NOTES:
- If you are using the Intel® Distribution of OpenVINO™ with Intel® System Studio, go to Get Started with Intel® System Studio.
- These steps apply to Ubuntu*, CentOS*, and Yocto*.
- If you are using Intel® Distribution of OpenVINO™ toolkit on Windows* OS, see the Installation Guide for Windows*.
- For the Intel Distribution of OpenVINO toolkit with FPGA support, see Installation Guide for Linux*.
- If you are migrating from the Intel® Computer Vision SDK 2017 R3 Beta version to the Intel Distribution of OpenVINO, read How to port your application from Intel® Computer Vision SDK 2017 R3 Beta to OpenVINO™ Toolkit article.
- CentOS and Yocto installations will require some modifications that are not covered in this guide.
- An internet connection is required to follow the steps in this guide.
Introduction
The Intel® Distribution of OpenVINO™ 2019 R1 toolkit quickly deploys applications and solutions that emulate human vision. Based on Convolutional Neural Networks (CNN), the toolkit extends computer vision (CV) workloads across Intel® hardware, maximizing performance. The Intel® Distribution of OpenVINO™ 2019 R1 toolkit includes the Intel® Deep Learning Deployment Toolkit (Intel® DLDT).
The Intel® Distribution of OpenVINO™ 2019 R1 toolkit for Linux*:
- Enables CNN-based deep learning inference on the edge
- Supports heterogeneous execution across Intel® CPU, Intel® Integrated Graphics, Intel® Movidius™ Neural Compute Stick, Intel® Neural Compute Stick 2, and Intel® Vision Accelerator Design with Intel® Movidius™ VPUs
- Speeds time-to-market via an easy-to-use library of computer vision functions and pre-optimized kernels
- Includes optimized calls for computer vision standards including OpenCV*, OpenCL™, and OpenVX*
Included with the Installation and installed by default:
| Component | Description |
|---|---|
| Model Optimizer | This tool imports, converts, and optimizes models that were trained in popular frameworks to a format usable by Intel tools, especially the Inference Engine. Popular frameworks include Caffe*, TensorFlow*, MXNet*, and ONNX*. |
| Inference Engine | This is the engine that runs the deep learning model. It includes a set of libraries for an easy inference integration into your applications. |
| Drivers and runtimes for OpenCL™ version 2.1 | Enables OpenCL on the GPU/CPU for Intel® processors |
| Intel® Media SDK | Offers access to hardware accelerated video codecs and frame processing |
| OpenCV version 3.4.2 | OpenCV* community version compiled for Intel® hardware. Includes PVL libraries for computer vision |
| OpenVX* version 1.1 | Intel's implementation of OpenVX* 1.1 optimized for running on Intel® hardware (CPU, GPU, IPU) |
| Demos and Sample Applications | A set of simple console applications demonstrating how to use the Inference Engine in your applications |
Development and Target Platform
The development and target platforms have the same requirements, but you can select different components during the installation, based on your intended use.
Hardware
- 6th-8th Generation Intel® Core™
- Intel® Xeon® v5 family
- Intel® Xeon® v6 family
- Intel® Pentium® processor N4200/5, N3350/5, N3450/5 with Intel® HD Graphics
- Intel® Movidius™ Neural Compute Stick
- Intel® Neural Compute Stick 2
- Intel® Vision Accelerator Design with Intel® Movidius™ VPU
Processor Notes:
- Processor graphics are not included in all processors. See Product Specifications for information about your processor.
- A chipset that supports processor graphics is required for Intel® Xeon® processors.
Operating Systems
- Ubuntu 16.04.x long-term support (LTS), 64-bit: Minimum supported kernel is 4.14
- CentOS 7.6, 64-bit
- Yocto Project Poky Jethro v2.0.3, 64-bit (for target only and requires modifications)
Overview
This guide provides step-by-step instructions on how to install the Intel® Distribution of OpenVINO™ 2019 R1 toolkit. Links are provided for each type of compatible hardware including downloads, initialization and configuration steps. The following steps will be covered:
- Install the Intel® Distribution of OpenVINO™ Toolkit
- Install External software dependencies
- Set the OpenVINO™ Environment Variables: Optional Update to .bashrc.
- Configure the Model Optimizer
- Run the Verification Scripts to Verify Installation and Compile Samples
- Steps for Intel® Processor Graphics (GPU)
- Steps for Intel® Movidius™ Neural Compute Stick and Intel® Neural Compute Stick 2
-
Steps for Intel® Vision Accelerator Design with Intel® Movidius™ VPU
After installing your Intel® Movidius™ VPU, you will return to this guide to complete OpenVINO™ installation. - Run a Sample Application
- Use the Face Detection Tutorial
Install the Intel® Distribution of OpenVINO™ 2019 R1 Toolkit Core Components
Download the Intel® Distribution of OpenVINO™ 2019 R1 toolkit package file from Intel® Distribution of OpenVINO™ toolkit for Linux*. Select the Intel® Distribution of OpenVINO™ toolkit for Linux package from the dropdown menu.
- Open a command prompt terminal window.
- Change directories to where you downloaded the Intel Distribution of OpenVINO toolkit for Linux* package file.
If you downloaded the package file to the current user'sDownloadsdirectory:By default, the file is saved ascd ~/Downloads/l_openvino_toolkit_p_<version>.tgz. - Unpack the .tgz file: The files are unpacked to thetar -xvzf l_openvino_toolkit_p_<version>.tgz
l_openvino_toolkit_p_<version>directory. - Go to the
l_openvino_toolkit_p_<version>directory:If you have a previous version of the Intel Distribution of OpenVINO toolkit installed, rename or delete these two directories:cd l_openvino_toolkit_p_<version>
/home/<user>/inference_engine_samples/home/<user>/openvino_models
Installation Notes:
- Choose an installation option and run the related script as root.
- You can use either a GUI installation wizard or command-line instructions (CLI).
- Screenshots are provided for the GUI, but not for CLI. The following information also applies to CLI and will be helpful to your installation where you will be presented with the same choices and tasks.
- Choose your installation option:
-
Option 1: GUI Installation Wizard: sudo ./install_GUI.sh
-
Option 2: Command-Line Instructions: sudo ./install.sh
-
Option 1: GUI Installation Wizard:
- Follow the instructions on your screen. Watch for informational messages such as the following in case you must complete additional steps:
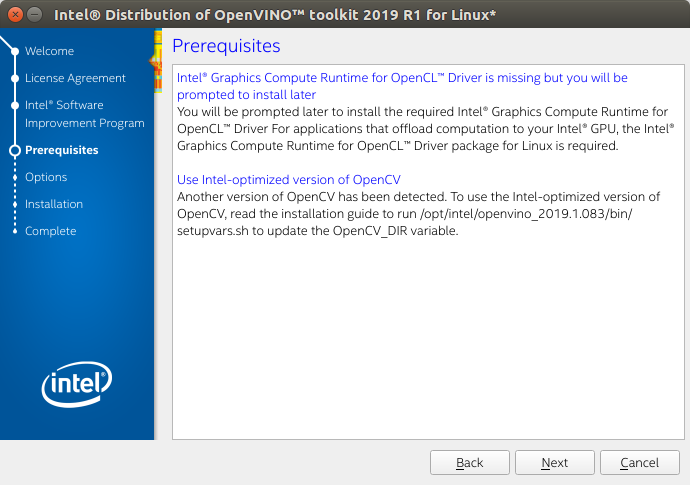
- If you select the default options, the Installation summary GUI screen looks like this:
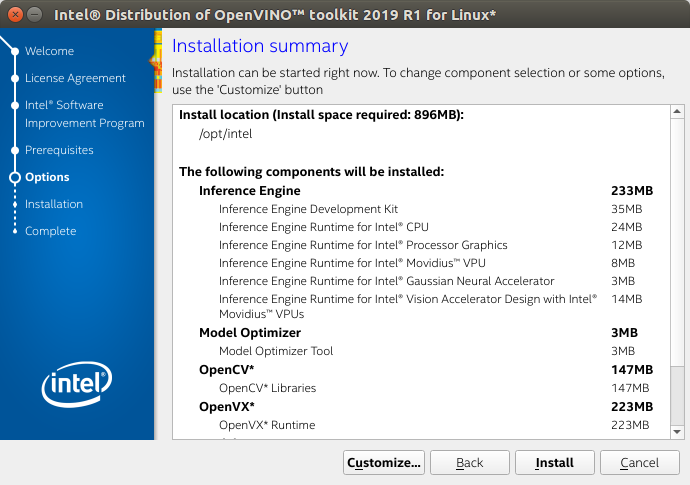
-
Optional: You can choose Customize to change the installation directory or the components you want to install: When installed as root the default installation directory for the Intel Distribution of OpenVINO 2019 R1 is
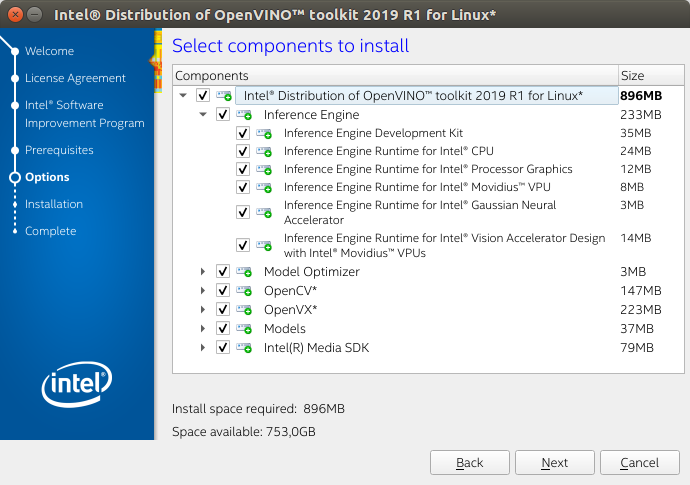
/opt/intel/openvino_<version>/.
For simplicity, a symbolic link to the latest installation is also created:/opt/intel/openvino/.
-
Optional: You can choose Customize to change the installation directory or the components you want to install:
- A Complete screen indicates that the core components have been installed:
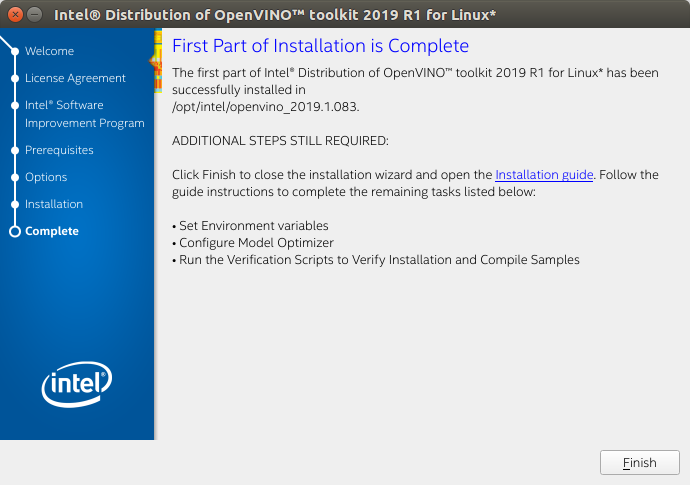
The first core components are installed. Continue to the next section to install additional dependencies.
Install External Software Dependencies
These dependencies are required for:
- Intel-optimized OpenCV
- Deep Learning Inference Engine
- Deep Learning Model Optimizer tools
- Change to the
install_dependenciesdirectory:cd /opt/intel/openvino/install_dependencies - Run a script to download and install the external software dependencies: The dependencies are installed. Continue to the next section to set your environment variables.sudo -E ./install_openvino_dependencies.sh
Set the Environment Variables
You must update several environment variables before you can compile and run OpenVINO™ applications. Run the following script to temporarily set your environment variables:
Optional: The OpenVINO environment variables are removed when you close the shell. As an option, you can permanently set the environment variables as follows:
- Open the
.bashrcfile in<user_directory>:vi <user_directory>/.bashrc - Add this line to the end of the file: source /opt/intel/openvino/bin/setupvars.sh
- Save and close the file: press the Esc key and type
:wq. - To test your change, open a new terminal. You will see
[setupvars.sh] OpenVINO environment initialized.
The environment variables are set. Continue to the next section to configure the Model Optimizer.
Configure the Model Optimizer
The Model Optimizer is a Python*-based command line tool for importing trained models from popular deep learning frameworks such as Caffe*, TensorFlow*, Apache MXNet*, ONNX* and Kaldi*.
The Model Optimizer is a key component of the Intel Distribution of OpenVINO toolkit. You cannot perform inference on your trained model without running the model through the Model Optimizer. When you run a pre-trained model through the Model Optimizer, your output is an Intermediate Representation (IR) of the network. The Intermediate Representation is a pair of files that describe the whole model:
-
.xml: Describes the network topology -
.bin: Contains the weights and biases binary data
For more information about the Model Optimizer, refer to the Model Optimizer Developer Guide.
Model Optimizer Configuration Steps
You can choose to either configure all supported frameworks at once OR configure one framework at a time. Choose the option that best suits your needs. If you see error messages, make sure you installed all dependencies.
IMPORTANT: The Internet access is required to execute the following steps successfully. If you have access to the Internet through the proxy server only, please make sure that it is configured in your environment.
NOTE: If you installed the Intel® Distribution of OpenVINO™ to the non-default install directory, replace
/opt/intelwith the directory in which you installed the software.
Option 1: Configure all supported frameworks at the same time
- Go to the Model Optimizer prerequisites directory: cd /opt/intel/openvino/deployment_tools/model_optimizer/install_prerequisites
- Run the script to configure the Model Optimizer for Caffe, TensorFlow, MXNet, Kaldi*, and ONNX: sudo ./install_prerequisites.sh
Option 2: Configure each framework separately
Configure individual frameworks separately ONLY if you did not select Option 1 above.
- Go to the Model Optimizer prerequisites directory: cd /opt/intel/openvino/deployment_tools/model_optimizer/install_prerequisites
- Run the script for your model framework. You can run more than one script:
- For Caffe: sudo ./install_prerequisites_caffe.sh
- For TensorFlow: sudo ./install_prerequisites_tf.sh
- For MXNet: sudo ./install_prerequisites_mxnet.sh
- For ONNX: sudo ./install_prerequisites_onnx.sh
- For Kaldi: The Model Optimizer is configured for one or more frameworks.sudo ./install_prerequisites_kaldi.sh
- For Caffe:
You are ready to compile the samples by running the verification scripts.
Run the Verification Scripts to Verify Installation
To verify the installation and compile two samples, run the verification applications provided with the product on the CPU:
- Go to the Inference Engine demo directory: cd /opt/intel/openvino/deployment_tools/demo
- Run the Image Classification verification script: This verification script downloads a SqueezeNet model, uses the Model Optimizer to convert the model to the .bin and .xml Intermediate Representation (IR) files. The Inference Engine requires this model conversion so it can use the IR as input and achieve optimum performance on Intel hardware../demo_squeezenet_download_convert_run.sh
This verification script builds the Image Classification Sample application and run it with thecar.pngimage located in the demo directory. When the verification script completes, you will have the label and confidence for the top-10 categories: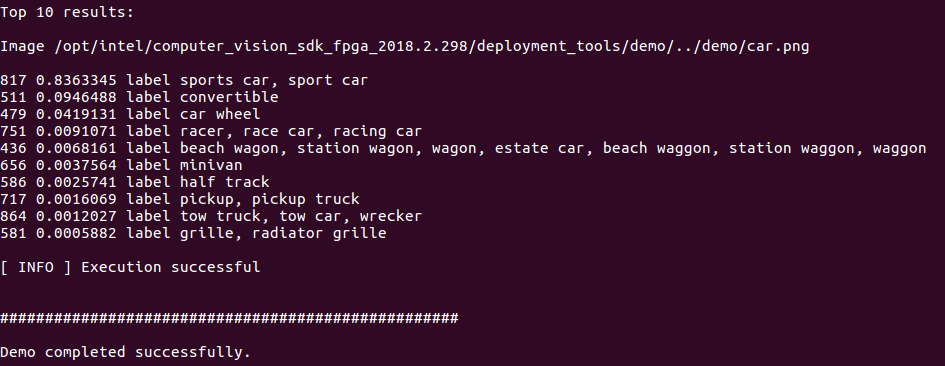
-
Run the Inference Pipeline verification script:
./demo_security_barrier_camera.shThis script downloads three pre-trained models IRs, builds the Security Barrier Camera Demo application and run it with the downloaded models and the
car_1.bmpimage from thedemodirectory to show an inference pipeline. The verification script uses vehicle recognition in which vehicle attributes build on each other to narrow in on a specific attribute.First, an object is identified as a vehicle. This identification is used as input to the next model, which identifies specific vehicle attributes, including the license plate. Finally, the attributes identified as the license plate are used as input to the third model, which recognizes specific characters in the license plate.
When the verification script completes, you will see an image that displays the resulting frame with detections rendered as bounding boxes, and text:

- Close the image viewer window to complete the verification script.
To learn about the verification scripts, see the README.txt file in /opt/intel/openvino/deployment_tools/demo.
For a description of the Intel Distribution of OpenVINO™ pre-trained object detection and object recognition models, see Overview of OpenVINO™ Toolkit Pre-Trained Models.
You have completed all required installation, configuration and build steps in this guide to use your CPU to work with your trained models. To use other hardware, see;
- Steps for Intel® Processor Graphics (GPU)
- Steps for Intel® Movidius™ Neural Compute Stick and Intel® Neural Compute Stick 2
-
Steps for Intel® Vision Accelerator Design with Intel® Movidius™ VPU
Steps for Intel® Processor Graphics (GPU)
The steps in this section are required only if you want to enable the toolkit components to use processor graphics (GPU) on your system.
- Go to the install_dependencies directory: cd /opt/intel/openvino/install_dependencies/
- Enter the super user mode: sudo -E su
- Install the Intel® Graphics Compute Runtime for OpenCL™ driver components required to use the GPU plugin and write custom layers for Intel® Integrated Graphics: You may see the following command line output:./install_NEO_OCL_driver.sh
- Add OpenCL user to video group
- Run script to install the 4.14 kernel script
Ignore those suggestions and continue.
- Optional Install header files to allow compiling a new code. You can find the header files at Khronos OpenCL™ API Headers.
Steps for Intel® Movidius™ Neural Compute Stick and Intel® Neural Compute Stick 2
These steps are only required if you want to perform inference on Intel® Movidius™ NCS powered by the Intel® Movidius™ Myriad™ 2 VPU or Intel® Neural Compute Stick 2 powered by the Intel® Movidius™ Myriad™ X VPU. See also the Get Started page for Intel® Neural Compute Stick 2:
- Add the current Linux user to the
usersgroup:Log out and log in for it to take effect.sudo usermod -a -G users "$(whoami)" - To perform inference on Intel® Movidius™ Neural Compute Stick and Intel® Neural Compute Stick 2, install the USB rules as follows: sudo cp /opt/intel/openvino/inference_engine/external/97-myriad-usbboot.rules /etc/udev/rules.d/sudo udevadm control --reload-rulessudo udevadm triggersudo ldconfig
Steps for Intel® Vision Accelerator Design with Intel® Movidius™ VPU
To install and configure your Intel® Vision Accelerator Design with Intel® Movidius™ VPU see the Intel® Vision Accelerator Design with Intel® Movidius™ VPUs Installation Guide
NOTE: After installing your Intel® Movidius™ VPU, you will return to this guide to complete OpenVINO™ installation.
You are ready to run the Classification Sample, which you have compiled by running the Image Classification verification script in the Run the Verification Scripts to Verify Installation section.
Run a Sample Application
IMPORTANT: This section requires that you have Run the Verification Scripts to Verify Installation.
Setting up a neural network is the first step in running a sample.
NOTE: If you are running inference only on a CPU, you already have the required FP32 neural network model. If you want to run inference on any hardware other than the CPU, you'll need an FP16 version of the model, which you will set up in the following section.
Set Up a Neural Network Model
In this section, you will create an FP16 model suitable for hardware accelerators.
- Make a directory for the FP16 SqueezeNet Model: mkdir /home/<user>/squeezenet1.1_FP16
- Go to
/home/<user>/squeezenet1.1_FP16:cd /home/<user>/squeezenet1.1_FP16 - Use the Model Optimizer to convert an FP16 Squeezenet Caffe* model into an optimized Intermediate Representation (IR): python3 /opt/intel/openvino/deployment_tools/model_optimizer/mo.py --input_model /home/<user>/openvino_models/models/FP32/classification/squeezenet/1.1/caffe/squeezenet1.1.caffemodel --data_type FP16 --output_dir .
- The
squeezenet1.1.labelsfile contains the classes that ImageNet uses. This file is included so that the inference results show text instead of classification numbers. Copysqueezenet1.1.labelsto your optimized model location:cp /home/<user>/openvino_models/ir/FP32/classification/squeezenet/1.1/caffe/squeezenet1.1.labels . - Copy a sample image to the release directory. You will use this with your optimized model: sudo cp /opt/intel/openvino/deployment_tools/demo/car.png ~/inference_engine_samples/intel64/Release
Once your neural network setup is complete, you're ready to run a sample application.
For information on Sample Applications, see the Inference Engine Samples Overview.
Congratulations, you have finished the Intel® Distribution of OpenVINO™ 2019 R1 toolkit installation for Linux. To learn more about how the Intel® Distribution of OpenVINO™ toolkit works, the Hello World tutorial and other resources are provided below.
Hello World Face Detection Tutorial
See the OpenVINO™ Hello World Face Detection Exercise.
Additional Resources
- Intel® Distribution of OpenVINO™ toolkit home page: https://software.intel.com/en-us/openvino-toolkit
- OpenVINO™ toolkit online documentation: https://docs.openvinotoolkit.org
- Model Optimizer Developer Guide
- Inference Engine Developer Guide
- For more information on Sample Applications, see the Inference Engine Samples Overview
- For information on Inference Engine Tutorials, see the Inference Tutorials
- For IoT Libraries & Code Samples see the Intel® IoT Developer Kit.
To learn more about converting models, go to: