DL Workbench provides a graphical interface to find the optimal configuration of Batch/Parallel requests on a certain machine. To learn more about optimal configurations on specific hardware, refer to Deploy and Integrate Performance Criteria into Application.
Select a model and a dataset, then click Run Inference. The Project page appears.
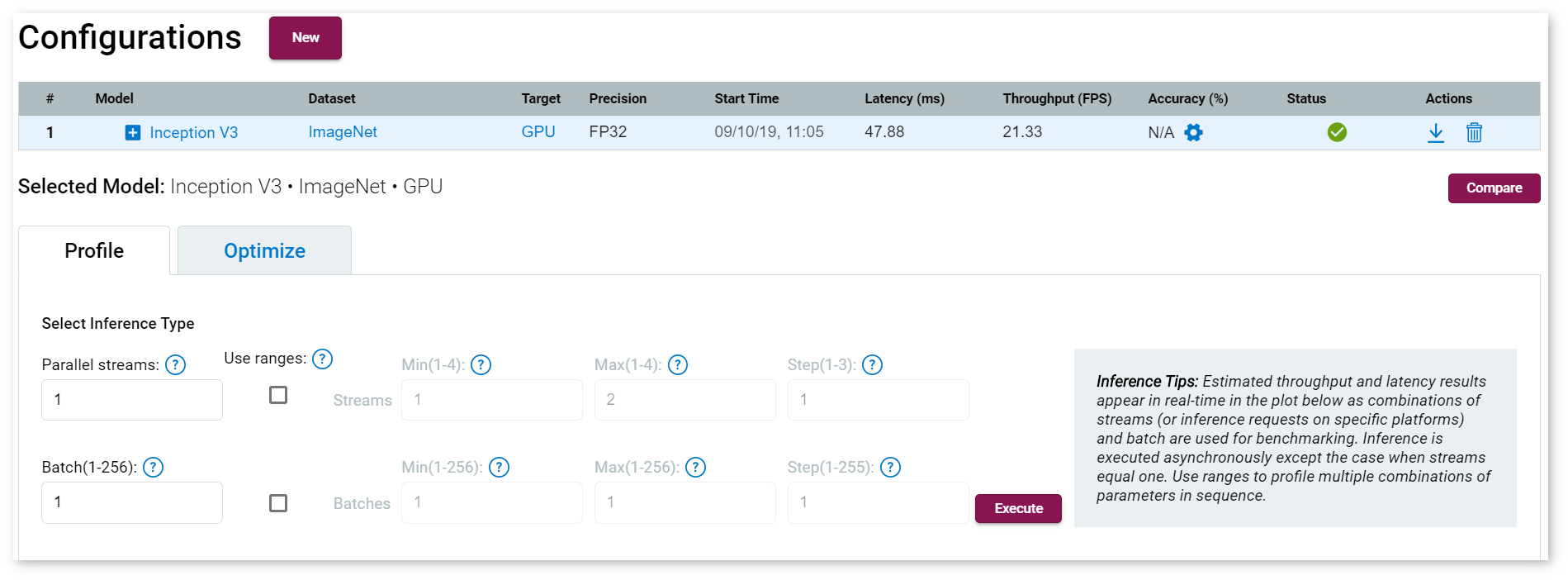
To run a range of inference streams, place check marks in the boxes under the Use Ranges section. Specify minimum and maximum numbers of inferences per an image and a batch, as well as the number of steps to increment on parallel requests or on a batch. Click Execute:
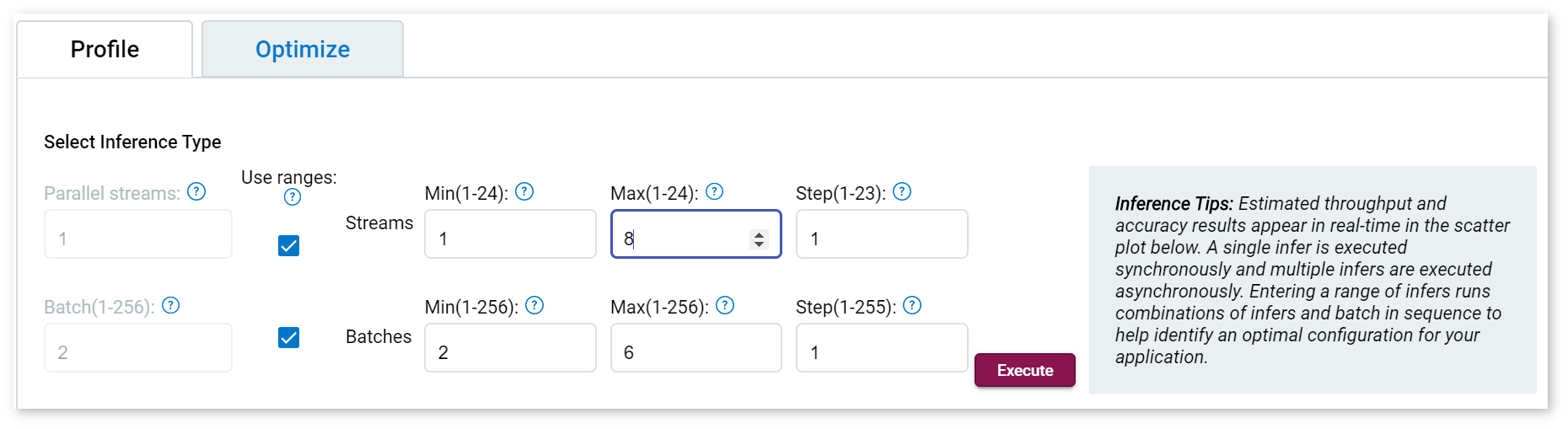
A step is the increment of parallel inference streams used for testing. For example, if the stream is set for 1-5, with step at 2, the inferences run for 1, 3 and 5 parallel streams. DL Workbench executes every combination of Batch/Inference values from minimum to maximum with the specified step.
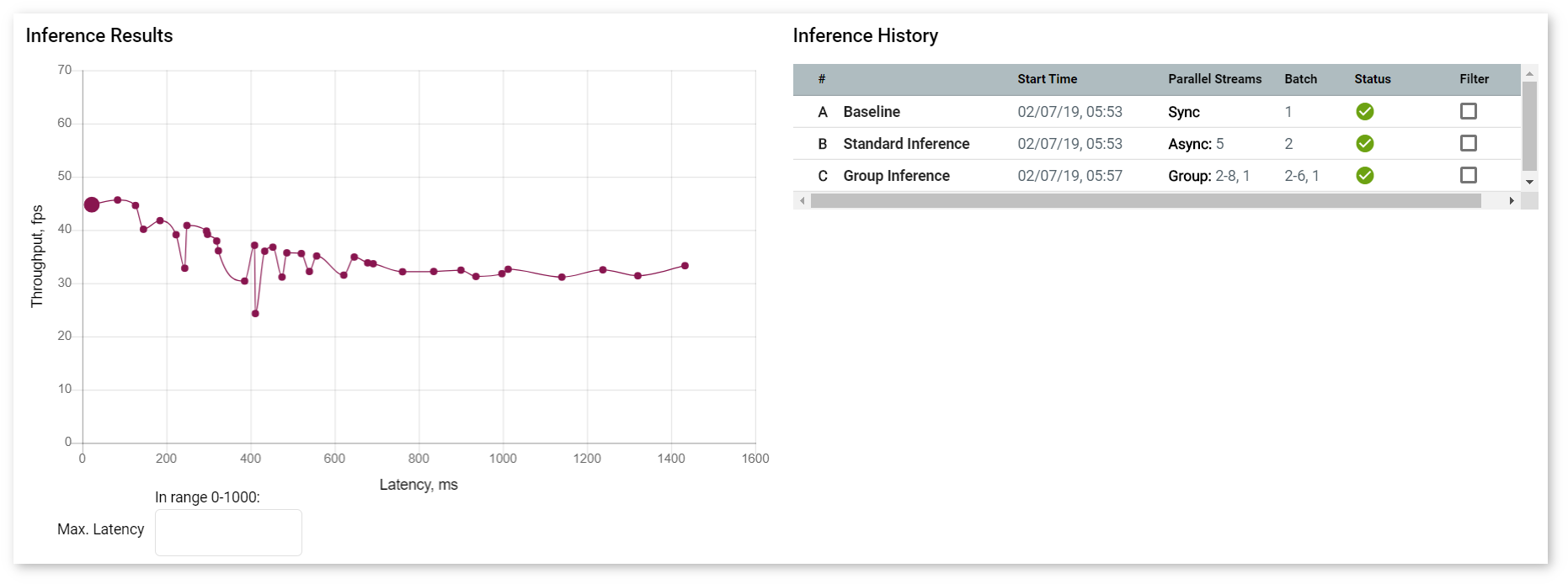
The graph in the Inference Results section shows points that represent each inference with a certain batch/parallel request configuration.
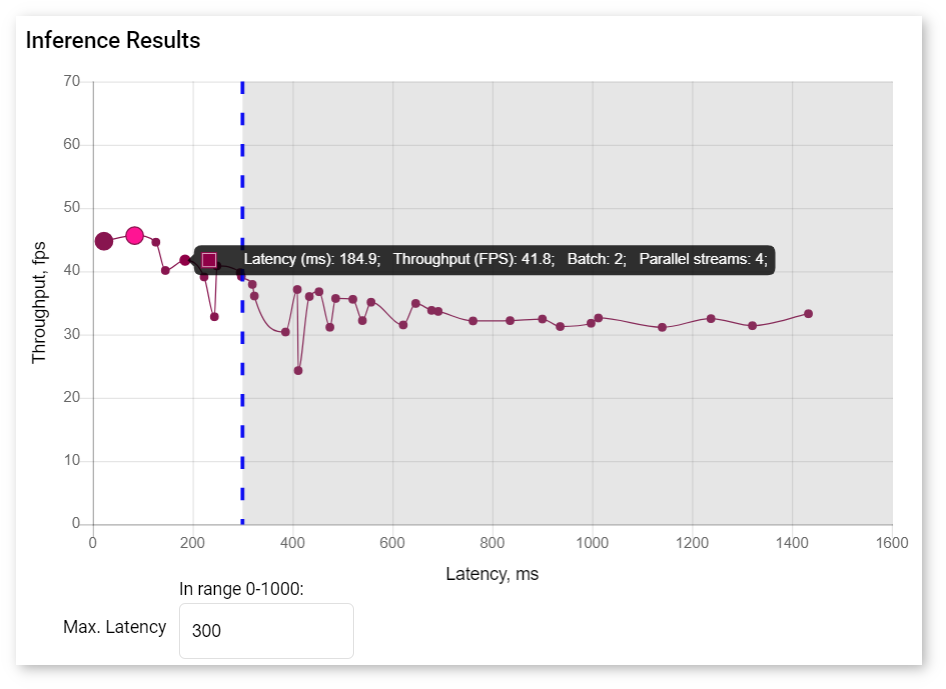
Right under the graph, you can specify maximum latency to find the optimal configuration with the best throughput. The point corresponding to this configuration turns pink.
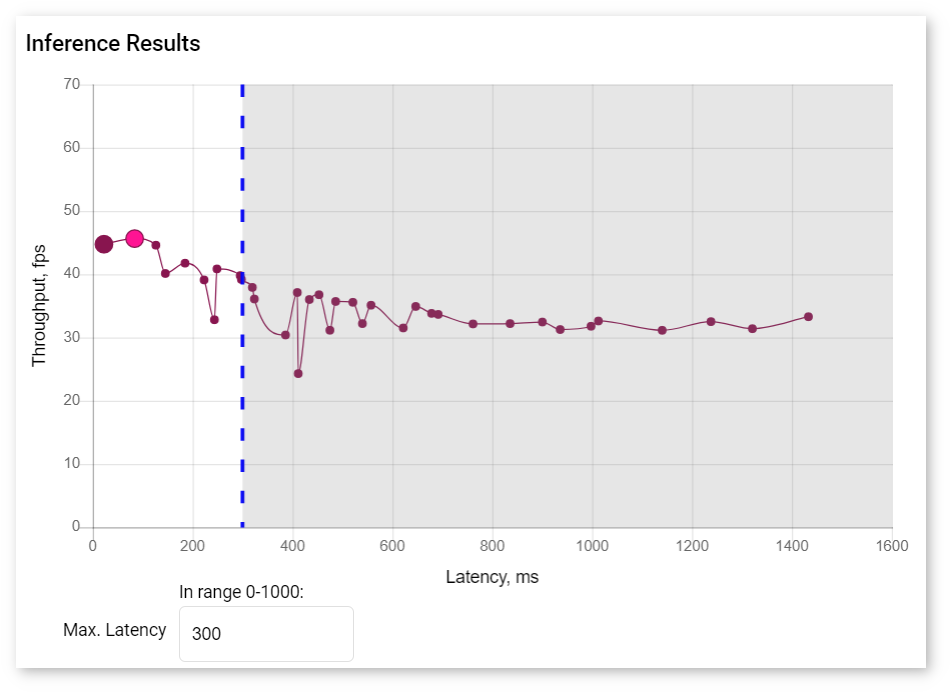
To view information about latency, throughput, batch, and parallel requests of a specific job, hover your cursor over the corresponding point on the graph.