This section provides a high-level description of the process of integrating the Inference Engine into your application. Refer to the Hello Infer Request Classification Sample sources for example of using the Inference Engine in applications.
Using the Inference Engine API in Your Code
The core libinference_engine.so library implements loading and parsing a model IR, and triggers inference using a specified plugin. The core library has the following API:
InferenceEngine::PluginDispatcher-
InferenceEngine::Blob,InferenceEngine::TBlob InferenceEngine::BlobMap-
InferenceEngine::InputsDataMap,InferenceEngine::InputInfo, InferenceEngine::OutputsDataMap
C++ IE API wraps the capabilities of core library:
InferenceEngine::CNNNetReaderInferenceEngine::CNNNetworkInferenceEngine::InferencePluginInferenceEngine::ExecutableNetworkInferenceEngine::InferRequest
Integration process consists of the following steps:
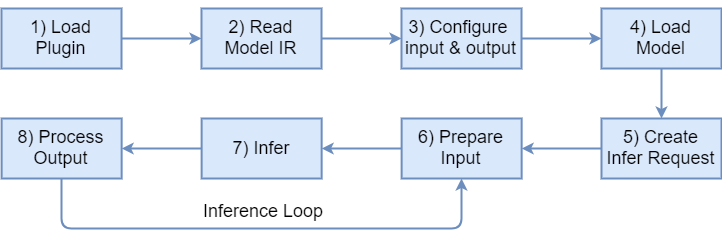
1) Load plugin
Load plugin by creating an instance of InferenceEngine::InferenceEnginePluginPtr. Wrap it by creating instance of InferenceEngine::InferencePlugin from C++ IE API. Specify the plugin or let Inference Engine to choose it using InferenceEngine::PluginDispatcher.
2) Read Model IR
Create an IR reader by creating an instance of InferenceEngine::CNNNetReader and read a model IR created by Model Optimizer:
3) Configure input & output
Request input and output information using
InferenceEngine::CNNNetReader::getNetwork(), InferenceEngine::CNNNetwork::getInputsInfo(), and InferenceEngine::CNNNetwork::getOutputsInfo() methods.
Optionally, set the number format (precision) and memory layout for inputs and outputs. Refer to the Supported configurations chapter to choose the relevant configuration.
You can also allow input of any size. To do this, mark each input as resizable by setting a desired resize algorithm (e.g. BILINEAR) inside of the appropriate input info.
If you skip this step, the default values are set:
- no resize algorithm is set for inputs
- input and output precision -
Precision::FP32 - input layout -
Layout::NCHW -
output layout depends on number of its dimensions:
Number of dimensions | 5 | 4 | 3 | 2 | 1 —|—|—|—|— Layout | NCDHW | NCHW | CHW | NC | C
4) Load Model
Load the model to the plugin using InferenceEngine::InferencePlugin::LoadNetwork():
It creates an executable network from a network object. The executable network is associated with single hardware device. It is possible to create as many networks as needed and to use them simultaneously (up to the limitation of the hardware resources). Second parameter is a configuration for plugin. It is map of pairs: (parameter name, parameter value). Choose device from Supported devices page for more details about supported configuration parameters.
## 5) Create an Infer Request
6) Prepare Input
The following options can be used to prepare input:
-
Optimal way for a single network. Get blobs allocated by an infer request using
InferenceEngine::InferRequest::GetBlob()and feed an image and the input data to the blobs. In this case, input data must be aligned (resized manually) with a given blob size.
-
Optimal way for a cascade of networks (output of one network is input for another). Get output blob from the first request using
InferenceEngine::InferRequest::GetBlob()and set it as input for the second request usingInferenceEngine::InferRequest::SetBlob().
-
Optimal way for ROI handling (a ROI object located inside of input of one network is input for another). It is possible to re-use shared input by several networks. You do not need to allocate separate input blob for a network if it processes a ROI object located inside of already allocated input of a previous network. For instance, when first network detects objects on a video frame (stored as input blob) and second network accepts detected bounding boxes (ROI inside of the frame) as input. In this case, it is allowed to re-use pre-allocated input blob (used by first network) by second network and just crop ROI without allocation of new memory using
InferenceEngine::make_shared_blob()with passing ofInferenceEngine::Blob::PtrandInferenceEngine::ROIas parameters.
Make sure that shared input is kept valid during execution of each network. Otherwise, ROI blob may be corrupted if the original input blob (that ROI is cropped from) has already been rewritten.
- Allocate input blobs of the appropriate types and sizes, feed an image and the input data to the blobs, and call
InferenceEngine::InferRequest::SetBlob()to set these blobs for an infer request:
A blob can be filled before and after SetBlob().
NOTE:
SetBlob()method compares precision and layout of an input blob with ones defined on step 3 and throws an exception if they do not match. It also compares a size of the input blob with input size of the read network. But if input was configured as resizable, you can set an input blob of any size (for example, any ROI blob). Input resize will be invoked automatically using resize algorithm configured on step 3.
NOTE:
GetBlob()logic is the same for resizable and not-resizable input. Even if it is called with input configured as resizable, a blob allocated by an infer request is returned. Its size is already consistent to input size of a read network. No resize will happen for this blob. If you callGetBlob()afterSetBlob(), you will get the blob you set inSetBlob().
7) Infer
Do inference by calling the InferenceEngine::InferRequest::StartAsync and InferenceEngine::InferRequest::Wait methods for asynchronous request:
or by calling the InferenceEngine::InferRequest::Infer method for synchronous request:
StartAsync returns immediately and starts inference without blocking main thread, Infer blocks main thread and returns when inference is completed. Call Wait for waiting result to become available for asynchronous request.
There are 3 ways to use it:
- specify maximum duration in milliseconds to block for. The method is blocked until the specified timeout has elapsed, or the result becomes available, whichever comes first.
-
InferenceEngine::IInferRequest::WaitMode::RESULT_READY- waits until inference result becomes available -
InferenceEngine::IInferRequest::WaitMode::STATUS_ONLY- immediately returns request status.It does not block or interrupts current thread.
Both requests are thread-safe: can be called from different threads without fearing corruption and failures.
Multiple requests for single ExecutableNetwork are executed sequentially one by one in FIFO order.
While request is ongoing, all its methods except InferenceEngine::InferRequest::Wait would throw an exception.
8) Process Output
Go over the output blobs and process the results. Note that casting Blob to TBlob via std::dynamic_pointer_cast is not recommended way, better to access data via buffer() and as() methods as follows:
Building Your Application
For details about building your application, refer to the CMake files for the sample applications. All samples reside in the samples directory in the Inference Engine installation directory.
Running Your Application
Before running compiled binary files, make sure your application can find the Inference Engine libraries. On Linux* operating systems, including Ubuntu* and CentOS*, the LD_LIBRARY_PATH environment variable is usually used to specify directories to be looked for libraries. You can update the LD_LIBRARY_PATH with paths to the directories in the Inference Engine installation directory where the libraries reside.
Add a path the directory containing the core and plugin libraries:
- For the Inference Engine installed within the OpenVINO™ toolkit package:
- For Intel® Deep Learning Deployment Toolkit installation:
Add paths the directories containing the required third-party libraries:
- For Inference Engine installed within the OpenVINO™ toolkit package:
- For Intel® Deep Learning Deployment Toolkit installation:
Alternatively, you can use the following scripts that reside in the Inference Engine directory of the OpenVINO™ toolkit and Intel® Deep Learning Deployment Toolkit installation folders respectively:
-
/opt/intel/computer_vision_sdk_<version>/bin/setupvars.sh
-
/opt/intel/deep_learning_sdk_<version>/deployment_tools/inference_engine/bin/setvars.sh
To run compiled applications on Microsoft* Windows* OS, make sure that Microsoft* Visual C++ 2015 Redistributable and Intel® C++ Compiler 2017 Redistributable packages are installed and <INSTALL_DIR>/bin/intel64/Release/*.dll files are placed to the application folder or accessible via PATH% environment variable.