Convolution Layer
Name: Convolution
Short description: Reference
Detailed description: Reference
Parameters: Convolution layer parameters should be specified in the convolution_data node, which is a child of the layer node.
-
Parameter name: stride
- Description: stride is a distance (in pixels) to slide the filter on the feature map over the (x, y) axis. For example, stride equal "1,1" means sliding the filter 1 pixel at a time over the (x, y) axis.
- Range of values: integer values starting from 0
-
Parameter name: stride-x
- Description: stride-x is a distance (in pixels) to slide the filter on the feature map over the x axis. For example, stride-x equal 1 means sliding the filter 1 pixel at a time over the x axis.
- Range of values: integer value
-
Parameter name: stride-y
- Description: stride-y is a distance (in pixels) to slide the filter on the feature map over the y axis. For example, stride-y equal 1 means sliding the filter 1 pixel at a time over the y axis.
- Range of values: integer value
-
Parameter name: pad
- Description: pad is a number of pixels to add to the left and top of the input. For example, pad equal 1 means adding 1 pixel to the left of the input. Right and bottom padding should be calculated from the expected output width (height).
- Range of values: integer values starting from 0
-
Parameter name: pad-x
- Description: pad-x is a number of pixels to add to the left of the input. For example, pad-x equal 1 means adding 1 pixel to the left of the input. Right and bottom padding should be calculated from the expected output width (height).
- Range of values: integer values starting from 0
-
Parameter name: pad-y
- Description: pad-y is a number of pixels to add to the top of the input. For example, pad-y equal 1 means adding 1 pixel to the top of the input. Right and bottom padding should be calculated from the expected output width (height).
- Range of values: integer values starting from 0
-
Parameter name: kernel
- Description: kernel is a width and height of each filter. For example, kernel equal 3 (3, 3) means that each filter has width and height equal to 3.
- Range of values: integer values starting from 0
-
Parameter name: kernel-x
- Description: kernel-x is a width of each filter. For example, kernel equal 3 means that each filter has width equal to 3.
- Range of values: integer value starting from 0
-
Parameter name: kernel-y
- Description: kernel-y is a height of each filter. For example, kernel-y equal 3 means that each filter has height equal to 3.
- Range of values: integer value starting from 0
-
Parameter name: output
- Description: output is a number of output feature maps per whole output (when group > 1, output still matches the number of output features regardless of group value). For example, output equals 1 means that there is 1 output feature map in a layer.
- Range of values: integer values starting from 0
-
Parameter name: group
- Description: group denotes the number of groups to which output and input should be split. For example, group equal 1 means that all the filters are applied to full input (usual convolution), group equals 2 means that both input and output channels are separated into 2 groups and i-th output group is connected to i-th input group channels. group equals number of output feature maps denotes depth-wise separable convolution (Reference).
- Range of values: integer values starting from 0
-
Parameter name: dilation
- Description: dilation denotes the distance in width and height between elements (weights) in the filter. For example, dilation equal "1,1" means that all the elements in the filter are neighbors, so it is the same as for the usual convolution. dilation equal "2,2" means that all the elements in the filter are matched not to adjacent elements in the input matrix, but to those that are adjacent with distance 1.
- Range of values: integer value starting from 0
-
Parameter name: dilation-x
- Description: dilation-x denotes the distance in width between elements (weights) in the filter. For example, dilation-x equal 1 means that all the elements in the filter are neighbors, so it is the same as for the usual convolution. dilation-x equal 2 means that all the elements in the filter are matched not to adjacent elements in the input matrix, but to those that are adjacent with distance 1.
-
Parameter name: dilation-y
- Description: dilation-y denotes the distance in height between elements (weights) in the filter. For example, dilation-y equal 1 means that all the elements in the filter are neighbors, so it is the same as for the usual convolution. dilation-y equal 2 means that all the elements in the filter are matched not to adjacent elements in the input matrix, but to those that are adjacent with distance 1.
- Range of values: integer value starting from 0
Weights Layout Weights layout is GOIYX, which means that X is changing the fastest, then Y, then Input, Output, then Group.
Mathematical Formulation
- For the convolutional layer, the number of output features in each dimension is calculated using the formula:
![\[ n_{out} = \left ( \frac{n_{in} + 2p - k}{s} \right ) + 1 \]](form_8.png)
- The receptive field in each layer is calculated using the formulas:
- Jump in the output feature map:
![\[ j_{out} = j_{in} * s \]](form_9.png)
- Size of the receptive field of output feature:
![\[ r_{out} = r_{in} + ( k - 1 ) * j_{in} \]](form_10.png)
- Center position of the receptive field of the first output feature:
![\[ start_{out} = start_{in} + ( \frac{k - 1}{2} - p ) * j_{in} \]](form_11.png)
- Output is calculated using the following formula:
![\[ out = \sum_{i = 0}^{n}w_{i}x_{i} + b \]](form_12.png)
- Jump in the output feature map:
Example
Gather Layer
Name: Gather
Short description: Gather layer takes slices of data in the second input blob according to the indices specified in the first input blob. The output blob shape is input2.shape[:axis] + input1.shape + input2.shape[axis + 1:].
Parameters: Gather layer parameters should be specified in the data section, which is placed as a child of the layer node.
-
Parameter name: axis
- Description: axis is a index of a dimension to gather data. For example, axis equal to 1 means that gathering is performed over the first dimension.
-
Range of values: a single integer in the range
[-len(input2.shape), len(input2.shape) - 1].
Inputs
-
1: Multidimensional input blob with indices to gather. The values for indices are in the range
[0, input1[axis] - 1]. - 2: Multidimensional input blob with arbitrary data.
Mathematical Formulation
![\[ output[:, ... ,:, i, ... , j,:, ... ,:] = input2[:, ... ,:, input1[i, ... ,j],:, ... ,:] \]](form_13.png)
Example
Pooling Layer
Name: Pooling
Short description: Reference
Detailed description: Reference
Parameters: Specify pooling layer parameters in the pooling_data node, which is a child of the layer node.
-
Parameter name: stride
- Description: stride is a distance (in pixels) to slide the filter on the feature map over the (x, y) axis. For example, stride equal "1,1" means sliding the filter 1 pixel at a time over the (x, y) axis.
- Range of values: integer values starting from 0
-
Parameter name: stride-x
- Description: stride-x is a distance (in pixels) to slide the filter on the feature map over the x axis. For example, stride-x equal 1 means sliding the filter 1 pixel at a time over the x axis.
- Range of values: integer value
-
Parameter name: stride-y
- Description: stride-y is a distance (in pixels) to slide the filter on the feature map over the y axis. For example, stride-y equal 1 means sliding the filter 1 pixel at a time over the y axis.
- Range of values: integer value
-
Parameter name: pad
- Description: pad is a number of pixels to add to the left and top of the input. For example, pad equal 1 means adding 1 pixel to the left of the input. Right and bottom padding should be calculated from the expected output width (height).
- Range of values: integer values starting from 0
-
Parameter name: pad-x
- Description: pad-x is a number of pixels to add to the left of the input. For example, pad-x equal 1 means adding 1 pixel to the left of the input. Right and bottom padding should be calculated from the expected output width (height).
- Range of values: integer values starting from 0
-
Parameter name: pad-y
- Description: pad-y is a number of pixels to add to the top of the input. For example, pad-y equal 1 means adding 1 pixel to the top of the input. Right and bottom padding should be calculated from the expected output width (height).
- Range of values: integer values starting from 0
-
Parameter name: kernel
- Description: kernel is a width and height of each filter. For example, kernel equal 3 (3, 3) means that each filter has width and height equal to 3.
- Range of values: integer values starting from 0
-
Parameter name: kernel-x
- Description: kernel-x is a width of each filter. For example, kernel equal 3 means that each filter has width equal to 3.
- Range of values: integer value starting from 0
-
Parameter name: kernel-y
- Description: kernel-y is a height of each filter. For example, kernel-y equal 3 means that each filter has height equal to 3.
- Range of values: integer value starting from 0
-
Parameter name: pool-method
- Description: pool-method is a type of pooling strategy for values.
-
Range of values:
- max - chooses the biggest value in a feature map for each filter position
- avg - takes the average value in a feature map for each filter position
-
Parameter name: exclude-pad
- Description: exclude-pad is a type of pooling strategy for values in the padding area. For example, if exclude-pad is "true", zero-values in the padding are not used.
- Range of values: "true" or "false"
-
Parameter name: rounding_type
- Description: rounding_type is a type of rounding to be applied.
-
Range of values:
- ceil
- floor
Mathematical Formulation
- For max pool-method:
![\[ output_{j} = MAX\{ x_{0}, ... x_{i}\} \]](form_14.png)
- For avg pool-method:
![\[ output_{j} = \frac{\sum_{i = 0}^{n}x_{i}}{n} \]](form_15.png)
Example
ROIPooling Layer
Name: ROIPooling
Short description: It is a pooling layer with max pooling strategy (see max option in the *Pooling layer* parameters description). It is used over feature maps of non-uniform sizes and outputs another feature map of a fixed size.
Detailed description: deepsense.io reference
Parameters: Specify ROIPooling layer parameters in the data node, which is a child of the layer node.
-
Parameter name: pooled_h
- Description: pooled_h is a height of the ROI output feature map. For example, pooled_h equal 6 means that the height of the output of ROIpooling is 6.
- Range of values: integer values starting from 0
-
Parameter name: pooled_w
- Description: pooled_w is a width of the ROI output feature map. For example, pooled_w equal 6 means that the width of the output of ROIpooling is 6.
- Range of values: integer values starting from 0
-
Parameter name: spatial_scale
- Description: spatial_scale is a ratio of the input feature map over the input image size.
- Range of values: positive floating point value
Mathematical Formulation
Example
FullyConnected Layer
Name: FullyConnected
Short description: Reference
Detailed description: Reference
Parameters: Specify FullyConnected layer parameters in the fc_data node, which is a child of the layer node.
-
Parameter name: out-size
- Description: out-size is a length of the output vector. For example, out-size equal 4096 means that the output vector length is 4096.
- Range of values: integer values starting from 0
Weights Layout OI, which means that Input is changing the fastest, then Output.
Mathematical Formulation
- If previous layer is FullyConnected:
![\[ y_{i} = f( z_{i} ) \quad with \quad z_{i} = \sum_{j=1}^{m_{1}^{( l-1 )}}w_{i,j}^{( l )}y_{i}^{ ( l -1 )} \]](form_16.png)
- Otherwise:
![\[ y_{i} = f( z_{i} ) \quad with \quad z_{i}^{ ( l )} = \sum_{j=1}^{m_{1}^{( l-1 )}}\sum_{r=1}^{m_{2}^{ ( l-1 )}}\sum_{s=1}^{m_{3}^{ ( l-1 )}}w_{i,j,r,s}^{ ( l )} ( Y_{i}^{ (l-1) })_{r,s} \]](form_17.png)
Example
ReLU Layer
Name: ReLU
Short description: Reference
Detailed description: Reference
Parameters: ReLU layer parameters can be (not mandatory) specified in the data node, which is a child of the layer node.
-
Parameter name: negative_slope
- Description: negative_slope is a multiplier, which is used if the unit is not active (that is negative). For example, negative_slope equal 0.1 means that an inactive unit value would be multiplied by 0.1 and this is the Leaky ReLU. If negative_slope is equal to 0, this is the usual ReLU.
- Range of values: double values starting from 0
Mathematical Formulation
![\[ Y_{i}^{( l )} = max(0, Y_{i}^{( l - 1 )}) \]](form_18.png)
Example
Activation Layer
Name: Activation
Short description: Activation layer represents an activation function of each neuron in a layer, which is used to add non-linearity to the computational flow.
Detailed description: Reference
Parameters: Activation layer parameters should be specified in the data node, which is a child of the layer node.
-
Parameter name: type
- Description: type represents particular activation function. For example, type equal sigmoid means that neurons of this layer have a sigmoid activation function.
-
Range of values:
- sigmoid - sigmoid activation function. Learn more from the Detailed description section.
- tanh - tanh activation function. Learn more from the Detailed description section.
- elu - elu activation function. Learn more from the Detailed description section.
- relu6 - relu6 activation function.
Mathematical Formulation
- Sigmoid function:
![\[ f( x ) = \frac{1}{1+e^{-x}} \]](form_19.png)
- Tahn function:
![\[ f ( x ) = \frac{2}{1+e^{-2x}} - 1 = 2sigmoid(2x) - 1 \]](form_20.png)
- Elu function:
![\[ f(x) = \left\{\begin{array}{ll} e^{x} - 1 \quad \mbox{if } x < 0 \\ x \quad \mbox{if } x \geq 0 \end{array}\right. \]](form_21.png)
- Relu6 function:
![\[ f(x) = min(max(0, x), 6) \]](form_22.png)
Example
SoftMax layer
Name: SoftMax
Short description: Reference
Detailed description: Reference
Parameters: SoftMax layer parameters can be (not mandatory) specified in the data node, which is a child of the layer node.
-
Parameter name: axis
- Description: axis represents the axis of which the SoftMax is calculated. axis equal 1 is a default value.
- Range of values: positive integer values
Mathematical Formulation
![\[ y_{c} = \frac{e^{Z_{c}}}{\sum_{d=1}^{C}e^{Z_{d}}} \]](form_23.png)
where 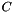 is a number of classes
is a number of classes
Example
Deconvolution Layer
Name: Deconvolution
Short description: Deconvolution layer is applied for upsampling the output to the higher image resolution.
Detailed description: Reference
Parameters: Deconvolution layer parameters should be specified in the deconvolution_data node, which is a child of the layer node.
Parameters: Convolution layer parameters should be specified in the convolution_data node, which is a child of the layer node.
-
Parameter name: stride
- Description: stride is a distance (in pixels) to slide the filter on the feature map over the (x, y) axis. For example, stride equal "1,1" means sliding the filter 1 pixel at a time over the (x, y) axis.
- Range of values: integer values starting from 0
-
Parameter name: stride-x
- Description: stride-x is a distance (in pixels) to slide the filter on the feature map over the x axis. For example, stride-x equal 1 means sliding the filter 1 pixel at a time over the x axis.
- Range of values: integer value
-
Parameter name: stride-y
- Description: stride-y is a distance (in pixels) to slide the filter on the feature map over the y axis. For example, stride-y equal 1 means sliding the filter 1 pixel at a time over the y axis.
- Range of values: integer value
-
Parameter name: pad
- Description: pad is a number of pixels to add to the left and top of the input. For example, pad equal 1 means adding 1 pixel to the left of the input. Right and bottom padding should be calculated from the expected output width (height).
- Range of values: integer values starting from 0
-
Parameter name: pad-x
- Description: pad-x is a number of pixels to add to the left of the input. For example, pad-x equal 1 means adding 1 pixel to the left of the input. Right and bottom padding should be calculated from the expected output width (height).
- Range of values: integer values starting from 0
-
Parameter name: pad-y
- Description: pad-y is a number of pixels to add to the top of the input. For example, pad-y equal 1 means adding 1 pixel to the top of the input. Right and bottom padding should be calculated from the expected output width (height).
- Range of values: integer values starting from 0
-
Parameter name: kernel
- Description: kernel is a width and height of each filter. For example, kernel equal 3 (3, 3) means that each filter has width and height equal to 3.
- Range of values: integer values starting from 0
-
Parameter name: kernel-x
- Description: kernel-x is a width of each filter. For example, kernel equal 3 means that each filter has width equal to 3.
- Range of values: integer value starting from 0
-
Parameter name: kernel-y
- Description: kernel-y is a height of each filter. For example, kernel-y equal 3 means that each filter has height equal to 3.
- Range of values: integer value starting from 0
-
Parameter name: output
- Description: output is a number of output feature maps per whole output (when group > 1, output still matches the number of output features regardless of group value). For example, output equals 1 means that there is 1 output feature map in a layer.
- Range of values: integer values starting from 0
-
Parameter name: group
- Description: group denotes the number of groups to which output and input should be split. For example, group equal 1 means that all the filters are applied to full input (usual convolution), group equals 2 means that both input and output channels are separated into 2 groups and i-th output group is connected to i-th input group channels. group equals number of output feature maps denotes depth-wise separable convolution (Reference).
- Range of values: integer values starting from 0
-
Parameter name: dilation
- Description: dilation denotes the distance in width and height between elements (weights) in the filter. For example, dilation equal "1,1" means that all the elements in the filter are neighbors, so it is the same as for the usual convolution. dilation equal "2,2" means that all the elements in the filter are matched not to adjacent elements in the input matrix, but to those that are adjacent with distance 1.
- Range of values: integer value starting from 0
-
Parameter name: dilation-x
- Description: dilation-x denotes the distance in width between elements (weights) in the filter. For example, dilation-x equal 1 means that all the elements in the filter are neighbors, so it is the same as for the usual convolution. dilation-x equal 2 means that all the elements in the filter are matched not to adjacent elements in the input matrix, but to those that are adjacent with distance 1.
-
Parameter name: dilation-y
- Description: dilation-y denotes the distance in height between elements (weights) in the filter. For example, dilation-y equal 1 means that all the elements in the filter are neighbors, so it is the same as for the usual convolution. dilation-y equal 2 means that all the elements in the filter are matched not to adjacent elements in the input matrix, but to those that are adjacent with distance 1.
- Range of values: integer value starting from 0
Weights Layout Weights layout is the following: GOIYX, which means that X is changing the fastest, then Y, then Input, Output, then Group.
Mathematical Formulation
Deconvolution is also called transpose convolution and performs operation, reverse to convolution.
The number of output features for each dimensions is calculated:
![\[S_{o}=stride(S_{i} - 1 ) + S_{f} - 2pad \]](form_24.png)
Where 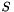 is size of output, input and filter.
is size of output, input and filter.
Output is calculated in the same way as for convolution layer:
![\[out = \sum_{i = 0}^{n}w_{i}x_{i} + b\]](form_26.png)
Example
Local Response Normalization (LRN) layer
Name: Norm
Short description: Reference
Detailed description: Reference
Parameters: Norm layer parameters should be specified in the norm_data node, which is a child of the layer node.
-
Parameter name: alpha
- Description: alpha represents the scaling parameter for the normalizing sum. For example, alpha equal 0.0001 means that the normalizing sum is multiplied by 0.0001.
- Range of values: floating point positive number
-
Parameter name: beta
- Description: beta represents the exponent for the normalizing sum. For example, beta equal 0.75 means that the normalizing sum is raised to the power of 0.75.
- Range of values: floating point positive number
-
Parameter name: region
- Description: region represents strategy of local regions extension. For example, region equal across means that the normalizing sum is performed over adjacent channels.
-
Range of values:
- across - normalizing sum is performed over adjacent channels
- same - normalizing sum is performed over nearby spatial locations
-
Parameter name: local-size
- Description: local-size represents the side length of the region to be used for the normalization sum or number of channels depending on the strategy specified in the region parameter. For example, local-size equal 5 for the across strategy means application of sum across 5 adjacent channels.
- Range of values: positive integer bigger than zero
Mathematical Formulation
![\[o_{i} = \left( 1 + \left( \frac{\alpha}{n} \right)\sum_{i}x_{i}^{2} \right)^{\beta}\]](form_27.png)
Where 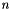 is the size of each local region.
is the size of each local region.
Example
Concat Layer
Name: Concat
Short description: Reference
Parameters: Concat layer parameters should be specified in the concat_data node, which is a child of the layer node.
-
Parameter name: axis
- Description: axis is the number of axis over which input blobs are concatenated. For example, axis equal 1 means that input blobs are concatenated over the first axis.
- Range of values: positive number greater or equal to 0
Mathematical Formulation
Axis parameter specifies a blob dimension to concat values. For example, for two input blobs B1xC1xH1xW1 and B2xC2xh4xW2 if axis: 1, output blob is****: B1xC1+C2xH1xW1. This is only possible if B1=B2, H1=H4, W1=W2.
Example
Split Layer
Name: Split
Short description: Split layer splits the input into several output groups. Group sizes are denoted by the number and the size of output ports.
Detailed description: Reference
Parameters: None
Mathematical Formulation
Splits input blob among children. For example, blob is BxC+CxHxW and there are two children. Then, output blob is BxCxHxW.
Example
Reshape Layer
Name: Reshape
Short description: Reshape layer changes dimensions of the input blob according to the specified order. Input blob volume is equal to output blob volume, where volume is the product of dimensions.
Detailed description: Reference
Parameters: Reshape layer parameters should be specified in the data node, which is a child of the layer node.
-
Parameter name: axis
- Description: axis is the number of the starting axis for reshape. For example, axis equal 1 means that Reshape replaces dimensions starting from the next after the first dimension.
- Range of values: positive number greater or equal to 0
-
Parameter name: dim
- Description: dim is a set of numbers separated with comma, which denote the dimensions of output blob. For example, dim equal 88,1,71 means that output blob gets following dimensions: first dimension equals 88, second dimension equals 1, third dimension equals 71. For more information, refer to the Description block. If dim is equal to two numbers, it performs flattening.
- Range of values: set of positive integer numbers separated with comma
-
Parameter name: num_axes
- Description: num_axes is the number of dimensions to be replaced with a reshaped blob starting from the dimension number specified in axis property. For example, num_axes equal 2 means that 2 dimensions are replaced with reshaped blob.
-
Range of values:
- -1 - all dimensions are taken starting from the dimension number specified in axis property
- positive number greater than the value in the axis parameter
Mathematical Formulation
If you want to reshape input blob BxCxHxW into Bx1x(C*H)xW, the dim parameters of your layer should be:
Example
Eltwise Layer
Name: Eltwise
Short description: Eltwise layer performs element-wise operation, which is specified in parameters, over given inputs.
Parameters: Eltwise layer parameters should be specified in the elementwise_data node, which is placed as a child of the layer node.
-
Parameter name: operation
- Description: operation is the simple mathematical operation to be performed over inputs. For example, operation equal mul means that input blobs are multiplied.
-
Range of values:
- sum - summation of given values
- max - select maximum from given values
- mul - multiplication of given values
Mathematical Formulation Eltwise accepts 2 inputs of any number of dimensions - from 1 to 4, however, it is required for both of them to have absolutely same dimensions. The produced blob is also of the same dimension as each of its parents
Eltwise does the following with the input blobs:
![\[ o_{i} = f(b_{i}^{1}, b_{i}^{2}) \]](form_29.png)
where 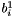 - first blob
- first blob 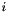 -th element,
-th element, 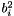 - second blob -th element,
- second blob -th element, 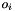 - output blob -th element,
- output blob -th element, 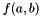 - is a function that performs an operation over its two arguments
- is a function that performs an operation over its two arguments 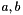 .
.
- For sum operation, is defined as
![\[ f(a,b) = a + b \]](form_36.png)
- For mul operation, is defined as
![\[ f(a,b) = a * b \]](form_37.png)
- For max operation, is defined as
![\[ f(a,b) = \left\{\begin{array}{ll} a \quad \mbox{if } a \geq b \\ b \quad \mbox{if } b > a \end{array}\right. \]](form_38.png)
Example
ScaleShift Layer
Name: ScaleShift
Short description: ScaleShift layer performs linear transformation of the input blobs. Weights denote scaling parameter, biases - a shift.
Parameters: ScaleShift layer does not have additional parameters.
Mathematical Formulation
![\[ o_{i} =\gamma b_{i} + \beta \]](form_39.png)
Example
Crop (Type 1) Layer
Name: Crop
Short description: Crop layer changes selected dimensions of the input blob according to the specified parameters.
Parameters: Crop layer parameters should be specified in data section, which is placed as a child of the layer node. Due to various representation of Crop attributes in existing frameworks, this layer can be described in three independent ways: Crop Type 1 layer takes two input blobs, and the shape of the second blob specifies the Crop size. The layer has two attributes: axis and offset. Crop layer takes two input blobs, and the shape of the second blob specifies the Crop size. The Crop layer of this type supports shape inference.
-
Parameter name: axis
- Description: axis is a number of a dimension to be used for cropping. For example, axis equal to 1 means that cropping is performed over the first dimension.
- Range of values: a list of unique integers, where each element is greater than or equal to 0 and less than input shape length.
-
Parameter name: offset
- Description: offset denotes the starting point for crop in the input blob. For example, offset equal to 2 means that crop is starting from the second value in the given axis.
-
Range of values: a list of integers of the length equal to the length of axis attribute. In the list,
offset[i]is greater than or equal to 0 and less than or equal toinput_shape[axis[i]] - crop_size[axis[i]], wherecrop_sizeis the shape of the second input.
Inputs
- 1: Multidimensional input blob *(for example, NCHW, NCH, or NC)*
- 2: Shape of this input will be used for crop
Example
Crop (Type 2) Layer
Name: Crop
Short description: Crop layer changes selected dimensions of the input blob according to the specified parameters.
Parameters: Crop layer parameters should be specified in data section, which is placed as a child of the layer node. Due to various representation of Crop attributes in existing frameworks, this layer can be described in three independent ways: Crop Type 2 layer takes one input blob to Crop and has three attributes: axis, offset, and dim. Crop layer takes one input blob to Crop and has axis, offset, and dim attributes. The Crop layer of this type supports shape inference only when shape propagation is applied to dimensions that are not specified in the axis attribute.
-
Parameter name: axis
- Description: axis is a number of a dimension to be used for cropping. For example, axis equal to 1 means that cropping is performed over the first dimension.
- Range of values: a list of unique integers, where each element is greater than or equal to 0 and less than input shape length
-
Parameter name: offset
- Description: offset denotes the starting point for crop in the input blob. For example, offset equal to 2 means that cropping starts from the second value in the given axis.
-
Range of values: a list of integers with the length equal to length of axis attribute, where
offset[i]is greater than or equal to 0 and less or equal toinput_shape[axis[i]] - dim[i]
-
Parameter name: dim
- Description: dim is the resulting size of the output blob for the given axis. For example, dim equal to 88 means that the output blob gets the dimension equal to 88 for the given axis.
- Range of values: a list of integers
Example
Crop (Type 3) Layer
Name: Crop
Short description: Crop layer changes selected dimensions of the input blob according to the specified parameters.
Parameters: Crop layer parameters should be specified in data section, which is placed as a child of the layer node. Due to various representation of Crop attributes in existing frameworks, this layer can be described in three independent ways: Crop Type 3 layer takes one input blob to Crop and has three attributes: axis, crop_begin, and crop_end. Crop layer takes one input blob to Crop and has axis, crop_begin, and crop_end attributes. The Crop layer of this type supports shape inference.
-
Parameter name: axis
- Description: axis is the number of the dimension to be used for cropping. For example, axis equal 1 means that cropping is performed over the first dimension.
- Range of values: a list of unique integers, where each element is greater than or equal to 0 and less than input shape length
-
Parameter name: crop_begin
- Description: crop_begin specifies the starting offset for crop in the input blob for given axes.
-
Range of values: a list of integers, where
crop_begin[i]is greater than or equal to 0 and less thaninput_shape[axis[i]] - crop_end[i]
-
Parameter name: crop_end
- Description: crop_end specifies the ending offset for crop in the input blob for given axes.
-
Range of values: a list of integers, where
crop_end[i]is greater than or equal to 0 and less thaninput_shape[axis[i]] - crop_begin[i]
Example
Batch Normalization Layer
Name: BatchNormalization
Short description: Reference
Detailed description: Reference
Parameters: BatchNormalization layer parameters should be specified as the batch_norm_data node, which is a child of the layer node.
-
Parameter name: epsilon
- Description: epsilon is the number to be added to the variance to avoid division by zero when normalizing the value. For example, epsilon equal 0.001 means that 0.001 is added to the variance.
- Range of values: positive floating point number
Mathematical Formulation
BatchNormalization is the normalization of the output in each hidden layer.
-
Input: Values of
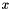 over a mini-batch:
over a mini-batch: ![\[ \beta = \{ x_{1...m} \} \]](form_41.png)
-
Parameters to learn:
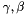
-
Output:
![\[ \{ o_{i} = BN_{\gamma, \beta} ( b_{i} ) \} \]](form_43.png)
-
Mini-batch mean:
![\[ \mu_{\beta} \leftarrow \frac{1}{m}\sum_{i=1}^{m}b_{i} \]](form_44.png)
-
Mini-batch variance:
![\[ \sigma_{\beta }^{2}\leftarrow \frac{1}{m}\sum_{i=1}^{m} ( b_{i} - \mu_{\beta} )^{2} \]](form_45.png)
-
Normalize:
![\[ \hat{b_{i}} \leftarrow \frac{b_{i} - \mu_{\beta}}{\sqrt{\sigma_{\beta }^{2} + \epsilon }} \]](form_46.png)
-
Scale and shift:
![\[ o_{i} \leftarrow \gamma\hat{b_{i}} + \beta = BN_{\gamma ,\beta } ( b_{i} ) \]](form_47.png)
Example
Normalize Layer
Name: Normalize
Short description: Normalize layer performs l-p normalization of 1 of input blob.
Parameters: Normalize layer parameters should be specified as the data node, which is a child of the layer node.
-
Parameter name: across_spatial
- Description: across_spatial is a flag that denotes if normalization is performed over CHW or HW. For example, across_spatial equals 0 means that normalization is not shared across channels.
-
Range of values:
- 0
- 1 - not supported
-
Parameter name: channel_shared
- Description: channel_shared is a flag that denotes if scale parameters are shared across channels. For example, channel_shared equal 0 means that scale parameters are not shared across channels.
-
Range of values:
- 0 - scale parameters are not shared across channels
- 1 - not supported
-
Parameter name: eps
- Description: eps is the epsilon used to avoid division by zero when normalizing the value. For example, eps equals 0.001 means that 0.001 is used if all the values in normalization are equal to zero.
- Range of values: positive floating point number
Mathematical Formulation
![\[ o_{i} = \sum_{i}^{H*W}\frac{\left ( n*C*H*W \right )* scale}{\sqrt{\sum_{i=0}^{C*H*W}\left ( n*C*H*W \right )^{2}}} \]](form_48.png)
Example
Tile Layer
Name: Tile
Short description: Tile layer extends input blob with copies of data along specific axis.
Detailed description: Reference
Parameters: Tile layer parameters should be specified as the tile_data node, which is a child of the layer node.
-
Parameter name: axis
- Description: axis is the index of the axis to tile. For example, axis equals 3 means that fourth axis is used for tiling.
- Range of values: positive integer number
-
Parameter name: tiles
- Description: tiles is a size of the specified axis in the output blob. For example, tiles equal 88 means that output blob gets 88 copies of data from specified axis.
- Range of values: positive integer number
Mathematical Formulation
Tile extends input blobs and filling in output blobs following rules:
![\[ out_i=input_i[inner\_dim*t] \]](form_49.png)
![\[ t \in \left ( 0, \quad tiles \right ) \]](form_50.png)
Example
Permute Layer
Name: Permute
Short description: Permute layer performs reordering of input blob dimensions.
Detailed description: Reference
Parameters: Permute layer parameters should be specified as the data node, which is a child of the layer node.
NOTE: Model Optimizer (Beta 2) does not use the
datanode for retrieving parameters and currently supports only the following order for permutation: 0,2,3,1.
-
Parameter name: order
- Description: order is the set of dimensions indexes for output blob. For example, order equal 0,2,3,1 means that the output blob has following dimensions: first dimension from the input blob, third dimension from the input blob, fourth dimension from the input blob, second dimension from the input blob.
- Range of values: set of positive integer numbers separated by comma
Mathematical Formulation
Permute layer performs reordering input blob. Source indexes and destination indexes are bound by formula:
![\[ src\_ind_{offset} = n * ordered[1] * ordered[2] * ordered[3] + (h * ordered[3] + w) \]](form_51.png)
![\[ n \in ( 0, order[0] ) \]](form_52.png)
![\[ h \in ( 0, order[2] ) \]](form_53.png)
![\[ w \in ( 0, order[3] ) \]](form_54.png)
Example
PriorBox Layer
Name: PriorBox
Short description: PriorBox layer generates prior boxes of specified sizes and aspect ratios across all dimensions.
Parameters: PriorBox layer parameters should be specified as the data node, which is a child of the layer node.
-
Parameter name: min_size (max_size)
- Description: min_size (max_size) is the minimum (maximum) box size (in pixels). For example, min_size (max_size) equal 15 means that the minimum (maximum) box size is 15.
- Range of values: positive integer number
-
Parameter name: aspect_ratio
- Description: aspect_ratio is a variance of aspect ratios. Duplicate values are ignored. For example, aspect_ratio equal 2.000000,3.000000 means that for the first box aspect_ratio is equal to 2 and for the second box - 3.
- Range of values: set of positive integer numbers
-
Parameter name: flip
- Description: flip is a flag that denotes that each aspect_ratio is duplicated and flipped. For example, flip equals 1 and aspect_ratio equals 3 mean that aspect_ratio is equal to 1/3.
-
Range of values:
- 0 - each aspect_ratio is flipped
- 1 - each aspect_ratio is not flipped
-
Parameter name: clip
- Description: clip is a flag that denotes if each value in the output blob is within [0,1]. For example, clip equal 1 means that each value in the output blob is within [0,1].
-
Range of values:
- 0 - clipping is not performed
- 1 - each value in the output blob is within [0,1]
-
Parameter name: step
- Description: step is a distance between box centers. For example, step equal 85 means that the distance between neighborhood prior boxes centers is 85.
- Range of values: floating point positive number
-
Parameter name: offset
- Description: offset is a shift of box respectively to top left corner. For example, offset equal 85 means that the shift of neighborhood prior boxes centers is 85.
- Range of values: floating point positive number
-
Parameter name: variance
- Description: variance denotes a variance of adjusting bounding boxes. For example, variance equals 85 means that the shift of neighborhood prior boxes centers is 85.
- Range of values: floating point positive number
-
Parameter name: scale_all_sizes
- Description: scale_all_sizes is a flag that denotes type of inference. For example, scale_all_sizes equals 0 means that priorbox layer is inferd in MXNet-like manner. In particular, max_size parameter is ignored.
-
Range of values:
- 0 - max_size is ignored
- 1 - default value. max_size is used
Mathematical Formulation: PriorBox computes coordinates of prior boxes by following:
-
First calculates center_x and center_y of prior box:
![\[ W \equiv Width \quad Of \quad Image \]](form_55.png)
![\[ H \equiv Height \quad Of \quad Image \]](form_56.png)
- If step equals 0:
![\[ center_x=(w+0.5) \]](form_57.png)
![\[ center_y=(h+0.5) \]](form_58.png)
- else:
![\[ center_x=(w+offset)*step \]](form_59.png)
![\[ center_y=(h+offset)*step \]](form_60.png)
![\[ w \subset \left( 0, W \right ) \]](form_61.png)
![\[ h \subset \left( 0, H \right ) \]](form_62.png)
- If step equals 0:
- Then, for each
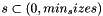 calculates coordinates of priorboxes:
calculates coordinates of priorboxes: ![\[ xmin = \frac{\frac{center_x - s}{2}}{W} \]](form_64.png)
![\[ ymin = \frac{\frac{center_y - s}{2}}{H} \]](form_65.png)
![\[ xmax = \frac{\frac{center_x + s}{2}}{W} \]](form_66.png)
![\[ ymin = \frac{\frac{center_y + s}{2}}{H} \]](form_67.png)
Example
SimplerNMS layer
Name: SimplerNMS
Short description: SimplerNMS layer performs filtering of bounding boxes and outputs only those with the highest confidence of prediction.
Parameters: SimplerNMS layer parameters should be specified as the data node, which is a child of the layer node.
-
Parameter name: pre_nms_topn (post_nms_topn)
- Description: pre_nms_topn (post_nms_topn) is the quantity of bounding boxes before (after) applying NMS operation. For example, pre_nms_topn (post_nms_topn) equals 15 means that the minimum (maximum) box size is 15.
- Range of values: positive integer number
-
Parameter name: cls_threshold
- Description: cls_threshold is the minimum value of the proposal to be taken into consideration. For example, cls_threshold equal 0.5 means that all boxes with prediction probability less than 0.5 are filtered out.
- Range of values: positive floating point number
-
Parameter name: iou_threshold
- Description: iou_threshold is the minimum ratio of boxes overlapping to be taken into consideration. For example, iou_threshold equal 0.7 means that all boxes with overlapping ratio less than 0.7 are filtered out.
- Range of values: positive floating point number
-
Parameter name: feat_stride
- Description: feat_stride is the step size to slide over boxes (in pixels). For example, feat_stride equal 16 means that all boxes are analyzed with the slide 16.
- Range of values: positive integer number
-
Parameter name: min_bbox_size
- Description: min_bbox_size is the minimum size of box to be taken into consideration. For example, min_bbox_size equal 35 means that all boxes with box size less than 35 are filtered out.
- Range of values: positive integer number
-
Parameter name: scale
- Description: scale is array of scales for anchor boxes generating.
- Range of values: positive integer number
Mathematical Formulation
SimplerNMS accepts three inputs with four dimensions. Produced blob has two dimensions, the first one equals post_nms_topn.
SimplerNMS does the following with the input blob:
- Generates initial anchor boxes. Left top corner of all boxes is (0, 0). Width and height of boxes are calculated based on scaled (according to the scale parameter) default widths and heights
- For each point in the first input blob:
- pins anchor boxes to picture according to the second input blob, which contains four deltas for each box: for x and y of center, for width, and for height
- finds out score in the first input blob
- Filters out boxes with size less than min_bbox_size.
- Sorts all proposals (box, score) by score from highest to lowest
- Takes top pre_nms_topn proposals
- Calculates intersections for boxes and filters out all with
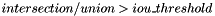
- Takes top post_nms_topn proposals
- Returns top proposals
Example
DetectionOutput Layer
Name: DetectionOutput
Short description: DetectionOutput layer performs non-maximum suppression to generate the detection output using information on location and confidence predictions.
Detailed description: Reference
Parameters: DetectionOutput layer parameters should be specified as the data node, which is a child of the layer node.
-
Parameter name: num_classes
- Description: number of classes to be predicted
- Range of values: positive integer values
-
Parameter name: background_label_id
- Description: background label id. If there is no background class, set it to -1.
- Range of values: integer values
-
Parameter name: top_k
- Description: maximum number of results to be kept on NMS stage
- Range of values: integer values
-
Parameter name: variance_encoded_in_target
- Description: if "true", variance is encoded in target. Otherwise, we need to adjust the predicted offset accordingly.
- Range of values: logical values
-
Parameter name: keep_top_k
- Description: number of total bboxes to be kept per image after NMS step. -1 means keeping all bboxes after NMS step.
- Range of values: integer values
-
Parameter name: num_orient_classes
- Range of values: integer values
-
Parameter name: code_type
- Description: type of coding method for bounding boxes
- Range of values: caffe.PriorBoxParameter.CENTER_SIZE and others
-
Parameter name: share_location
- Description: bounding boxes are shared among different classes.
- Range of values: logical values
-
Parameter name: interpolate_orientation
- Range of values: integer values
-
Parameter name: nms_threshold
- Description: threshold to be used in NMS stage
- Range of values: floating point values
-
Parameter name: confidence_threshold
- Description: only consider detections whose confidences are larger than a threshold. If not provided, consider all boxes.
- Range of values: floating point values
Mathematical Formulation
At each feature map cell, DetectionOutput predicts the offsets relative to the default box shapes in the cell, as well as the per-class scores that indicate the presence of a class instance in each of those boxes. Specifically, for each box out of k at a given location, DetectionOutput computes class scores and the four offsets relative to the original default box shape. This results in a total of 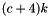 filters that are applied around each location in the feature map, yielding
filters that are applied around each location in the feature map, yielding 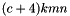 outputs for a m × n feature map.
outputs for a m × n feature map.
Example
Memory / Delay Object layer
Name: Memory
Short description: Memory layer represents delay layer in terms of LSTM terminology. To read more about LSTM topologies please refer this link.
Detailed description: Memory layer saves state between two infer requests. In the topology, it is the single layer, however, in the Intermediate Representation, it is always represented as a pair of Memory layers. One of these layers does not have outputs and another does not have inputs (in terms of the Intermediate Representation).
Parameters: Memory layer parameters should be specified as the data node, which is a child of the layer node.
-
Parameter name: id
- Description: id is the id of the pair of Memory layers. For example, id equals r_27-28 means that layers with id 27 and 28 are in one pair.
- Range of values: positive integer number
-
Parameter name: index
- Description: index represents if the given layer is input or output. For example, index equal 0 means this layer is output one.
-
Range of values:
- 0 - current layer is output one
- 1 - current layer is input one
-
Parameter name: size
- Description: size represents the size of the group. For example, size equals 2 means this group is a pair.
- Range of values: only 2 is supported
Mathematical Formulation Memory save data from the input blob.
Example
Clamp Layer
Name: Clamp
Short description: Clamp layer represents clipping activation operation.
Detailed description: Reference
Parameters: Clamp layer parameters should be specified as the data node, which is a child of the layer node.
-
Parameter name: min
- Description: min is the lower bound of values in the output shape. Any value in the input shape that is smaller than the bound, is replaced by the min value. For example, min equal 10 means that any value in the input shape that is smaller than the bound, is replaced by 10.
- Range of values: positive integer number
-
Parameter name: max
- Description: max is the upper bound of values in the output shape. Any value in the input shape that is greater than the bound, is replaced by the max value. For example, max equals 50 means that any value in the input shape that is greater than the bound, is replaced by 50.
- Range of values: positive integer number
Mathematical Formulation
Clamp generally does the following with the input blobs:
![\[ out_i=\left\{\begin{array}{ll} max\_value \quad \mbox{if } \quad input_i>max\_value \\ min\_value \quad \mbox{if } \quad input_i \end{array}\right. \]](form_71.png)
Example
ArgMax Layer
Name: ArgMax
Short description: ArgMax layer compute the index of the K maximum values for each datum across all dimensions CxHxW.
Detailed description: Intended for use after a classification layer to produce a prediction. If parameter out_max_val is set to "true", output is a vector of pairs *(max_ind, max_val)* for each image. The axis parameter specifies an axis along which to maximize.
Parameters: ArgMax layer parameters should be specified as the data node, which is a child of the layer node.
-
Parameter name: top_k
- Description: number K of maximum items to output
- Range of values: positive integer number
- **Parameter name**: out_max_val
- Description: if out_max_val equals 1, output is a vector of pairs *(max_ind, max_val)*, unless axis is set. Then output is max_val along the specified axis.
- Range of values: 0 or 1
-
Parameter name: axis
- Description: if set, maximizes along the specified axis, else maximizes the flattened trailing dimensions for each index of the first / num dimension.
- Range of values: integer values
Mathematical Formulation
ArgMax generally does the following with the input blobs:
![\[ o_{i} = \left\{ x| x \in S \wedge \forall y \in S : f(y) \leq f(x) \right\} \]](form_72.png)
Example
PSROIPooling Layer
Name: PSROIPooling
Short description: PSROIPooling layer compute position-sensitive max pooling on regions of interest specified by input, takes as input N position-sensitive score maps and a list of R regions of interest.
Detailed description: Reference
Parameters: PSRoiPooling layer parameters should be specified as the data node, which is a child of the layer node.
-
Parameter name: output_dim
- Description: pooled output channel number
- Range of values: positive integer number
-
Parameter name: group_size
- Description: number of groups to encode position-sensitive score maps
- Range of values: positive integer number
-
Parameter name: spatial_scale
- Description: multiplicative spatial scale factor to translate ROI coordinates from their input scale to the scale used when pooling
- Range of values: positive floating point value
Mathematical Formulation
The output value for 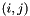 -th bin is obtained by summation from one score map
-th bin is obtained by summation from one score map 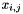 corresponding to that bin. In short, the difference from RoIPooling is that a general feature map is replaced by a specific positive-sensitive score map .
corresponding to that bin. In short, the difference from RoIPooling is that a general feature map is replaced by a specific positive-sensitive score map .
Example
GRN Layer
Name: GRN
Short description: GRN is Global Response Normalization with L2 norm (across channels only).
Parameters: GRN layer parameters should be specified as the data node, which is a child of the layer node.
- Parameter name: bias
- Description: bias is added to the variance.
- Range of values: floating point value
Mathematical Formulation
GRN computes L2 norm by channels for input blob. GRN generally does the following with the input blob:
![\[ output_{i} = \frac{input_{i}}{\sqrt{\sum_{i}^{C} input_{i}}} \]](form_75.png)
Example
PReLU Layer
Name: PReLU
Short description: PReLU is the Parametric Rectifier Linear Unit. The difference from ReLU is that negative slopes can vary across channels.
Parameters: PReLU layer parameters should be specified as the data node, which is a child of the layer node.
-
Parameter name: channel_shared
- Description: channel_shared shows if negative slope shared across channels or not.
- Range of values: 0 or 1
-
Parameter name: filler_type
- Description: filler_type defines initialization type for negative slope.
- Range of values: string
-
Parameter name: filler_value
- Description: filler_value defines the value in constant filler.
- Range of values: integer
-
Parameter name: min(max)
- Description: min(max) defines the minimal(maximal) value in uniform filler.
- Range of values: integer
-
Parameter name: mean
- Description: mean defines the mean value in Gaussian filler.
- Range of values: integer
Mathematical Formulation
PReLU accepts one input with four dimensions. The produced blob has the same dimensions as input.
PReLU does the following with the input blob:
![\[ o_{i} = max(0, x_{i}) + w_{i} * min(0,x_{i}) \]](form_76.png)
where 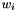 is from weights blob.
is from weights blob.
Example
RegionYolo layer
Name: RegionYolo
Short description: RegionYolo computes coordinates of regions with probability for each class.
Detailed description: Reference
Parameters: RegionYolo layer parameters should be specified as the data node, which is a child of the layer node.
-
Parameter name: coords
- Description: coords is num coordinates for each region
- Range of values: integer value
-
Parameter name: classes
- Description: classes is num classes for each region
- Range of values: integer value
-
Parameter name: num
- Description: num is number of regions
- Range of values: integer value
-
Parameter name: do_softmax
- Description: do_softmax is a flag which specifies the method of infer
-
Range of values:
- 0 - softmax is not performed
- 1 - softmax is performed
-
Parameter name: anchors
- Description: anchors coordinates regions
- Range of values: floating point values
-
Parameter name: mask
- Description: mask specifies which anchors to use
- Range of values: integer values
-
Parameter name: mask
- Description: mask specifies which anchors to use
- Range of values: integer values
-
Parameter name: axis
- Description: axis is the number of the dimension from which flattening is performed. For example, axis equals 1 means that flattening is started from the 1st dimension.
- Range of values: positive number greater or equal to 0
-
Parameter name: end_axis
- Description: end_axis is the number of the dimension on which flattening is ended. For example, end_axis equals -1 means that flattening is performed till the last dimension.
- Range of values: positive number greater or equal to 0
Mathematical formulation
RegionYolo calculates coordinates of regions by the rule:
![\[ p_{0,0}^i=b*o^i+n*w*h*(coords^i + classes + 1) + w*h+loc \]](form_78.png)
![\[ p_{1,1}^i=b*o^i+n*w*h*(coords^i + classes + 1) + coords*w*h+loc \]](form_79.png)
where:
i is number of regions
w and h are dimensions of image
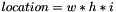
coords and classes are attributes of this layer
b is bacth
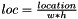
For each region, RegionYolo calculates probability by probability:
![\[ p^i = \frac{1}{1+e^-i} \]](form_82.png)
Example
ReorgYolo layer
Name: ReorgYolo
Short description: ReorgYolo reorganizes input blob taking into account strides.
Detailed description: Reference
Parameters: ReorgYolo layer parameters should be specified as the data node, which is a child of the layer node.
-
Parameter name: stride
- Description: stride is distance of cut throws in output blobs.
- Range of values: integer values
Mathematical formulation
RegionYolo reorganized the blob.
Destination index of the data calculates the following rules:
![\[ DistIndex=b * IC * IH * IW + ic * IH * IW + ih * IW + iw \]](form_83.png)
Source index of the data calculates the following rules:
![\[ SrcIndex=b * off_{ic} * off_{ih} * off_{iw} + C^o * off_{ih} * off_{iw} + H^o * off_{iw} + W^o; \]](form_84.png)
where:
![\[ C^o=C^i \pmod{\frac{IC}{stride^2}} \]](form_85.png)
![\[ W^o=W^i*stride + off_{ic}\pmod{stride} \]](form_86.png)
![\[ H^o=H^i*stride + \frac{C^i}{\frac{IC}{stride^2}} /{stride} \]](form_87.png)
![\[ off_{ic}=\frac{C^i}{\frac{IC}{stride^2}} \]](form_88.png)
![\[ off_{ih}=IH*stride \]](form_89.png)
![\[ off_{iw}=IW*stride \]](form_90.png)
![\[ ic \subset \left( 0, IC \right ) \]](form_91.png)
![\[ iw \subset \left( 0, IW \right ) \]](form_92.png)
![\[ ih \subset \left( 0, IH \right ) \]](form_93.png)
Example
PriorBoxClustered Layer
Name: PriorBoxClustered
Short description: PriorBoxClustered layer generates prior boxes of specified sizes.
Parameters: PriorBoxClustered layer parameters should be specified as the data node, which is a child of the layer node.
-
Parameter name: width (height)
- Description: width (height) is a parameter that specifies desired boxes widths (heights) in pixels.
- Range of values: floating point positive number
-
Parameter name: clip
- Description: clip is a flag that denotes if each value in the output blob is within [0,1]. For example, clip equal 1 means that each value in the output blob is within [0,1].
-
Range of values:
- 0 - clipping is not performed
- 1 - each value in the output blob is within [0,1]
-
Parameter name: flip
- Description: flip is a flag that denotes whether the list of boxes is augmented with the flipped ones.
-
Range of values:
- 0 - list of boxes is not augmented with the flipped ones
- 1 - list of boxes is augmented with the flipped ones
-
Parameter name: step (step_w, step_h)
- Description: step (step_w, step_h) is a distance between box centers. For example, step equal 85 means that the distance between neighborhood prior boxes centers is 85.
- Range of values: floating point positive number
-
Parameter name: offset
- Description: offset is a shift of box respectively to top left corner. For example, offset equal 85 means that the shift of neighborhood prior boxes centers is 85.
- Range of values: floating point positive number
-
Parameter name: variance
- Description: variance denotes a variance of adjusting bounding boxes. For example, variance equal 85 means that the shift of neighborhood prior boxes centers is 85.
- Range of values: floating point positive number
-
Parameter name: img_h (img_w)
- Description: img_h (img_w) specifies height (width) of input image. These parameters are calculated unless provided explicitly.
- Range of values: floating point positive number
Mathematical Formulation
PriorBoxClustered computes coordinates of prior boxes by following:
-
Calculates the center_x and center_y of prior box:
-
For each
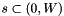 calculates the prior boxes coordinates:
calculates the prior boxes coordinates: ![\[ xmin = \frac{center_x - \frac{width_s}{2}}{W} \]](form_95.png)
![\[ ymin = \frac{center_y - \frac{height_s}{2}}{H} \]](form_96.png)
![\[ xmax = \frac{center_x - \frac{width_s}{2}}{W} \]](form_97.png)
![\[ ymax = \frac{center_y - \frac{height_s}{2}}{H} \]](form_98.png)
If clip is defined, the coordinates of prior boxes are recalculated with the formula: 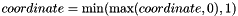
Example
MVN Layer
Name: MVN
Short description: Reference
Parameters: MVN layer parameters should be specified as the data node, which is a child of the layer node.
-
Parameter name: across_channels
- Description: across_channels is a flag that denotes if mean values are shared across channels. For example, across_channels equal 0 means that mean values are not shared across channels.
-
Range of values:
- 0 - mean values are not shared across channels
- 1 - mean values are shared across channels
-
Parameter name: normalize_variance
- Description: normalize_variance is a flag that denotes whether to perform variance normalization.
-
Range of values:
- 0 - variance normalization is not performed
- 1 - variance normalization is performed
-
Parameter name: eps
- Description: eps is the number to be added to the variance to avoid division by zero when normalizing the value. For example, epsilon equal 0.001 means that 0.001 is added to the variance.
- Range of values: positive floating point number
Mathematical Formulation
MVN subtracts mean from the input blob:
![\[ o_{i} = i_{i} - \frac{\sum{i_{k}}}{C * H * W} \]](form_100.png)
If normalize_variance is set to 1, the output blob is divided by variance:
![\[ o_{i}=\frac{o_{i}}{\sum \sqrt {o_{k}^2}+\epsilon} \]](form_101.png)
Example
CTCGreadyDecoder Layer
Name: CTCGreadyDecoder
Short description: CTCGreadyDecoder performs greedy decoding on the logits given in input (best path).
Detailed description: Reference
Parameters: CTCGreadyDecoder layer parameters should be specified as the data node, which is a child of the layer node.
-
Parameter name: ctc_merge_repeated
- Description: ctc_merge_repeated is a flag for collapsing the repeated labels during the ctc calculation.
- Range of values: 0 or 1
Mathematical Formulation
Given an input sequence 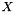 of length
of length 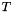 , CTCGreadyDecoder assumes the probability of a length character sequence is given by
, CTCGreadyDecoder assumes the probability of a length character sequence is given by
![\[ p(C|X) = \prod_{t=1}^{T} p(c_{t}|X) \]](form_104.png)
Example
Proposal Layer
Name: Proposal
Short description: Proposal layer performs filtering of only those bounding boxes and outputs with the highest confidence of prediction.
Parameters: Proposal layer parameters should be specified as the data node, which is a child of the layer node.
-
Parameter name: pre_nms_topn (post_nms_topn)
- Description: pre_nms_topn (post_nms_topn) is the quantity of bounding boxes before (after) applying NMS operation. For example, pre_nms_topn (post_nms_topn) equal 15 means that the minimum (maximum) box size is 15.
- Range of values: positive integer number
-
Parameter name: nms_thresh
- Description: nms_thresh is the minimum value of the proposal to be taken into consideration. For example, nms_thresh equal 0.5 means that all boxes with prediction probability less than 0.5 are filtered out.
- Range of values: positive floating point number
-
Parameter name: feat_stride
- Description: feat_stride is the step size to slide over boxes (in pixels). For example, feat_stride equal 16 means that all boxes are analyzed with the slide 16.
- Range of values: positive integer number
-
Parameter name: min_size
- Description: min_size is the minimum size of box to be taken into consideration. For example, min_size equal 35 means that all boxes with box size less than 35 are filtered out.
- Range of values: positive integer number
-
Parameter name: base_size
- Description: base_size is the base size for anchor generation.
- Range of values: positive integer number
-
Parameter name: ratio
- Description: ratio is the ratios for anchor generation.
- Range of values: array of float numbers
-
Parameter name: scale
- Description: scale is the scales for anchor generation.
- Range of values: array of float numbers
Mathematical Formulation
Proposal layer accepts three inputs with four dimensions. The produced blob has two dimensions: first one equals batch_size * post_nms_topn.
Proposal does the following with the input blob:
- Generates initial anchor boxes Left top corner of all boxes in (0, 0). Width and height of boxes are calculated from base_size with scale and ratio parameters
- For each point in the first input blob:
- pins anchor boxes to the image according to the second input blob that contains four deltas for each box: for x and y of center, for width and for height
- finds out score in the first input blob
- Filters out boxes with size less than min_size
- Sorts all proposals (box, score) by score from highest to lowest
- Takes top pre_nms_topn proposals
- Calculates intersections for boxes and filter out all with
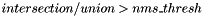
- Takes top post_nms_topn proposals
- Returns top proposals
Example
Resample Layer
Name: Resample
Short description: Resample layer scales the input blob by the specified parameters.
Parameters: Resample layer parameters should be specified as the data node, which is a child of the layer node.
-
Parameter name: type
- Description: type parameter specifies type of blob interpolation.
-
Range of values:
- LINEAR - linear blob interpolation
- CUBIC - cubic blob interpolation
- NEAREST - nearest-neighbor blob interpolation
-
Parameter name: antialias
- Description: antialias is a flag that denotes whether to perform anti-aliasing.
-
Range of values:
- 0 - anti-aliasing is not performed
- 1 - anti-aliasing is performed
Mathematical formulation
Resample layer scales the input blob. Depending on the type parameter, Resample applies different blob interpolation algorithms and performs anti-aliasing if the antialias parameter is specified.
Example
Power Layer
Name: Power
Short description: Power layer computes the output as (shift + scale * x) ^ power for each input element x.
Parameters: Power layer parameters should be specified as the data node, which is a child of the layer node.
-
Parameter name: power
- Description: power represents the power parameter.
-
Parameter name: scale
- Description: scale represents the scaling parameter.
-
Parameter name: shift
- Description: shift represents the shifting parameter.
Mathematical Formulation
![\[ p = (shift + scale * x)^{power} \]](form_106.png)
Example
Pad Layer
Name: Pad
Short description: Pad layer extends an input tensor on edges. New element values are generated based on the Pad layer parameters described below.
Parameters: Pad layer parameters should be specified in the data section, which is placed as a child of the layer node. The parameters specify a number of elements to added along each axis and a rule by which new element values are generated: for example, whether they are filled with a given constant or generated based on the input tensor content.
-
Parameter name: pads_begin
- Description: A number of padding elements at the beginning of each axis. Required.
- Range of values: A list of non-negative integers. The length of the list must be equal to the number of dimensions in the input tensor.
-
Parameter name: pads_end
- Description: A number of padding elements at the end of each axis. Required.
- Range of values: A list of non-negative integers. The length of the list must be equal to the number of dimensions in the input tensor.
-
Parameter name: pad_mode
- Description: A method used to generate new element values. Required.
-
Range of values: Name of the method in string format:
-
constant: Padded values are equal to the value of the pad_value layer parameter. -
edge: Padded values are copied from the respective edge of the input tensor. -
reflect: Padded values are a reflection of the input tensor; values on the edges are not duplicated.pads_begin[D]andpads_end[D]must be not greater thaninput.shape[D] – 1for any validD. -
symmetric: Padded values are symmetrically added from the input tensor. This method is similar to thereflect, but values on edges are duplicated. Refer to the examples below for more details.pads_begin[D]andpads_end[D]must be not greater thaninput.shape[D]for any validD.
-
-
Parameter name: pad_value
-
Description: Applicable for the
pad_mode = "constant"only. All new elements are filled with this value. Optional, default value is 0. - Range of values: An arbitrary floating point value.
-
Description: Applicable for the
Inputs
- 1: Multidimensional input blob
Outputs
-
1: Multidimensional input blob with dimensions
pads_begin[D] + input.shape[D] + pads_end[D]for eachDfrom0tolen(input.shape) - 1.
pad_mode Examples
The following examples illustrate how output tensor is generated for the Pad layer for a given input tensor:
with the following parameters:
depending on the pad_mode.
-
pad_mode = "constant":OUTPUT =[[ 0 1 2 3 4 0 0 0 ][ 0 5 6 7 8 0 0 0 ][ 0 9 10 11 12 0 0 0 ][ 0 0 0 0 0 0 0 0 ][ 0 0 0 0 0 0 0 0 ]] -
pad_mode = "edge":OUTPUT =[[ 1 1 2 3 4 4 4 4 ][ 5 5 6 7 8 8 8 8 ][ 9 9 10 11 12 12 12 12 ][ 9 9 10 11 12 12 12 12 ][ 9 9 10 11 12 12 12 12 ]] -
pad_mode = "reflect":OUTPUT =[[ 2 1 2 3 4 3 2 1 ][ 6 5 6 7 8 7 6 5 ][ 10 9 10 11 12 11 10 9 ][ 6 5 6 7 8 7 6 5 ][ 2 1 2 3 4 3 2 1 ]] -
pad_mode = "symmetric":OUTPUT =[[ 1 1 2 3 4 4 3 2 ][ 5 5 6 7 8 8 7 6 ][ 9 9 10 11 12 12 11 10 ][ 9 9 10 11 12 12 11 10 ][ 5 5 6 7 8 8 7 6 ]]
Example
LSTMCell Layer
Name: LSTMCell
Short description: LSTMCell layer computes the output using the formula described in original paper Long Short-Term Memory.
Parameters: None
Mathematical Formulation
Example
TensorIterator Layer
Name: TensorIterator
Short description: TensorIterator (TI) layer performs recurrent subgraph execution iterating through the data.
Parameters: port_map and back_edges sections specifying data mapping rules:
-
port_map: A set of rules to map in/out data tensors of the
TensorIteratorlayer onbodydata tensorsPort mapping rule is presented like
input/outputnode with a set of rule attributes:-
external_port_id: port ID of theTensorIteratorlayer -
internal_layer_id: layer ID inside thebodysubnetwork to map to -
internal_port_id: port ID of thebodylayer to map to -
axis: an axis to iterate through.-1means no iteration is done. Default value is-1. -
start: an index from where iteration starts. Negative value means index from the end. Default value is0. -
end: an index where iterations ends. Negative value means index from the end. Default value is-1. -
stride: step of iteration. Negative value means backward iteration. Default value is1.
-
-
back_edges: A set of rules to transfer data tensors between
bodyiteration. Mapping rule is presented like generaledgenode with port indexes ofbodysubnetwork. - body: A subnetwork that will be recurrently executed
Example