) output cell state.
StridedSlice
Category: Data movement operation
Short description: StridedSlice extracts a strided slice of a tensor. It is similar to generalized array indexing in Python*.
Attributes
- begin_mask
- Description: begin_mask is a bit mask. begin_mask[i] equal to 1 means that the corresponding dimension of the
begininput is ignored and the 'real' beginning of the tensor is used along corresponding dimension. - Range of values: a list of
0s and1s - Type:
int[] - Default value: None
- Required: yes
- Description: begin_mask is a bit mask. begin_mask[i] equal to 1 means that the corresponding dimension of the
- end_mask
- Description: end_mask is a bit mask. If end_mask[i] is 1, the corresponding dimension of the
endinput is ignored and the real 'end' of the tensor is used along corresponding dimension. - Range of values: a list of
0s and1s - Type:
int[] - Default value: None
- Required: yes
- Description: end_mask is a bit mask. If end_mask[i] is 1, the corresponding dimension of the
- new_axis_mask
- Description: new_axis_mask is a bit mask. If new_axis_mask[i] is 1, a length 1 dimension is inserted on the
i-th position of input tensor. - Range of values: a list of
0s and1s - Type:
int[] - Default value:
[0] - Required: no
- Description: new_axis_mask is a bit mask. If new_axis_mask[i] is 1, a length 1 dimension is inserted on the
- shrink_axis_mask
- Description: shrink_axis_mask is a bit mask. If shrink_axis_mask[i] is 1, the dimension on the
i-th position is deleted. - Range of values: a list of
0s and1s - Type:
int[] - Default value:
[0] - Required: no
- Description: shrink_axis_mask is a bit mask. If shrink_axis_mask[i] is 1, the dimension on the
- ellipsis_mask
- Description: ellipsis_mask is a bit mask. It inserts missing dimensions on a position of a non-zero bit.
- Range of values: a list of
0s and1. Only one non-zero bit is allowed. - Type:
int[] - Default value:
[0] - Required: no
Inputs:
- 1: Multidimensional input tensor to be sliced. Required.
- 2:
begininput - 1D input tensor with begin indexes for input tensor slicing. Required. Out-of-bounds values are silently clamped. Ifbegin_mask[i]is 1, the value ofbegin[i]is ignored and the range of the appropriate dimension starts from 0. Negative values mean indexing starts from the end. For example, iffoo=[1,2,3],begin[0]=-1meansbegin[0]=3. - 3:
endinput - 1D input tensor with end indexes for input tensor slicing. Required. Out-of-bounds values will be silently clamped. Ifend_mask[i]is 1, the value ofend[i]is ignored and the full range of the appropriate dimension is used instead. Negative values mean indexing starts from the end. For example, iffoo=[1,2,3],end[0]=-1meansend[0]=3. - 4:
strideinput - 1D input tensor with strides. Optional.
Example
Subtract
Category: Arithmetic binary operation
Short description: Subtract performs element-wise subtraction operation with two given tensors applying multi-directional broadcast rules.
Attributes:
- auto_broadcast
- Description: specifies rules used for auto-broadcasting of input tensors.
- Range of values:
- none - no auto-broadcasting is allowed, all input shapes should match
- numpy - numpy broadcasting rules, aligned with ONNX Broadcasting. Description is available in ONNX docs.
- Type: string
- Default value: "numpy"
- Required: no
Inputs
- 1: A tensor of type T. Required.
- 2: A tensor of type T. Required.
Outputs
- 1: The result of element-wise subtraction operation. A tensor of type T.
Types
- T: any numeric type.
Detailed description Before performing arithmetic operation, input tensors a and b are broadcasted if their shapes are different and auto_broadcast attributes is not none. Broadcasting is performed according to auto_broadcast value.
After broadcasting Subtract does the following with the input tensors a and b:
![\[ o_{i} = a_{i} - b_{i} \]](form_79.png)
Examples
Example 1
Example 2: broadcast
Squeeze
Category: Reshaping
Short description: Squeeze removes specified dimensions (second input) equal to 1 of the first input tensor. If the second input is omitted then all dimensions equal to 1 are removed. If the specified dimension is not equal to one then error is raised.
Attributes: Squeeze operation doesn't have attributes.
Inputs:
- 1: Multidimensional input tensor. Required.
- 2:
(optional): 0D or 1D tensor with dimensions indices to squeeze. Values could be negative. Indices could be integer or float values.
Example
Example 1:
Example 2: squeeze 1D tensor with 1 element to a 0D tensor (constant)
Unsqueeze
Category: Reshaping
Short description: Unsqueeze adds dimensions of size 1 to the first input tensor. The second input value specifies a list of dimensions that will be inserted. Indices specify dimensions in the output tensor.
Attributes: Unsqueeze operation doesn't have attributes.
Inputs:
- 1: Multidimensional input tensor. Required.
- 2: OD or 1D tensor with dimensions indices to be set to 1. Values could be negative. Indices could be integer or float values.
Example
Example 1:
Example 2: (unsqueeze 0D tensor (constant) to 1D tensor)
DepthToSpace
Category: Data movement
Short description: DepthToSpace operation rearranges data from the depth dimension of the input tensor into spatial dimensions of the output tensor.
Attributes
- block_size
- Description: block_size specifies the size of the value block to be moved. The depth dimension size must be evenly divided by
block_size ^ (len(input.shape) - 2). - Range of values: a positive integer
- Type:
int - Default value: 1
- Required: no
- Description: block_size specifies the size of the value block to be moved. The depth dimension size must be evenly divided by
- mode
- Description: specifies how the input depth dimension is split to block coordinates and the new depth dimension.
- Range of values:
- blocks_first: the input depth is divided to
[block_size, ..., block_size, new_depth] - depth_first: the input depth is divided to
[new_depth, block_size, ..., block_size]
- blocks_first: the input depth is divided to
- Type:
string - Default value: None
- Required: yes
Inputs
- 1:
data- input tensor of any type with rank >= 3. Required.
Outputs
- 1: permuted tensor with shape
[N, C / block_size ^ K, D1 * block_size, D2 * block_size, ..., DK * block_size].
Detailed description
DepthToSpace operation permutes elements from the input tensor with shape [N, C, D1, D2, ..., DK], to the output tensor where values from the input depth dimension (features) C are moved to spatial blocks in D1, ..., DK. Refer to the ONNX* specification for an example of the 4D input tensor case.
The operation is equivalent to the following transformation of the input tensor data with K spatial dimensions of shape [N, C, D1, D2, ..., DK] to Y output tensor. If mode = blocks_first:
x' = reshape(data, [N, block_size, block_size, ..., block_size, C / (block_size ^ K), D1, D2, ..., DK]) x'' = transpose(x', [0, K + 1, K + 2, 1, K + 3, 2, K + 4, 3, ..., K + (K + 1), K]) y = reshape(x'', [N, C / (block_size ^ K), D1 * block_size, D2 * block_size, D3 * block_size, ..., DK * block_size])
If mode = depth_first:
x' = reshape(data, [N, C / (block_size ^ K), block_size, block_size, ..., block_size, D1, D2, ..., DK]) x'' = transpose(x', [0, 1, K + 2, 2, K + 3, 3, K + 4, 4, ..., K + (K + 1), K + 1]) y = reshape(x'', [N, C / (block_size ^ K), D1 * block_size, D2 * block_size, D3 * block_size, ..., DK * block_size])
Example
SpaceToDepth
Category: Data movement
Short description: SpaceToDepth operation rearranges data from the spatial dimensions of the input tensor into depth dimension of the output tensor.
Attributes
- block_size
- Description: block_size specifies the size of the value block to be moved. The depth dimension size must be evenly divided by
block_size ^ (len(input.shape) - 2). - Range of values: a positive integer
- Type:
int - Default value: 1
- Required: no
- Description: block_size specifies the size of the value block to be moved. The depth dimension size must be evenly divided by
- mode
- Description: specifies how the output depth dimension is gathered from block coordinates and the old depth dimension.
- Range of values:
- blocks_first: the output depth is gathered from
[block_size, ..., block_size, C] - depth_first: the output depth is gathered from
[C, block_size, ..., block_size]
- blocks_first: the output depth is gathered from
- Type:
string - Default value: None
- Required: yes
Inputs
- 1:
data- input tensor of any type with rank >= 3. Required.
Outputs
- 1: permuted tensor with shape
[N, C * (block_size ^ K), D1 / block_size, D2 / block_size, ..., DK / block_size].
Detailed description
SpaceToDepth operation permutes element from the input tensor with shape [N, C, D1, D2, ..., DK], to the output tensor where values from the input spatial dimensions D1, D2, ..., DK are moved to the new depth dimension. Refer to the ONNX* specification for an example of the 4D input tensor case.
The operation is equivalent to the following transformation of the input tensor data with K spatial dimensions of shape [N, C, D1, D2, ..., DK] to Y output tensor. If mode = blocks_first:
x' = reshape(data, [N, C, D1/block_size, block_size, D2/block_size, block_size, ... , DK/block_size, block_size]) x'' = transpose(x', [0, 3, 5, ..., K + (K + 1), 1, 2, 4, ..., K + K]) y = reshape(x'', [N, C * (block_size ^ K), D1 / block_size, D2 / block_size, ... , DK / block_size])
If mode = depth_first:
x' = reshape(data, [N, C, D1/block_size, block_size, D2/block_size, block_size, ..., DK/block_size, block_size]) x'' = transpose(x', [0, 1, 3, 5, ..., K + (K + 1), 2, 4, ..., K + K]) y = reshape(x'', [N, C * (block_size ^ K), D1 / block_size, D2 / block_size, ..., DK / block_size])
Example
OneHot
Category: Sequence processing
Short description: OneHot sets the elements in the output tensor with specified indices to on_value and fills all other locations with off_value.
Detailed description
Taking a tensor with rank N as the first input indices, OneHot produces tensor with rank N+1 extending original tensor with a new dimension at axis position in shape. Output tensor is populated with two scalar values: on_value that comes from the 3rd input and off_value that comes from the 4nd input. Population is made in the following way:
output[:, ... ,:, i, :, ... ,:] = on_value if (indices[:, ..., :, :, ..., :] == i) else off_value
where i is at axis position in output shape and has values from range [0, ..., depth-1].
When index element from indices is greater or equal to depth, it is a well-formed operation. In this case the corresponding row output[..., i, ...] is populated with off_value only for all i values.
Types of input scalars on_value and off_value should match and can be any of the supported types. The type of output tensor is derived from on_value and off_value, they all have the same type.
Attributes:
- axis
- Description: axis is a new axis position in the output shape to fill with one-hot values.
- Range of values: an integer. Negative value means counting dimension from the end.
- Type:
int - Default value: None
- Required: yes
Inputs:
- 1:
indices: input tensor of rankNwith indices of any supported integer data type. Can be 0D. Required. - 2:
depth: scalar (0D tensor) of any supported integer type that specifies number of classes and the size of one-hot dimension. - 3:
on_value: scalar (0D tensor) of any type that is the value that the locations in output tensor represented by indices in input take. - 4:
off_value: scalar (0D tensor) of any type that is the value that the locations not represented by indices in input take.
Outputs:
- 1 Output tensor of rank
N+1, whereNis a rank of input tensorindices. A new axis of the sizedepthis inserted at the dimensionaxis.
Examples
Acos
Category: Arithmetic unary operation
Short description: Acos performs element-wise inverse cosine (arccos) operation with given tensor.
Attributes:
No attributes available.
Inputs
- 1: An tensor of type T. Required.
Outputs
- 1: The result of element-wise acos operation. A tensor of type T.
Types
- T: any numeric type.
Acos does the following with the input tensor a:
![\[ a_{i} = acos(a_{i}) \]](form_80.png)
Examples
Example 1
Asin
Category: Arithmetic unary operation
Short description: Asin performs element-wise inverse sine (arcsin) operation with given tensor.
Attributes:
No attributes available.
Inputs
- 1: An tensor of type T. Required.
Outputs
- 1: The result of element-wise asin operation. A tensor of type T.
Types
- T: any numeric type.
Asin does the following with the input tensor a:
![\[ a_{i} = asin(a_{i}) \]](form_81.png)
Examples
Example 1
Cos
Category: Arithmetic unary operation
Short description: Cos performs element-wise cosine operation with given tensor.
Attributes:
No attributes available.
Inputs
- 1: An tensor of type T. Required.
Outputs
- 1: The result of element-wise cos operation. A tensor of type T.
Types
- T: any numeric type.
Cos does the following with the input tensor a:
![\[ a_{i} = cos(a_{i}) \]](form_82.png)
Examples
Example 1
Sin
Category: Arithmetic unary operation
Short description: Sin performs element-wise sine operation with given tensor.
Attributes:
No attributes available.
Inputs
- 1: An tensor of type T. Required.
Outputs
- 1: The result of element-wise sin operation. A tensor of type T.
Types
- T: any numeric type.
sin does the following with the input tensor a:
![\[ a_{i} = sin(a_{i}) \]](form_83.png)
Examples
Example 1
Tan
Category: Arithmetic unary operation
Short description: Tan performs element-wise tangent operation with given tensor.
Attributes:
No attributes available.
Inputs
- 1: An tensor of type T. Required.
Outputs
- 1: The result of element-wise tan operation. A tensor of type T.
Types
- T: any numeric type.
Tan does the following with the input tensor a:
![\[ a_{i} = tan(a_{i}) \]](form_84.png)
Examples
Example 1
Atan
Category: Arithmetic unary operation
Short description: Atan performs element-wise inverse tangent (arctangent) operation with given tensor.
Attributes:
No attributes available.
Inputs
- 1: An tensor of type T. Required.
Outputs
- 1: The result of element-wise atan operation. A tensor of type T.
Types
- T: any numeric type.
atan does the following with the input tensor a:
![\[ a_{i} = atan(a_{i}) \]](form_85.png)
Examples
Example 1
Sinh
Category: Arithmetic unary operation
Short description: Sinh performs element-wise hyperbolic sine (sinh) operation with given tensor.
Attributes:
No attributes available.
Inputs
- 1: An tensor of type T. Required.
Outputs
- 1: The result of element-wise sinh operation. A tensor of type T.
Types
- T: any numeric type.
sinh does the following with the input tensor a:
![\[ a_{i} = sinh(a_{i}) \]](form_86.png)
Examples
Example 1
Cosh
Category: Arithmetic unary operation
Short description: Cosh performs element-wise hyperbolic cosine operation with given tensor.
Attributes:
No attributes available.
Inputs
- 1: An tensor of type T. Required.
Outputs
- 1: The result of element-wise cosh operation. A tensor of type T.
Types
- T: any numeric type.
Cosh does the following with the input tensor a:
![\[ a_{i} = cosh(a_{i}) \]](form_87.png)
Examples
Example 1
Log
Category: Arithmetic unary operation
Short description: Log performs element-wise natural logarithm operation with given tensor.
Attributes:
No attributes available.
Inputs
- 1: An tensor of type T. Required.
Outputs
- 1: The result of element-wise log operation. A tensor of type T.
Types
- T: any numeric type.
Log does the following with the input tensor a:
![\[ a_{i} = log(a_{i}) \]](form_88.png)
Examples
Example 1
Sqrt
Category: Arithmetic unary operation
Short description: Sqrt performs element-wise square root operation with given tensor.
Attributes:
No attributes available.
Inputs
- 1: An tensor of type T. Required.
Outputs
- 1: The result of element-wise sqrt operation. A tensor of type T.
Types
- T: any numeric type.
Sqrt does the following with the input tensor a:
![\[ a_{i} = sqrt(a_{i}) \]](form_89.png)
Examples
Example 1
Negative
Category: Arithmetic unary operation
Short description: Negative performs element-wise negative operation with given tensor.
Attributes:
No attributes available.
Inputs
- 1: An tensor of type T. Required.
Outputs
- 1: The result of element-wise negative operation. A tensor of type T.
Types
- T: any numeric type.
Negative does the following with the input tensor a:
![\[ a_{i} = -a_{i} \]](form_90.png)
Examples
Example 1
Abs
Category: Arithmetic unary operation
Short description: Abs performs element-wise the absolute value with given tensor.
Attributes:
No attributes available.
Inputs
- 1: An tensor of type T. Required.
Outputs
- 1: The result of element-wise abs operation. A tensor of type T.
Types
- T: any numeric type.
Abs does the following with the input tensor a:
![\[ a_{i} = abs(a_{i}) \]](form_91.png)
Examples
Example 1
Ceiling
Category: Arithmetic unary operation
Short description: Ceiling performs element-wise ceiling operation with given tensor.
Attributes:
No attributes available.
Inputs
- 1: An tensor of type T. Required.
Outputs
- 1: The result of element-wise ceiling operation. A tensor of type T.
Types
- T: any numeric type.
Ceiling does the following with the input tensor a:
![\[ a_{i} = ceiling(a_{i}) \]](form_92.png)
Examples
Example 1
Floor
Category: Arithmetic unary operation
Short description: Floor performs element-wise floor operation with given tensor.
Attributes:
No attributes available.
Inputs
- 1: An tensor of type T. Required.
Outputs
- 1: The result of element-wise floor operation. A tensor of type T.
Types
- T: any numeric type.
Floor does the following with the input tensor a:
![\[ a_{i} = floor(a_{i}) \]](form_93.png)
Examples
Example 1
RegionYolo
Category: Object detection
Short description: RegionYolo computes the coordinates of regions with probability for each class.
Detailed description: This operation is directly mapped to the original YOLO layer. Reference
Attributes:
- anchors
- Description: anchors codes a flattened list of pairs
[width, height]that codes prior box sizes. This attribute is not used in output computation, but it is required for post-processing to restore real box coordinates. - Range of values: list of any length of positive floating point number
- Type:
float[] - Default value: None
- Required: no
- Description: anchors codes a flattened list of pairs
- axis
- Description: starting axis index in the input tensor
datashape that will be flattened in the output; the end of flattened range is defined byend_axisattribute. - Range of values:
-rank(data) .. rank(data)-1 - Type:
int - Default value: None
- Required: yes
- Description: starting axis index in the input tensor
- coords
- Description: coords is the number of coordinates for each region.
- Range of values: an integer
- Type:
int - Default value: None
- Required: yes
- classes
- Description: classes is the number of classes for each region.
- Range of values: an integer
- Type:
int - Default value: None
- Required: yes
- end_axis
- Description: ending axis index in the input tensor
datashape that will be flattened in the output; the beginning of the flattened range is defined byaxisattribute. - Range of values:
-rank(data)..rank(data)-1 - Type:
int - Default value: None
- Required: yes
- Description: ending axis index in the input tensor
- num
- Description: num is the number of regions.
- Range of values: an integer
- Type:
int - Default value: None
- Required: yes
- do_softmax
- Description: do_softmax is a flag that specifies the inference method and affects how the number of regions is determined. It also affects output shape. If it is 0, then output shape is 4D, and 2D otherwise.
- Range of values:
- False - do not perform softmax
- True - perform softmax
- Type:
boolean - Default value: True
- Required: no
- mask
- Description: mask specifies the number of regions. Use this attribute instead of num when do_softmax is equal to 0.
- Range of values: a list of integers
- Type:
int[] - Default value:
[] - Required: no
Inputs:
- 1:
data- 4D input tensor with floating point elements and shape[N, C, H, W]. Required.
Outputs:
1: output tensor of rank 4 or less that codes detected regions. Refer to the original YOLO paper to decode the output as boxes.
anchorsshould be used to decode real box coordinates. Ifdo_softmaxis set to 0, then the output shape is[N, (classes + coords + 1)*len(mask), H, W]. Ifdo_softmaxis set to 1, then output shape is partially flattened and defined in the following way:flat_dim = data.shape[axis] * data.shape[axis+1] * ... * data.shape[end_axis] output.shape = [data.shape[0], ..., data.shape[axis-1], flat_dim, data.shape[end_axis + 1], ...]
Example
ReorgYolo Layer
Category: Object detection
Short description: ReorgYolo reorganizes input tensor taking into account strides.
Detailed description:
Attributes
- stride
- Description: stride is the distance between cut throws in output blobs.
- Range of values: positive integer
- Type:
int - Default value: None
- Required: yes
Inputs:
- 1: 4D input tensor of any type and shape
[N, C, H, W].HandWshould be divisible bystride. Required.
Outputs:
- 1: 4D output tensor of the same type as input tensor and shape
[N, C*stride*stride, H/stride, W/stride]. Required.
Example
Sign
Category: Arithmetic unary operation
Short description: Sign performs element-wise sign operation with given tensor.
Attributes:
No attributes available.
Inputs
- 1: An tensor of type T. Required.
Outputs
- 1: The result of element-wise sign operation. A tensor of type T with mapped elements of the input tensor to -1 (if it is negative), 0 (if it is zero), or 1 (if it is positive).
Types
- T: any numeric type.
Sign does the following with the input tensor a:
![\[ a_{i} = sign(a_{i}) \]](form_94.png)
Examples
Example 1
ReduceMax
Category: ReduceMax
Short description: ReduceMax operation performs reduction with finding the maximum value of the 1st input tensor in slices specified by the 2nd input.
Attributes
- keep_dims
- Description: If set to
Trueit holds axes that are used for reduction. For each such axis, output dimension is equal to 1. - Range of values: True or False
- Type:
boolean - Default value: False
- Required: no
- Description: If set to
Inputs
- 1: Input tensor x of any data type that has defined maximum operation. Required.
- 2: Scalar or 1D tensor with axis indices for the 1st input along which reduction is performed. Required.
Outputs
- 1: Tensor of the same type as the 1st input tensor and
shape[i] = shapeOf(input1)[i]for allithat is not in the list of axes from the 2nd input. For dimensions from the 2nd input tensor,shape[i] == 1ifkeep_dims == True, ori-th dimension is removed from the output otherwise.
Detailed Description
Each element in the output is the result of reduction with finding a maximum operation along dimensions specified by the 2nd input:
output[i0, i1, ..., iN] = max[j0,..., jN](x[j0, ..., jN]**2))
Where indices i0, ..., iN run through all valid indices for the 1st input and finding the maximum value max[j0, ..., jN] have jk = ik for those dimensions k that are not in the set of indices specified by the 2nd input of the operation. Corner cases:
- When the 2nd input is an empty list, then this operation does nothing, it is an identity.
- When the 2nd input contains all dimensions of the 1st input, this means that a single reduction value is calculated for entire input tensor.
Example
ReduceMin
Category: ReduceMin
Short description: ReduceMin operation performs reduction with finding the minimum value of the 1st input tensor in slices specified by the 2nd input.
Attributes
- keep_dims
- Description: If set to
Trueit holds axes that are used for reduction. For each such axis, output dimension is equal to 1. - Range of values: True or False
- Type:
boolean - Default value: False
- Required: no
- Description: If set to
Inputs
- 1: Input tensor x of any data type that has defined minimum operation. Required.
- 2: Scalar or 1D tensor with axis indices for the 1st input along which reduction is performed. Required.
Outputs
- 1: Tensor of the same type as the 1st input tensor and
shape[i] = shapeOf(input1)[i]for allithat is not in the list of axes from the 2nd input. For dimensions from the 2nd input tensor,shape[i] == 1ifkeep_dims == True, ori-th dimension is removed from the output otherwise.
Detailed Description
Each element in the output is the result of reduction with finding a minimum operation along dimensions specified by the 2nd input:
output[i0, i1, ..., iN] = min[j0,..., jN](x[j0, ..., jN]**2))
Where indices i0, ..., iN run through all valid indices for the 1st input and finding the minimum value min[j0, ..., jN] have jk = ik for those dimensions k that are not in the set of indices specified by the 2nd input of the operation. Corner cases:
- When the 2nd input is an empty list, then this operation does nothing, it is an identity.
- When the 2nd input contains all dimensions of the 1st input, this means that a single reduction value is calculated for entire input tensor.
Example
LogicalAnd
Category: Logical binary operation
Short description: LogicalAnd performs element-wise logical AND operation with two given tensors applying multi-directional broadcast rules.
Attributes:
- auto_broadcast
- Description: specifies rules used for auto-broadcasting of input tensors.
- Range of values:
- none - no auto-broadcasting is allowed, all input shapes should match
- numpy - numpy broadcasting rules, aligned with ONNX Broadcasting. Description is available in ONNX docs.
- Type: string
- Default value: "numpy"
- Required: no
Inputs
- 1: A tensor of type T. Required.
- 2: A tensor of type T. Required.
Outputs
- 1: The result of element-wise logical AND operation. A tensor of type boolean.
Types
- T: boolean type.
Detailed description Before performing logical operation, input tensors a and b are broadcasted if their shapes are different and auto_broadcast attributes is not none. Broadcasting is performed according to auto_broadcast value.
After broadcasting LogicalAnd does the following with the input tensors a and b:
![\[ o_{i} = a_{i} and b_{i} \]](form_95.png)
Examples
Example 1
Example 2: broadcast
LogicalOr
Category: Logical binary operation
Short description: LogicalOr performs element-wise logical OR operation with two given tensors applying multi-directional broadcast rules.
Attributes:
- auto_broadcast
- Description: specifies rules used for auto-broadcasting of input tensors.
- Range of values:
- none - no auto-broadcasting is allowed, all input shapes should match
- numpy - numpy broadcasting rules, aligned with ONNX Broadcasting. Description is available in ONNX docs.
- Type: string
- Default value: "numpy"
- Required: no
Inputs
- 1: A tensor of type T. Required.
- 2: A tensor of type T. Required.
Outputs
- 1: The result of element-wise logical OR operation. A tensor of type boolean.
Types
- T: boolean type.
Detailed description Before performing logical operation, input tensors a and b are broadcasted if their shapes are different and auto_broadcast attributes is not none. Broadcasting is performed according to auto_broadcast value.
After broadcasting LogicalOr does the following with the input tensors a and b:
![\[ o_{i} = a_{i} or b_{i} \]](form_96.png)
Examples
Example 1
Example 2: broadcast
LogicalXor
Category: Logical binary operation
Short description: LogicalXor performs element-wise logical XOR operation with two given tensors applying multi-directional broadcast rules.
Attributes:
- auto_broadcast
- Description: specifies rules used for auto-broadcasting of input tensors.
- Range of values:
- none - no auto-broadcasting is allowed, all input shapes should match
- numpy - numpy broadcasting rules, aligned with ONNX Broadcasting. Description is available in ONNX docs.
- Type: string
- Default value: "numpy"
- Required: no
Inputs
- 1: A tensor of type T. Required.
- 2: A tensor of type T. Required.
Outputs
- 1: The result of element-wise logical XOR operation. A tensor of type T.
Types
- T: boolean type.
Detailed description Before performing logical operation, input tensors a and b are broadcasted if their shapes are different and auto_broadcast attributes is not none. Broadcasting is performed according to auto_broadcast value.
After broadcasting LogicalXor does the following with the input tensors a and b:
![\[ o_{i} = a_{i} xor b_{i} \]](form_97.png)
Examples
Example 1
Example 2: broadcast
LogicalXor
Category: Logical binary operation
Short description: LogicalXor performs element-wise logical XOR operation with two given tensors applying multi-directional broadcast rules.
Attributes:
- auto_broadcast
- Description: specifies rules used for auto-broadcasting of input tensors.
- Range of values:
- none - no auto-broadcasting is allowed, all input shapes should match
- numpy - numpy broadcasting rules, aligned with ONNX Broadcasting. Description is available in ONNX docs.
- Type: string
- Default value: "numpy"
- Required: no
Inputs
- 1: A tensor of type T. Required.
- 2: A tensor of type T. Required.
Outputs
- 1: The result of element-wise logical XOR operation. A tensor of type T.
Types
- T: boolean type.
Detailed description Before performing logical operation, input tensors a and b are broadcasted if their shapes are different and auto_broadcast attributes is not none. Broadcasting is performed according to auto_broadcast value.
After broadcasting LogicalXor does the following with the input tensors a and b:
Examples
Example 1
Example 2: broadcast
LogicalNot
Category: Logical unary operation
Short description: LogicalNot performs element-wise logical negation operation with given tensor.
Attributes:
No attributes available.
Inputs
- 1: An tensor of type T. Required.
Outputs
- 1: The result of element-wise logical negation operation. A tensor of type T.
Types
- T: boolean type.
LogicalNot does the following with the input tensor a:
![\[ a_{i} = not(a_{i}) \]](form_98.png)
Examples
Example 1
ReduceMean
Category: ReduceMean
Short description: ReduceMean operation performs reduction with finding the arithmetic mean of the 1st input tensor in slices specified by the 2nd input.
Attributes
- keep_dims
- Description: If set to
Trueit holds axes that are used for reduction. For each such axis, output dimension is equal to 1. - Range of values: True or False
- Type:
boolean - Default value: False
- Required: no
- Description: If set to
Inputs
- 1: Input tensor x of any data type that has defined the arithmetic mean operation. Required.
- 2: Scalar or 1D tensor with axis indices for the 1st input along which reduction is performed. Required.
Outputs
- 1: Tensor of the same type as the 1st input tensor and
shape[i] = shapeOf(input1)[i]for allithat is not in the list of axes from the 2nd input. For dimensions from the 2nd input tensor,shape[i] == 1ifkeep_dims == True, ori-th dimension is removed from the output otherwise.
Detailed Description
Each element in the output is the result of reduction with finding the arithmetic mean operation along dimensions specified by the 2nd input:
output[i0, i1, ..., iN] = mean[j0,..., jN](x[j0, ..., jN]**2))
Where indices i0, ..., iN run through all valid indices for the 1st input and finding the arithmetic mean mean[j0, ..., jN] have jk = ik for those dimensions k that are not in the set of indices specified by the 2nd input of the operation. Corner cases:
- When the 2nd input is an empty list, then this operation does nothing, it is an identity.
- When the 2nd input contains all dimensions of the 1st input, this means that a single reduction value is calculated for entire input tensor.
Example
ReduceLogicalAnd
Category: ReduceLogicalAnd
Short description: ReduceLogicalAnd operation performs reduction with logical and operation of the 1st input tensor in slices specified by the 2nd input.
Attributes
- keep_dims
- Description: If set to
Trueit holds axes that are used for reduction. For each such axis, output dimension is equal to 1. - Range of values: True or False
- Type:
boolean - Default value: False
- Required: no
- Description: If set to
Inputs
- 1: Input tensor x of any data type that has defined logical and operation. Required.
- 2: Scalar or 1D tensor with axis indices for the 1st input along which reduction is performed. Required.
Outputs
- 1: Tensor of the same type as the 1st input tensor and
shape[i] = shapeOf(input1)[i]for allithat is not in the list of axes from the 2nd input. For dimensions from the 2nd input tensor,shape[i] == 1ifkeep_dims == True, ori-th dimension is removed from the output otherwise.
Detailed Description
Each element in the output is the result of reduction with logical and operation along dimensions specified by the 2nd input:
output[i0, i1, ..., iN] = and[j0,..., jN](x[j0, ..., jN]**2))
Where indices i0, ..., iN run through all valid indices for the 1st input and logical and operation and[j0, ..., jN] have jk = ik for those dimensions k that are not in the set of indices specified by the 2nd input of the operation. Corner cases:
- When the 2nd input is an empty list, then this operation does nothing, it is an identity.
- When the 2nd input contains all dimensions of the 1st input, this means that a single reduction value is calculated for entire input tensor.
Example
ReduceLogicalOr
Category: ReduceLogicalOr
Short description: ReduceLogicalOr operation performs reduction with logical or operation of the 1st input tensor in slices specified by the 2nd input.
Attributes
- keep_dims
- Description: If set to
Trueit holds axes that are used for reduction. For each such axis, output dimension is equal to 1. - Range of values: True or False
- Type:
boolean - Default value: False
- Required: no
- Description: If set to
Inputs
- 1: Input tensor x of any data type that has defined logical or operation. Required.
- 2: Scalar or 1D tensor with axis indices for the 1st input along which reduction is performed. Required.
Outputs
- 1: Tensor of the same type as the 1st input tensor and
shape[i] = shapeOf(input1)[i]for allithat is not in the list of axes from the 2nd input. For dimensions from the 2nd input tensor,shape[i] == 1ifkeep_dims == True, ori-th dimension is removed from the output otherwise.
Detailed Description
Each element in the output is the result of reduction with logical or operation along dimensions specified by the 2nd input:
output[i0, i1, ..., iN] = or[j0,..., jN](x[j0, ..., jN]**2))
Where indices i0, ..., iN run through all valid indices for the 1st input and logical or operation or[j0, ..., jN] have jk = ik for those dimensions k that are not in the set of indices specified by the 2nd input of the operation. Corner cases:
- When the 2nd input is an empty list, then this operation does nothing, it is an identity.
- When the 2nd input contains all dimensions of the 1st input, this means that a single reduction value is calculated for entire input tensor.
Example
SquaredDifference
Category: Arithmetic binary operation
Short description: SquaredDifference performs element-wise subtraction operation with two given tensors applying multi-directional broadcast rules, after that each result of the subtraction is squared.
Attributes:
- auto_broadcast
- Description: specifies rules used for auto-broadcasting of input tensors.
- Range of values:
- none - no auto-broadcasting is allowed, all input shapes should match
- numpy - numpy broadcasting rules, aligned with ONNX Broadcasting. Description is available in ONNX docs.
- Type: string
- Default value: "numpy"
- Required: no
Inputs
- 1: A tensor of type T. Required.
- 2: A tensor of type T. Required.
Outputs
- 1: The result of element-wise SquaredDifference operation. A tensor of type T.
Types
- T: any numeric type.
Detailed description Before performing arithmetic operation, input tensors a and b are broadcasted if their shapes are different and auto_broadcast attributes is not none. Broadcasting is performed according to auto_broadcast value.
After broadcasting SquaredDifference does the following with the input tensors a and b:
![\[ o_{i} = (a_{i} - b_{i})^2 \]](form_99.png)
Examples
Example 1
Example 2: broadcast
Transpose
Category: Layer
Short description: Transpose operation reorders the input tensor dimensions.
Attributes:
No attributes available.
Inputs:
- 1: "arg" - the tensor to be transposed. A tensor of type T1. Required.
- 2: "input_order" - the permutation to apply to the axes of the input shape. Must be a vector of element T2 type, with shape [n], where n is the rank of "arg". The tensor's value must contain every integer in the range [0,n-1]. If an empty list is specified [] then the axes will be inverted. A tensor of type T2. Required.
Outputs:
- 1: A tensor with shape and type matching 1st tensor.
Types
- T1: arbitrary supported type.
- T2: any integer type.
Detailed description:
Transpose operation reorders the input tensor dimensions. Source indexes and destination indexes are bound by the formula:
![\[ output[i(order[0]), i(order[1]), ..., i(order[N-1])] = input[i(0), i(1), ..., i(N-1)], where i(j) in range 0..(input.shape[j]-1). \]](form_100.png)
Examples
Example 1
Example 2: input_order in not specified
Example 3: input_order = empty_list []
Tile
Category: Layer
Short description: Tile operation repeats an input tensor *"data"* the number of times given by *"repeats"* input tensor along each dimension.
- If number of elements in *"repeats"* is more than shape of *"data"*, then *"data"* will be promoted to "*repeats*" by prepending new axes, e.g. let's shape of *"data"* is equal to (2, 3) and *"repeats"* is equal to [2, 2, 2], then shape of *"data"* will be promoted to (1, 2, 3) and result shape will be (2, 4, 6).
- If number of elements in *"repeats"* is less than shape of *"data"*, then *"repeats"* will be promoted to "*data*" by prepending 1's to it, e.g. let's shape of *"data"* is equal to (4, 2, 3) and *"repeats"* is equal to [2, 2], then *"repeats"* will be promoted to [1, 2, 2] and result shape will be (4, 4, 6)
Attributes:
No attributes available.
Inputs:
- 1: "data" - an input tensor to be padded. A tensor of type T1. Required.
- 2: "repeats" - a per-dimension replication factor. For example, repeats equal to 88 means that the output tensor gets 88 copies of data from the specified axis. A tensor of type T2. Required.
Outputs:
- 1: The count of dimensions in result shape will be equal to the maximum from count of dimensions in "data" shape and number of elements in "repeats". A tensor with type matching 1st tensor.
Types
- T1: arbitrary supported type.
- T2: any integer type.
Detailed description:
Tile operation extends input tensor and filling in output tensor by the following rules:
![\[out_i=input_i[inner_dim*t]\]](form_101.png)
![\[ t \in \left ( 0, \quad tiles \right ) \]](form_102.png)
Examples
Example 1: number elements in "repeats" is equal to shape of data
Example 2: number of elements in "repeats" is more than shape of "data"
Example 3: number of elements in "repeats" is less than shape of "data"
Range
Category: Layer
Short description: Range operation generates a sequence of numbers according input values [start, stop) with a step.
Attributes:
No attributes available.
Inputs:
- 1: "start" - If a value is not given then start = 0. A scalar of type T. Required.
- 2: "stop" - A scalar of type T. Required.
- 3: "step" - If a value is not given then step = 1. A scalar of type T. Required.
Outputs:
- 1: A tensor with type matching 2nd tensor.
Types
- T: any numeric type.
Detailed description:
Range operation generates a sequence of numbers starting from the value in the first input (start) up to but not including the value in the second input (stop) with a step equal to the value in the third input, according to the following formula:
![\[ [start, start + step, start + 2*step, ..., start + K*step], where K is the maximal integer value that satisfies condition start + K*step < stop, then step is positive value and start + K*step > stop, then step is negative value. \]](form_103.png)
Examples
Example 1: positive step
Example 2: negative step
Asinh
Category: Arithmetic unary operation
Short description: Asinh performs element-wise hyperbolic inverse sine (arcsinh) operation with given tensor.
Attributes:
No attributes available.
Inputs
- 1: An tensor of type T. Required.
Outputs
- 1: The result of element-wise asinh operation. A tensor of type T.
Types
- T: any numeric type.
Asinh does the following with the input tensor a:
![\[ a_{i} = asinh(a_{i}) \]](form_104.png)
Examples
Example 1
Atanh
Category: Arithmetic unary operation
Short description: Atanh performs element-wise hyperbolic inverse tangent (arctangenth) operation with given tensor.
Attributes:
No attributes available.
Inputs
- 1: An tensor of type T. Required.
Outputs
- 1: The result of element-wise atanh operation. A tensor of type T.
Types
- T: any numeric type.
Atanh does the following with the input tensor a:
![\[ a_{i} = atanh(a_{i}) \]](form_105.png)
Examples
Example 1
Acosh
Category: Arithmetic unary operation
Short description: Acosh performs element-wise hyperbolic inverse cosine (arccosh) operation with given tensor.
Attributes:
No attributes available.
Inputs
- 1: An tensor of type T. Required.
Outputs
- 1: The result of element-wise acosh operation. A tensor of type T.
Types
- T: any numeric type.
Acosh does the following with the input tensor a:
![\[ a_{i} = acosh(a_{i}) \]](form_106.png)
Examples
Example 1
VariadicSplit
Category: Data movement operations
Short description: VariadicSplit operation splits an input tensor into pieces along some axis. The pieces may have variadic lengths depending on *"split_lengths*" attribute.
Attributes
No attributes available.
Inputs
- 1:
data- A tensor of type T1. Required. - 2:
axis- An axis alongdatato split. A scalar of type T2 with value from range-rank(data) .. rank(data)-1. Negative values address dimensions from the end. Required. - 3:
split_lengths- A list containing the sizes of each output tensor along the splitaxis. Size ofsplit_lengthsshould be equal to the number of outputs. The sum of sizes must matchdata.shape[axis]. A 1-D Tensor of type T2.split_lenghtscan contain a single-1element, that means all remining items along specifiedaxisthat are not consumed by other parts. Required.
Outputs
- Multiple outputs: Tensors of the same type as the
datatensor. The shape of the i-th output has the same shape as thedataexcept along dimensionaxiswhere the size issplit_lengths[i]ifsplit_lengths[i] != -1.-1item, if exists, is processed as described in thesplit_lengthsinput description.
Detailed Description
VariadicSplit operation splits the data input tensor into pieces along axis. The i-th shape of output tensor will be equal to the data shape except along dimension axis where the size will be split_lengths[i]. The sum of elements of split_lengths must match data.shape[axis].
Shape of output tensor will be:
![\[ shape_output_tensor = shape_input_tensor[shape_input_tensor[0], shape_input_tensor[1], ..., split_lengths[axis], ..., shape_input_tensor[D-1]], where D rank of input tensor. \]](form_107.png)
Types
- T1: arbitrary supported type.
- T2: any integer type.
Examples
Split
Category: Data movement operations
Short description: Split operation splits an input tensor into pieces of the same length along some axis.
Attributes
- num_splits
- Description: it specifies the number of outputs into which the initial "*data*" tensor will be split along *"axis"*
- Range of values: a positive integer less than or equal to the size of the dimension being split over
- Type: any integer type
- Default value: None
- Required: Yes
Inputs
- 1: "data" - A tensor of type T1. Required.
- 2: "axis" - axis along *"data"* to split. A scalar of type T2 with value from range
-rank(data) .. rank(data)-1. Negative values address dimensions from the end. Required.
Outputs
- Multiple outputs: Tensors of the same type as the 1st input tensor. The shape of the i-th output has the same shape as the *"data"* except along dimension *"axis"* where the size is
data.shape[i]/num_splits.
Detailed Description
Split operation splits the *"data"* input tensor into pieces of the same length along *"axis"*. The i-th shape of output tensor will be equal to the *"data"* shape except along dimension *"axis"* where the shape will be data.shape[i]/num_splits. The sum of elements of split_lengths must match data.shape[axis].
Shape of output tensor will be:
![\[ shape_output_tensor = shape_input_tensor[shape_input_tensor[0], shape_input_tensor[1], ... ,split_lengths[axis], ... shape_input_tensor[D-1]], where D rank of input tensor. \]](form_108.png)
Types
- T1: arbitrary supported type.
- T2: any integer type.
Example
Convert
Category: type conversion
Short description: Operation converts all elements of the input tensor to a type specified in the *"destination_type"* attribute.
Attributes:
- destination_type
- Description: the destination type
- Range of values: one of the supported types T
- Type: string
- Default value: None
- Required: Yes
Inputs
- 1: A tensor of type T. Required.
Outputs
- 1: The result of element-wise *"Convert"* operation. A tensor of *"destination_type"* type and the same shape with input tensor.
Types
- T: u8, u16, u32, u64, i8, i16, i32, i64, f16, f32, boolean, bf16
Detailed description
Conversion from one supported type to another supported type is always allowed. User must be aware of precision loss and value change caused by range difference between two types. For example, a 32-bit float 3.141592 may be round to a 32-bit int 3.
![\[ o_{i} = convert(a_{i}) \]](form_109.png)
Examples
Example 1
Result
Category: Infrastructure
Short description: Result layer specifies output of the model.
Attributes:
No attributes available.
Inputs
- 1: A tensor of type T. Required.
Types
- T: arbitrary supported type.
Example
BatchNormInference
Category: Normalization
Short description: BatchNormInference layer normalizes a input tensor by mean and variance, and applies a scale (gamma) to it, as well as an offset (beta).
Attributes:
- epsilon
- Description: epsilon is the number to be added to the variance to avoid division by zero when normalizing a value. For example, epsilon equal to 0.001 means that 0.001 is added to the variance.
- Range of values: a positive floating-point number
- Type:
float - Default value: None
- Required: yes
Inputs
- 1:
input- input tensor with data for normalization. At least a 2D tensor of type T, the second dimension represents the channel axis and must have a span of at least 1. Required. - 2:
gamma- gamma scaling for normalized value. A 1D tensor of type T with the same span as input's channel axis. Required. - 3:
beta- bias added to the scaled normalized value. A 1D tensor of type T with the same span as input's channel axis.. Required. - 4:
mean- value for mean normalization. A 1D tensor of type T with the same span as input's channel axis.. Required. - 5:
variance- value for variance normalization. A 1D tensor of type T with the same span as input's channel axis.. Required.
Outputs
- 1: The result of normalization. A tensor of the same type and shape with 1st input tensor.
Types
- T: any numeric type.
Mathematical Formulation
BatchNormInference normalizes the output in each hidden layer.
- Input: Values of
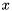 over a mini-batch:
over a mini-batch: ![\[ \beta = \{ x_{1...m} \} \]](form_111.png)
- Parameters to learn:
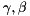
- Output:
![\[ \{ o_{i} = BN_{\gamma, \beta} ( b_{i} ) \} \]](form_113.png)
- Mini-batch mean:
![\[ \mu_{\beta} \leftarrow \frac{1}{m}\sum_{i=1}^{m}b_{i} \]](form_114.png)
- Mini-batch variance:
![\[ \sigma_{\beta }^{2}\leftarrow \frac{1}{m}\sum_{i=1}^{m} ( b_{i} - \mu_{\beta} )^{2} \]](form_115.png)
- Normalize:
![\[ \hat{b_{i}} \leftarrow \frac{b_{i} - \mu_{\beta}}{\sqrt{\sigma_{\beta }^{2} + \epsilon }} \]](form_116.png)
- Scale and shift:
![\[ o_{i} \leftarrow \gamma\hat{b_{i}} + \beta = BN_{\gamma ,\beta } ( b_{i} ) \]](form_117.png)
Example
ConvertLike
Category: type convertion
Short description: Operation converts all elements of the 1st input tensor to a type of elements of 2nd input tensor.
Attributes:
No attributes available.
Inputs
- 1:
data- A tensor of type T1. Required. - 2:
like- A tensor of type T2. Required.
Outputs
- 1: The result of element-wise *"ConvertLike"* operation. A tensor of the same type with
liketensor and the same shape withdatatensor.
Types
- T1: u8, u16, u32, u64, i8, i16, i32, i64, f16, f32, boolean, bf16
- T2: u8, u16, u32, u64, i8, i16, i32, i64, f16, f32, boolean, bf16
Detailed description
Conversion from one supported type to another supported type is always allowed. User must be aware of precision loss and value change caused by range difference between two types. For example, a 32-bit float 3.141592 may be round to a 32-bit int 3.
a - data input tensor, b - like input tensor.
 \]](form_118.png)
Examples
Example 1
TensorIterator
Category: Loops
Short description: TensorIterator layer performs recurrent execution of the network, which is discribed in the body, iterating through the data.
TensorIterator attributes:
Body:
bodyis a network that will be recurrently executed. The network is described layer by layer as a typical IR network.- Body attributes:
No attributes available.
- Body attributes:
Port map:
port_map is a set of rules to map input or output data tensors of
TensorIteratorlayer ontobodydata tensors. Theport_mapentries can beinputandoutput. Each entry describes a corresponding mapping rule.- Port map attributes:
- external_port_id
- Description: external_port_id is a port ID of the
TensorIteratorlayer. - Range of values: indexes of the TensorIterator outputs
- Type:
int - Default value: None
- Required: yes
- Description: external_port_id is a port ID of the
- internal_layer_id
- Description: internal_layer_id is a Parameter or Result layer ID inside the
bodynetwork to map to. - Range of values: IDs of the Parameter layers inside in the TensorIterator layer
- Type:
int - Default value: None
- Required: yes
- Description: internal_layer_id is a Parameter or Result layer ID inside the
- axis
- Description: axis is an axis to iterate through. It triggers the slicing of this tensor. Only if it is specified, the corresponding
inputoroutputis divided into pieces and start, end and stride attributes define how slicing is performed. - Range of values: an integer
- Type:
int - Default value: None
- Required: no
- Description: axis is an axis to iterate through. It triggers the slicing of this tensor. Only if it is specified, the corresponding
- start
- Description: start is an index where the iteration starts from. Negative value means counting indexes from the end. Applies only when the attribute
axisis specified. - Range of values: an integer
- Type:
int - Default value: 0
- Required: no
- Description: start is an index where the iteration starts from. Negative value means counting indexes from the end. Applies only when the attribute
- end
- Description: end is an index where iteration ends. Negative value means counting indexes from the end. Applies only when the attribute
axisis specified. - Range of values: an integer
- Type:
int - Default value: -1
- Required: no
- Description: end is an index where iteration ends. Negative value means counting indexes from the end. Applies only when the attribute
- stride
- Description: stride is a step of iteration. Negative value means backward iteration. Applies only when the attribute
axisis specified. - Range of values: an integer
- Type:
int - Default value: 1
- Required: no
- Description: stride is a step of iteration. Negative value means backward iteration. Applies only when the attribute
- external_port_id
- Port map attributes:
Back edges:
back_edges is a set of rules to transfer tensor values from
bodyoutputs at one iteration tobodyparameters at the next iteration. Back edge connects some Result layer inbodyto Parameter layer in the samebody.- Back edge attributes:
- from-layer
- Description: from-layer is a Result layer ID inside the
bodynetwork. - Range of values: IDs of the Result layers inside the TensorIterator
- Type:
int - Default value: None
- Required: yes
- Description: from-layer is a Result layer ID inside the
- to-layer
- Description: to-layer is a Parameter layer ID inside the
bodynetwork to end mapping. - Range of values: IDs of the Parameter layers inside the TensorIterator
- Type:
int - Default value: None
- Required: yes
- Description: to-layer is a Parameter layer ID inside the
- from-layer
- Back edge attributes:
Inputs
- Multiple inputs: Tensors of any type and shape supported type.
Outputs
- Multiple outputs: Results of execution of the
body. Tensors of any type and shape.
Detailed description
Similar to other layers, TensorIterator has regular sections: input and output. It allows connecting TensorIterator to the rest of the IR. TensorIterator also has several special sections: body, port_map, back_edges. The principles of their work are described below.
How body is iterated:
At the first iteration: TensorIterator slices input tensors by a specified axis and iterates over all parts in a specified order. It process input tensors with arbitrary network specified as an IR network in the body section. IR is executed as no back-edges are present. Edges from port map are used to connect input ports of TensorIterator to Parameters in body.
[inputs] - Port map edges -> [Parameters:body:Results]
Parameter and Result layers are part of the body. Parameters are stable entry points in the body. The results of the execution of the body are presented as stable Result layers. Stable means that these nodes cannot be fused.
Next iterations: Back edges define which data is copied back to Parameters layers from Results layers between IR iterations in TensorIterator body. That means they pass data from source layer back to target layer. Each layer that is a target for back-edge has also an incoming port map edge as an input. The values from back-edges are used instead of corresponding edges from port map. After each iteration of the network, all back edges are executed. Iterations can be considered as statically unrolled sequence: all edges that flow between two neighbor iterations are back-edges. So in the unrolled loop, each back-edge is transformed to regular edge.
... -> [Parameters:body:Results] - back-edges -> [Parameters:body:Results] - back-edges -> [Parameters:body:Results] - back-edges -> ...
Calculation of results:
If output entry in the Port map doesn't have partitioning (axis, begin, end, strides) attributes, then the final value of output of TensorIterator is the value of Result node from the last iteration. Otherwise the final value of output of TensorIterator is a concatenation of tensors in the Result node for all body iterations. Concatenation order is specified by stride attribute.
The last iteration:
[Parameters:body:Results] - Port map edges -> [outputs], if partitioning attributes are not set.
if there are partitioning attributes, then an output tensor is a concatenation of tensors from all body iterations. If stride > 0:
where Si is value of Result operation at i-th iteration in the tensor iterator body that corresponds to this output port. If stride < 0, then output is concatenated in a reverse order:
Examples
Example 1: a typical TensorIterator structure
Example 2: a full TensorIterator layer