What's New in the 2018 R4 Release
- With 2018 R4 release, the Model Optimizer supports the
--input_shapecommand line parameter for the TensorFlow* Object Detection API topologies. Refer to the Custom Input Shape for more information. - To generate IRs for SSD topologies, the Model Optimizer creates a number of
PriorBoxClusteredlayers instead of a constant node with prior boxes calculated for the particular input image size. This change allows you to reshape the topology in the Inference Engine using dedicated Inference Engine API. The reshaping is supported for all SSD topologies except FPNs which contain hardcoded shapes for some operations preventing from changing topology input shape.
How to Convert a Model
With 2018 R3 release, the Model Optimizer introduces a new approach to convert models created using the TensorFlow* Object Detection API. Compared with the previous approach, the new process produces inference results with higher accuracy and does not require modifying any configuration files and providing intricate command line parameters.
You can download TensorFlow* Object Detection API models from the Object Detection Model Zoo.
NOTE: Before converting, make sure you have configured the Model Optimizer. For configuration steps, refer to Configuring the Model Optimizer.
To convert a TensorFlow* Object Detection API model, go to the <INSTALL_DIR>/deployment_tools/model_optimizer directory and run the mo_tf.py script with the following required parameters:
-
--input_model <path_to_frozen.pb>— File with a pre-trained model (binary or text .pb file after freezing) -
--tensorflow_use_custom_operations_config <path_to_subgraph_replacement_configuration_file.json>— A subgraph replacement configuration file that describes rules to convert specific TensorFlow* topologies. For the models downloaded from the TensorFlow* Object Detection API zoo, you can find the configuration files in the<INSTALL_DIR>/deployment_tools/model_optimizer/extensions/front/tfdirectory. Use:-
ssd_v2_support.json— for frozen SSD topologies from the models zoo -
faster_rcnn_support.json— for frozen Faster R-CNN topologies from the models zoo -
faster_rcnn_support_api_v1.7.json— for Faster R-CNN topologies trained manually using the TensorFlow* Object Detection API version 1.7.0 or higher -
mask_rcnn_support.json— for frozen Mask R-CNN topologies from the models zoo -
mask_rcnn_support_api_v1.7.json— for Mask R-CNN topologies trained manually using the TensorFlow* Object Detection API version 1.7.0 or higher up to 1.10.1 inclusively -
mask_rcnn_support_api_v1.11.json— for Mask R-CNN topologies trained manually using the TensorFlow* Object Detection API version 1.11.0 or higher -
rfcn_support.json— for the frozen RFCN topology from the models zoo frozen with TensorFlow* version 1.9.0 or lower.
-
-
--tensorflow_object_detection_api_pipeline_config <path_to_pipeline.config>— A special configuration file that describes the topology hyper-parameters and structure of the TensorFlow Object Detection API model. For the models downloaded from the TensorFlow* Object Detection API zoo, the configuration file is namedpipeline.config. If you plan to train a model yourself, you can find templates for these files in the models repository. -
--input_shape(optional) — A custom input image shape. Refer to Custom Input Shape for more information how the--input_shapeparameter is handled for the TensorFlow* Object Detection API models.
NOTE: If you convert a TensorFlow* Object Detection API model to use with the Inference Engine sample applications, you must specify the --reverse_input_channels parameter also.
Additionally to the mandatory parameters listed above you can use optional conversion parameters if needed. A full list of parameters is available in the Converting a TensorFlow* Model topic.
For example, if you downloaded the pre-trained SSD InceptionV2 topology and extracted archive to the directory /tmp/ssd_inception_v2_coco_2018_01_28, the sample command line to convert the model looks as follows:
Custom Input Shape
Model Optimizer handles command line parameter --input_shape for TensorFlow* Object Detection API models in a special way depending on the image resizer type defined in the pipeline.config file. TensorFlow* Object Detection API generates different Preprocessor sub-graph based on the image resizer type. Model Optimizer supports two types of image resizer:
-
fixed_shape_resizer— Stretches input image to the specific height and width. Thepipeline.configsnippet below shows afixed_shape_resizersample definition:image_resizer {fixed_shape_resizer {height: 300width: 300}} -
keep_aspect_ratio_resizer— Resizes the input image keeping aspect ratio to satisfy the minimum and maximum size constraints. Thepipeline.configsnippet below shows akeep_aspect_ratio_resizersample definition:image_resizer {keep_aspect_ratio_resizer {min_dimension: 600max_dimension: 1024}}
Fixed Shape Resizer Replacement
- If the
--input_shapecommand line parameter is not specified, the Model Optimizer generates an input layer with the height and width as defined in thepipeline.config. - If the
--input_shape [1, H, W, 3]command line parameter is specified, the Model Optimizer sets the input layer height toHand width toWand convert the model. However, the conversion may fail because of the following reasons:- The model is not reshape-able, meaning that it's not possible to change the size of the model input image. For example, SSD FPN models have
Reshapeoperations with hard-coded output shapes, but the input size to theseReshapeinstances depends on the input image size. In this case, the Model Optimizer shows an error during the shape inference phase. Run the Model Optimizer with--log_level DEBUGto see the inferred layers output shapes to see the mismatch. - Custom input shape is too small. For example, if you specify
--input_shape [1,100,100,3]to convert a SSD Inception V2 model, one of convolution or pooling nodes decreases input tensor spatial dimensions to non-positive values. In this case, the Model Optimizer shows error message like this: '[ ERROR ] Shape [ 1 -1 -1 256] is not fully defined for output X of "node_name".'
- The model is not reshape-able, meaning that it's not possible to change the size of the model input image. For example, SSD FPN models have
Keep Aspect Ratio Resizer Replacement
- If the
--input_shapecommand line parameter is not specified, the Model Optimizer generates an input layer with both height and width equal to the value of parametermin_dimensionin thekeep_aspect_ratio_resizer. - If the
--input_shape [1, H, W, 3]command line parameter is specified, the Model Optimizer scales the specified input image heightHand widthWto satisfy themin_dimensionandmax_dimensionconstraints defined in thekeep_aspect_ratio_resizer. The following function calculates the input layer height and width:
Models with keep_aspect_ratio_resizer were trained to recognize object in real aspect ratio, in contrast with most of the classification topologies trained to recognize objects stretched vertically and horizontally as well. By default, the Model Optimizer converts topologies with keep_aspect_ratio_resizer to consume a square input image. If the non-square image is provided as input, it is stretched without keeping aspect ratio that results to objects detection quality decrease.
NOTE: It is highly recommended to specify the
--input_shapecommand line parameter for the models withkeep_aspect_ratio_resizerif the input image dimensions are known in advance.
Important Notes About Feeding Input Images to the Samples
Inference Engine comes with a number of samples that use Object Detection API models including:
- Object Detection for SSD Sample — for RFCN, SSD and Faster R-CNNs
- Mask R-CNN Sample for TensorFlow* Object Detection API Models — for Mask R-CNNs
There are a number of important notes about feeding input images to the samples:
- Inference Engine samples stretch input image to the size of the input layer without preserving aspect ratio. This behavior is usually correct for most topologies (including SSDs), but incorrect for the following Faster R-CNN topologies: Inception ResNet, Inception V2, ResNet50 and ResNet101. Images pre-processing for these topologies keeps aspect ratio. Also all Mask R-CNN and R-FCN topologies require keeping aspect ratio. The type of pre-processing is defined in the pipeline configuration file in the section
image_resizer. If keeping aspect ratio is required, then it is necessary to resize image before passing it to the sample. - TensorFlow* implementation of image resize may be different from the one implemented in the sample. Even reading input image from compressed format (like
.jpg) could give different results in the sample and TensorFlow*. So, if it is necessary to compare accuracy between the TensorFlow* and the Inference Engine it is recommended to pass pre-scaled input image in a non-compressed format (like.bmp). - if you want to infer the model with the Inference Engine samples, convert the model specifying the
--reverse_input_channelscommand line parameter. The samples load images in BGR channels order, while TensorFlow* models were trained with images in RGB order. When the--reverse_input_channelscommand line parameter is specified, the Model Optimizer performs first convolution or other channel dependent operation weights modification so the output will be like the image is passed with RGB channels order.
Detailed Explanations of Model Conversion Process
This section is intended for users who want to understand how the Model Optimizer performs Object Detection API models conversion in details. The knowledge given in this section is also useful for users having complex models that are not converted with the Model Optimizer out of the box. It is highly recommended to read Sub-Graph Replacement in Model Optimizer chapter first to understand sub-graph replacement concepts which are used here.
Implementation of the sub-graph replacers for Object Detection API models is located in the file <INSTALL_DIR>/deployment_tools/model_optimizer/extensions/front/tf/ObjectDetectionAPI.py.
It is also important to open the model in the TensorBoard to see the topology structure. Model Optimizer can create an event file that can be then fed to the TensorBoard* tool. Run the Model Optimizer with providing two command line parameters:
-
--input_model <path_to_frozen.pb>— Path to the frozen model -
--tensorboard_logdir— Path to the directory where TensorBoard looks for the event files.
SSD (Single Shot Multibox Detector) Topologies
The SSD topologies are the simplest ones among Object Detection API topologies, so they will be analyzed first. The sub-graph replacement configuration file ssd_v2_support.json, which should be used to convert these models, contains three sub-graph replacements: ObjectDetectionAPIPreprocessorReplacement, ObjectDetectionAPISSDPostprocessorReplacement and ObjectDetectionAPIOutputReplacement. Their implementation is described below.
Preprocessor Block
All Object Detection API topologies contain Preprocessor block of nodes (aka "scope") that performs two tasks:
- Scales image to the size required by the topology.
- Applies mean and scale values if needed.
Model Optimizer cannot convert the part of the Preprocessor block performing scaling because the TensorFlow implementation uses while- loops which the Inference Engine does not support. Another reason is that the Inference Engine samples scale input images to the size of the input layer from the Intermediate Representation (IR) automatically. Given that it is necessary to cut-off the scaling part of the Preprocessor block and leave only operations applying mean and scale values. This task is solved using the Model Optimizer sub-graph replacer mechanism.
The Preprocessor block has two outputs: the tensor with pre-processed image(s) data and a tensor with pre-processed image(s) size(s). While converting the model, Model Optimizer keeps only the nodes producing the first tensor. The second tensor is a constant which can be obtained from the pipeline.config file to be used in other replacers.
The implementation of the Preprocessor block sub-graph replacer is the following (file <INSTALL_DIR>/deployment_tools/model_optimizer/extensions/front/tf/ObjectDetectionAPI.py):
The run_before function defines a list of replacers which current replacer should be run before. In this case it is Pack and Sub. The Sub operation is not supported by Inference Engine plugins so Model Optimizer replaces it with a combination of the Eltwise layer (element-wise sum) and the ScaleShift layer. But the Preprocessor replacer expects to see Sub node, so it should be called before the Sub is replaced.
The nodes_to_remove function returns list of nodes that should be removed after the replacement happens. In this case it removes all nodes matched in the Preprocessor scope except the Sub and Mul nodes performing mean value subtraction and scaling.
The generate_sub_graph function performs the following actions:
- Lines 20-24: Reads the
pipeline.configconfiguration file to get the model hyper-parameters and other attributes. - Lines 25-29: Checks that the output node of the
Preprocessorscope is of typeSub. - Lines 31-34: Checks that the input of the
Subnode is of typeMul. This information is needed to correctly connect the input node of the topology later. - Lines 36-50: Finds the topology input (placeholder) node and sets its weight and height according to the image resizer defined in the
pipeline.configfile and the--input_shapeprovided by the user. The batch size is set to 1 by default, but it will be overridden if you specify a batch size using command-line option-b. Refer to the Custom Input Shape on how the Model Optimizer calculates input layer height and width. - Lines 52-54: Saves the placeholder shape in the
graphobject for other sub-graph replacements. - Lines 56-59: Checks that the placeholder node follows the 'Cast' node which converts model input data from UINT8 to FP32.
- Lines 61-65: Creates edge from the placeholder node to the
Mul(if present) orSubnode to a correct input port (0 forSuband 1 forMul). - Line 69: The replacer returns a dictionary with nodes mapping that is used by other sub-graph replacement functions. In this case, it is not needed, so the empty dictionary is returned.
Postprocessor Block
A distinct feature of any SSD topology is a part performing non-maximum suppression of proposed images bounding boxes. This part of the topology is implemented with dozens of primitive operations in TensorFlow, while in Inference Engine, it is one layer called DetectionOutput. Thus, to convert a SSD model from the TensorFlow, the Model Optimizer should replace the entire sub-graph of operations that implement the DetectionOutput layer with a single DetectionOutput node.
The Inference Engine DetectionOutput layer implementation consumes three tensors in the following order:
- Tensor with locations of bounding boxes
- Tensor with confidences for each bounding box
- Tensor with prior boxes ("anchors" in a TensorFlow terminology)
The Inference Engine DetectionOutput layer implementation produces one tensor with seven numbers for each actual detection:
- batch index
- class label
- class probability
- x_1 box coordinate
- y_1 box coordinate
- x_2 box coordinate
- y_2 box coordinate.
There are more output tensors in the TensorFlow Object Detection API: "detection_boxes", "detection_classes", "detection_scores" and "num_detections", but the values in them are consistent with the output values of the Inference Engine DetectionOutput layer.
The sub-graph replacement by points is used in the ssd_v2_support.json to match the Postprocessor block. The start points are defined the following way:
- "Postprocessor/Shape" receives tensor with bounding boxes;
- "Postprocessor/scale_logits" receives tensor with confidences(probabilities) for each box;
- "Postprocessor/Tile" receives tensor with prior boxes (anchors);
- "Postprocessor/Reshape_1" is specified only to match the whole
Postprocessorscope. Not used in the replacement code; - "Postprocessor/ToFloat" is specified only to match the whole
Postprocessorscope. Not used in the replacement code.
There are a number of differences in layout, format and content of in input tensors to DetectionOutput layer and what tensors generates TensorFlow, so additional tensors processing before creating DetectionOutput layer is required. It is described below. The sub-graph replacement class for the DetectionOutput layer is given below:
The run_before and run_after functions define lists of replacers that this replacer should be run before and after respectively.
The input_edges_match and output_edges_match functions generate dictionaries describing how the input/output nodes matched with the replacer should be connected with new nodes generated in the generate_sub_graph function. Refer to sub-graph replacements documentation for more information.
The generate_sub_graph function performs the following actions:
- Lines 19-23: Reads the
pipeline.configconfiguration file to get the model hyper-parameters and other attributes. - Lines 25-32: Makes tensor with confidences 4D and apply correct activation function (read from the
pipeline.configfile) to it. - Line 33: Disables permutation of
expand_dims_node's attributes because they are already in the NCHW layout. - Lines 35-39: Makes tensor with bounding boxes 2D, where the first dimension corresponds to a batch size.
- Lines 49-52: Makes tensor with confidences 2D, where the first dimension corresponds to a batch size.
- Lines 41-44: Creates a node with
DetectionOutputlayer with a number of layer attributes from thepipeline.configfile. Also the inference function (inferattribute) is updated with a custom inference function__class__.do_infer. The latter change is described below. - Lines 46-59: Creates several
PriorBoxClusteredlayers which generate prior boxes depending on the type of the grid anchor generator defined in thepipeline.configfile. If the grid anchor type is not known then initializepriors_nodeas a node matched by the sub-graph replacement. In the latter case it is a constant node with prior boxes calculated for a particular input image shape. - Lines 61-72: Creates
DetectionOutputlayer with attributes from thepipeline.configfile. - Line 74: Returns dictionary with mapping of nodes that is used in the
input_edges_matchandoutput_edges_matchfunctions.
The paragraphs below explains why the inference function for the Detection Output layer is modified. Before doing that it is necessary to make acquaintance with selected high-level steps of the Model Optimize model conversion pipeline. Note, that only selected steps are required for understanding the change are mentioned:
- Model Optimizer creates calculation graph from the initial topology where each nodes corresponds to a operation from the initial model.
- Model Optimizer performs "Front replacers" (including the one being described now).
- Model Optimizer adds data nodes between operation nodes to the graph.
- Model Optimizer performs "Middle replacers".
- Model Optimizer performs "shape inference" phase. During this phase the shape of all data nodes is being calculated. Model Optimizer also calculates value for data tensors which are constant, i.e. do not depend on input. For example, tensor with prior boxes (generated with
MultipleGridAnchorGeneratoror similar scopes) doesn't depend on input and is evaluated by Model Optimizer during shape inference. Model Optimizer uses inference function stored in the 'infer' attribute of operation nodes. - Model Optimizer performs "Back replacers".
- Model Optimizer generates IR.
The do_infer function is needed to perform some adjustments to the tensor with prior boxes (anchors) that is known only after the shape inference phase and to perform additional transformations described below. This change is performed only if the tensor with prior boxes is not constant (so it is produced by PriorBoxClustered layers during inference). It is possible to make the Postprocessor block replacement as a Middle replacer (so the prior boxes tensor would be evaluated by the time the replacer is called), but in this case it will be necessary to correctly handle data nodes which are created between each pair of initially adjacent operation nodes. In order to inject required modification to the inference function of the DetectionOutput node, a new function is created to perform modifications and to call the initial inference function. The code of a new inference function is the following:
- Lines 3-18: Updates the value of the tensor with prior boxes by appending variance values if the prior boxes are pre-calculated. Inference Engine implementation of the
DetectionOutputlayer expects these values located within the tensor with bounding boxes, but in TensorFlow they are applied in different way. - Line 20: Executes initial inference function to calculate the output shape of this node.
- Lines 23-24: Finds predecessor node of type "Conv2D" of the node with bounding boxes (which is
node.in_node(0)) and modifies convolution weights so "X" and "Y" coordinates are swapped. In TensorFlow bounding boxes are stored in the tensors in "YXYX" order, while in the Inference Engine it is "XYXY". - Line 25: Executes function looking for
Reshapeoperations after theConv2Dnodes found above with 4D output and remove the dimension with index 2 which should be equal to 1. This is a workaround to make tensor 3D so its shape will not be transposed during the IR generation. The problem arises when bounding boxes predictions are reshaped from [1, 1, 1, X] to [1, X / 4, 1, 4]. The result tensor should not be transposed because after transpose it will have shape [1, 4, X / 4, 1] and the concatenation over dimension with index 2 will produce incorrect tensor. Also the function looks forConcatoperations and changes the concatenation dimension from 2 to 1.
Faster R-CNN Topologies
The Faster R-CNN models contain several building blocks similar to building blocks from SSD models so it is highly recommended to read the section about converting them first. Detailed information about Faster R-CNN topologies is provided in the abstract.
Preprocessor Block
Faster R-CNN topologies contain similar Preprocessor block as SSD topologies. The same ObjectDetectionAPIPreprocessorReplacement sub-graph replacer is used to cut it off.
Proposal
The Proposal layer is implemented with dozens of primitive operations in TensorFlow, meanwhile, it is a single layer in the Inference Engine. The ObjectDetectionAPIProposalReplacement sub-graph replacer identifies nodes corresponding to the layer and replaces them with required new nodes.
The main interest of the implementation of this replacer is the generate_sub_graph function.
Lines 26-36: Parses the pipeline.config file and gets required parameters for the Proposal layer.
Lines 38-73: Performs the following manipulations with the tensor with class predictions:
- TensorFlow uses the NHWC layout, while the Inference Engine uses NCHW. Model Optimizer by default performs transformations with all nodes data in the inference graph to convert it to the NCHW layout. The size of 'C' dimension of the tensor with class predictions is equal to
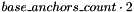 , where 2 corresponds to a number of classes (background and foreground) and
, where 2 corresponds to a number of classes (background and foreground) and 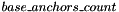 is equal to number of anchors that are applied to each position of 'H' and 'W' dimensions. Therefore, there are
is equal to number of anchors that are applied to each position of 'H' and 'W' dimensions. Therefore, there are 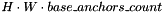 bounding boxes. Lines 54-56 apply the Softmax layer to this tensor to get class probabilities for each bounding box.
bounding boxes. Lines 54-56 apply the Softmax layer to this tensor to get class probabilities for each bounding box. - The dimension with classes must be in the fastest growing dimension to apply the Softmax activation. Lines 41-43 permute the tensor to NHWC layout first (because the Model Optimizer automatically permuted it to NCHW before) and then reshape to [N, total_bounding_boxes, 2].
- After applying the Softmax activation, lines 52-64 perform reversed actions to reshape the tensor to the initial dimensions.
- The inference function injection (like with
DetectionOutputlayer for SSD conversion) is used for the last reshape (lines 71-72), as the value of 'H' and 'W' dimensions are unknown during the replacement (because this is a Front replacer that is performed before the shape inference).
Lines 75-92: Adds the Proposal layer to the graph. This layer has one input containing input image size (lines 46-47). The image sizes are read from the pipeline.config file.
Lines 94-106: Scales bounding boxes to [0,1] interval as required by the ROIPooling layer with a bi-linear filtration.
Lines 108-113: Crops the output from the Proposal node to remove the batch indices (the Inference Engine implementation of the Proposal layer generates tensor with shape [num_proposals, 5]). The final tensor contains just box coordinates as in the TensorFlow implementation.
Lines 118-125: Updated inference function for the Reshape layer which restores the original shape of tensor with class probabilities. The inference function is patched because the original shape for this tensor is known only during the shape inference phase.
SecondStagePostprocessor Block
The SecondStagePostprocessor block is similar to the Postprocessor block from the SSDs topologies. But there are a number of differences in conversion of the SecondStagePostprocessor block.
The differences in conversion are the following:
- The locations tensor does not contain information about class 0 (background), but Inference Engine
DetectionOutputlayer expects it. Lines 45-58 append dummy tensor with fake coordinates. - The prior boxes tensor are not constant like in SSDs models, so it is not possible to apply the same solution. Instead, the element-wise multiplication is added to scale prior boxes values with [0.1, 0.1, 0.2, 0.2] and the attribute
variance_encoded_in_target=1is set to theDetectionOutputlayer (lines 62-74). - The X and Y coordinates in the tensor with bounding boxes locations adjustments should be swapped. For some topologies it could be done by updating preceding convolution weights, but if there is no preceding convolutional node, the Model Optimizer inserts convolution node with specific kernel and weights that performs coordinates swap during topology inference.
- Added marker node of type
OpOutputthat is used by the Model Optimizer to determine output nodes of the topology. It is used in the dead nodes elimination pass.
Cutting Off Part of the Topology
There is an ability to cut-off part of the topology using the --output command line parameter. Detailed information on why it could be useful is provided here. The Faster R-CNN models are cut at the end using the sub-graph replacer ObjectDetectionAPIOutputReplacement.
This is a replacer of type "general" which is called just once in comparison with other Front-replacers ("scope" and "points") which are called for each matched instance. The replacer reads node names that should become new output nodes, like specifying --output <node_names>. The only difference is that the string containing node names could contain '|' character specifying output node names alternatives. Detailed explanation is provided in the class description in the code.
The detection_boxes, detection_scores, num_detections nodes are specified as outputs in the faster_rcnn_support.json file. These nodes are used to remove part of the graph that is not be needed to calculate value of specified output nodes.
R-FCN topologies
The R-FCN models are based on Faster R-CNN models so it is highly recommended to read the section about converting them first. Detailed information about R-FCN topologies is provided in the abstract.
Preprocessor Block
R-FCN topologies contain similar Preprocessor block as SSD and Faster R-CNN topologies. The same ObjectDetectionAPIPreprocessorReplacement sub-graph replacer is used to cut it off.
Proposal
Similar to Faster R-CNNs, R-FCN topologies contain implementation of Proposal layer before the SecondStageBoxPredictor block, so ObjectDetectionAPIProposalReplacement replacement is used in the sub-graph replacement configuration file.
SecondStageBoxPredictor block
The SecondStageBoxPredictor block differs from the self-titled block from Faster R-CNN topologies. It contains a number of CropAndResize operations consuming variously scaled boxes generated with a Proposal layer. This block of operations is converted to intermediate representation as is, without using sub-graph replacements.
SecondStagePostprocessor block
The SecondStagePostprocessor block implements functionality of the DetectionOutput layer from the Inference Engine. The ObjectDetectionAPIDetectionOutputReplacement sub-graph replacement is used to replace the block. For this type of topologies the replacer adds convolution node to swap coordinates of boxes in of the 0-th input tensor to the DetectionOutput layer. The custom attribute coordinates_swap_method is set to value add_convolution in the sub-graph replacement configuration file to enable that behaviour. A method (swap_weights) is not suitable for this type of topologies because there are no Mul or Conv2D operations before the 0-th input of the DetectionOutput layer.
Cutting Off Part of the Topology
The R-FCN models are cut at the end with the sub-graph replacer ObjectDetectionAPIOutputReplacement as Faster R-CNNs topologies using the following output node names: detection_boxes.
Mask R-CNN Topologies
The Mask R-CNN models are based on Faster R-CNN models so it is highly recommended to read the section about converting them first. Detailed information about Mask R-CNN topologies is provided in the abstract.
Preprocessor Block
Mask R-CNN topologies contain similar Preprocessor block as SSD and Faster R-CNN topologies. The same ObjectDetectionAPIPreprocessorReplacement sub-graph replacer is used to cut it off.
Proposal and ROI (Region of Interest) Pooling
Proposal and ROI Pooling layers are added to Mask R-CNN topologies like in Faster R-CNNs.
DetectionOutput
Unlike in SSDs and Faster R-CNNs, the implementation of the DetectionOutput layer in Mask R-CNNs topologies is not separated in a dedicated scope. But the matcher is defined with start/end points defined in the mask_rcnn_support.json so the replacer correctly adds the DetectionOutput layer.
One More ROIPooling
There is the second CropAndResize (equivalent of ROIPooling layer) that uses boxes produced with the DetectionOutput layer. The ObjectDetectionAPIMaskRCNNROIPoolingSecondReplacement replacer is used to replace this node.
The Inference Engine DetectionOutput layer implementation produces one tensor with seven numbers for each actual detection:
- batch index
- class label
- class probability
- x_1 box coordinate
- y_1 box coordinate
- x_2 box coordinate
- y_2 box coordinate.
The boxes coordinates must be fed to the ROIPooling layer, so the Crop layer is added to remove unnecessary part (lines 37-38).
Then the result tensor is reshaped (lines 41-42) and ROIPooling layer is created (lines 44-47).
Mask Tensors Processing
The post-processing part of Mask R-CNN topologies filters out bounding boxes with low probabilities and applies activation function to the rest one. This post-processing is implemented using the Gather operation, which is not supported by the Inference Engine. Special Front-replacer removes this post-processing and just inserts the activation layer to the end. The filtering of bounding boxes is done in the dedicated demo mask_rcnn_demo. The code of the replacer is the following:
The replacer looks for the output node which name starts with 'SecondStageBoxPredictor' (the another node of type 'OpOutput' is located after the DetectionOutput node). This node contains the generated masks. The replacer adds activation layer 'Sigmoid' after this node as it is done in the initial TensorFlow* model.
Cutting Off Part of the Topology
The Mask R-CNN models are cut at the end with the sub-graph replacer ObjectDetectionAPIOutputReplacement using the following output node names:
SecondStageBoxPredictor_1/Conv_3/BiasAdd|SecondStageBoxPredictor_1/Conv_1/BiasAdd
One of these two nodes produces output mask tensors. The child nodes of these nodes are related to post-processing which is implemented in the Mask R-CNN demo and should be cut off.