Deployment Challenges
Deploying deep learning networks from the training environment to embedded platforms for inference might be a complex task that introduces a number of technical challenges that must be addressed:
- There are a number of deep learning frameworks widely used in the industry, such as Caffe*, TensorFlow*, MXNet*, Kaldi* etc.
- Typically the training of the deep learning networks is performed in data centers or server farms while the inference might take place on embedded platforms, optimized for performance and power consumption. Such platforms are typically limited both from software perspective (programming languages, third party dependencies, memory consumption, supported operating systems), and from hardware perspective (different data types, limited power envelope), so usually it is not recommended (and sometimes just impossible) to use original training framework for inference. An alternative solution would be to use dedicated inference APIs that are well optimized for specific hardware platforms.
- Additional complications of the deployment process include supporting various layer types and networks that are getting more and more complex. Obviously, ensuring the accuracy of the transforms networks is not trivial.
Deployment Workflow
The process assumes that you have a network model trained using one of the supported frameworks. The scheme below illustrates the typical workflow for deploying a trained deep learning model:
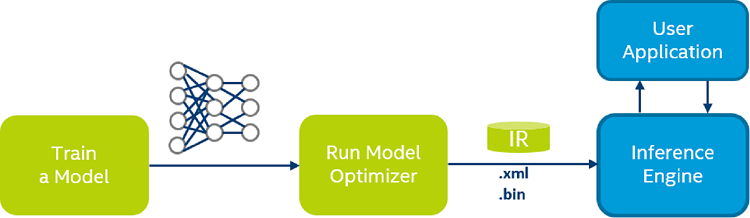
The steps are:
- Configure Model Optimizer for the specific framework (used to train your model).
- Run Model Optimizer to produce an optimized Intermediate Representation (IR) of the model based on the trained network topology, weights and biases values, and other optional parameters.
- Test the model in the IR format using the Inference Engine in the target environment via provided Inference Engine validation application or sample applications.
- Integrate Inference Engine in your application to deploy the model in the target environment.
Model Optimizer
Model Optimizer is a cross-platform command line tool that facilitates the transition between the training and deployment environment, performs static model analysis and automatically adjusts deep learning models for optimal execution on end-point target devices.
Model Optimizer is designed to support multiple deep learning supported frameworks and formats.
While running Model Optimizer you do not need to consider what target device you wish to use, the same output of the MO can be used in all targets.
Model Optimizer Workflow
The process assumes that you have a network model trained using one of the supported frameworks. The Model Optimizer workflow can be described as following:
- Configure Model Optimizer for one of the supported deep learning framework that was used to train the model.
- Provide as input a trained network that contains a certain network topology, and the adjusted weights and biases (with some optional parameters).
- Run Model Optimizer to perform specific model optimizations (for example, horizontal fusion of certain network layers). Exact optimizations are framework-specific, refer to appropriate documentation pages: Converting a Caffe Model, Converting a TensorFlow Model, Converting a MXNet Model, Converting a Kaldi Model, Converting an ONNX Model.
- Model Optimizer produces as output an Intermediate Representation (IR) of the network which is used as an input for the Inference Engine on all targets. The IR is a pair of files that describe the whole model:
-
.xml: The topology file - an XML file that describes the network topology -
.bin: The trained data file - a .bin file that contains the weights and biases binary data
-
The Intermediate Representation (IR) files can be read, loaded and inferred with Inference Engine. The Inference Engine API offers a unified API across a number of supported Intel® platforms.
Supported Frameworks and Formats
- Caffe* (most public branches)
- TensorFlow*
- MXNet*
- Kaldi*
- ONNX*
Supported Models
For the list of supported models refer to the framework or format specific page:
- Supported Caffe* models
- Supported TensorFlow* models
- Supported MXNet* models
- Supported ONNX* models
- Supported Kaldi* models
Inference Engine
Inference Engine is a runtime that delivers a unified API to integrate the inference with application logic:
- Takes as input the model. The model presented in the specific form of Intermediate Representation (IR) produced by Model Optimizer.
- Optimizes inference execution for target hardware.
- Delivers inference solution with reduced footprint on embedded inference platforms.
The Inference Engine supports inference of multiple image classification networks, including AlexNet, GoogLeNet, VGG and ResNet families of networks, fully convolutional networks like FCN8 used for image segmentation, and object detection networks like Faster R-CNN.
For the full list of supported hardware, refer to the Supported Devices section.
The Inference Engine package contains headers, runtime libraries, and sample console applications demonstrating how you can use the Inference Engine in your applications.
See Also
Optimization Notice
For complete information about compiler optimizations, see our Optimization Notice.