Model Optimizer is a cross-platform command-line tool that facilitates the transition between the training and deployment environment, performs static model analysis, and adjusts deep learning models for optimal execution on end-point target devices.
Model Optimizer process assumes you have a network model trained using a supported deep learning framework. The scheme below illustrates the typical workflow for deploying a trained deep learning model:
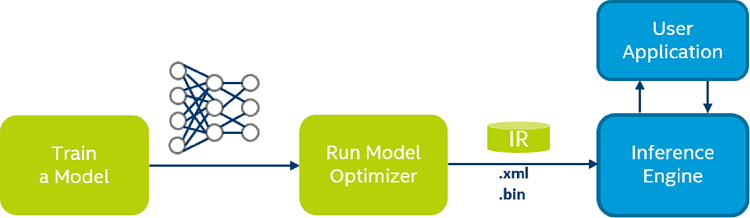
Model Optimizer produces an Intermediate Representation (IR) of the network, which can be read, loaded, and inferred with the Inference Engine. The Inference Engine API offers a unified API across a number of supported Intel® platforms. The Intermediate Representation is a pair of files describing the model:
-
.xml- Describes the network topology -
.bin- Contains the weights and biases binary data.
What's New in the Model Optimizer in this Release?
- ONNX*:
- Added support of the following ONNX* operations: DeformableConvolution, Upsample operation supporting 7th and 9th versions of opset, Gemm operation supporting alpha and beta attributes.
- Added support of the following Pytorch* topologies through conversion to ONNX*: ESPNet models from https://github.com/sacmehta/ESPNet/tree/master/pretrained.
- TensorFlow*:
- Added support of the following TensorFlow* operations: Erf, BatchMatMul, SpaceToDepth, Fill, Select, OneHot, TopK, GatherTree, LogicalAnd, LogicalOr, Equal, NotEqual, Less, LessEqual, Greater, GreaterEqual, Squeeze and ExpandDims (not converted to the Reshape layer anymore).
- Updated Model Optimizer to be compatible with TensorFlow 1.14.0.
- Added support of the following TensorFlow* topologies:
- TensorFlow Object Detection API version 1.13.X and 1.14.0 topologies
- I3D topologies from https://github.com/deepmind/kinetics-i3d
- GNMT (https://github.com/tensorflow/nmt) can be converted using this instruction
- BERT (https://github.com/google-research/bert) can be converted using this instruction
- Added support of the Dynamic sequence lengths in TensorFlow recurrent models
- Caffe*:
- Added support of SSH model (Single Stage Headless Face Detector) from https://github.com/mahyarnajibi/SSH.
- MXNet*:
- Added support of the following MXNet* operations: DeformableConvolution, DeformablePSROIPooling, Where, exp, slice_like, div_scalar, minus_scalar, greater_scalar, elemtwise_sub.
- Kaldi*:
- Added support for nnet3 TDNN networks.
- Common changes:
- Updated the IR version from 5 to 6.
- Extended the
--inputcommand line parameters to specify shapes and values for freezing arbitrary nodes (not only model inputs). The command line parameter--freeze_placeholder_with_valueis deprecated. - Implemented fusing of a Softmax layer pattern from Pytorch*.
- Introduced the new model transformation API for writing better Model Optimizer extensions.
- Renamed Intel experimental layer Quantize to FakeQuantize and ONNX Intel experimental operator Quantize to FakeQuantize
Notice that certain topology-specific layers (like DetectionOutput used in the SSD*) and several general-purpose layers (like Squeeze and Unsqueeze) are now delivered in the source code. This assumes that the extensions library is compiled/loaded. The extensions are also required for the pre-trained models inference. Please refer to the complete list of layers that require the extensions library.
NOTE: Intel® System Studio is an all-in-one, cross-platform tool suite, purpose-built to simplify system bring-up and improve system and IoT device application performance on Intel® platforms. If you are using the Intel® Distribution of OpenVINO™ with Intel® System Studio, go to Get Started with Intel® System Studio.
Table of Content
- Introduction to Intel® Deep Learning Deployment Toolkit
-
Preparing and Optimizing your Trained Model with Model Optimizer
- Configuring Model Optimizer
-
Converting a Model to Intermediate Representation (IR)
- Converting a Model Using General Conversion Parameters
- Converting Your Caffe* Model
-
Converting Your TensorFlow* Model
- Converting BERT from TensorFlow
- Converting GNMT from TensorFlow
- Converting YOLO from DarkNet to Tensorflow and then to IR
- Converting FaceNet from TensorFlow
- Converting DeepSpeech from TensorFlow
- Converting Language Model on One Billion Word Benchmark from TensorFlow
- Converting Neural Collaborative Filtering Model from TensorFlow*
- Converting TensorFlow* Object Detection API Models
- Converting TensorFlow*-Slim Image Classification Model Library Models
- Converting CRNN Model from TensorFlow*
- Converting Your MXNet* Model
- Converting Your Kaldi* Model
- Converting Your ONNX* Model
- Model Optimizations Techniques
- Cutting parts of the model
- Sub-graph Replacement in Model Optimizer
- Supported Framework Layers
- IR Notation Reference
- Custom Layers in Model Optimizer
- Model Optimizer Frequently Asked Questions
- Known Issues
Typical Next Step: Introduction to Intel® Deep Learning Deployment Toolkit